Microsoft Syntexのモデルの種類の概要
適用対象: ✓ すべてのカスタム モデル |✓すべての事前構築済みモデル
Microsoft Syntexでのコンテンツの理解は、ドキュメント処理モデルから始まります。 ドキュメント処理モデルを使用すると、SharePoint ドキュメント ライブラリにアップロードされたドキュメントを特定して分類し、各ファイルから必要な情報を抽出できます。
SharePoint ドキュメント ライブラリに適用すると、モデルはコンテンツ タイプに関連付けられます。また、抽出される情報を格納する列があります。 作成したコンテンツタイプは、SharePoint コンテンツタイプ ギャラリーに保存されます。 既存のコンテンツ タイプを使用してスキーマを使用することもできます。
Syntex では、 カスタム モデル と 事前構築済みモデルが使用されます。
モデルには、コンテンツ センターで作成されるエンタープライズ モデルと、ローカル SharePoint サイトで作成されるローカル モデルのいずれかを指定できます。
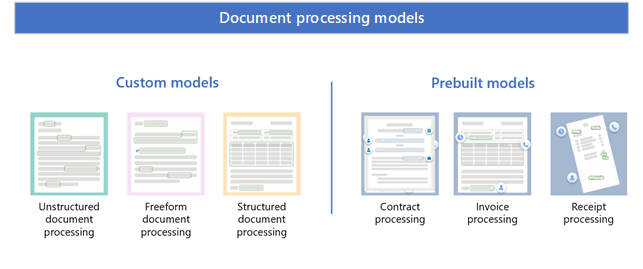
カスタム モデル
選択するカスタム モデルの種類は、使用するファイルの種類、ファイルの形式と構造、モデルを適用する場所によって異なります。
カスタム モデルには、次のものが含まれます。
カスタム モデルのサイド バイ サイドの違いを表示するには、「カスタム モデルの 比較」を参照してください。
カスタム モデルを作成するときに、モデルの種類に関連付けられているトレーニング メソッドを選択します。 たとえば、非構造化ドキュメント処理モデルを作成する場合は、モデルを作成する [ モデル作成のオプション] ページで、[ 教育方法 ] オプションを選択します。 次の表は、各カスタム モデルの種類に関連付けられているトレーニング メソッドを示しています。
| 非構造化 ドキュメント処理 |
フリーフォーム ドキュメント処理 |
構造化されたレッスン ドキュメント処理 |
|---|---|---|
 |
 |
 |
注:
フリーフォームの選択方法と Layout メソッドオプションをユーザーが使用できるようにするには、最初にMicrosoft 365 管理センターで構成する必要があります。
非構造化ドキュメント処理
非構造化ドキュメント処理モデルを使用して、ドキュメントを自動的に分類し、そこから情報を抽出します。 手紙や契約書などの非構造化ドキュメントで最適に機能します。 これらのドキュメントには、フレーズやパターンに基づいて識別できるテキストが含まれている必要があります。 識別されたテキストは、ファイルのタイプ (分類) および抽出するもの (抽出プログラム) の両方を指定します。
たとえば、非構造化ドキュメントは、さまざまな方法で記述できる契約更新レターである可能性があります。 ただし、各契約更新ドキュメントの本文には、テキスト文字列 "サービス開始日" の後に実際の日付が続くなど、一貫して情報が存在します。
このモデル型は、最も広い範囲のファイルの種類をサポートし、 40 を超える言語をサポートします。
非構造化ドキュメント処理モデルを作成する場合は、 Teaching メソッド オプションを使用します。
詳細については、「 非構造化ドキュメント処理の概要」を参照してください。
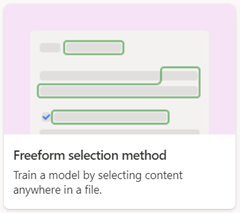
フリーフォームドキュメント処理
フリーフォーム ドキュメント処理モデルを使用して、文書内の任意の場所に情報を表示できる文字やコントラクトなどの非構造化ドキュメントやフリーフォーム ドキュメントから情報を自動的に抽出します。
フリーフォーム ドキュメント処理モデルでは、Microsoft Power Apps AI Builder を使用して Syntex 内でモデルを作成およびトレーニングします。
注:
フリーフォーム ドキュメント処理モデルは、一部のリージョンではまだ使用できません。 詳細については、「 リージョン別の機能の可用性」を参照してください。
