このチュートリアルでは、セマンティック リンクを使用して、パブリック Synthea データセット内のリレーションシップを検出する方法について説明します。
新しいデータを操作する場合や、既存のデータ モデルを使用せずに作業する場合は、リレーションシップを自動的に検出すると便利です。 このリレーションシップ検出は、次の場合に役立ちます。
- モデルを高レベルで理解し、
- 探索的データ分析中により多くの洞察を得る
- 更新されたデータまたは新規受信データを検証してください
- データをクリーンにします。
リレーションシップが事前にわかっていても、リレーションシップの検索は、データ モデルの理解やデータ品質の問題の特定に役立ちます。
このチュートリアルでは、単純なベースラインの例から始めます。ここでは、3 つのテーブルのみを試して、それらの間の接続を簡単に追跡できるようにします。 次に、より大きなテーブル セットを使用して、より複雑な例を示します。
このチュートリアルでは、以下の内容を学習します。
- Power BI との統合をサポートし、データ分析の自動化に役立つセマンティック リンクの Python ライブラリ (SemPy) のコンポーネントを使用します。 コンポーネントには以下が含まれます。
- FabricDataFrame - 追加のセマンティック情報で強化された pandas のような構造体。
- Fabric ワークスペースからノートブックにセマンティック モデルをプルするための関数。
- セマンティック モデル内のリレーションシップの検出と視覚化を自動化する関数。
- 複数のテーブルと相互依存関係を持つセマンティック モデルのリレーションシップ検出プロセスのトラブルシューティングを行います。
[前提条件]
Microsoft Fabric サブスクリプションを取得します。 または、無料で Microsoft Fabric の試用版にサインアップしてください 。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して Fabric に切り替えます。
- 左側のナビゲーション ウィンドウから [ワークスペース ] を選択して、ワークスペースを見つけて選択します。 このワークスペースが現在のワークスペースになります。
ノートブックで作業を進める
このチュートリアルには 、relationships_detection_tutorial.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付けたい場合は、新しいノートブックを作成できます。
コードを実行する前に、必ずノートブック にラケハウス をアタッチしてください。
ノートブックを設定する
このセクションでは、必要なモジュールとデータを含むノートブック環境を設定します。
ノートブック内の
SemPyインライン インストール機能を使用して PyPI から%pipをインストールします。%pip install semantic-link後で必要になる SemPy モジュールの必要なインポートを実行します。
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )出力の書式設定に役立つ構成オプションを適用するために pandas をインポートします。
import pandas as pd pd.set_option('display.max_colwidth', None)サンプル データをプルします。 このチュートリアルでは、合成医療記録の Synthea データセットを使用します (わかりやすくするために小さいバージョン)。
download_synthea(which='small')
Synthea テーブルの小さなサブセットのリレーションシップを検出する
大きなセットから 3 つのテーブルを選択します。
-
patients患者情報を指定します -
encountersは、医療上の出会いを受けた患者 (医療予約、手順など) を指定します。 -
providersは、どの医療提供者が患者に出席するかを指定します。
encountersテーブルは、patientsとprovidersの間の多対多リレーションシップを解決し、連想エンティティとして記述できます。patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
SemPy の
find_relationships関数を使用してテーブル間のリレーションシップを検索します。suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsSemPy の
plot_relationship_metadata関数を使用して、リレーションシップ DataFrame をグラフとして視覚化します。plot_relationship_metadata(suggested_relationships)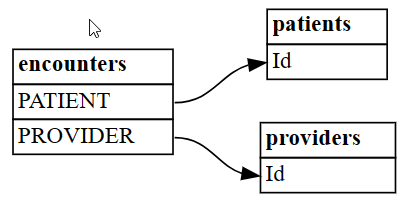
この関数は、リレーションシップ階層を左側から右側にレイアウトします。これは、出力の "from" テーブルと "to" テーブルに対応します。 つまり、左側の独立した "from" テーブルは、右側の "to" 依存関係テーブルを指すために外部キーを使用します。 各エンティティ ボックスには、リレーションシップの "from" または "to" 側に参加する列が表示されます。
既定では、リレーションシップは "m:1" ("1:m" ではなく) または "1:1" として生成されます。 "1:1" リレーションシップは、すべての値に対するマップされた値の比率が一方向または両方向の
coverage_thresholdを超えるかどうかに応じて、一方または両方の方法で生成できます。 このチュートリアルの後半では、"m:m" リレーションシップの頻度が低いケースについて説明します。

