自然言語理解(NLU)は、Copilot Studioのエージェントがユーザーの問い合わせを理解し、関連性のある文脈に沿った応答を提供するための核心です。 意図認識、エンティティ抽出、フォールバック処理に対する明確なアプローチにより、エージェントはビジネスニーズに沿った効率的で自然な会話を提供できます。
ユーザーがエージェントに何かを入力すると、それは発話(発話)と呼ばれます。 エージェントはその発話を意図と実体に分解し、エージェントの応答を自然かつ効率的に感じさせる必要があります。
言語理解とは何か?
言語理解(LU)は、自然言語処理(NLP)のサブフィールドであり、機械が人間の言語の背後にある意味、意図、文脈を理解できるようにすることを目的としています。
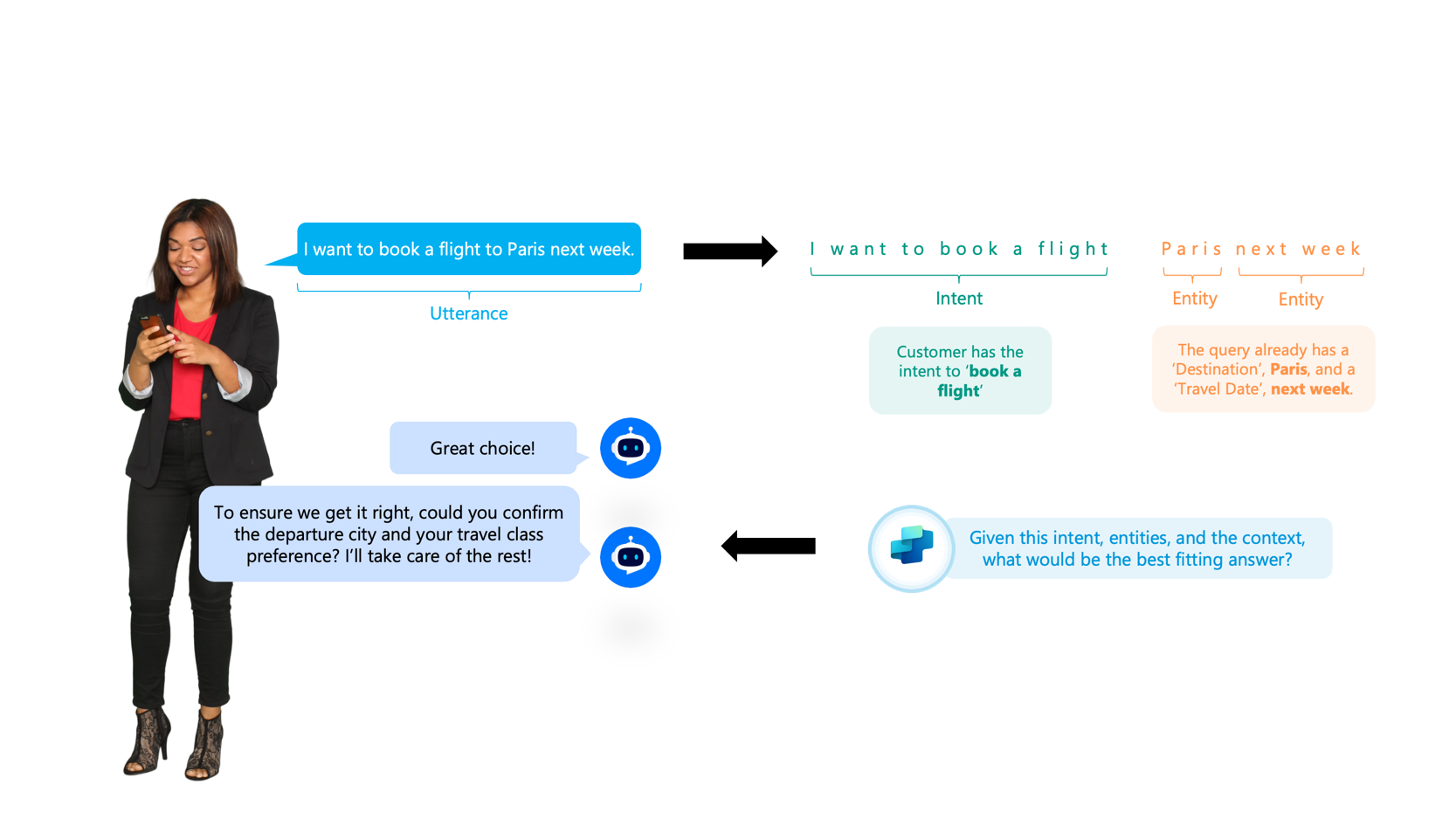
ユーザーのメッセージが意図と実体にどのように分解されているかを示す図。 ある人が「来週パリ行きのフライトを予約したい」とタイプします。 メッセージは発話としてラベル付けされます。 「フライトを予約したい」というフレーズが意図として、「パリ」と「来週」が実体として識別されます。 その後、出発都市や旅行クラスなどの詳細を尋ねられます。 図は、エージェントが意図、実体、文脈を用いて最適な応答を決定する方法を示しています。
言語理解には以下が含まれます:
- 意図認識:ユーザーが達成したいことを特定すること(例:「来週パリ行きのフライトを予約」はフライト予約の意図にマッピングされます)。
- エンティティ抽出:日付、場所、名前などの重要な情報(例:「パリ」を目的地、「来週」を旅行日)を抽出します。
- 文脈認識:会話の連続性を維持し、曖昧さ(例えば代名詞や参照の理解)を解消すること。
- 曖昧さの扱い:複数の意味を持つ単語(例えば「銀行」を金融機関や川岸として扱う)を文脈を用いて解決すること。
Copilot Studioにおける言語理解
Copilot Studioは言語理解のための柔軟なモデルを持ち、複数の設定オプションを備えています。
生成オーケストレーション
生成的オーケストレーション は言語モデルを用いて、トピック、アクション、知識を知的に連結させます。 この機能により、多目的認識、高度なエンティティ抽出、複雑なクエリに対する動的な計画生成が可能になります。
この方法はCopilot Studioのデフォルトです。 このアプローチは、単一の発話に複数の意図やトピックを認識し、アクションと知識源を自動的に連鎖させ、統一応答を生成します。 特に複数のビジネス分野にまたがる複雑な会話を扱うのに有用です。 生成オーケストレーションには制限があり、例えばトピックやアクションチェーンあたり5つのメッセージ、1オーケストレーションあたり128のトピックやアクションまでですが、会話の幅を広げる強力な方法を提供します。
詳細は 「生成オーケストレーション機能を適用」をご覧ください。
クラシック オーケストレーション
クラシックなオーケストレーションはトリガーフレーズと決定論的なトピックルーティングを用います。 ユーザーの発言がトリガーフレーズと一致すれば、対応するトピックが実行されます。 一致しない場合は、バックアップ機能として知識源を検索したり、ユーザーに説明を求めるプロンプトを行ったりします。
組み込みNLU
