適用対象: ✓ 非構造化ドキュメント処理
ドキュメント処理用のエンタープライズ モデルの作成に関するページの手順に従って、コンテンツ センターで非構造化ドキュメント処理モデルを作成します。 または、「 ローカル SharePoint サイトにモデルを作成する 」の手順に従って、ローカル サイトにモデルを作成します。 次に、この記事から始めてモデルのトレーニングを開始します。
分類子を作成する
分類子は、ドキュメントの種類の識別および分類を自動化するために使用できるモデルの種類です。
たとえば、次の図に示すように、ドキュメントライブラリに追加されたすべての 契約更新 ドキュメントを特定することも可能です。

分類子を作成すると、モデルに関連付けられる新しい SharePoint コンテンツの種類を作成できます。
分類子を作成するときに、モデルを定義するために 説明 を作成する必要があります。 この手順では、このドキュメントの種類を一貫して見つけることが予想される一般的なデータをメモできます。
コンテンツタイプが同じファイルを特定できるように、モデルに "トレーニング" するには、ドキュメントの種類 ("ファイルの例") の例を使用します。
分類子を作成するには、次の操作を行う必要があります。
注:
モデルでは、ドキュメントタイプを特定して分類するために分類子を使用していますが、モデルで識別された各ファイルから特定の情報を取得することもできます。 これを行うには、モデルに追加する 抽出機能 を作成します。 「抽出機能を作成 」を参照してください。
モデルに名前を付けます
モデルを作成する最初の手順は、名前を付けることです。
コンテンツ センターから [ 新規] を選択し、[ モデル] を選択します。
[ モデル作成のオプション] ページで 、[ 教育方法] を選択します。
[ 教育方法: 詳細 ] ページで、[ 次へ] を選択します。
[ 指導方法を使用してモデルを作成する] ページの [ モデル名 ] フィールドに、モデルの名前を入力します。 たとえば、契約更新ドキュメントを特定する場合、モデルに契約更新と名前を付けます。
[作成] を選択します。 このアクションにより、モデルのホーム ページが作成されます。
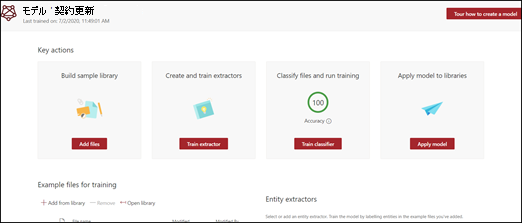
モデルを作成するときに、新しいサイト コンテンツ タイプも作成します。 コンテンツタイプは、共通の特徴を持つドキュメントのカテゴリを表し、特定のコンテンツの列またはメタデータプロパティのコレクションを共有します。 SharePoint コンテンツの種類は、[コンテンツの種類ギャラリー] で管理されます。 この例では、モデルを作成するときに、新しい コントラクト更新 コンテンツ タイプを作成します。
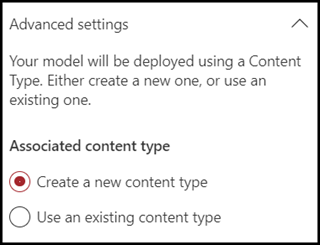
このモデルを SharePoint コンテンツ タイプ ギャラリー内の既存のエンタープライズ コンテンツ タイプにマップしてスキーマを使用する場合は、[詳細設定] を選択します。 エンタープライズコンテンツタイプは、SharePoint 管理センターのコンテンツタイプハブに格納され、テナントのすべてのサイトにシンジケートされます。 既存のコンテンツ タイプを使用してスキーマを活用して識別と分類に役立てることができる場合でも、識別したファイルから情報を抽出するためにモデルをトレーニングする必要があることに注意してください。
