適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
指定された軸に沿って、指定された集計値の系列を作成します。
構文
T| make-series [MakeSeriesParameters] [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumn [fromstart] [toend] stepstep [by [Column=] GroupExpression [, ...]]
構文規則について詳しく知る。
パラメーター
| 件名 | タイプ | 必須 | 説明 |
|---|---|---|---|
| 列 | string |
結果の列の名前。 既定値は式から派生した名前です。 | |
| DefaultValue | スカラー (scalar) | 存在しない値の代わりに使用する既定値。 AxisColumn と GroupExpression の特定の値を持つ行がない場合は、配列の対応する要素に DefaultValue が割り当てられます。 既定値は 0 です。 | |
| 集計 | string |
✔️ | 引数として列名が指定された や count() などのavg()の呼び出し。
集計関数のリストを参照してください。
make-series 演算子と共に使用できるのは、数値の結果を返す集計関数のみです。 |
| AxisColumn | string |
✔️ | 系列を並べ替える列。 通常、列の値は datetime 型または timespan 型ですが、すべての数値型が受け入れられます。 |
| を開始 | スカラー (scalar) | ✔️ | 構築する各系列の AxisColumn の下限値。 start が指定されていない場合は、各系列のデータを含む最初のビン (ステップ) です。 |
| 終わり | スカラー (scalar) | ✔️ | AxisColumn の非包含の上限値。 時系列の最後のインデックスはこの値より小さく、start と end より小さいステップの整数倍数です。 end が指定されていない場合は、各系列のデータを含む最後のビン (ステップ) の上限です。 |
| 歩 | スカラー (scalar) | ✔️ | AxisColumn 配列の 2 つの連続する要素間の差 (ビンのサイズ)。 可能な期間*のリスト*については、「期間」を参照してください。 |
| GroupExpression | 個別の値のセットを示す、列に対する式。 通常は、限られた値のセットが既に指定されている列名です。 | ||
| MakeSeriesParameters | 動作を制御する 0 個以上のスペース区切りパラメーター ( Name=Value の形式。 「サポートされている make series パラメーター」を参照してください。 |
注
start、end、およびstepパラメーターを使用して、AxisColumn 値の配列を作成します。 配列は、 start と endの間の値で構成され、 step 値は、1 つの配列要素と次の配列要素の差を表します。 すべての Aggregation 値は、この配列にそれぞれ並べ替えられます。
サポートされている make series パラメーター
| 件名 | 説明 |
|---|---|
kind |
make-series 演算子*の入力*が空の場合に、デフォルト*の結果が生成されます。 値: nonempty |
hint.shufflekey=<key> |
shufflekey クエリ*は、データ*をパーティション*化するキー*で、クラスター ノード*のクエリ*負荷*を共有*します。
クエリ*のシャッフルを参照 |
注
make シリーズによって生成される配列は、1,048,576 個の値 (2^20) に制限されています。 make-series を使用してそれより大きい配列を生成しようとすると、エラーまたは切り詰められた配列の結果となります。
代替構文
T| make-series [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumninrange(start,stop,step) [by [Column=] GroupExpression [, ...]]
代替構文から生成される系列は、次の 2 つの点でメイン構文と異なります。
- stop 値は包含値です。
- インデックス軸のビン分割は bin() で生成され、bin_at() は生成されません。つまり、 開始 は生成された系列に含まれない可能性があります。
代替構文ではなく、make シリーズの主な構文を使用することをお勧めします。
戻り値
入力行は、by 式と bin_at(AxisColumn,step,start) 式の同じ値を持つグループにまとめられます。 次に、指定された集計関数によってグループごとに計算が行われ、各グループに対応する行が生成されます。 結果には、by 列、AxisColumn 列のほか、計算された各集計に対応する 1 つ以上の列も含まれます (複数の列以上または数値以外の結果の集計はサポートされていません)。
この中間結果には、by と bin_at(AxisColumn,step,start ) 値の個別の組み合わせと同じ数の行が含まれています。
最後に、中間結果の行は by 式と同じ値を持つグループにまとめられ、すべての集計値は配列 (dynamic 型の値) にまとめられます。 集計ごとに、同じ名前の配列を含む 1 つの列が存在します。 最後の列は、指定された step に従ってビンされた AxisColumn の値を含む配列です。
注
集計式とグループ化式の両方に任意の式を指定できますが、単純な列名を使用する方がより効率的です。
集計関数の一覧
| 機能 | 説明 |
|---|---|
| avg() | グループ全体の平均値を返します |
| avgif() | グループの述語を使用して平均を返します |
| count() | グループの数を返します |
| countif() | グループの述語を使用してカウントを返します |
| covariance() | 2 つのランダム変数のサンプル共分散を返します。 |
| covarianceif() | 述語を持つ 2 つのランダム変数のサンプル共分散を返します |
| covariancep() を する | 2 つのランダム変数の母共分散を返します。 |
| covariancepif() | 述語を持つ 2 つのランダム変数の母共分散を返します。 |
| dcount() | グループ要素の個別の概数を返します |
