リード スコアリング モデルを編集して再トレーニングする
リード スコアリング モデル の予測精度が期待を満たさない場合、またはモデルが既存のモデルと重複する場合は、使用する属性を編集して再トレーニングできます。
注意
リアルタイム スコアリング機能は、Sales Insightsバージョン9.0.22121.10001の一部として2022年12月に展開されました。 このロールアウト前に公開されたモデルは、リアルタイムでスコア付けできるように、編集して再度公開する必要があります。
ライセンスとロールの要件
| 要件タイプ | 以下が必要です |
|---|---|
| ライセンス | Dynamics 365 Sales Premium または Dynamics 365 Sales Enterprise 詳細情報: Dynamics 365 Sales の価格 |
| セキュリティ ロール | システム管理者 詳細: 営業向けに事前定義されたセキュリティ ロール |
モデルを編集する
営業ハブ アプリの左下隅で 領域の変更 に移動し、Sales Insights の設定 を選択します。
サイトマップの 予測モデル配下のリードスコアリング を選択します。
予測リード スコアリング ページでモデルを開き、自動的に再トレーニング がオフになっていることを確認します。
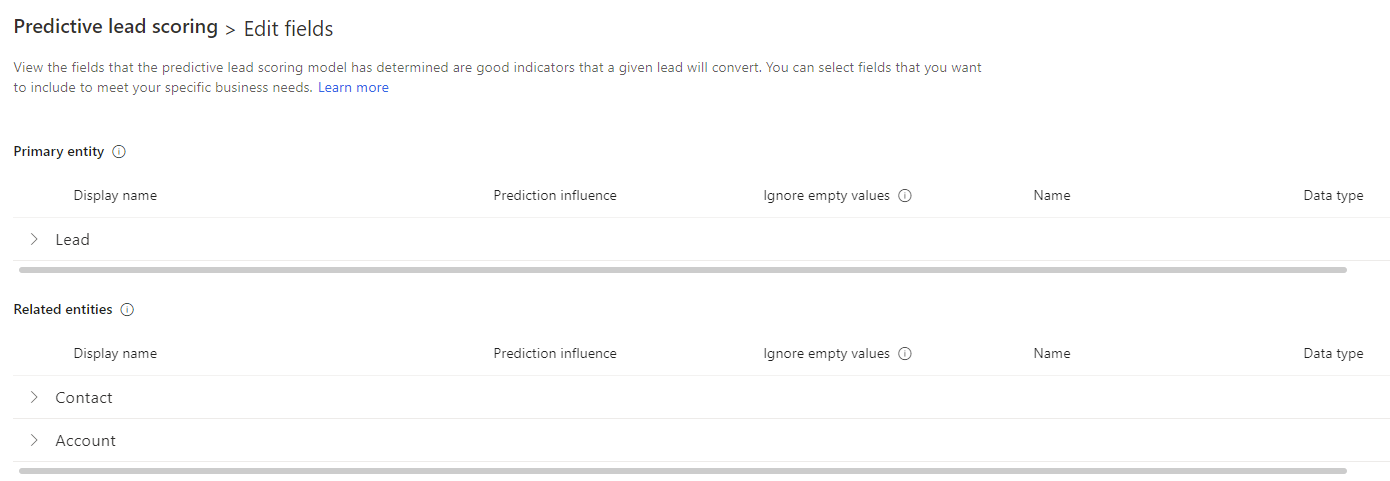
モデルの編集 を選択し、以下いずれかかのアクションを実行します:
属性を選択して、モデルへの影響に関する分析情報を確認します。
リード エンティティとその関連エンティティ (取引先担当者と取引先企業) から属性 (カスタム属性を含む) を選択して、モデルをトレーニングします。
インテリジェント フィールドを選択してモデルに含めます。
注意
スコアリングモデルは、次のタイプの属性をサポートしていません。
- カスタム エンティティの属性
- 日付と時間に関連する属性
- システム生成属性 (リードスコア、リードグレード、バージョン番号、エンティティ イメージ、為替レート、予測スコアリング ID など)
(オプション) 属性リストの右側にスクロールして、空の値を無視するをオンにします。
既定では、モデルのトレーニング用に属性に空の値が含まれています。 空の値が中傷者として機能している、または誤検知を生成していることに気付いた場合は、空の値を無視するをオンにします。
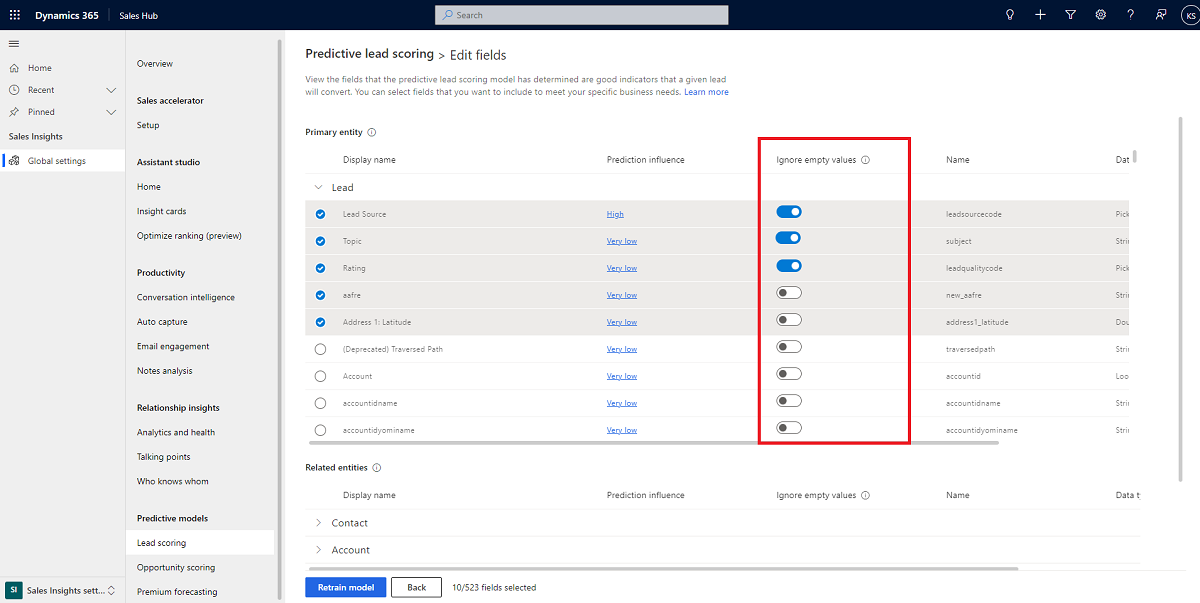
次のタイプの属性では、空の値を無視するオプションが無効になっています:
- 空の値に対して自動的に検証が行われる属性 (firstname_validation_engineered など)
- 値の有無によってスコアに影響を与える属性 (郵便番号や勤務先電話番号など)。
