作成者: Ruslan Yakushev
IIS サイト分析は、検索エンジン クローラー用にサイトのコンテンツ、構造、URL を最適化することを目的とした Web サイト分析に使用できる IIS 検索エンジン最適化ツールキット内のツールです。 さらに、このツールを使用すると、サイトのユーザー エクスペリエンスに悪影響を与えるサイト コンテンツの一般的な問題を検出して修正できます。 IIS サイト分析ツールには、公開されているすべてのサイト リンクとリソースをクロールし、サイト分析に使用されるコンテンツをダウンロードするスパイダーが含まれています。
Web サイトのクロール
Web サイト分析の最初の手順は、サイトによって公開されているすべてのリソースと URL をクロールすることです。 新しいサイト分析を作成するとき、この処理を IIS サイト分析ツールが行います。 IIS サイト分析ツールで Web サイトをクロールし、分析用のデータを収集するには、次の手順に従います。
[スタート] > [プログラム ファイル] > [IIS 7.0 拡張機能] の順に移動して SEO ツールを起動し、[検索エンジン最適化 (SEO) ツールキット] アイコンをクリックします。
[接続] ペインでサーバー ノードを選択します。 SEO のメイン ページが自動的に開きます。
[サイト分析] セクション内の [新しい分析の作成] タスク リンクをクリックします。
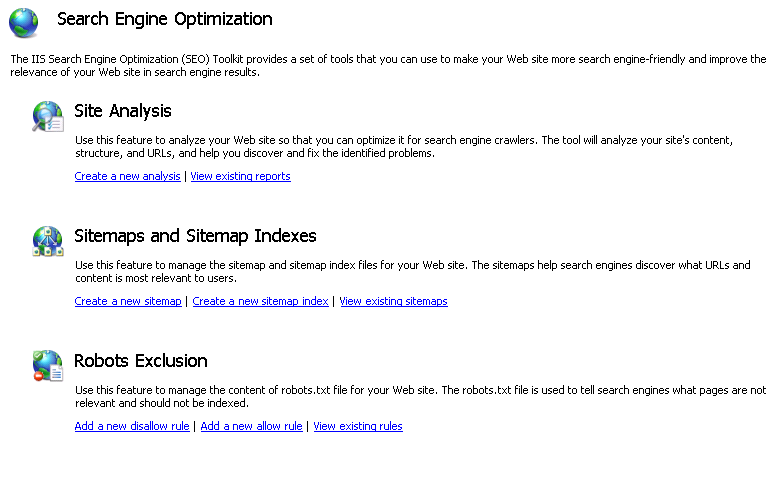
[新しい分析] ダイアログ ボックスで、分析レポートを一意に識別する名前を入力します。 また、クローラーを開始する URL を入力します。
![S E O Toolkit サイト分析ページのスクリーンショット。[新しい分析] ダイアログ ボックスが開いています。](using-site-analysis-to-crawl-a-web-site/_static/image5.png)
[接続] ペインでサーバー ノードが選択されているため (サーバー上の特定の Web サイトを選択するのではなく)、インターネット上でパブリックにアクセスできる任意の Web サイトをクロールできます。 [新しい分析] ダイアログ ボックスの詳細については、「スパイダーの設定」セクションを参照してください。すべてのパラメーターを指定したら、[OK] をクリックして分析を開始します。
![分析の結果を表示する [新しい分析] ダイアログ ボックスのスクリーンショット。](using-site-analysis-to-crawl-a-web-site/_static/image7.png)
分析中に次の 2 つの数値がレポートされます。- [スタート] - スパイダーによってクロールおよびダウンロードされたリンクの合計数です。
- [リンクの合計数] - Web サイトのクロール中に見つかったリンクの合計数です。
Note
スパイダーは常にクライアント コンピューター上で実行されます。 リモート IIS サーバーに接続して新しい分析を開始すると、スパイダーは、そのリモート IIS サーバーに接続されているローカル コンピューター上の IIS マネージャー プロセス (InetMgr.exe) 内でホストされます。 収集されたすべてのデータとキャッシュされた Web コンテンツは、そのローカル クライアント ファイル システムに保持されます。
Web サイトのクロールと分析が完了すると、サイト分析レポートの [概要] ビューが表示されます。 SEO およびコンテンツ固有の問題に関してサイトを分析する方法については、サイト分析レポートの使用方法に関する記事を参照してください。
スパイダーの設定
新しい分析を開始するときに指定できるその他のパラメーターは次のとおりです。
