このチュートリアルでは、Spark ランタイムでノートブックを使用して、Lakehouse 内の生データを変換および準備します。
前提条件
開始する前に、このシリーズの前のチュートリアルを完了する必要があります。
- レイクハウスを作成する
- レイクハウスにデータを取り込む
- lakehouse で lakehouse スキーマが有効になっていることを確認します。
データを準備する
前のチュートリアルの手順では、ソースから lakehouse のファイルセクションに生データを取り込んでいます。 これで、そのデータを変換し、デルタ テーブルを作成するための準備を行うことができます。
Lakehouse Tutorial Source Code フォルダーからノートブックをダウンロードします。
ブラウザーで、 Fabric ポータルで Fabric ワークスペースに移動します。
[>>。
![Fabric ポータルの [ノートブックのインポート] オプションを示すスクリーンショット。](media/tutorial-lakehouse-data-preparation/import-notebook.png)
画面の右側に表示される [インポート状態] ウィンドウから [アップロード] を選択します。
好みのコーディング言語に一致するノートブックのみを選択します。
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
[開く] を選択します。 インポートの状態を示す通知がブラウザー ウィンドウの右上隅に表示されます。
インポートが成功したら、ワークスペースのアイテム ビューに移動して、インポートされたノートブックを確認します。
wwilakehouse のレイクハウスを開くことで、次に開くノートブックとリンクされます。
上部のナビゲーション メニューで、[ ノートブックを開く>ノートブックの作成] を選択します。
PySpark または Spark SQL 用にインポートしたノートブックを選択し、[ 開く] を選択します。 ノートブックは、レイクハウス エクスプローラーに示すように、開いているレイクハウスに既にリンクされています。
![Fabric ポータルの [ノートブックのインポート] オプションを示すスクリーンショット。](media/tutorial-lakehouse-data-preparation/import-notebook.png#lightbox)


これで、Delta テーブルを作成して変換するノートブック セルを実行する準備ができました。
次のセクションでは、ノートブックのセルを順番に実行します。 セルを実行するには、ホバー時にセルの左側に表示される [実行 ] アイコンを選択します。 上部のリボン (ホーム) で [すべて実行] を選択して、すべてのセルを順番に実行することもできます。
Important
このチュートリアルでは、lakehouse スキーマを有効にする必要があります。 スキーマが有効になっていない場合、このチュートリアルのコードは意図したとおりに動作しません。
インポートしたノートブックには、 パス 1 と パス 2 の両方のセクションが表示されます。 このチュートリアルでは、 パス 1 (lakehouse スキーマが有効) を使用し、 パス 2 (レイクハウス スキーマが有効になっていない) を無視します。
Delta テーブルを作成する
このセクションでは、ノートブックのセルを実行して、生データから差分テーブルを作成します。
テーブルはスター スキーマに従います。これは、分析データを整理するための一般的なパターンです。
-
ファクト テーブル (
fact_sale) には、ビジネスの測定可能なイベント (この場合は、数量、価格、利益を含む個々の販売トランザクション) が含まれています。 -
ディメンション テーブル (
dimension_city、dimension_customer、dimension_date、dimension_employee、dimension_stock_item) には、販売の発生場所、作成者、タイミングなど、ファクトに関するコンテキストを示す説明的な属性が含まれています。
このチュートリアル ページでは、インポートしたノートブックに一致するタブを選択し、すべての手順で同じタブを使用し続けます。 タブは、ノートブックではなく、この記事にあります。
セル 1 - Spark セッションの構成。 このセルを使用すると、後続のセルでのデータの書き込みと読み取り方法を最適化する 2 つの Fabric 機能が有効になります。 V オーダーでは 、読み取り速度が向上し、圧縮が向上するため、Parquet ファイルレイアウトが最適化されます。 書き込みを最適化 すると、書き込まれるファイルの数が減り、個々のファイル サイズが増加します。
このセルを実行し、完了するまで待ってから次の手順に進みます。
セル 2 - ファクト - セール。 このセルは、
Files/wwi-raw-data/full/fact_sale_1y_fullから生の Parquet データを読み取り、日付の一部である列 (Year、Quarter、Month) を追加し、fact_saleを Year と Quarter でパーティション化された Delta テーブルとして書き込みます。このセルを実行し、完了するまで待ってから次の手順に進みます。
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)セル 3 - 寸法。 このセルは、5 つのディメンション Parquet データセットを読み取り、
dimension_cityの下の Delta テーブル (dimension_customer、dimension_date、dimension_employee、dimension_stock_item、およびTables/dbo/...) として書き込みます。このセルを実行し、完了するまで待ってから次の手順に進みます。
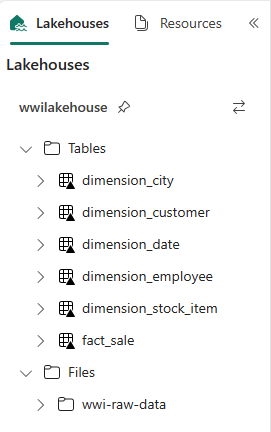
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)作成したテーブルを検証するには、エクスプローラーで wwilakehouse lakehouse を右クリックし、[最新の 情報に更新] を選択します。 テーブルが表示されます。

ビジネス集計のデータを変換する
このセクションでは、同じノートブックに進み、次のセルを実行して、前のセクションで作成した Delta テーブルから集計テーブルを作成します。
ノートブックが wwilakehouse にリンクされていることを確認します。
セル 4 - 変換のソース テーブルを読み込みます (PySpark のみ)。 PySpark ノートブックを使用している場合は、このセルを実行して、次の集計手順のために Delta テーブルを DataFrames に読み込みます。
このセルを実行し、完了するまで待ってから次の手順に進みます。
セル 5 -
aggregate_sale_by_date_cityを作成します。 このセルは、売上、日付、および市区町村のデータを結合し、市レベルの集計テーブルを作成します。このセルを実行し、完了するまで待ってから次の手順に進みます。
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")セル 6 -
aggregate_sale_by_date_employeeを作成します。 このセルは、売上、日付、従業員のデータを結合し、従業員レベルの集計テーブルを作成します。このセルを実行し、完了するまで待ってから次の手順に進みます。
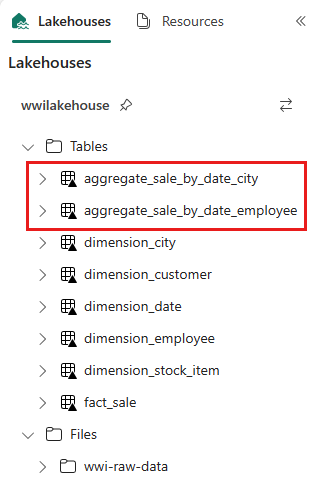
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")作成したテーブルを検証するには、エクスプローラーで wwilakehouse lakehouse を右クリックし、[最新の 情報に更新] を選択します。 集計テーブルが表示されます。

このチュートリアルでは、データを Delta Lake ファイルとして書き込みます。 Fabric は、これらのテーブルを自動的に検出してメタストアに登録するため、個別の CREATE TABLE ステートメントを実行する必要はありません。