リレーションシップの検出に関する問題の解決
ベースラインの例は、クリーンな Synthea データでの正常なリレーションシップ検出を示しています。 実際には、データがクリーンになることはほとんどありません。これにより、検出が成功しません。 データがクリーンでない場合に役立つ手法がいくつかあります。
このチュートリアルのこのセクションでは、セマンティック モデルにダーティ データが含まれている場合のリレーションシップの検出について説明します。
まず、元の DataFrame を操作して "ダーティ" データを取得し、ダーティ データのサイズを出力します。
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))比較のために、元の表の印刷サイズ:
print(len(patients)) print(len(providers))SemPy の
find_relationships関数を使用してテーブル間のリレーションシップを検索します。find_relationships([patients_dirty, providers_dirty, encounters])コードの出力は、前に "ダーティ" セマンティック モデルを作成するために導入したエラーにより、リレーションシップが検出されていないことを示しています。
検証を使用する
検証は、次の理由から、リレーションシップ検出エラーのトラブルシューティングに最適なツールです。
- 特定のリレーションシップが外部キールールに従っていないため、検出できない理由が明確に報告されます。
- 宣言されたリレーションシップのみに焦点を当て、検索を実行しないため、大規模なセマンティック モデルでは高速に実行されます。
検証では、 find_relationshipsによって生成されたものと同様の列を持つ任意の DataFrame を使用できます。 次のコードでは、suggested_relationships DataFrame はpatientsではなくpatients_dirtyを参照しますが、ディクショナリを使用して DataFrame のエイリアスを設定できます。
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
検索条件を緩める
より暗いシナリオでは、検索条件を緩めてみてください。 この方法では、誤検知の可能性が高くなります。
include_many_to_many=True設定し、それが役立つかどうかを評価します。find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)結果は、
encountersからpatientsへの関係が検出されたことを示していますが、次の 2 つの問題があります。- リレーションシップは、
patientsからencountersへの方向を示します。これは、予想されるリレーションシップの逆です。 これは、すべてのpatientsがencounters(Coverage Fromは 1.0) でカバーされ、encountersはpatients(Coverage To= 0.85) の一部しかカバーされていないためです。これは、患者の行がないためです。 - カーディナリティが低い
GENDER列が偶然に一致しています。これは両方のテーブルで名前と値が一致していますが、注目すべき"m:1"リレーションシップではありません。 カーディナリティが低い場合は、Unique Count From列とUnique Count To列によって示されます。
- リレーションシップは、
find_relationshipsを再実行して、"m:1" リレーションシップのみを検索しますが、coverage_threshold=0.5は低くなります。find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)結果は、
encountersからprovidersへのリレーションシップの正しい方向を示しています。 ただし、encountersが一意でないため、patientsからpatientsへのリレーションシップは検出されないため、"m:1" リレーションシップの "一" 側にすることはできません。include_many_to_many=Trueとcoverage_threshold=0.5の両方を緩めます。find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)これで、両方の関心のある関係が可視化されますが、ノイズも多くなっています。
-
GENDERでの低いカーディナリティの一致が存在します。 -
ORGANIZATIONのカーディナリティ "m:m" が高くなったため、ORGANIZATIONが両方のテーブルに対して非正規化された列である可能性が高いことが明らかになりました。
-
列名を一致させる
既定では、SemPy は名前の類似性を示す属性にのみ一致すると見なされます。これは、データベース デザイナーが通常、同じ方法で関連する列に名前を付けるという事実を利用します。 この動作は、カーディナリティの低い整数キーで最も頻繁に発生するスプリアスなリレーションシップを回避するのに役立ちます。 たとえば、製品カテゴリと注文状態コード1,2,3,...,101,2,3,...,10がある場合、列名を考慮せずに値のマッピングのみを調べる場合は、互いに混同されます。 偽のリレーションシップは、GUID に似たキーでは問題になりません。
SemPy では、列名とテーブル名の類似性が確認されます。 照合は概数であり、大文字と小文字は区別されません。 "id"、"code"、"name"、"key"、"pk"、"fk" など、最も頻繁に見つかった "デコレーター" 部分文字列は無視されます。 その結果、最も一般的な一致ケースは次のようになります。