- リンクの最大数 - この設定は、クロール中に Web サイトから処理およびダウンロードされる一意のリンクの数を制御します。 リンクとは、ハイパーリンク、画像ファイルへの参照、css ファイル、javascript ファイルなど、ページのマークアップ内で使用される任意の URL を指します。 この数を増やすと、レポート ファイルのサイズが増え、クロール プロセスの実行時間が長くなります。
- Maximum Download Size per Link (リンクあたりの最大ダウンロード サイズ) - この設定は、リンクごとにダウンロードされるコンテンツのサイズをキロバイト単位で制御します。 この数を増やすと、サイト分析によってローカル ファイル システム上に格納されるキャッシュ コンテンツのサイズが大きくなります。
- Ignore 'nofollow' attribute ('nofollow' 属性を無視) - 'nofollow' 属性と 'nofollow' メタ タグは、そのページ内の特定のハイパーリンクまたはすべてのハイパーリンクに従わないように検索エンジン クローラーに指示するために使用されます。 これは、ブログ コメントのスパムに対する保護の手段です。 サイト上のページでこの属性を使用すると、それらのページのハイパーリンクの処理や分析はサイト分析中に行われません。 画像、css、javascript ファイルなどのリソースへのリンクは引き続き処理されることに注意してください。 この属性を使用するハイパーリンクも分析する必要がある場合は、'nofollow' 属性とメタ タグを無視するためにこの設定を使用します。
- Ignore 'noindex' meta tag ('noindex' メタ タグを無視) - 'noindex' タグは、ページのコンテンツにインデックスを付けないように検索エンジン クローラーに指示するために使用されます。 サイト上のページでこのメタ タグを使用すると、それらのページのコンテンツの違反は検索されなくなります。 この属性を使用するページも分析する必要がある場合は、'noindex' メタ タグを無視するためにこの設定を使用します。
- 外部リンク - このドロップダウン リストは、Web サイトにサブドメインがある場合や、サイト内の特定のディレクトリに対して分析を実行する場合に使用できます。 この設定は、サブドメインやサブディレクトリを外部リンクとして扱うか、内部リンクとして扱うかを制御します。
さらに、[アクション] ペインで [FeatureSettings の編集] を選択することで、スパイダーに対して次の一般的な設定を指定できます。
- 同時要求の最大数 - この設定は、スパイダーによる同時要求の数を制御します。
- レポート ディレクトリ - クロールされたすべてのデータとキャッシュされた Web サイト コンテンツが格納されるローカル ファイル システム上のディレクトリを指定します。
IIS サイト分析スパイダーのブロック
IIS サイト分析スパイダーのすべての HTTP 要求では、HTTP ヘッダーの "user-agent" が次のように設定されています。
"iisbot/1.0 (+http://www.iis.net/iisbot.html)"
IIS サイト分析スパイダーはロボット排除プロトコルに完全に準拠しています。 つまり、Robots.txt ファイルを使用することで、IIS サイト分析スパイダーが Web サイトをクロールしないようにすることができます。 これを使用して、他者が自分の Web サイトに対して IIS サイト分析を実行できないようにすることができます。
IIS サイト分析スパイダーが Web サイトをクロールしないようにするには、サイトのルート ディレクトリにある Robots.txt ファイルの末尾に次の行を追加します。
User-Agent: iisbot
Disallow: /
まとめ
これで、IIS サイト分析ツールで Web サイトをクロールし、サイトのコンテンツと構造に関するデータを収集するための設定が完了しました。 サイト分析レポートを使用して収集されたデータの分析方法については、「サイト分析レポートの使用」を参照してください。