この方法はかつてはデフォルトでしたが、今ではバックアップ手段となっています。 Copilot Studioは、トリガーフレーズ、あらかじめ定義されたエンティティ、カスタムエンティティをサポートする標準の NLUモデル を提供します。 このモデルにより、エージェントはユーザーの意図を特定し、日付、宛先、数量などの重要な情報をクエリから直接抽出できます。
NLU+
高精度を狙うなら 、NLU+オプションを使いましょう。 NLU+ オプションは、大規模なエンタープライズ レベルのアプリケーションに最適です。 これらの種類のアプリケーションは、通常、多数のトピックとエンティティで構成され、多数のトレーニング サンプルを使用します。 また、 音声対応エージェントがある場合は、NLU+ トレーニング データを使用して音声認識機能を最適化することもできます。
Azure CLU integration
デフォルトの生成オーケストレーションが使えないより高度なシナリオでは、 Azure Conversational Language Understanding(CLU)を統合できます。 CLUはより高度なカスタマイズ性、多言語対応、複雑なエンティティ抽出(例えば複数の「from」エンティティ)を提供します。 CLUの意図をCopilot Studioのトピックにマッピングして同期させる必要があります。このオプションは、業界特有の語彙、非英語言語、またはより高い精度が必要なシナリオに特に価値があります。
主な特徴と制限
この表はCopilot Studioにおける3つの言語理解アプローチを比較しています。 その主要な特徴と制限を明確に示し、エージェントの複雑さ、規模、精度のニーズに合った最適なモデルを選ぶのに役立ちます。
| 機能および制限事項 | 生成オーケストレーション | 組み込みのNLUモデル | カスタム Azure CLU モデル |
|---|---|---|---|
| 主な機能 |
|
|
|
| 制限 |
|
|
|
自然 言語理解(NLU)の概要で詳しく学びましょう。
トピック構成とフォールバック
テーマは硬直した意図に基づく道から、より柔軟でオーケストレーション重視のアプローチへとシフトしています。 あらかじめ定義されたトリガーや経路だけに頼るのではなく、トピックはモジュール化された指示として機能し、エージェントが会話をオーケストレーションする際に呼び出せるようになりました。 生成オーケストレーションは、ユーザーの入力を動的に解釈することでほとんどのルーティングを処理し、精度が必要なトピックは構造化されたフォールバックを提供します。
より伝統的な構造化されたトピックデザインは、会話を自然で効率的に感じさせます。 トピックは、ユーザーの発言によってトリガーされるエントリポイントや、リダイレクトやシステムイベントで呼び出される再利用可能なサブトピックである場合があります。 曖昧さ回避トピックは複数のトピックがトリガーされる場合の混乱を避け、フォールバックや会話促進トピックは、エージェントが意図を正確に一致できない場合の安全網を提供します。 また、外部の知識源から生成回答を引き出すための生成回答を重ねることも可能で、ユーザーが回答なしで過ごすことがほとんどないようにします。
詳細は 「著述トピックへのベストプラクティスの適用」をご覧ください。
ローカライズと言語
Copilot Studioエージェントが使用する言語は、システム変数の値である「 System.User.Language」によって決まります。
この変数はエージェント内のすべての言語関連動作の中央制御点として機能します。 手動で、プログラムで、または自動で検出することもできます。
それはどのように動作しますか?
