この記事では、パイプラインでコピー アクティビティを使用して、Azure SQL Database との間でデータをコピーする方法について説明します。
サポートされている構成
コピー アクティビティの下の各タブの構成については、それぞれ次のセクションを参照してください。
全般
全般 設定 ガイダンスを参照して、全般 設定タブを構成します。
ソース
コピー アクティビティの [ソース] タブの Azure SQL Database では、次のプロパティがサポートされます。
必要なプロパティは次のとおりです :
- 接続: 接続の一覧から Azure SQL Database 接続を選択します。 接続が存在しない場合は、[新規] を選択して新しい Azure SQL Database 接続を作成します。
- 接続の種類: Azure SQL Databaseを選択します。
- テーブル: ドロップダウン リストからデータベース内のテーブルを選択します。 または、[ 編集] をオンにして、テーブル名を手動で入力します。
- データのプレビュー: プレビュー データ を選択して、テーブル内のデータをプレビューします。
[詳細設定 で、次のフィールドを指定できます。
クエリを使用する: テーブル、クエリ、またはストアド プロシージャ を選択できます。 次の一覧では、各設定の構成について説明します。
テーブル: このボタンを選択した場合、テーブル で指定したテーブルからデータを読み取る。
クエリ: データを読み取るカスタム SQL クエリを指定します。 たとえば、
select * from MyTableです。 または、コード エディターで編集する鉛筆アイコンを選択します。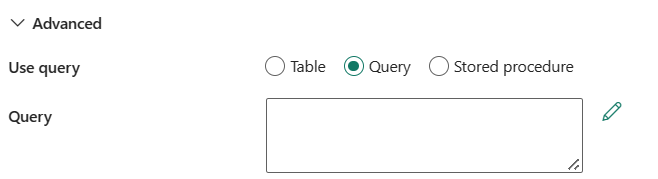
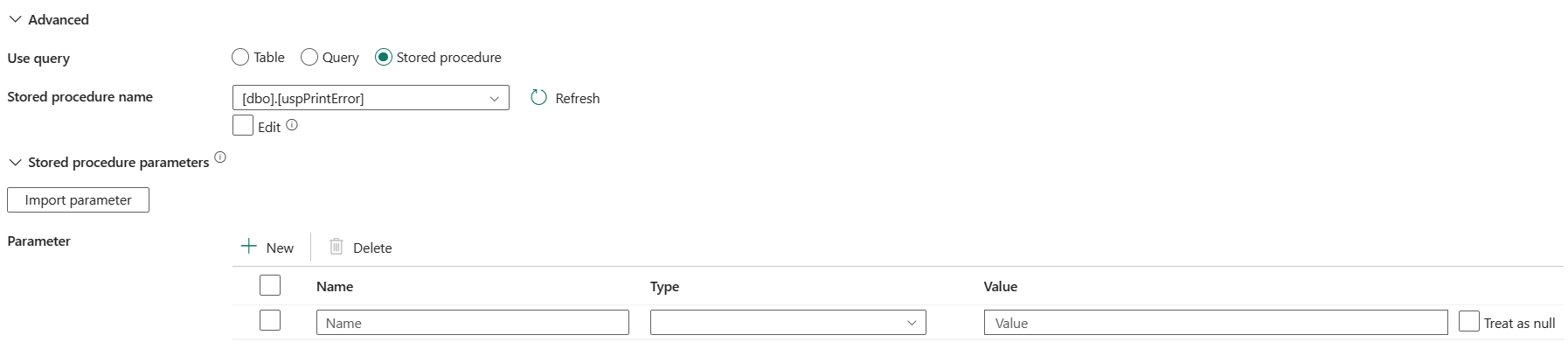
ストアド プロシージャ: ソース テーブルからデータを読み取るストアド プロシージャを使用します。 最後の SQL ステートメントは、ストアド プロシージャ内の SELECT ステートメントである必要があります。
ストアド プロシージャ名: ソース テーブルからデータを読み取る [ の編集] ボックスをオンにするときに、ストアド プロシージャを選択するか、ストアド プロシージャ名を手動で指定します。
ストアド プロシージャ パラメーター: ストアド プロシージャ パラメーターの値を指定します。 使用できる値は、名前または値のペアです。 パラメーターの名前と大文字と小文字の区別は、ストアド プロシージャ パラメーターの名前と大文字と小文字の区別と一致する必要があります。
クエリ タイムアウト (分): クエリ コマンドの実行のタイムアウトを指定します。既定値は 120 分です。 このプロパティにパラメーターが設定されている場合、使用できる値は"02:00:00" (120 分) などの期間です。
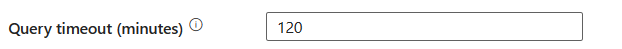
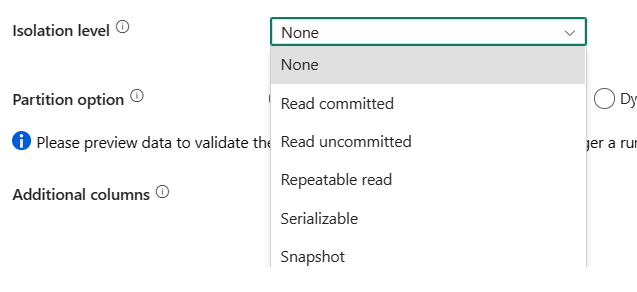
分離レベル: SQL ソースのトランザクション ロック動作を指定します。 使用できる値は、None、ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、またはスナップショット です。 指定しない場合は、分離レベル None が使用されます。 詳細については、「IsolationLevel 列挙型」 を参照してください。
パーティション オプション: Azure SQL Database からデータを読み込むのに使用するデータ パーティション分割オプションを指定します。 使用できる値は、None (既定値)、テーブル の物理パーティション、ダイナミック レンジ です。 パーティション オプションが有効になっている場合 (つまり、なしではない場合)、Azure SQL Database から同時にデータを読み込む並列処理の程度は、コピー アクティビティの 並列コピー 設定によって制御されます。

なし: パーティションを使用しない場合は、この設定を選択します。
テーブルの物理パーティション: 物理パーティションを使用すると、物理テーブル定義に基づいてパーティション列とメカニズムが自動的に決定されます。
ダイナミック レンジ: 並列が有効なクエリを使用する場合は、範囲パーティション パラメーター (
