このチュートリアルでは、セマンティック モデル (Power BI データセット) として格納されている Power BI アナリストによる作業を基に構築します。 Microsoft Fabric の Synapse Data Science エクスペリエンスで SemPy (プレビュー) を使用して、DataFrame 列の機能依存関係を分析します。 この分析は、微妙なデータ品質の問題を検出して、より正確な分析情報を得るのに役立ちます。
このチュートリアルでは、次の方法を学習します。
- ドメインの知識を応用して、セマンティック モデル内の機能依存関係に関する仮説を立てる。
- Power BI と統合され、データ品質分析の自動化に役立つセマンティック リンクの Python ライブラリ (SemPy) のコンポーネントについて理解します。 コンポーネントには以下が含まれます。
- FabricDataFrame - 追加のセマンティック情報で強化された pandas のような構造
- Fabric ワークスペースからノートブックにセマンティック モデルをプルする関数
- 関数の依存関係の仮説を評価し、セマンティック モデルのリレーションシップ違反を特定する関数
前提条件
Microsoft Fabric サブスクリプションを取得します。 または、無料のMicrosoft Fabric試用版にサインアップしてください。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して Fabric に切り替えます。
ナビゲーション ウィンドウから [ワークスペース ] を選択して、ワークスペースを検索して選択します。 このワークスペースが現在のワークスペースになります。
Fabric-samples GitHub リポジトリから Customer Profitability Sample.pbix ファイルをダウンロードします。
ワークスペースで、[インポート]>[レポートまたはページ割り付けレポート]>[このコンピューターから] を選択し、Customer Profitability Sample.pbix ファイルをワークスペースにアップロードします。
ノートブックで作業を進める
このチュートリアルには、powerbi_dependencies_tutorial.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付けたい場合は、新しいノートブックを作成できます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
ノートブックを設定する
必要なモジュールとデータを使用してノートブック環境を設定します。
%pipを使用して、ノートブックに PyPI から SemPy をインストールします。%pip install semantic-link必要なモジュールをインポートします。
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
データを読み込んで前処理する
このチュートリアルでは、標準的なサンプル セマンティック モデル Customer Profitability Sample.pbixを使用します。 セマンティック モデルの説明については、Power BI のお客様の収益性のサンプルに関する記事を参照してください。
FabricDataFrame関数を使用して Power BI データをfabric.read_tableに読み込みます。dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()StateテーブルをFabricDataFrameに読み込みます。state = fabric.read_table(dataset, "State") state.head()出力は pandas DataFrame のように見えますが、このコードは pandas の上に操作を追加する
FabricDataFrameと呼ばれるデータ構造を初期化します。customerのデータ型を確認します。type(customer)出力は、
customerがsempy.fabric._dataframe._fabric_dataframe.FabricDataFrameされていることを示しています。customerオブジェクトとstateDataFrameオブジェクトを結合します。customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
機能依存関係を特定する
関数型依存関係は、 DataFrame内の 2 つ以上の列の値間の一対多リレーションシップです。 これらのリレーションシップを使用して、データ品質の問題を自動的に検出します。
結合された
find_dependenciesで SemPy のDataFrame関数を実行して、列値間の機能依存関係を識別します。dependencies = customer_state_df.find_dependencies() dependenciesSemPy の
