適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
クラウド サービスと IoT デバイスは、サービスの正常性の監視、物理的な運用プロセス、使用状況の傾向などの分析情報を得るために使用できるテレメトリ データを生成します。 時系列分析の実行は、一般的なベースライン パターンと比較して、これらのメトリックのパターンの偏差を識別する 1 つの方法です。
Kusto クエリ言語 (KQL) には、複数の時系列の作成、操作、および分析に関するネイティブ サポートが含まれています。 この記事では、KQL を使用して数千の時系列を秒単位で作成および分析し、ほぼリアルタイムの監視ソリューションとワークフローを有効にする方法について説明します。
時系列の作成
このセクションでは、 make-series 演算子を使用して簡単かつ直感的に通常の時系列の大規模なセットを作成し、必要に応じて欠損値を入力します。
時系列分析の最初の手順は、元のテレメトリ テーブルを一連の時系列に分割して変換することです。 通常、テーブルにはタイムスタンプ列、コンテキスト ディメンション、およびオプションのメトリックが含まれます。 ディメンションは、データのパーティション分割に使用されます。 目標は、一定の時間間隔でパーティションごとに数千の時系列を作成することです。
入力テーブル demo_make_series1 には、任意の Web サービス トラフィックの 600,000 レコードが含まれています。 次のコマンドを使用して、10 個のレコードをサンプリングします。
demo_make_series1 | take 10
結果のテーブルには、タイムスタンプ列、3 つのコンテキスト ディメンション列があり、メトリックは含まれていません。
| タイムスタンプ | BrowserVer | OsVer | 国/リージョン |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | イギリス |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | イギリス |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Windows 10 | イギリス |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Windows 10 | リトアニア共和国 |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | インド |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Windows 10 | イギリス |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | オランダ |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Windows 10 | イギリス |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Windows 10 | インド |
メトリックがないため、次のクエリを使用して OS によってパーティション分割された、トラフィック数自体を表す一連の時系列のみを構築できます。
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
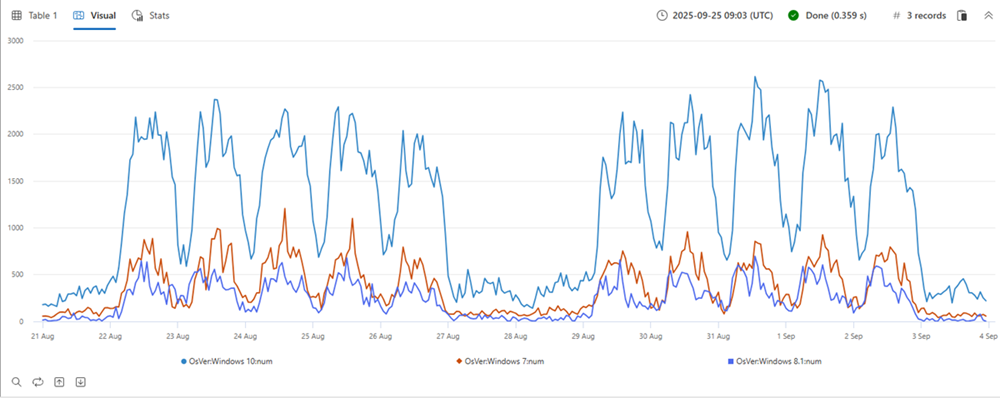
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
-
make-series演算子を使用して、次の 3 つの時系列のセットを作成します。-
num=count(): トラフィックの時系列 -