サンプルファイルを追加する
モデルのホーム ページで、ドキュメントの種類を識別するためにモデルのトレーニングに役立つサンプル ファイルを追加します。
注:
分類子と 抽出機能トレーニングに同じファイルを使用する必要があります。 後で追加するオプションは常に用意されていますが、通常はサンプルファイルすべてを追加します。 モデルを学習させるためにラベルを付け、残りのラベルのないものをテストして、モデルの適合性を評価します。
トレーニングセットについては、ポジティブなものとネガティブなものと両方のサンプルを使用します。
- ポジティブな例: ドキュメントの種類を表すドキュメント。 これらには、この種類のドキュメントに常に存在する文字列と情報が含まれます。
- 負の例: 分類するドキュメントを表さないその他のドキュメント。
モデルをトレーニングする場合は、少なくとも1つのポジティブな例と少なくとも1つのネガティブな例を使用してください。 トレーニング プロセスの後にモデルをテストする別のモデルを作成する必要があります。
サンプルファイルを追加するには:
モデルのホーム ページの [ サンプル ファイルの追加] タイルで、[ ファイルの追加] を選択します。
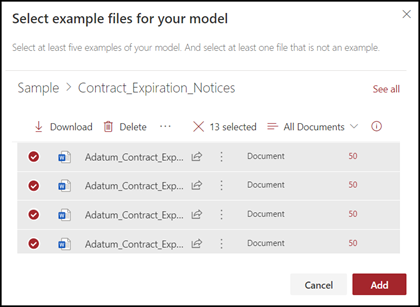
[ モデル 用にサンプルファイルを選択してください] ページで、コンテンツセンターのトレーニングファイルライブラリからサンプルファイルを選択します。 まだアップロードしていない場合は、[アップロード] をクリックしてトレーニング ファイル ライブラリにコピー して、今すぐアップロードすることを選択します。
モデルのトレーニングに使用するサンプル ファイルを選択したら、[ 追加] を選択します。
サンプルファイルにラベルを付ける
サンプルファイルを追加した後は、ポジティブまたはネガティブのラベルを付ける必要があります。
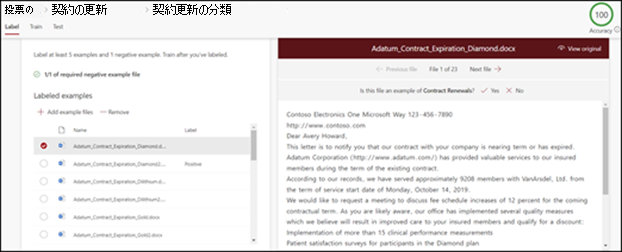
モデルのホーム ページの [ファイルの 分類とトレーニングの実行 ] タイルで、[ 分類子のトレーニング] を選択します。 この手順では、サンプル ファイルの一覧を示すラベル ページが表示され、最初のファイルがビューアーに表示されます。
最初のサンプルファイルの一番上にあるビューアーで、作成したモデルの例として、そのファイルが適切かどうかをテキストを見て確認する必要があります。 正の例の場合は、[ はい] を選択します。 負の例の場合は、[いいえ] を選択 します。
左側にある ラベル付きのサンプル リストで、サンプルとして使用する追加のファイルを選択し、ラベルを付けます。
注:
少なくとも5個のポジティブな例にラベルを付けます。 少なくとも1つのネガティブな例にラベルを付けます。
説明を作成する
次の手順では、トレーニングページに説明を作成します。 詳細を使用すると、モデルがドキュメントの識別をしやすくなります。 たとえば、契約更新ドキュメントには常に、テキスト文字列追加の開示要求が含まれます。
注:
エクストラクターを使用する場合、説明を使用すると、文書から抽出する文字列を特定します。
説明を作成するには:
[モデルのホーム] ページで、[トレーニング] タブを選択し、[トレーニング] ページに移動します。
[トレーニング] ページの [トレーニング済みファイル] セクション には、以前にラベルが付けられたサンプルファイルの一覧が表示されています。 一覧からいずれかのポジファイルを選び、viewer で表示します。
[説明] セクションで、[新しい ] を選択し、[空を選択し ます。
[ 説明の作成 ] ページで、 を
します。 名前 を入力します (たとえば、"暴露ブロック")。
B。 [ 種類]を選びます。 この例では、文字列を追加するので、[ 語句のリスト] を選択します。
C。 [ ここに入力してください] ボックスに、文字列を入力します。 このサンプルには、"追加情報開示の要求" を追加します。 文字列に大文字と小文字を区別する必要がある場合は、大文字と小文字の区別を選択することができます。
d. [保存] を選択します。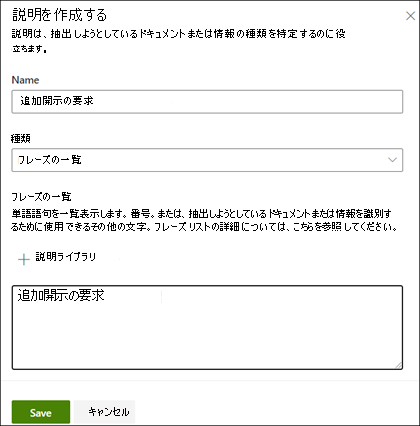
コンテンツ センターでは、作成した説明がポジティブまたはネガティブの例として、残りのラベル付きファイルの例を正しく識別するのに適しているかどうかを確認するようになりました。 [トレーニング済みファイル] セクションで、トレーニングが完了した後で結果を確認するため、[評価] 列をチェックします。 ファイルには、ユーザーがポジティブまたはネガティブとラベルをつけたものと一致させるために作成した説明が適切であった場合、一致が表示されます。
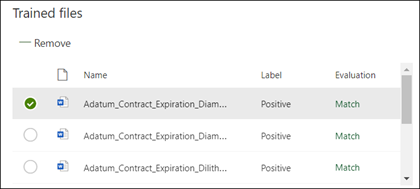
ラベルが付けられたファイルの不一致 を受信した場合は、モデルがドキュメントの種類を識別できるように、追加の説明を作成し提供しなければならない場合があります。 不一致が発生した場合は、ファイルを選択して、不一致が発生した理由の詳細を取得します。
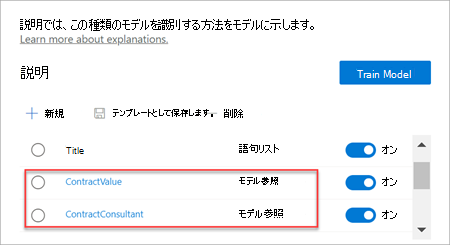
エクストラクターをトレーニングしたら、そのトレーニング済みエクストラクターを説明として使用できます。 [説明セクション] では、これは [モデル リファレンス] として表示されています。
モデルをテストする
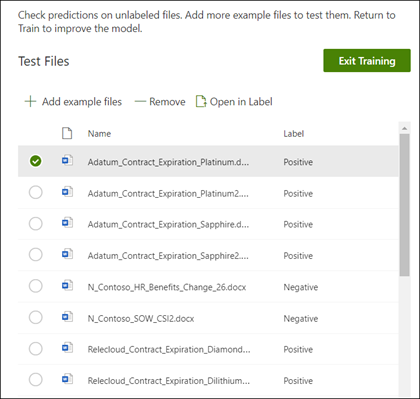
ラベル付けされたサンプル ファイルで一致するものを受け取った場合は、モデルがこれまでに見たことのないラベル付けされていない残りのサンプル ファイルでモデルをテストできるようになりました。 この手順は省略可能ですが、モデルを使用する前にモデルの "適合性" または準備状況を評価するための便利な手順です。これは、モデルがこれまでに見たことがないファイルでテストすることで行います。
[モデルのホーム] ページで、[テスト] タブを選択します。 ラベルなしのサンプルファイル上でモデルが実行されます。
[ テストファイル ] の一覧では、サンプルファイルが表示され、モデルがポジティブかネガティブであるかを予測します。 この情報を使用して、ドキュメントを特定するときの分類子の有効性を判断します。