次の図は、一般向け Web サイトまたは Bing カスタム検索 が ナレッジ ソースとして使用される場合のアーキテクチャを示しています。

Microsoft Bing Custom Search が結果を提供する仕組み
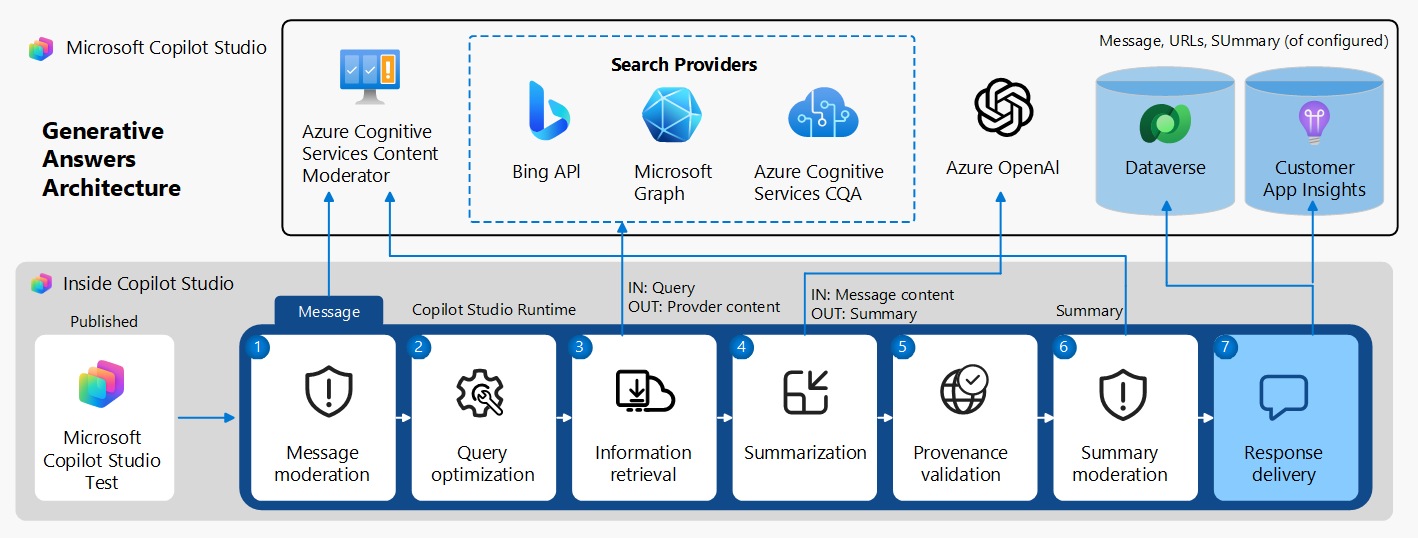
生成型の回答ノード が Bing 検索を使用するように構成されている場合、Copilot Studio は次の操作を実行します。
- メッセージモデレーション: ユーザーのクエリを解析し、悪意のあるコンテンツをフィルタリングします。
- クエリの最適化: 場所や時間に関連する情報など、会話履歴からクエリ コンテキストを追加します。
- 情報の取得: ユーザーの応答を検索クエリに変換します。検索クエリは Bing Custom Search サービスに渡され、顧客が構成したドメインに制限されます。
Bing の複雑なシステムでは、これらの条件を使用して、Bing Custom Search インデックスから検索結果を提供します。 Bing Custom Search はグローバル サービスであるため、リージョンの境界はありません。
検索結果が返され、Copilot Studio は次の操作を実行します。
- 指定されたソースまたは顧客が構成したドメインからの関連する上位の結果を照合して解析します。
- 接地チェック、来歴チェック、およびセマンティック類似性のクロスチェックを実行します。
- エージェントのユーザーに配信される平易な言語に検索結果を要約します。
すべてのコンテンツは 2 回チェックされます (1 回目はユーザー入力時、もう 1 回目はエージェントが応答しようとしているとき)。 システムが有害、攻撃的、または悪意のあるコンテンツを検出すると、エージェントからの応答が防止されます。

生成 AI モデル
生成 AI モデルは内部の Microsoft Azure OpenAI サービスでホストされ、Microsoft Services Trust 境界を尊重しています。 モデルは、Microsoft の責任ある AI の原則とポリシーに従ってアクセスして使用されます。
Copilot Studio および Bing カスタム検索間のデータ交換
会話コンテキストでユーザーの書き換えられた発話は、Copilot Studio から Bing に送信されます。 コンテキストは、最後の数回の複数ターンの会話から派生します。
次に、Bing 応答データ (検索結果) が Copilot Studio に送り返されます。
さらに、Copilot Studio では、データ交換中にこれらのモデルのトレーニングに使用される顧客データを収集または提供しません。
Copilot Studio および Bing カスタム検索間の個人データの交換
Microsoft は、構造化された End User Pseudonymous Identifier (EUPI)、つまり、Microsoft サービスのユーザーに関連付けられた Microsoft によって作成された識別子を Bing Search に送信しません。
ただし、ユーザーが個人データとして解釈される可能性のあるものを追加した場合、生成型の回答はそのようなデータを検出、スクラブ、またはマスクしません。 この削除の欠如は、他の業界の多くの認証済みユース ケースでは、正当な処理に個人データ情報が必要であるためです。
生成型回答のための事前に開発されたガードレール
マイクロソフトのポリシーでは、生成 AI 機能を開発、展開、または統合するマイクロソフトの製品や研究をリリースする前に 責任ある AI プラクティスを適切に遵守していることを示すための評価が必要です。 マイクロソフトが軽減策を開発するすべての害は、レッド チームを通過し、軽減策の普及率がテストされます。 テストと軽減策の実装が完了して初めて、生成 AI システムがデプロイされます。
Copilot Studio はまた、すべての生成 AI 要求にコンテンツ モデレーション ポリシーを適用して、攻撃的または有害なコンテンツから保護します。 これらのコンテンツモデレーションポリシーは、ジェイルブレイク、プロンプトインジェクション、プロンプト流出、著作権侵害などの悪意のある試みにも及びます。
生成型の回答で Bing 検索結果の誤った情報を防ぐ方法