from min_t to max_t step 1h: 時系列データは、テーブル レコードの最古と最新のタイムスタンプを含む期間において、1時間単位で作成されます。 -
default=0: 欠けているビンの塗りつぶし方法を指定して、規則的な時系列を作成します。 または、変更にseries_fill_const()、series_fill_forward()、series_fill_backward()、series_fill_linear()を使用する -
by OsVer: OS によるパーティション分割
-
- 実際の時系列データ構造は、各タイム ビンごとの集計値の数値配列です。 視覚化には
render timechartを使用します。
上の表では、3 つのパーティションがあります。 グラフに示すように、OS バージョンごとに Windows 10 (赤)、7 (青)、8.1 (緑) の時系列を作成できます。
時系列分析関数
このセクションでは、一般的なシリーズ処理関数を実行します。 一連の時系列が作成されると、KQL はそれらを処理および分析するための関数の増加する一覧をサポートします。 時系列を処理および分析するための代表的な関数をいくつか説明します。
フィルタリング
フィルタリングは、信号処理の一般的な手法であり、時系列処理タスク (ノイズの多い信号のスムーズ化、変更検出など) に役立ちます。
- 次の 2 つの汎用フィルター関数があります。
-
series_fir(): FIR フィルターを適用しています。 変化検出のための時系列の移動平均と差別化の単純な計算に使用されます。 -
series_iir(): IIR フィルターを適用しています。 指数平滑化と累積合計に使用されます。
-
-
Extendサイズ 5 ビンの新しい移動平均系列 ( ma_num という名前) をクエリに追加して設定された時系列。
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart

回帰分析
セグメント化線形回帰分析を使用して、時系列の傾向を推定できます。
- series_fit_line() を使用して、一般的な傾向検出の時系列に最適な線を適合します。
- series_fit_2lines() を使用して、シナリオの監視に役立つベースラインに対する傾向の変化を検出します。
時系列クエリの series_fit_line() 関数と series_fit_2lines() 関数の例:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)
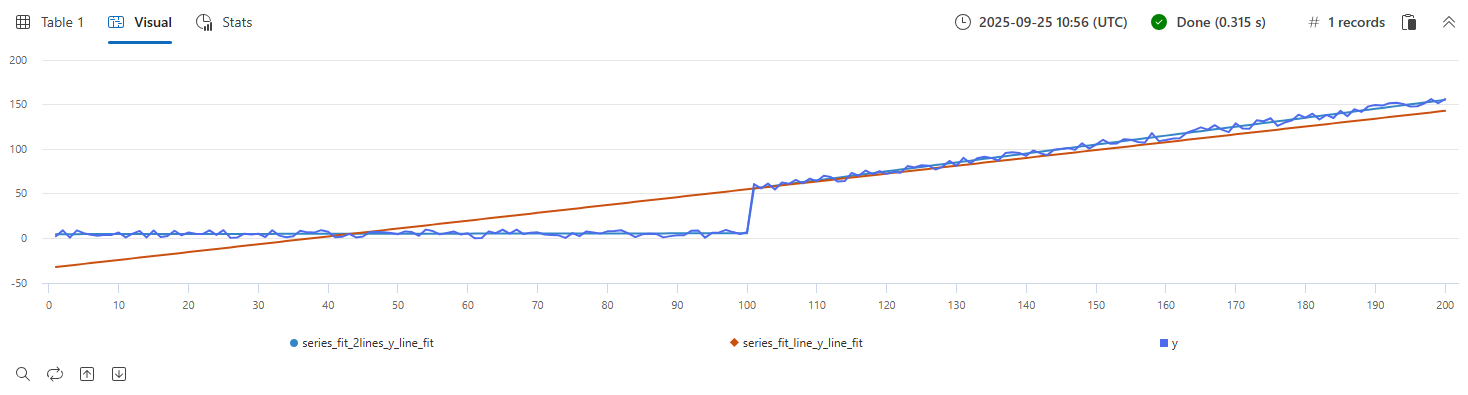
- 青: 元の時系列
- 緑: フィットされたライン
- 赤: フィットした2本の線
注
この関数は、ジャンプ (レベル変更) ポイントを正確に検出しました。
季節性の検出
多くのメトリックは、季節的な (定期的な) パターンに従います。 クラウド サービスのユーザー トラフィックには、通常、営業日の途中で最も高く、夜間と週末に最も低い、毎日および毎週のパターンが含まれます。 IoT センサーは、定期的な間隔で測定します。 温度、圧力、湿度などの物理的な測定値も季節的な動作を示す場合があります。
次の例では、Web サービスの 1 か月のトラフィック (2 時間のビン) に季節性検出を適用します。
demo_series3
| render timechart

-
series_periods_detect() を使用して、時系列内の期間を自動的に検出します。ここで、次のようになります。
-
num: 分析する時系列データ -
0.: 日数の最小期間 (0 は最小を意味しません) -
14d/2h: 最大期間の長さ (日数) (14 日を 2 時間のビンに分割) -
2: 検出する期間の数
-
- メトリックに特定の期間が必要であり、それらが存在することを確認する必要がある場合は、 series_periods_validate() を使用します。
注
特定の異なる期間が存在しない場合は異常です
