手順 1. Microsoft Syntexを使用してコントラクト ファイルを識別し、データを抽出する
組織では、受信した多数のファイルからすべての契約ドキュメントを識別して分類する方法が必要です。 また、特定された各コントラクト ファイル内のいくつかの重要な要素 ( クライアント、 請負業者、 料金など) をすばやく表示できるようにしたい場合もあります。 これを行うには、[Syntex] を使用して、非構造化ドキュメント処理モデルを作成し、それをドキュメント ライブラリに適用します。
プロセスの概要
非構造化ドキュメント処理モデル では、人工知能 (AI) を使用して、ファイルの分類と情報の抽出を自動化します。 これらの種類のモデルは、必要な情報がテーブルやフォーム (コントラクトなど) に含まれていない非構造化ドキュメントや半構造化ドキュメントから情報を抽出する場合にも最適です。
非構造化ドキュメント処理モデルでは、サンプル ファイルを使用してモデルをトレーニングするときと、ドキュメント ライブラリ内のファイルに対してモデルを実行する場合の両方で、光学式文字認識 (OCR) テクノロジを使用して PDF、画像、TIFF ファイルをスキャンします。
まず、特定しようとしているコンテンツ タイプ (コントラクト) に固有の特性を検索するためにモデルを "トレーニング" するために使用できる少なくとも 5 つのサンプル ファイルを見つける必要があります。
Syntex を使用して、新しい非構造化ドキュメント処理モデルを作成します。 サンプル ファイルを使用して、 分類子を作成する必要があります。 サンプル ファイルで分類子をトレーニングすることで、会社の契約に表示される特性に固有の特性を検索するように教えます。 たとえば、契約に含まれる特定の文字列 (サービス契約、契約条件、報酬など) を検索する "説明" を作成します。 説明をトレーニングして、ドキュメントの特定のセクションでこれらの文字列を探したり、他の文字列の横に配置したりすることもできます。 必要な情報を使用して分類子をトレーニングしたと思われる場合は、サンプル ファイルのサンプル セットでモデルをテストして、その効率を確認できます。 テスト後、必要に応じて説明を変更して、より効率的にすることができます。
モデルでは、 抽出器を作成 して、各コントラクトから特定のデータを取り出すことができます。 たとえば、契約ごとに、最も懸念される情報は、クライアントが誰であるか、請負業者の名前、合計コストです。
モデルを正常に作成したら、 それを SharePoint ドキュメント ライブラリに適用します。 ドキュメント ライブラリにドキュメントをアップロードすると、非構造化ドキュメント処理モデルが実行され、モデルで定義したコントラクト コンテンツ タイプに一致するすべてのファイルが識別され、分類されます。 コントラクトとして分類されたすべてのファイルは、カスタム ライブラリ ビューに表示されます。 ファイルには、エクストラクターで定義した各コントラクトの値も表示されます。
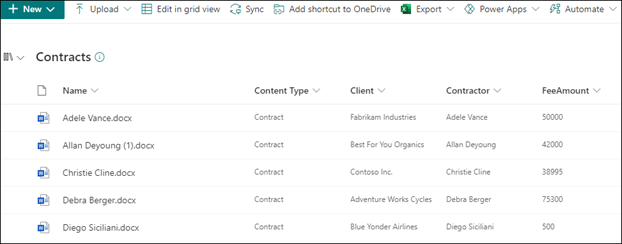
契約の保持またはセキュリティの要件がある場合は、モデルを使用して、指定した期間にコントラクトが削除されないようにする 保持ラベル または 秘密度ラベル を適用したり、コントラクトにアクセスできるユーザーを制限したりすることもできます。
モデルを作成してトレーニングする手順
注:
これらの手順では、 Contracts Management Solution Assets リポジトリのサンプル ファイルを使用できます。 このリポジトリの例には、モデル ファイルと、モデルのトレーニングに使用されるファイルの両方が含まれています。
コントラクト モデルを作成する
最初の手順は、コントラクト モデルを作成することです。
コンテンツ センターで、[ 新しい>モデル>教育方法] を選択します。
[ 教育方法を使用してモデルを作成する ] ウィンドウの [ 名前 ] フィールドに、モデルの名前を入力します。 このコントラクト管理ソリューションでは、モデルに Contract という名前を付けることができます。
[作成] を選択します。 これにより、モデルのホームページが作成されます。
ファイルの種類を分類するようにモデルをトレーニングする
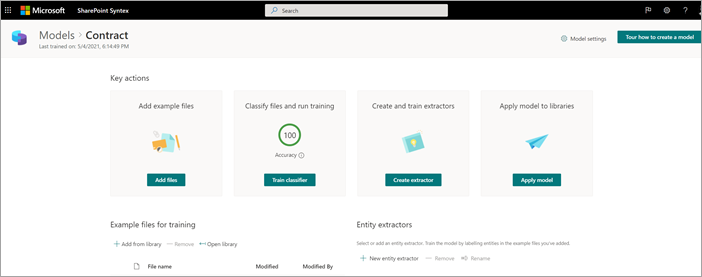
モデルのサンプル ファイルを追加する
コントラクト ドキュメントである少なくとも 5 つのサンプル ファイルと、コントラクト ドキュメントではない 1 つのサンプル ファイル (たとえば、作業ステートメント) を追加する必要があります。
[ モデル > コントラクト ] ページの [ キー アクション>] [サンプル ファイルの追加] で、[ ファイルの追加] を選択します。
![[サンプル ファイルの追加] オプションが強調表示されている [コントラクト] ページを示すスクリーンショット。](../media/content-understanding/key-actions-add-example-files.png)