organizationは、メール、FAX、電子メールなど、さまざまなソースから大量の文字やドキュメントを受け取るため、これらのドキュメントを処理してデータベースに手動で入力すると、かなりの時間がかかる場合があります。 AI を使用してこれらのドキュメントからテキストやその他の情報を抽出することで、このモデルによってこのプロセスが自動化されます。
このモデルの種類は、ドキュメントの種類を自動分類する必要がなく、 40 を超える言語をサポートしている場合に、PDF またはイメージ ファイル内のドキュメントに最適なオプションです。
フリーフォーム ドキュメント処理モデルを作成する場合は、 フリーフォームの選択方法 オプションを使用します。
詳細については、「 構造化および自由形式のドキュメント処理の概要」を参照してください。
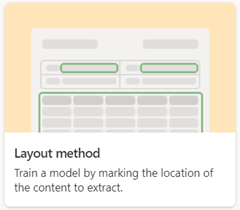
構造化ドキュメント処理
構造化ドキュメント処理モデルを使用して、フィールドとテーブルの値を自動的に識別します。 フォームや請求書などの構造化ドキュメントまたは半構造化ドキュメントに最適です。
構造化ドキュメント処理モデルでは、Microsoft Power Apps AI Builder ドキュメント処理 (旧称フォーム処理) を使用して、Syntex 内でモデルを作成およびトレーニングします。
このモデル型は 、最も広い範囲の言語 をサポートし、ドキュメントの例からフォームのレイアウトを理解するようにトレーニングされた後、類似の場所から抽出する必要があるデータを探す方法を学習します。 通常、フォームには、エンティティが同じ場所 (税フォームの社会保障番号など) にある、より構造化されたレイアウトがあります。
構造化ドキュメント処理モデルを作成する場合は、 Layout メソッド オプションを使用します。
詳細については、「 構造化および自由形式のドキュメント処理の概要」を参照してください。
事前構築済みモデル
カスタム モデルを構築する必要がない場合は、特定の構造化ドキュメントに対してトレーニング済 みの事前構築済みのドキュメント処理モデル を使用できます。
事前構築済みモデルには、次のものが含まれます。
![事前構築済みのモデル オプションを示す [モデル作成のオプション] ページのスクリーンショット。](../media/content-understanding/model-options-prebuilt.png)
事前構築済みモデルは、ドキュメントとドキュメント内の構造化情報を認識するために事前トレーニングされます。 新しいカスタム モデルをゼロから作成する代わりに、既存の事前トレーニング済みモデルを反復処理して、organizationのニーズに合った特定のフィールドを追加できます。
契約処理
コントラクト処理モデルは、コントラクト ドキュメントからキー情報を分析および抽出します。 API は、さまざまな形式でコントラクトを分析し、クライアント名やパーティー名、請求先住所、管轄区域、有効期限などの主要なコントラクト情報を抽出します。
事前構築済みコントラクト処理モデルの詳細については、「 事前構築済みモデルを使用してコントラクトから情報を抽出する」を参照してください。
請求書処理
請求書処理モデルは、売上請求書から重要な情報を分析および抽出します。 API は、さまざまな形式で請求書を分析し、顧客名、請求先住所、期日、支払金額などの主要な請求書情報を抽出します。
事前構築済みの請求書処理モデルの詳細については、「 事前構築済みモデルを使用して請求書から情報を抽出する」を参照してください。
領収書処理
事前構築済みのレシート処理モデルでは、売上受領書からキー情報を分析および抽出します。 API は、印刷されたレシートと手書きの領収書を分析し、マーチャント名、マーチャント電話番号、取引日、税金、取引合計などのキーレシート情報を抽出します。
事前構築済みのレシート処理モデルの詳細については、「 事前構築済みモデルを使用して領収書から情報を抽出する」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示