| dcountif() | グループの述語を使用して個別の概数を返します |
| max() | グループ全体の最大値を返します |
| maxif() | グループの述語を使用して最大値を返します |
| min() | グループ全体の最小値を返します |
| minif() | グループの述語を使用して最小値を返します |
| percentile() | グループ全体のパーセンタイル値を返します |
| take_any() | グループの空でないランダムな値を返します |
| stdev() | グループ全体の標準偏差を返します |
| sum() | グループ内の要素の合計を返します |
| sumif() | グループの述語を使用して要素の合計を返します |
| variance() | グループ全体のサンプル分散を返します。 |
| varianceif() | 述語を持つグループ全体のサンプル分散を返します。 |
| variancep() | グループ全体の母分散を返します。 |
| variancepif() | 述語を持つグループ全体の母分散を返します。 |
系列分析関数の一覧
| 機能 | 説明 |
|---|---|
| series_fir() | 有限インパルス応答フィルターを適用します |
| series_iir() | 無限インパルス応答フィルターを適用します |
| series_fit_line() | 入力に最も近い直線を検索します |
| series_fit_line_dynamic() | 入力に最も近い線を検索し、動的オブジェクトを返します |
| series_fit_2lines() | 入力に最も近い 2 本の線を検索します |
| series_fit_2lines_dynamic() | 入力に最も近い 2 本の線を検索し、動的オブジェクトを返します |
| series_outliers() | 系列内の異常な点にスコアを付けます |
| series_periods_detect() | 時系列に存在する最も重要な期間を検索します |
| series_periods_validate() | 時系列に特定の長さの周期的なパターンが含まれているかどうかを確認します |
| series_stats_dynamic() | 一般的な統計情報 (最小、最大、分散、標準偏差、平均) を含む複数の列を返します |
| series_stats() | 一般的な統計情報 (最小、最大、分散、標準偏差、平均) を含む動的な値を生成します |
系列分析関数の完全な一覧については、「系列処理関数」を参照してください。
系列補間関数の一覧
| 機能 | 説明 |
|---|---|
| series_fill_backward() | 系列内の欠損値の後方埋め込み補間を実行します |
| series_fill_const() | 系列の欠損値を指定した定数値に置き換えます |
| series_fill_forward() | 系列内の欠損値の前方埋め込み補間を実行します |
| series_fill_linear() | 系列内の欠損値の線形補間を実行します |
- 注:補間関数では、既定で欠損値として
nullが想定されています。 そのため、系列に補間関数を使用する場合は、default=にnull(make-series) を指定してください。
例
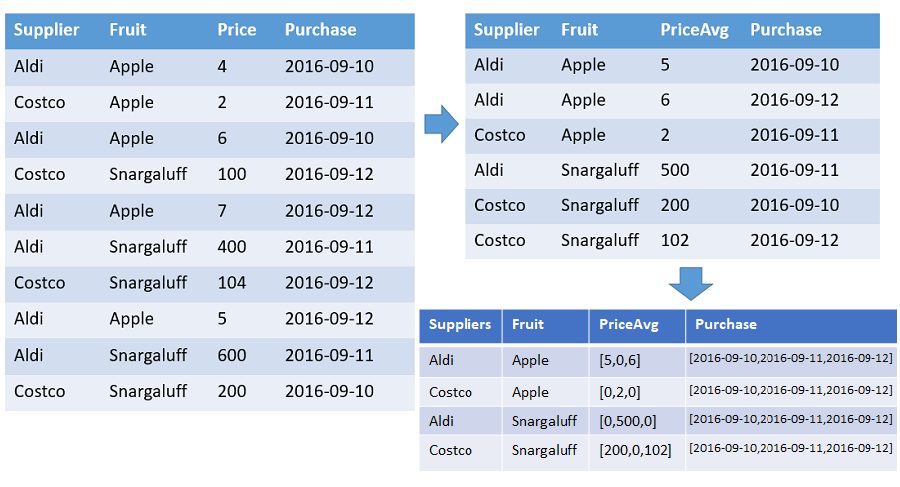
指定した範囲のタイムスタンプで並べ替えられた、各サプライヤーからの各果物の数と平均価格の配列を示すテーブル。 出力には、果物とサプライヤーの個別の組み合わせごとに行があります。 出力列には、果物、サプライヤー、配列 (カウント、平均、およびタイムライン全体 (2016-01-01 から 2016-01-10 まで)) が表示されます。 すべての配列はそれぞれのタイムスタンプで並べ替えられ、すべての欠落値に既定値 (この例では 0) が埋められます。 他のすべての入力列は無視されます。
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | タイムスタンプ |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
make-series への入力が空の場合、make-series の既定の動作で空の結果が生成されます。
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
出力
| 数える |
|---|
| 0 |
kind=nonemptyでmake-seriesを使用すると、既定値の空でない結果が生成されます。
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
出力
| avg_metric | タイムスタンプ |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
make-seriesとmv-expandを使用して、不足しているレコードの値を入力します。
let startDate = datetime(2025-01-06);
let endDate = datetime(2025-02-09);
let data = datatable(Time: datetime, Value: int, other:int)
[
datetime(2025-01-07), 10, 11,
datetime(2025-01-16), 20, 21,
datetime(2025-02-01), 30, 5
];
data
| make-series Value=sum(Value), other=-1 default=-2 on Time from startDate to endDate step 7d
| mv-expand Value, Time, other
| extend Time=todatetime(Time), Value=toint(Value), other=toint(other)
| project-reorder Time, Value, other
出力
| 時間 | 価値 | その他 |
|---|---|---|
| 2025-01-06T00:00:00Z | 10 | -1 |
| 2025-01-13T00:00:00Z | 20 | -1 |
| 2025-01-20T00:00:00Z | 0 | -2 |
| 2025-01-27T00:00:00Z | 30 | -1 |
| 2025-02-03T00:00:00Z | 0 | -2 |