ある属性に対して空白の値を無視を有効にすると、スコアリング ウィジェットでは、空白の値を除外した後でスコアが計算されることが示されます。
モデルの再トレーニング を選択します。
モデルの再トレーニングまで数分待機します。 準備が整うと、次のようなメッセージが表示されます:
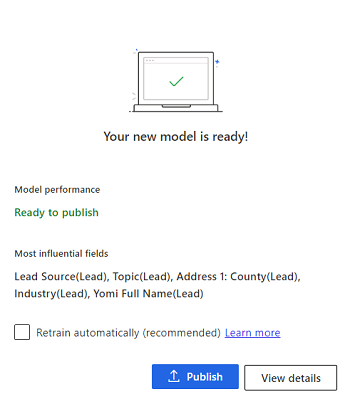
アプリケーションで 15 日ごとにモデルを自動的に再トレーニングする場合は、自動的に再トレーニングを選択します。
次のアクションのうち 1 つを実行します。
公開する準備ができたら、公開を選択します。 モデルは、モデル構成で指定された条件に一致するリードに適用されます。 予測リード スコアリングは、 リード スコアリング 列の配下のビューや、潜在顧客フォームのウィジェットに表示されます。 詳細情報 : リードを営業案件に変換する
精度の検証: モデルの精度を確認する場合、詳細の表示 を選択してから パフォーマンス タブを選択します。詳細については、予測スコアリング モデルの精度とパフォーマンスの表示 を参照してください。
再トレーニングされたモデルの正確性が不十分な場合は、属性を編集してモデルを再トレーニングします。 以前のバージョンに戻す場合は、そのバージョンに戻します。
インテリジェント フィールドを選択する
インテリジェント フィールドは、モデルが記録をよりよく理解し、スコアを向上させる要因とそれを損なう要因を区別するのに役立つ。 たとえば、このモデルでは、アプリケーションで利用可能なデータとモデルに追加されたインテリジェンスを使用して電子メールの種類を識別し、グループ化することにより、ビジネス用の電子メールアドレスと個人用の電子メールアドレスを区別することができます。 この識別を通じて、モデルは、フィールドのグループが予測スコアにどのように影響するかについての詳細な洞察を生成できます。
前のセクションで説明したようにモデルを編集して、モデルで使用するインテリジェント フィールドを選択します。 次の画像は、インテリジェント フィールドを選択する方法を示しています。
![モデルコンセプトセクションにインテリジェントフィールドの選択リストが表示されている [フィールドの編集] ページのスクリーンショット。](media/si-admin-predictive-lead-scoring-edit-model-intelligent-fields.png)
予測の影響 列でリンクを選択し、資格率や、その率の正と負の両方の最も影響力のある理由など、フィールドに関する分析情報を表示します。 モデルに対する属性の影響を確認する方法について解説します。
次のフィールドがサポートされています: メールドメインの検証 (電子メール)、名の検証 (名)、と 姓の検証 (姓)。 モデルは常に以下を優先します。
- ビジネスドメインの一部であるメール
- 特殊文字ではなく英数字を含む姓名