[ モデルのサンプル ファイルの選択 ] ページで、[コントラクト] フォルダーを開き、使用するファイルを選択し、[ 追加] を選択します。 ファイルの例がない場合は、[ アップロード ] を選択して追加します。
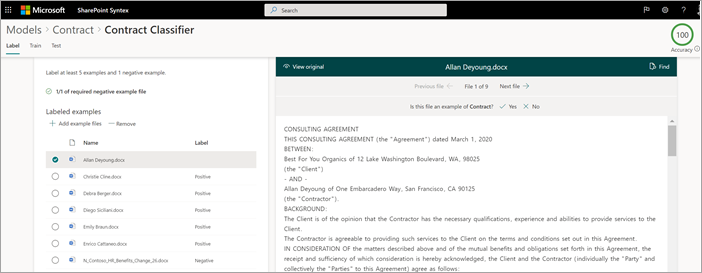
ファイルに正または負の例としてラベルを付ける
[モデル > コントラクト] ページの [キー アクション>] [ファイルを分類してトレーニングを実行する] で、[分類子のトレーニング] を選択します。
![[ファイルの分類とトレーニングの実行] オプションが強調表示されている [コントラクト] ページを示すスクリーンショット。](../media/content-understanding/key-actions-classify-files.png)
[ モデル > コントラクト > の分類子 ] ページで、最初のサンプル ファイルの上部にあるビューアーに、ファイルが作成したコントラクト モデルの例であるかどうかを確認するテキストが表示されます。 この例がポジティブの場合は、[ はい] を選択します。 ネガティブの例の場合は、[ いいえ] を選択します。
左側の [ラベル付き例 ] リストから、例として使用する他のファイルを選択し、ラベルを付けます。
分類子をトレーニングするための説明を少なくとも 1 つ追加する
[ モデル > コントラクト > の分類子 ] ページで、[ トレーニング ] タブを選択します。
[ トレーニング済みファイル ] セクションに、以前にラベルを付けたサンプル ファイルの一覧が表示されます。 一覧から正のファイルの 1 つを選択して、ビューアーに表示します。
[説明] セクション で 、[ 新規 ] を選択し、[ 空白] を選択します。
[ 説明を作成する ] ページで:
a. [ 名前 ] フィールドに、説明の名前 ("Agreement" など) を入力します。
b. テキスト文字列を追加するため、[ 説明の種類 ] フィールドで [ フレーズ 一覧] を選択します。
c. [ 語句] リスト ボックスに、文字列 ("AGREEMENT" など) を入力します。 文字列で 大文字と小文字を区別 する必要がある場合は、[大文字と小文字を区別] を選択できます。
d. [ 保存してトレーニング] を選択します。
![[説明の作成] パネルのスクリーンショット。](../media/content-understanding/contract-classifier-create-explanation.png)
モデルをテストする
コントラクト モデルは、これまでに見たことがないサンプル ファイルでテストできます。 これは省略可能ですが、便利なベスト プラクティスになる場合があります。
[ モデル > コントラクト > 分類子 ] ページで、[ テスト ] タブを選択します。これにより、ラベル付けされていないサンプル ファイルでモデルが実行されます。
[ テスト ファイル ] ボックスの一覧に、サンプル ファイルが表示され、モデルで正または負と予測されたかどうかを示します。 この情報を使用して、ドキュメントを特定するときの分類子の有効性を判断します。
![[テキスト ファイル] リストのラベル付けされていないファイルのスクリーンショット。](../media/content-understanding/test-on-files.png)
完了したら、[ Exit Training]\(トレーニングの終了\) を選択します。
抽出器を作成してトレーニングする
[モデル > コントラクト] ページの [キー アクション>] [エクストラクターの作成とトレーニング] で、[抽出器の作成] を選択します。
![[エクストラクターの作成とトレーニング] オプションが強調表示されている [コントラクト] ページを示すスクリーンショット。](../media/content-understanding/key-actions-create-extractors.png)
[ 新しいエンティティ抽出器 ] パネルの [ 新しい名前 ] フィールドに、抽出器の名前を入力します。 たとえば、各コントラクトから クライアント の名前を抽出する場合は、Client という名前を付けます。
完了したら、[ 作成] を選択します。
抽出するエンティティにラベルを付ける
エクストラクターを作成すると、エクストラクター ページが開きます。 ここでは、サンプルファイルの一覧が表示されます。リストの最初のファイルは、viewer に表示されています。
![[Client extractor Labeled examples]\(クライアントエクストラクターのラベル付き例\) ページのスクリーンショット。](../media/content-understanding/client-extractor-labeled-examples.png)
エンティティにラベルを付ける方法:
Viewer で、ファイルから抽出するデータを選択します。 たとえば、 クライアントを抽出する場合は、最初のファイル (この例では Best For You Organics) のクライアント値を強調表示し、[保存] を選択 します。 [ ラベル付き例 ] ボックスの一覧の [ ラベル ] 列に、ファイルの値が表示されます。
[ 次のファイル ] を選択して自動保存し、ビューアーの一覧で次のファイルを開きます。 または、[ 保存] を選択し、[ ラベル付けされた例 ] の一覧から別のファイルを選択します。
ビューアーで手順 1 と 2 を繰り返し、ラベルをすべてのファイルに保存するまで繰り返します。
ファイルにラベルを付けた後、トレーニングに移行することを通知する通知バナーが表示されます。 より多くのドキュメントにラベルを付けるか、トレーニングに進むことができます。
説明を作成する
エンティティ形式自体とサンプル ファイルに含まれるバリエーションに関するヒントを提供する説明を作成できます。 たとえば、日付の値は、次のようなさまざまな形式にすることができます。
- 10/14/2019
- 2019 年 10 月 14 日
- 2019 年 10 月 14 日、月曜日
契約開始日を特定するために、説明を作成できます。
[説明] セクション で 、[ 新規 ] を選択し、[ 空白] を選択します。
[ 説明を作成する ] ページで:
a. [ 名前 ] フィールドに、説明の名前 (Date など) を入力 します。
b. [ 説明の種類 ] フィールドで、[ フレーズ 一覧] を選択します。
c. [ 値 ] フィールドで、サンプル ファイルに表示される日付のバリエーションを指定します。 たとえば、0/00/0000 として表示される日付形式がある場合は、次のようなドキュメントに表示されるバリエーションを入力します。
- 0/0/0000
- 0/00/0000
- 00/0/0000
- 00/00/0000
[ 保存してトレーニング] を選択します。
モデルをもう一度テストする
コントラクト モデルは、これまでに見たことがないサンプル ファイルでテストできます。 これは省略可能ですが、便利なベスト プラクティスになる場合があります。
[ モデル > コントラクト > 分類子 ] ページで、[ テスト ] タブを選択します。これにより、ラベル付けされていないサンプル ファイルでモデルが実行されます。
[ テスト ファイル ] の一覧に、サンプル ファイルが表示され、モデルが必要な情報を抽出できるかどうかを示します。 この情報を使用して、ドキュメントを特定するときの分類子の有効性を判断します。
完了したら、[ Exit Training]\(トレーニングの終了\) を選択します。
モデルをドキュメント ライブラリに適用する
SharePoint ドキュメント ライブラリにモデルを適用するには:
[モデル > コントラクト] ページの [キー アクション>] の [モデルをライブラリに適用する] で、[モデルの適用] を選択します。
![[モデルをライブラリに適用] オプションが強調表示されている [コントラクト] ページを示すスクリーンショット。](../media/content-understanding/key-actions-apply-model.png)
[ 契約の追加 ] パネルで、モデルを適用するドキュメント ライブラリを含む SharePoint サイトを選択します。 リストにサイトが表示されない場合は、検索ボックスを使用して検索します。 [追加] を選択します。
注:
モデルを適用しようとしているドキュメントライブラリへのリスト管理許可を持っているかまたは、編集 権限を持っていなければなりません。
サイトを選択したら、モデルを適用するドキュメント ライブラリを選択します。
モデルはコンテンツ タイプに関連付けられているため、ライブラリに適用すると、抽出したラベルが列として表示されたコンテンツ タイプとそのビューが追加されます。 このビューは既定でライブラリの既定のビューですが、[ 詳細設定 ] を選択し、[ この新しいビューを既定に設定 する] チェック ボックスをオフにして、既定のビューにしないようにオプションで選択できます。
モデルをライブラリに適用するには、[ 追加 ] を選択します。
[ モデル > コントラクト ] ページの [ このモデルを含むライブラリ ] セクションに、SharePoint サイトの URL が一覧表示されます。
![[このモデルを使用したライブラリ] セクションを示すコントラクト ホーム ページのスクリーンショット。](../media/content-understanding/contract-libraries-with-this-model.png)
[設定ライブラリの設定]> で、次の手順を実行します。
- [状態] という名前の列を追加し、列の種類として [選択] を選択します。
- [レビュー中]、[承認済み]、[拒否] の値を適用します。
モデルをドキュメント ライブラリに適用すると、サイトへのドキュメントのアップロードを開始し、結果を確認できます。