?DfDynamicRangePartitionCondition) が必要です。 サンプル クエリ:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。-
パーティション列名: 並列コピーの範囲パーティション分割で使用されるソース列の名前 整数型または date/date time 型 (
int、smallint、bigint、date、smalldatetime、datetime、datetime2、またはdatetimeoffset) で指定します。 指定しない場合、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。 - パーティションの上限: パーティション範囲分割のパーティション列の最大値を指定します。 この値は、テーブル内の行をフィルター処理するためではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果のすべての行がパーティション分割され、コピーされます。
- パーティションの下限: パーティション範囲分割のパーティション列の最小値を指定します。 この値は、テーブル内の行をフィルター処理するためではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果のすべての行がパーティション分割され、コピーされます。
-
パーティション列名: 並列コピーの範囲パーティション分割で使用されるソース列の名前 整数型または date/date time 型 (
追加の列: ソース ファイルの相対パスまたは静的な値を格納するデータ列を追加します。 後者では式がサポートされています。 詳細については、「コピー中に列を追加する」を参照してください。


行き先
コピー アクティビティの [変換先] タブの Azure SQL Database では、次のプロパティがサポートされています。
[宛先] タブを示す 
必要なプロパティは次のとおりです :
- 接続: 接続の一覧から Azure SQL Database 接続を選択します。 接続が存在しない場合は、[新規] を選択して新しい Azure SQL Database 接続を作成します。
- 接続の種類: Azure SQL Databaseを選択します。
- テーブル: ドロップダウン リストからデータベース内のテーブルを選択します。 または、[ 編集] をオンにして、テーブル名を手動で入力します。
- データのプレビュー: プレビュー データ を選択して、テーブル内のデータをプレビューします。
[詳細設定 で、次のフィールドを指定できます。
書き込み動作: ソースがファイル ベースのデータ ストアのファイルである場合の書き込み動作を定義します。 [挿入]、[アップサート]、または [ストアド プロシージャ] を選択できます。

挿入: ソース データに挿入がある場合は、このオプションを選択します。
Upsert: ソース データに挿入と更新の両方がある場合は、このオプションを選択します。
TempDBを使用する: アップサートの中間テーブルとしてグローバル一時テーブルと物理テーブルのどちらを使用するかを指定します。 既定では、サービスは中間テーブルとしてグローバル一時テーブルを使用し、このチェック ボックスがオンになっています。
![[TempDBの使用を選択]を示すスクリーンショット。](media/connector-azure-sql-database/use-tempdb.png)
ユーザー DB スキーマの選択: TempDB を使用する] チェック ボックスがオンになっていない場合は、物理テーブルを使用する場合に中間テーブルを作成するための中間スキーマを指定します。
手記
テーブルを作成および削除するためのアクセス許可が必要です。 既定では、中間テーブルは宛先テーブルと同じスキーマを共有します。
[TempDB の使用] が選択されていないことを示すスクリーンショット
キー列: 一意の行識別の列名を指定します。 1 つのキーまたは一連のキーを使用できます。 指定しない場合は、主キーが使用されます。
ストアド プロシージャ: ソース データをターゲット テーブルに適用する方法を定義するストアド プロシージャを使用します。 このストアド プロシージャはバッチごとに呼び出されます。
