このチュートリアルでは、Jupyter ノートブックを使用して Power BI と対話し、SemPy ライブラリを使用してテーブル間のリレーションシップを検出する方法について説明します。
このチュートリアルでは、以下の内容を学習します。
- セマンティック リンクの Python ライブラリ (SemPy) を使用して、セマンティック モデル (Power BI データセット) 内のリレーションシップを検出します。
- Power BI と統合し、データ品質分析を自動化する SemPy コンポーネントを使用します。 コンポーネントには、次が含まれます。
-
FabricDataFrame- セマンティック情報で強化された pandas のような構造 - Fabric ワークスペースからノートブックにセマンティック モデルをプルする関数
- 関数の依存関係をテストし、セマンティック モデルのリレーションシップ違反を識別する関数
-
前提条件
Microsoft Fabric サブスクリプションを取得します。 無料の Microsoft Fabric 試用版 にサインアップするか。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して Fabric に切り替えます。
ナビゲーション ウィンドウで [ワークスペース] に移動し、ワークスペースを選択して現在のワークスペースとして設定します。
Fabric-samples GitHub リポジトリから Customer Profitability Sample.pbix と Customer Profitability Sample (auto).pbix セマンティック モデルをダウンロードし、ワークスペースにアップロードします。
ノートブックで作業を進める
powerbi_relationships_tutorial.ipynb ノートブックを使用して操作を進めます。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付けたい場合は、新しいノートブックを作成することができます
。 コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
ノートブックを設定する
必要なモジュールとデータを使用してノートブック環境を設定します。
ノートブックの
semantic-linkインライン コマンドを使用して、PyPI から%pipパッケージをインストールします。%pip install semantic-link後で使用する
sempyモジュールをインポートします。import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationspandasライブラリをインポートし、出力書式の表示オプションを設定します。import pandas as pd pd.set_option('display.max_colwidth', None)
## Explore semantic models
This tutorial uses the Customer Profitability Sample semantic model [_Customer Profitability Sample.pbix_](https://github.com/microsoft/fabric-samples/blob/main/docs-samples/data-science/datasets/Customer%20Profitability%20Sample.pbix). Learn about the semantic model in [Customer Profitability sample for Power BI](/power-bi/create-reports/sample-customer-profitability).
- Use SemPy's `list_datasets` function to explore semantic models in your current workspace:
```python
fabric.list_datasets()
このノートブックの残りの部分では、2 つのバージョンの Customer Profitability Sample セマンティック モデルを使用します。
- 顧客の収益性のサンプル: Power BI サンプルで提供されているセマンティック モデルと定義済みのテーブル リレーションシップ
- 顧客の収益性のサンプル (自動): 同じデータですが、リレーションシップは Power BI が自動検出するデータに限定されます
サンプル セマンティック モデルから定義済みのリレーションシップを抽出する
SemPy の
list_relationships関数を使用して、Customer Profitability Sample セマンティック モデルに定義済みのリレーションシップを読み込みます。 この関数は、テーブル オブジェクト モデル (TOM) のリレーションシップを一覧表示します。dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsSemPy の
relationships関数を使用して、plot_relationship_metadataDataFrame をグラフとして視覚化します。plot_relationship_metadata(relationships)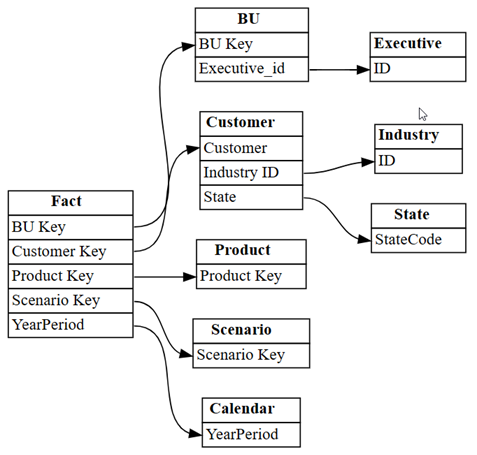
このグラフは、対象分野の専門家によって Power BI で定義されている、このセマンティック モデル内のテーブル間のリレーションシップを示しています。

追加のリレーションシップを検出する
Power BI が自動検出するリレーションシップから始めると、セットが小さくなります。
セマンティック モデルで Power BI によって自動検出されたリレーションシップを視覚化します:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)
Power BI の自動検出では、多くのリレーションシップが失われます。 また、自動検出された 2 つのリレーションシップは意味的に正しくありません。
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
リレーションシップをテーブルとして出力します:
autodetected行 3 と 4 は、
Industryテーブルとの間違ったリレーションシップを示しています。 これらの行を削除します。誤って識別されたリレーションシップを破棄します。
# Remove rows 3 and 4 which point incorrectly to Industry[ID] autodetected = autodetected[~autodetected.index.isin([3, 4])]これで、正しいが不完全なリレーションシップが作成されました。
plot_relationship_metadataを使用して、これらの不完全なリレーションシップを視覚化します。plot_relationship_metadata(autodetected)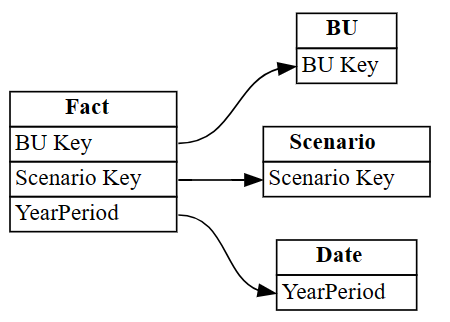
SemPy の
list_tables関数とread_table関数を使用してセマンティック モデルからすべてのテーブルを読み込み、find_relationshipsを使用してテーブル間のリレーションシップを見つけます。 ログ出力を確認して、この関数のしくみに関する分析情報を取得します。suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )新しく検出されたリレーションシップを視覚化する:
plot_relationship_metadata(suggested_relationships_all)
SemPy はすべてのリレーションシップを検出します。
excludeパラメーターを使用して、以前に識別されなかった追加のリレーションシップに検索を制限します:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



リレーションシップを検証する
まず、 顧客収益性サンプル セマンティック モデルからデータを読み込みます。
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()list_relationship_violations関数と主キーと外部キーの重複を確認します。list_relationships関数の出力をlist_relationship_violationsに渡します。list_relationship_violations(tables, fabric.list_relationships(dataset))その結果、有用な分析情報が明らかになります。 たとえば、
Fact[Product Key]の 7 つの値のいずれかがProduct[Product Key]に存在せず、不足しているキーが50。探索的データ分析とデータクリーニングは反復的です。 学習内容は、質問とデータの探索方法によって異なります。 セマンティック リンクを使用すると、データの操作を増やすのに役立つツールが追加されます。
関連コンテンツ
セマンティック リンクと SemPy に関するその他のチュートリアルを確認します。
\n\n