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| 期間 | スコア | 日 |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
この関数は、毎日および毎週の季節性を検出します。 週末は平日と異なるため、1 日のスコアは週単位よりも少なくなります。
要素ごとの関数
算術演算と論理演算は、時系列で実行できます。 series_subtract() を使用すると、残差時系列 (つまり、元の生メトリックと平滑化されたメトリックの差) を計算し、残差シグナルの異常を探すことができます。
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart
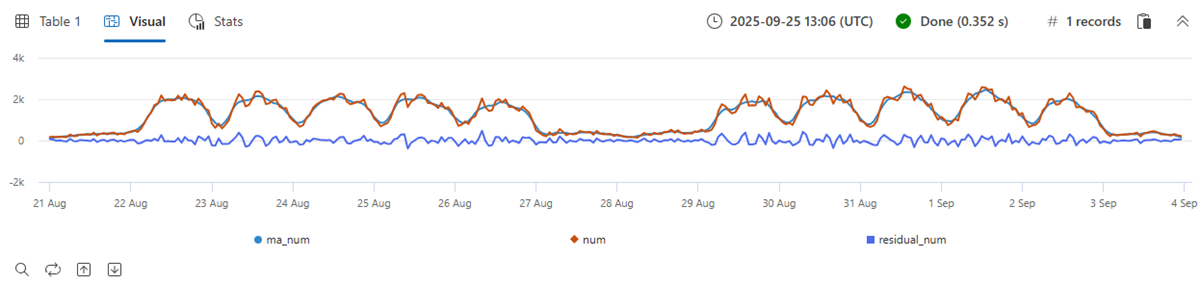
- 青: 元の時系列
- 赤: 平滑化された時系列
- 緑: 残余の時系列
大規模な時系列ワークフロー
次の例は、異常検出のために、これらの関数を数千の時系列で秒単位で大規模に実行する方法を示しています。 DB サービスの読み取りカウント メトリックのサンプル テレメトリ レコードを 4 日間にわたって確認するには、次のクエリを実行します。
demo_many_series1
| take 4
| タイムスタンプ | Loc | Op | DB | DataRead |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
簡単な統計:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| 番号 | min_t | max_t |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
読み取りメトリックの 1 時間ビン (合計 4 日 * 24 時間 = 96 ポイント) で時系列を構築すると、通常のパターンの変動が発生します。
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)
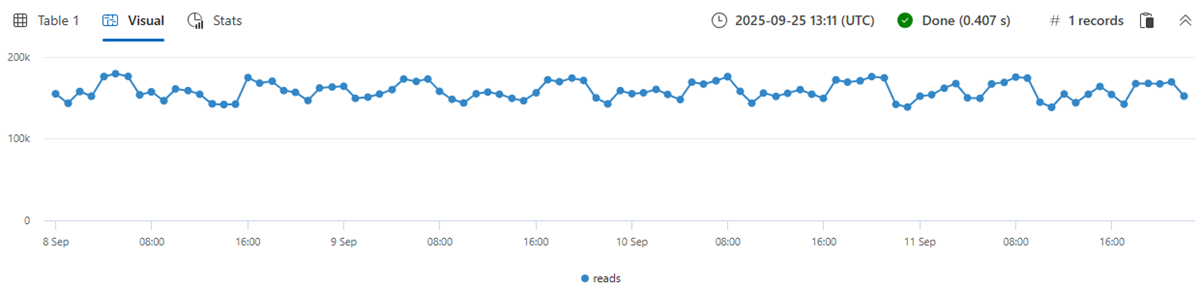
1 つの通常の時系列は、異常なパターンを持つ可能性のある数千の異なるインスタンスから集計されるため、上記の動作は誤解を招きます。 そのため、インスタンスごとに時系列を作成します。 インスタンスは、Loc (location)、Op (operation)、DB (特定のマシン) によって定義されます。
作成できる時系列の数はいくつですか?
demo_many_series1
| summarize by Loc, Op, DB
| count
| 数える |
|---|
| 18339 |
次に、読み取りカウント メトリックの 18339 時系列のセットを作成します。 make-series ステートメントに by 句を追加し、線形回帰を適用し、最も有意な減少傾向を持つ上位 2 つの時系列を選択します。
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
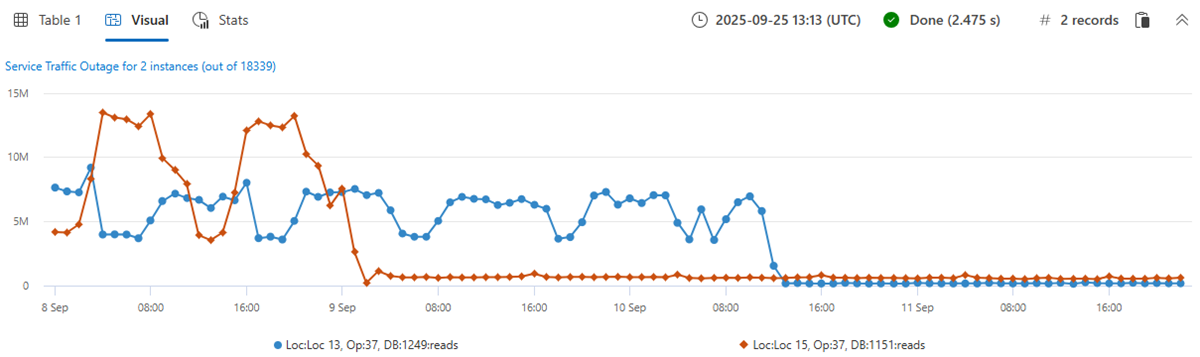
インスタンスを表示します。
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Loc | Op | DB | 坂 |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -102743.910227889 |
| Loc 13 | 37 | 1249 | -86303.2334644601 |
2 分以内に 20,000 件近くの時系列データが分析され、読み取りカウントが突然減少した 2 つの異常な時系列が検出されました。
これらの高度な機能と高速パフォーマンスを組み合わせることで、時系列分析のための独自の強力なソリューションが提供されます。