ストアド プロシージャ名: ソース テーブルからデータを読み取る [ の編集] ボックスをオンにするときに、ストアド プロシージャを選択するか、ストアド プロシージャ名を手動で指定します。
ストアド プロシージャ パラメーター: ストアド プロシージャ パラメーターの値を指定します。 使用できる値は、名前または値のペアです。 パラメーターの名前と大文字と小文字の区別は、ストアド プロシージャ パラメーターの名前と大文字と小文字の区別と一致する必要があります。
[一括挿入テーブル ロック]: [はい] または [いいえ] を選択します。 この設定を使用して、複数のクライアントからのインデックスがないテーブルに対する一括挿入操作中のコピーのパフォーマンスを向上させます。 詳細については、BULK INSERT(Transact-SQL) を参照してください。
テーブル オプション: ソース スキーマに基づいてテーブルが存在しない場合 、変換先テーブルを自動的に作成 するかどうかを指定します。 [なし] または [テーブルの自動作成] を選択します。 変換先でストアド プロシージャが指定されている場合、テーブルの自動作成はサポートされません。
コピー前スクリプト: 各実行のコピー先テーブルにデータを書き込む前に、コピー アクティビティを実行するスクリプトを指定します。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。
バッチの書き込みタイムアウト: バッチ挿入操作がタイムアウトするまでの待機時間を指定します。使用できる値は timespan です。 既定値は "00:30:00" (30 分) です。
バッチ サイズの書き込み: バッチごとに SQL テーブルに挿入する行数を指定します。 使用できる値は整数 (行数) です。 既定では、サービスは行サイズに基づいて適切なバッチ サイズを動的に決定します。
最大コンカレント接続: アクティビティの実行中にデータ ストアに確立される同時接続の上限を指定します。 同時接続を制限する場合にのみ値を指定します。
パフォーマンス メトリック分析を無効にする: この設定は、コピーのパフォーマンスの最適化と推奨事項のために、DTU、DWU、RU などのメトリックを収集するために使用されます。 この動作に関心がある場合は、このチェック ボックスをオンにします。
マッピング
[マッピング] タブの構成で、自動生成テーブル付きの Azure SQL Database を宛先として適用しない場合は、[マッピング] に移動します。
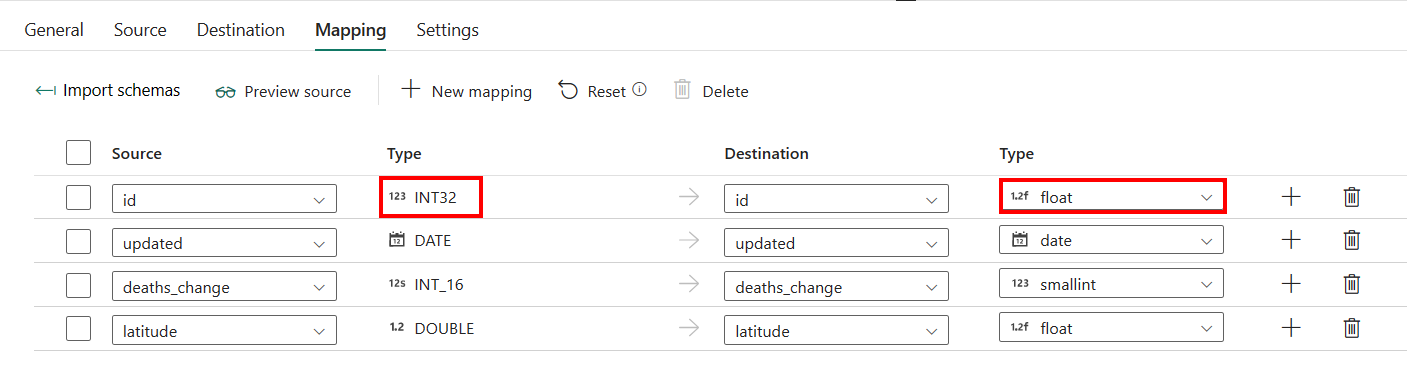
マッピングの構成を除き、Azure SQL Database で「自動作成テーブル」を使用する場合は、ターゲットの列の型を編集することができます。 インポート スキーマを選択した後、変換先で列の種類を指定できます。
たとえば、ソースの列 ID の型は int であり、変換先の列にマッピングするときに float 型に変更できます。
設定
設定 タブの構成については、設定タブのの下で他の設定を構成するに移動します。
Azure SQL Database のデータ型のマッピング
Azure SQL Database からデータをコピーする場合、次のマッピングが Azure SQL Database データ型からサービスによって内部的に使用される中間データ型に使用されます。
| Azure SQL Database のデータ型 | 中間サービス データ型 |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | ブール値 |
| char | String、Char[] |
| date | DateTime |
| 日時 | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM 属性(varbinary(max)) | Byte[] |
| Float | Double |
| イメージ | Byte[] |
| 整数 (int) | Int32 |
| money | Decimal |
| nchar | String、Char[] |
| ntext | String、Char[] |
| 数値 | Decimal |
| nvarchar(エヌヴァーチャー) | String、Char[] |
