このチュートリアルは、レイクハウスを作成し、それを操作するための基本的な方法を開始するためのクイック ガイドです。 このチュートリアルを完了すると、Microsoft Fabric 内に Lakehouse がプロビジョニングされ、OneLake 上で作業できるようになります。
レイクハウスを作成する
Microsoft Fabric にサインインします。
左側のメニューから [ワークスペース] を選択します。
ワークスペースを開くには、上部にある [検索テキスト ボックス] にその名前を入力し、検索結果から選択します。
ワークスペースのホームページの左上隅にある「新しいアイテム」を選択し、「データを保存」のセクションから「Lakehouse」を選びます。
レイクハウスに名前を付け、[作成] を選択します。
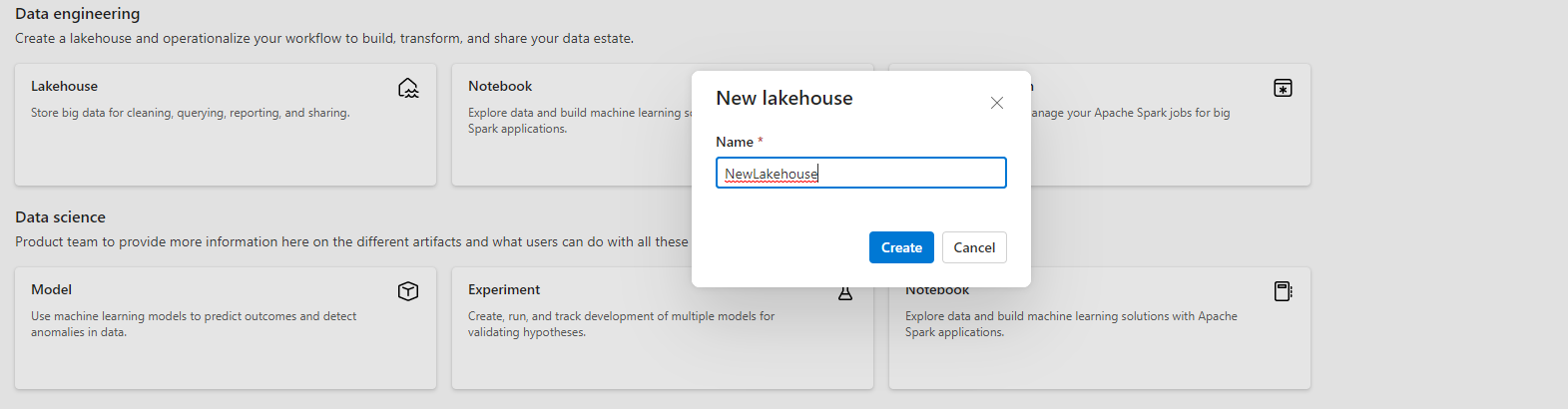
新しいレイクハウスが作成され、このレイクハウスが最初の OneLake アイテムである場合、OneLake はバックグラウンドでプロビジョニングされます。

現時点で、OneLake の上にレイクハウスが稼働しています。 次に、データを追加し、レイクの整理を開始します。
レイクハウスにデータを読み込む
左側のファイルブラウザーで、ファイル の横にあるその他のオプション ([ ...]) を選択し、新しいサブフォルダーを選択します。 サブフォルダーに名前を付け、[作成] を選択します。
![メニューで [新しいサブフォルダー] を選択する場所を示すスクリーンショット。](media/create-lakehouse-onelake/new-subfolder-menu.png)
この手順を繰り返して、必要に応じてサブフォルダーを追加できます。
フォルダーの横にあるその他のオプション ([...]) を選択し、次にメニューから [アップロード]、そして [ファイルのアップロード]> を選択します。
ローカル コンピューターから目的のファイルを選択し、[アップロード] を選択します。
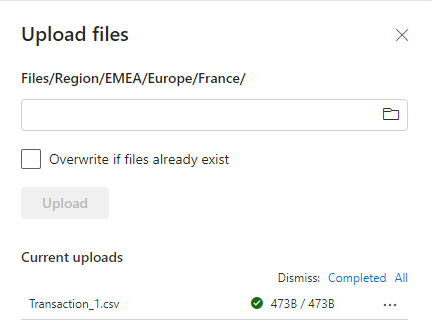
OneLake にデータが追加されました。 OneLake にデータを一括で追加したり、データの読み込みをスケジュールしたりするには、[データの取得] ボタンを使用してパイプラインを作成します。 データを取得するためのオプションの詳細については、「Microsoft Fabric の意思決定ガイド (コピー アクティビティ、データフロー、Spark)」 を参照してください。
アップロードしたファイルのその他のオプション (...) を選択し、メニューから [プロパティ] 選択します。
[プロパティ] 画面には、ノートブックで使用する URL と Azure Blob File System (ABFS) パスなど、ファイルのさまざまな詳細が表示されます。 ABFS を Fabric Notebook にコピーして、Apache Spark を使用してデータのクエリを実行できます。 Fabric のノートブックについて詳しく知るには、「ノートブックを使用して Lakehouse 内のデータを探索する」をご覧ください。
これで、OneLake にデータが格納された最初の Lakehouse が作成されました。
関連するコンテンツ
OneLake ショートカットを使用して既存のデータ ソース接続する方法について説明します。