規定では、すぐに使用できる値を使用してモデルをトレーニングするときに、インテリジェント フィールドが考慮されます。 インテリジェント フィールドの結果が満足のいくものである場合、モデルにはトレーニングするフィールドが含まれます。それ以外の場合、フィールドは無視されます。 ただし、結果が不十分な場合でも、必要に応じて、モデルをトレーニングするためのインテリジェント フィールドを含めることを選択できます。
注意
インテリジェント フィールドは、リードエンティティやその関連エンティティ、取引先担当者、取引先企業では使用できません。
モデルの再トレーニング
予測の精度スコアが組織の基準を満たしていない場合、またはモデルが古すぎる場合は、モデルを再トレーニングします。 通常、再トレーニングすると一般的にモデルの予測精度のスコアが向上します。 アプリケーションは、組織の最新リードを使用してモデルをトレーニングし、より正確なスコアを営業担当に提供できるようにします。
予測精度のスコアリングを向上させるには、組織内のデータを更新した後にモデルを再トレーニングします。
自動再トレーニング
自動再トレーニングでは、アプリケーションは 15 日ごとに 1 回、モデルを再トレーニングできます。 これにより、モデルは最新のデータから学習し、予測精度のスコアを向上させることができます。
モデルを自動的に再トレーニングするには、モデルの予測リード スコアリングページに移動し、自動的に再トレーニングを選択します。 既定では、このオプションはモデルが公開されたときに有効になります。
モデルの精度に応じて、アプリケーションは再トレーニングされたモデルを公開するか無視するかを情報に基づいて決定します。 このアプリケーションは、以下のシナリオでモデルを自動的に公開します:
- 再トレーニングされたモデルの精度が、アクティブ モデルの精度の 95% 以上である場合。
- 現在のモデルが 3 か月以上前のものである場合。
それ以外の場合、アプリケーションは現在のモデルを保持します。
手動による再トレーニング
次の場合、モデルを手動で再トレーニングできます。
- 正確性を高めるためにモデルを編集し、再トレーニングしたいと考えています。
- 自動的に再トレーニング をオフにしました。
どちらの場合も、モデルを編集して、手動再トレーニングをトリガーする必要があります。
アプリのオプションが見つかりませんか?
次の 3 つの可能性があります:
- 必要なライセンスまたは役割がありません。 このページの上部にあるライセンスとロールの要件のセクションを確認してください。
- 管理者がこの機能を有効にしていない場合。
- 組織がカスタム アプリを使用している場合。 正確な手順について管理者に確認してください。 この記事で説明する手順は、すぐに使用できる営業ハブ アプリと Sales Professional アプリのみに該当します。