| real | シングル |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| smallint(スモールイント) | Int16 |
| 少額のお金 | Decimal |
| sql_variant | Object |
| SMS 送信 | String、Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| tinyint | Byte |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | String、Char[] |
| XML | 糸 |
手記
10 進の中間型にマップされるデータ型の場合、コピー アクティビティでは、現在、最大 28 の有効桁数がサポートされています。 28 よりも大きな有効桁数のデータがある場合は、SQL クエリで文字列に変換することを検討してください。
Azure SQL Database からの並列コピー
コピー アクティビティの Azure SQL Database コネクタでは、データを並列にコピーするための組み込みのデータ パーティション分割が提供されます。 データのパーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
パーティションコピーを有効にすると、コピー アクティビティによって Azure SQL Database ソースに対して並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、[コピー アクティビティの設定] タブで コピーの並列処理の次数によって制御されます。たとえば、コピー並列処理の次数 を 4 に設定すると、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成および実行され、各クエリによって Azure SQL Database からデータの一部が取得されます。
特に Azure SQL Database から大量のデータを読み込む場合は、データ パーティション分割を使用して並列コピーを有効にすることをお勧めします。 さまざまなシナリオで推奨される構成を次に示します。 ファイル ベースのデータ ストアにデータをコピーする場合は、フォルダーに複数のファイルとして書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、パフォーマンスは 1 つのファイルに書き込むよりも優れています。
パーティション オプションを使用してデータを読み込むベスト プラクティス:
- データスキューを回避するために、パーティション列として固有の列 (主キーや一意キーなど) を選択します。
- テーブルに組み込みのパーティションがある場合は、パフォーマンスを向上させるために、テーブル の物理パーティション パーティション オプションを使用します。
物理パーティションを確認するサンプル クエリ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
テーブルに物理パーティションがある場合は、次のように "HasPartition" が "yes" と表示されます。

テーブルの概要
次の表に、Azure SQL Database のコピー アクティビティの詳細を示します。
ソース
| 名前 | 説明 | 価値 | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| 接続 | ソース データ ストアへの接続。 | <使用している接続> | はい | 接続 |
| 接続の種類 | 接続の種類。 Azure SQL Databaseを選択します。 | Azure SQL データベース | はい | / |
| テーブル | 使用しているソース データ テーブル。 | <コピー先テーブルの名前> | はい | スキーマ テーブル |
| クエリ を使用する | データを読み取るカスタム SQL クエリ。 | •何一つ •クエリ • ストアド プロシージャ |
いいえ | • sqlReaderQuery • sqlReaderStoredProcedureName、storedProcedureParameters |
| クエリ タイムアウト | クエリ コマンドの実行のタイムアウト。既定値は 120 分です。 | timespan | いいえ | queryTimeout |