- エンティティ 'foo' の 'column' という属性が、エンティティ 'bar' の 'column' ('COLUMN' または 'Column' とも呼ばれます) と一致します。
- エンティティ 'foo' の 'column' という属性が、'bar' の 'column_id' という属性と一致します。
- エンティティ 'foo' の 'bar' という属性が、'bar' の 'code' という属性と一致します。
列名を最初に照合すると、検出の実行速度が速くなります。
列名を一致させてください。
- さらに評価するためにどの列が選択されているかを理解するには、
verbose=2オプションを使用します (verbose=1は、処理中のエンティティのみを一覧表示します)。 -
name_similarity_thresholdパラメーターは、列の比較方法を決定します。 しきい値 1 は、100% 一致のみに関心があることを示します。
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);100% の類似度で実行すると、名前間の小さな違いを考慮に入れることができません。 この例では、テーブルは "s" サフィックスを持つ複数形を持ち、完全に一致しません。 これは、既定の
name_similarity_threshold=0.8で適切に処理されます。- さらに評価するためにどの列が選択されているかを理解するには、
既定の
name_similarity_threshold=0.8を使用して再実行します。find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);複数形の
patientsの ID が、実行時間に他のスプリアスな比較を追加しすぎることなく、単数形のpatientと比較されるようになったことに注意してください。既定の
name_similarity_threshold=0を使用して再実行します。find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);name_similarity_thresholdを 0 に変更することはもう 1 つの極端なものであり、すべての列を比較することを示します。 これはほとんど必要なく、実行時間が長くなり、レビューが必要なスプリアスな一致が発生します。 詳細出力内の比較の数を確認します。
トラブルシューティングのヒントの概要
- "m:1" リレーションシップ (つまり、既定の
include_many_to_many=Falseとcoverage_threshold=1.0) の完全一致から開始します。 これは通常、望ましいものです。 - テーブルの小さなサブセットに狭いフォーカスを使用します。
- 検証を使用して、データ品質の問題を検出します。
- リレーションシップと見なされる列を理解する場合は、
verbose=2を使用します。 これにより、大量の出力が発生する可能性があります。 - 検索引数のトレードオフに注意してください。
include_many_to_many=Trueとcoverage_threshold<1.0は、分析が難しい可能性があり、フィルター処理する必要があるスプリアスなリレーションシップを生成する可能性があります。
完全な Synthea データセットのリレーションシップを検出する
簡単なベースラインの例は、便利な学習およびトラブルシューティング ツールでした。 実際には、より多くのテーブルを持つ完全な Synthea データセットなどのセマンティック モデルから開始できます。 次のように、完全な 合成 データセットを調べる。
synthea/csv ディレクトリからすべてのファイルを読み取ります。
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }SemPy の
find_relationships関数を使用して、テーブル間のリレーションシップを検索します。suggested_relationships = find_relationships(all_tables) suggested_relationshipsリレーションシップを視覚化する:
plot_relationship_metadata(suggested_relationships)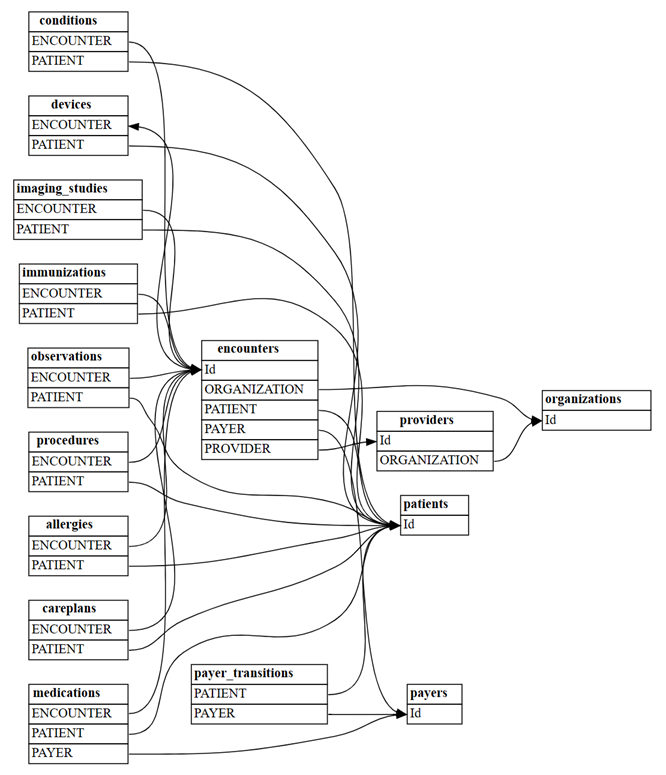
include_many_to_many=Trueで検出される新しい "m:m" リレーションシップの数をカウントします。 これらのリレーションシップは、前に示した "m:1" リレーションシップに加えて表示されます。そのため、multiplicityでフィルター処理する必要があります。suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']リレーションシップ データをさまざまな列で並べ替えて、その性質をより深く理解することができます。 たとえば、最大のテーブルを識別するのに役立つ
Row Count FromとRow Count Toで出力を並べ替える場合があります。suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)別のセマンティック モデルでは、null
Null Count FromまたはCoverage Toの数に焦点を当てることが重要な場合があります。この分析は、いずれかのリレーションシップが無効である可能性があるかどうか、および候補の一覧から削除する必要があるかどうかを理解するのに役立ちます。

関連コンテンツ
セマンティック リンク/SemPy については、他のチュートリアルを参照してください。