Copilot Studio は、検索結果を取得し、それらの検索結果をまとまりのある応答に要約するステップを分離する検索拡張生成を使用します。 Web サイトから返された検索結果は、そのソースまで遡ることができ、適切な引用元が確認されます。 さらに、ユーザーが尋ねた質問に関連する検索結果の関連性が検証されます。
注意
AI に独自の一般知識の使用を許可する設定をオンにすると、引用の制限が緩和されます。
Bing 検索結果から応答を生成する際の有害なコンテンツの管理
憎悪、暴力、性的コンテンツ、自傷行為など、有害なコンテンツ カテゴリに対する有害出力と冒涜の緩和は、事前に開発されたガードレールとして利用可能です。 ユーザーからの問い合わせや Web サイトから返された検索結果は、違反がないことをチェックされ、そのような内容の質問や検索結果は無視されます。
さらに、生成 AI のプロンプトには、脱獄、プロンプト インジェクション、プライバシー侵害に分類される質問や検索結果を無視する指示も含まれています。
個人データクエリを無視するための生成型回答ノードのカスタマイズ
エージェント用のカスタム プロンプトを作成したり、カスタム ノード命令を作成して、個人データや機密性の高いビジネス情報を検出したりできます。 次に、生成型回答ノードに応答しないように指示できます。
注意
ただし、この方法では、個人データや機密性の高いビジネス情報が Bing Search やその他のナレッジ ソースに送信されるのを防ぐことはできません。
生成型の回答への個人データの流れ
生成型回答は 会話対応であるため、生成型回答ノードは、マルチターン会話中の以前の対話からのユーザーのクエリを内部的にコンテキスト化します。 最後の数回の会話のクエリはすべて コンテキスト化 され、生成型回答ノードによって書き直されたクエリの一部になります。
個人データ検出機能を備えた AI Builder プロンプトまたは Azure OpenAI モデルを使用すると、エージェントの会話内の個人データを識別できますが、回答を生成する前にユーザーの最後のクエリを確認するだけでは十分ではありません。
Bing をナレッジ ソースとして使用しない生成回答の代替手段
エージェントのナレッジ ソースとしての Azure AI 検索インデックスを使用します。 この機能は、エージェントの基礎となるデータとして、事前構築済みの Azure AII 検索インデックスを使用します。 Azure AI 検索は、大量のドキュメントコレクションを検索できる強力な検索エンジンを提供します。 Azure AI 検索インデックスは、開発者によって構築されています。 これにより、インデックスが地理的領域内で独自のコンテンツを検索する柔軟性を持ちながら、生成 AI を使用してモデレート、要約がされた回答を作成する生成回答機能を使用することができます。
ユーザーは、準拠した検索エンジン API を使用したカスタム ソリューションや、コンテンツ管理システムに直接クエリを実行し、結果を生成型回答ノードの カスタム データ ソース フィールドのデータに変換する方法を選択することもできます。 このオプションは、サポートされているナレッジ ソースの 1 つにデータが存在しない可能性がある場合に使用されます。 これらのシナリオでは、エージェントには Power Automate フローまたは HTTP 要求を介してグラウンディング データが提供されます。 通常、これらのオプションは JSON オブジェクトを返し、それをテーブル形式に解析して回答を生成できます。
Copilot Studio および Bing 検索間のデータ交換のセキュリティ
Microsoft Bingでの検索リクエストはHTTPS経由で行われます。 接続はエンドツーエンドで暗号化され、セキュリティが強化されます。
データ収集
Microsoftは、エンドユーザーのIPアドレス、リクエスト、送信時間、エンドユーザーに返された結果などの情報を、本サービスへのトランザクションリクエストとともにエンドユーザーから収集する場合があります。 Microsoftは、機能に関連して提供されるデータ、情報、またはコンテンツの所有権を主張しません。
本サービスへのすべてのアクセスおよび使用は、プライバシーに関する声明に規定されているデータの取り扱いに従うものとします。
データ保有期間