plot_dependency_metadata関数を使用して依存関係を視覚化します。plot_dependency_metadata(dependencies)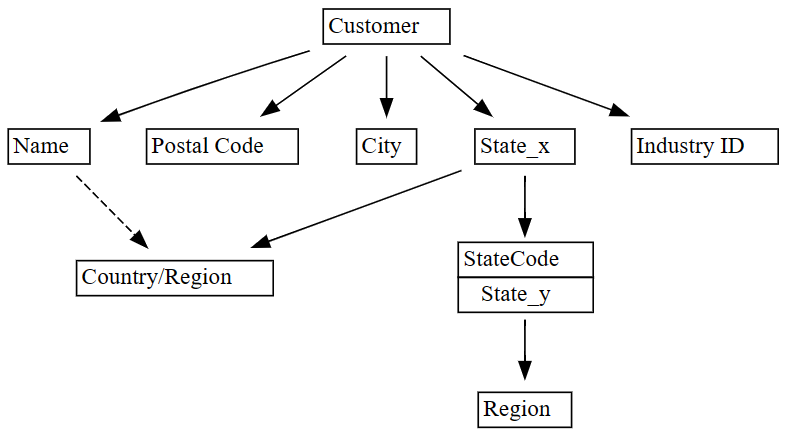
機能依存関係グラフは、
Customer列がCity、Postal Code、Nameなどの列を決定することを示しています。グラフには、列間のリレーションシップに多くの違反があるため、
CityとPostal Codeの間の機能的な依存関係は表示されません。 SemPy のplot_dependency_violations関数を使用して、特定の列間の依存関係違反を視覚化します。

品質の問題についてデータを調べる
SemPy の
plot_dependency_violations視覚化関数を使用してグラフを描画します。customer_state_df.plot_dependency_violations('Postal Code', 'City')
依存関係違反のプロットには、左側の
Postal Codeの値と右側のCityの値が表示されます。 この 2 つの値を含む行がある場合、エッジは左側のPostal Codeと右側のCityを接続します。 エッジには、そのような行の数を示す注釈が付けられています。 たとえば、郵便番号が 20004 の行が 2 つあり、そのうちの 1 つの市が "North Tower" で、もう 1 つの市が "Washington" です。プロットには、いくつかの違反と多数の空の値も表示されます。
Postal Codeの空値の数を確認します。customer_state_df['Postal Code'].isna().sum()Postal Codeの場合、50 行に NA があります。空値がある行を削除します。 次に、
find_dependencies関数を使用して依存関係を確認します。 追加のパラメーターverbose=1に注目してください。これを使用すると、SemPy の内部動作を見ることができます。customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Postal CodeとCityの条件付きエントロピは 0.049 です。 この値は、機能依存関係の違反があることを示します。 違反を修正する前に、依存関係を確認するために、条件付きエントロピのしきい値を既定値の0.01から0.05に引き上げます。 しきい値を小さくすると、依存関係が少なくなります (つまり、選択度が高くなります)。条件付きエントロピのしきい値を既定値の
0.01から0.05に上げます。plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))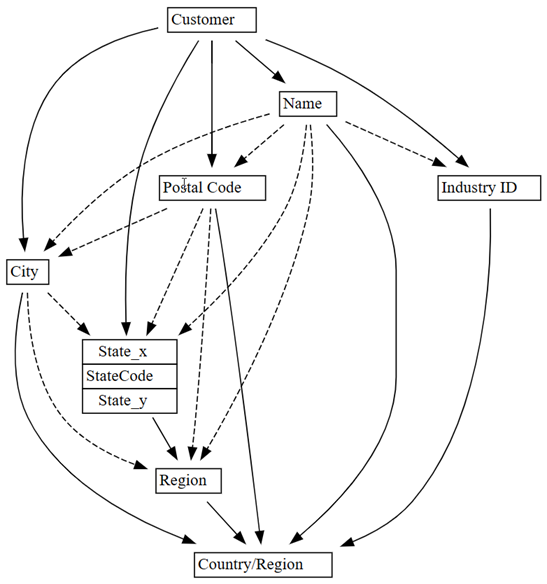
他のエンティティの値を決定するエンティティに関するドメイン知識を適用すると、この依存関係グラフは正確に見えます。
検出されたデータ品質の問題をさらに詳しく調べます。 たとえば、
CityとRegionを結合している破線の矢印は、依存関係が近似的であることを示します。 この近似的なリレーションシップは、部分的な機能依存関係があることを意味する可能性があります。customer_state_df.list_dependency_violations('City', 'Region')空でない
Region値が違反の原因となる各ケースを詳しく見てみましょう。customer_state_df[customer_state_df.City=='Downers Grove']結果は、イリノイ州とネブラスカ州のダウナーズグローブ市を示しています。 しかし、ダウナーズグローブは イリノイ州の都市であり、ネブラスカ州ではありません。
Fremont 市を見てみましょう。
customer_state_df[customer_state_df.City=='Fremont']California 州に Fremont という市があります。 ただし、Texas 州の場合、検索エンジンは Fremont ではなく Premont を返します。
また、依存関係違反の元のグラフの点線で示されているように (空の値を持つ行を削除する前)、
NameとCountry/Regionの間に見られる依存関係の違反も疑わしいです。customer_state_df.list_dependency_violations('Name', 'Country/Region')1 人の顧客である SDI デザインが、米国とカナダの 2 つのリージョンに表示されます。 このケースはセマンティック違反ではなく、一般的ではない可能性があります。 それでも、よく見る価値があります。
顧客 の SDI 設計を詳しく確認しましょう。
customer_state_df[customer_state_df.Name=='SDI Design']さらに検査を行うと、同じ名前の異なる業界の 2 つの異なる顧客が表示されます。

探索的データ分析とデータクリーニングは反復的です。 何を見つけるかは、質問と視点によって異なります。 セマンティック リンクを使用すると、データからさらに多くを得るための新しいツールが提供されます。
関連コンテンツ
セマンティック リンクと SemPy については、他のチュートリアルを参照してください。