ユーザーの言語で知識を検索する:Copilot Studioは
System.User.Languageの値を用いて指定された言語で知識ソースを検索します。 このアプローチでは、ユーザーが一つの言語で質問しても、エージェントは検索クエリをSystem.User.Languageに設定された言語に翻訳します(検索クエリの自動翻訳)。ユーザーの言語で応答する:エージェントは質問で使われている言語や元の文書に関係なく、
System.User.Languageが指定した言語で回答を生成します(回答生成のための自動翻訳)。手動オーバーライド:
System.User.Languageの値を手動設定して、エージェントに特定の言語で動作させることができます。 この機能はテストや言語を明示的に制御しなければならない状況に役立ちます。 詳細については、「 多言語エージェントの構成と作成」を参照してください。
自動検出音声
Copilot Studioでは、ユーザーの話し言葉や書き言葉を自動的に検出し、それに応じて System.User.Language 変数を設定することができます。 この機能により、ユーザーが言語の好みを指定することなく、シームレスな多言語体験が可能になります。
自動検知の仕組み
- トリガーベースの検出:ボットがメッセージを受信すると、トリガーが言語検出フローを開始します。
-
システム変数を設定する:ボットは検出した言語を
System.User.Languageに割り当てます。 - 動的応答:エージェントは検出された言語で会話を続け、知識を検索し、それに応じて応答を生成します。
メリット
- パーソナライズされた体験:ユーザーは手動設定なしで好みの言語で交流できます。
- 一貫した体験:すべての応答と知識の検索は検出または設定された言語と一致しています。
- スケーラブルソリューション:最小限の設定でグローバル展開をサポートします。
ヒント
Copilot Studioのエージェントがユーザーの話し言葉を自動的に検出し、エージェントがメーパニー承認の言語「自動検出言語」に切り替える方法を示すサンプルソリューションをレビューしてください
ローカリゼーションのベストプラクティス
- 対応言語の設定:エージェントのプライマリとセカンダリー言語を定義します。 ローカリゼーションファイル(JSONまたはResX)を使って、プロンプトやメッセージ、トピックの翻訳を提供します。
- 多言語シナリオのテスト:異なる言語でのユーザーインタラクションをシミュレートし、スムーズな移行と正確な応答を確保しましょう。
- 自動翻訳の活用:知識検索や回答生成にはCopilot Studioの組み込み翻訳を活用しつつ、重要な内容やニュアンスのある内容にはカスタム翻訳を提供しましょう。
- モニタリングと改善:言語使用を追跡し、時間をかけてローカリゼーションのカバレッジを改善する分析ツールを活用しましょう。
Copilot Studioエージェント言語アプローチ:
- 言語ごとに別のエージェントを配置してください。
- 単一の多言語エージェントと事前執筆済みの翻訳。
- リアルタイムの多言語エージェントで、ユーザーとエージェント間の翻訳サービスを利用しています。
適切なアプローチは、利用状況、分離、規模、更新の頻度、利用可能なリソースによって異なります。
特定された技術的課題
典型的な課題には、Azure CLUとCopilot Studioのトピックの同期管理、曖昧な発言の処理、多言語展開の拡大などが含まれます。 これらの障害を早期に特定することで、フォールバック構成、トリガーフレーズの一括テスト、リレーベースの翻訳サービスなどの緩和策を計画できます。
言語理解の目標は、すべてのエージェントがユーザーのクエリを正確に解釈し、多様な言語やシナリオに適応し、予期せぬ事態に優雅に対応できるようにすることです。 この目標は、信頼性が高く魅力的かつ効率的なCopilot Studioの会話を構築するための強固な基盤を築きます。