関数kmeans_dynamic_fl()は、k-means アルゴリズムを使用してデータセットをクラスター化する UDF (ユーザー定義関数)です。 この関数は、 kmeans_fl() に似ていますが、複数のスカラー列ではなく、単一の数値配列列によって特徴が提供されるだけです。
前提条件
- Python プラグインは、クラスター 有効にする必要があります。 これは、関数で使用されるインライン Python に必要です。
- Python プラグインは、データベース 有効にする必要があります。 これは、関数で使用されるインライン Python に必要です。
構文
T | invoke kmeans_dynamic_fl(k, features_col, cluster_col)
構文規則について詳しく知る。
パラメーター
| 件名 | タイプ | Required | 説明 |
|---|---|---|---|
| k | int |
✔️ | クラスターの数。 |
| features_col | string |
✔️ | クラスタリングに使用する特徴の数値配列を含む列の名前。 |
| cluster_col | string |
✔️ | 各レコードの出力クラスター ID を格納する列の名前。 |
関数定義
関数を定義するには、次のようにコードをクエリ定義関数として埋め込むか、データベースに格納された関数として作成します。
次の let ステートメントを使用して関数を定義。 権限は必要ありません。
重要
let ステートメント単独では実行できません。 その後に 表形式の式ステートメントが続く必要があります。 kmeans_fl()の作業例を実行するには、サンプルを参照してください。
let kmeans_dynamic_fl=(tbl:(*),k:int, features_col:string, cluster_col:string)
{
let kwargs = bag_pack('k', k, 'features_col', features_col, 'cluster_col', cluster_col);
let code = ```if 1:
from sklearn.cluster import KMeans
k = kargs["k"]
features_col = kargs["features_col"]
cluster_col = kargs["cluster_col"]
df1 = df[features_col].apply(np.array)
matrix = np.vstack(df1.values)
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(matrix)
result = df
result[cluster_col] = kmeans.labels_
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
例
次の例では、 invoke 演算子 を使用して関数を実行します。
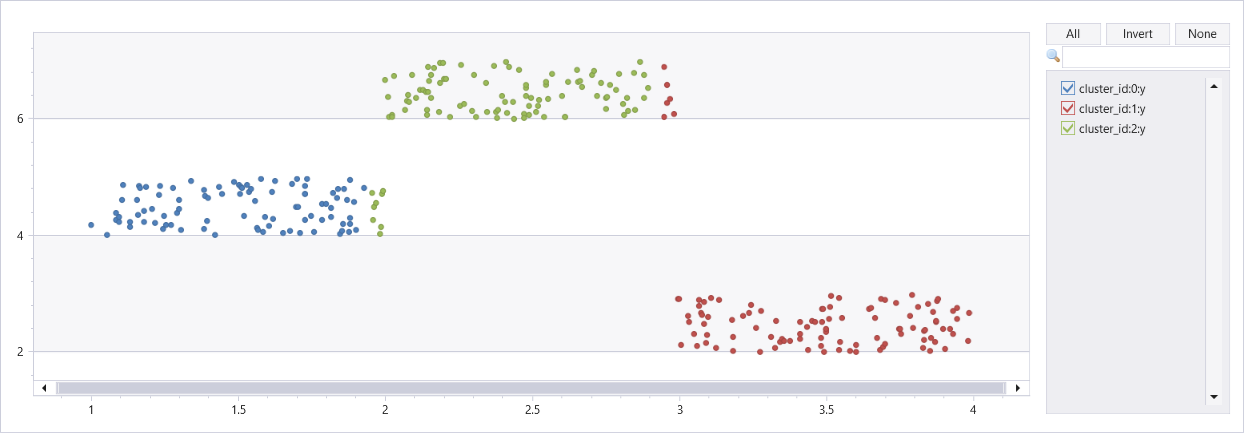
3 つのクラスターを使用した人工データセットのクラスタリング
クエリ定義関数を使用するには、埋め込み関数定義の後に呼び出します。
let kmeans_dynamic_fl=(tbl:(*),k:int, features_col:string, cluster_col:string)
{
let kwargs = bag_pack('k', k, 'features_col', features_col, 'cluster_col', cluster_col);
let code = ```if 1:
from sklearn.cluster import KMeans
k = kargs["k"]
features_col = kargs["features_col"]
cluster_col = kargs["cluster_col"]
df1 = df[features_col].apply(np.array)
matrix = np.vstack(df1.values)
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(matrix)
result = df
result[cluster_col] = kmeans.labels_
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| project Features=pack_array(x, y), cluster_id=int(null)
| invoke kmeans_dynamic_fl(3, "Features", "cluster_id")
| extend x=toreal(Features[0]), y=toreal(Features[1])
| render scatterchart with(series=cluster_id)