| 分離レベル | SQL ソースのトランザクション ロック動作を指定します。 | •何一つ • ReadCommitted • ReadUncommitted(リードアンコミット) • RepeatableRead (リピート可能な読み取り) • シリアライズ可能 •スナップショット |
いいえ | 分離レベル (isolationLevel) |
| パーティション オプション | Azure SQL Database からデータを読み込むのに使用されるデータ パーティション分割オプション。 | •何一つ • テーブルの物理パーティション • ダイナミック レンジ |
いいえ | パーティションオプション • PhysicalPartitionsOfTable (フィジカルパーティションズオブテーブル) • DynamicRange |
| 追加の列 | ソース ファイルの相対パスまたは静的値を格納するデータ列を追加します。 後者では式がサポートされています。 | •名前 •価値 |
いいえ | additionalColumns: •名前 •価値 |
行き先
| 名前 | 説明 | 価値 | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| 接続 | コピー先データ ストアへの接続。 | <使用している接続> | はい | 接続 |
| 接続の種類 | 接続の種類。 Azure SQL Databaseを選択します。 | Azure SQL データベース | はい | / |
| テーブル | あなたの宛先データテーブル。 | <コピー先テーブルの名前> | はい | スキーマ テーブル |
| 書き込み動作 | ソースがファイル ベースのデータ ストアのファイルである場合の書き込み動作を定義します。 | •挿入する • アップサート • ストアド プロシージャ |
いいえ | writeBehavior: •挿入する • アップサート (upsert) • sqlWriterStoredProcedureName、sqlWriterTableType、storedProcedureParameters |
| 一括挿入テーブルのロック | この設定を使用して、複数のクライアントからのインデックスがないテーブルに対する一括挿入操作中のコピーのパフォーマンスを向上させます。 | イエスかノーか答えてください | いいえ | sqlWriterUseTableLock: 真または偽 |
| テーブル オプション | ソース スキーマに基づいてターゲット テーブルが存在しない場合に、そのテーブルを自動的に作成するかどうかを指定します。 | •何一つ • テーブルの自動作成 |
いいえ | tableOption: • 自動作成 |
| コピー前スクリプト | 各実行のコピー先テーブルにデータを書き込む前に実行するコピー アクティビティのスクリプト。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。 |
<コピー前スクリプト> (文字列) |
いいえ | preCopyScript |
| バッチ タイムアウト を書き込む | バッチ挿入操作が終了してからタイムアウトするまでの待機時間。使用できる値は timespan です。 既定値は "00:30:00" (30 分) です。 | timespan | いいえ | writeBatchTimeout |
| 書き込みバッチ サイズ | バッチごとに SQL テーブルに挿入する行数。 既定では、サービスは行サイズに基づいて適切なバッチ サイズを動的に決定します。 |
<行数> (整数) |
いいえ | writeBatchSize |
| 最大同時接続数 | アクティビティの実行中にデータ ストアに確立される同時接続の上限。 同時接続を制限する場合にのみ値を指定します。 | 同時接続の上限 <> (整数) |
いいえ | 最大同時接続数 |
| パフォーマンス メトリック分析 を無効にする | この設定は、コピーのパフォーマンスの最適化と推奨事項のために、DTU、DWU、RU などのメトリックを収集するために使用されます。 この動作に関心がある場合は、このチェック ボックスをオンにします。 | 選択または選択解除 | いいえ | disableMetricsCollection: 真または偽 |
関連コンテンツ
- Azure SQL Database 接続 を設定する