Bing 検索クエリの場合、マイクロソフトは 6 か月後に IP アドレス全体を削除することで、保存されているクエリを匿名化し、18 か月後に特定のアカウントまたはデバイスを識別するために使用される Cookie ID やその他のクロスセッション識別子を匿名化します (https://www.microsoft.com/en-us/privacy/privacystatement#mainwherewestoreandprocessdatamodule)。
Bing 検索結果
リアルタイム検索操作には、複雑でほぼ瞬時のアルゴリズム計算が含まれます。 Bing は、アルゴリズムを使用して、保存されている利用可能な Web ページのインデックスをランク付けおよび最適化し、ユーザーに最高品質の検索結果を提供します。 クロールは、Bingbot (Bing クローラー) が検索インデックスに追加する新しいページや更新されたページやコンテンツを検出する方法です。
Bing Web クロールの頻度
Bingbot (Bing クローラー)は、アルゴリズムを使用してクロールする対象と頻度を決定し、毎日何十億もの URL をクロールするため、Web サイトへの影響を最小限に抑えるように努めています。 Bingbot は Web をクロールするときに、検出した内容に関する情報を Bing に送信します。 Bing では、まだインデックスに登録されていない関連既知のページと、更新済みとして検出されたページが優先されます。 これらのページは Bing のインデックスに追加され、アルゴリズムを使用してページを分析し、ユーザーが特定のキーワードで検索した際に、どのサイト、ニュース記事、画像、動画がインデックスに含まれ、利用できるかを決定するなど、効果的に検索結果に含まれるようになります。
検索結果のランク
Bing は 機械学習に依存して、ユーザーにクエリの最良の結果が表示されるようにします。 以下は、ナレッジソースとして提供されるURL内の検索に影響を与えるランキングの主なパラメータです。 次の各パラメーターの相対的な重要度は、検索ごとに異なり、時間の経過とともに進化する可能性があります。
関連性 (コンテンツは、検索クエリの背後にあるユーザーの意図と一致します)。
ユーザー エンゲージメント (アルゴリズムは新鮮なコンテンツを好みます。)
鮮度 (ユーザーの Web ページとの対話。)
Bing は、利用可能な最も包括的で関連性が高く、価値のある検索結果のコレクションを提供するために、アルゴリズムを設計し、継続的に改善しています。
Bing検索の生成型回答ノードの改善
ユーザーはコンテキストから外れた質問をすることができるため、生成型の回答カスタム プロンプトで別の特定の情報を提供し、検索エンジンが関連する結果を照会するように指示することで、Bing 検索を改善できます。 ユーザーの発話とクエリは、数式を使用して特定のデータで強化し、生成型の回答カスタム プロンプトに挿入できます。
Bing インデックスの作成を改善するためのベスト プラクティス
次の代表的なガイドラインは、Bing でサイトを効果的にインデックスに登録するのに役立ちます。 また、サイトを最適化して、Bing の検索結果で関連するクエリをランク付けする機会を増やすのにも役立ちます。
Web サイトの URL とコンテンツを検出できるように更新された Bing のサイトマップ。
IndexNow API または Bing URL または Content Submission API を使用して、Web サイトの変更を即座に反映させます。
サイト上のすべてのページを、Web サイトの人気度を判断するためのシグナルとして、少なくとも 1 つの他の検出可能およびクロール可能なページにリンクする。
Webサイトのページ数を制限します。
必要に応じてリダイレクトを使用します。
動的レンダリングは、Bingbot のクライアント サイド レンダリングとプリレンダリング コンテンツを切り替えます。
検索エンジンが Web ページのインデックスを作成するのを妨げる
nofollowまたはnoindexなどのタグは避けてください。robots.txtファイルは、検索エンジン クローラー (Bingbot) に、クローラーがアクセスできるページとアクセスできないページを通知します。
注意
検索エンジン最適化 (SEO) は、組織内の CBA SEO/コンテンツ管理チームが最適に管理する専門スキルです。 詳細については、Bing ウェブマスター向けガイドラインをご覧ください。