Prompt API は、Web サイトまたはブラウザー拡張機能の JavaScript コードから、Microsoft Edge に組み込まれている小規模言語モデル (SLM) を要求できる試験段階の Web API です。 Prompt API を使用して、テキストを生成して分析したり、ユーザー入力に基づいてアプリケーション ロジックを作成したり、プロンプト エンジニアリング機能を Web アプリケーションに統合する革新的な方法を見つけ出したりできます。
詳細な内容:
- Prompt API の可用性
- Prompt API の代替手段と利点
- Microsoft Edge に組み込まれている小さな言語モデル
- Phi-4 ミニ モデル
- Aion-1.0-Instruct モデル
- Prompt API を有効にする
- 動作する例を見る
- Prompt API を使用する
- フィードバック送信
- 関連項目
Prompt API の可用性
Prompt API は、バージョン 138.0.3309.2 以降の Microsoft Edge Canary および Edge Dev チャネルで開発者プレビューとして使用できます。
Prompt API は、ユース ケースを検出し、組み込みの SLM の課題を理解するのに役立ちます。 この API は、書き込み支援やテキスト翻訳など、AI を利用した特定のタスクに対する他の試験的な API によって成功することが期待されます。 これらの他の API の詳細については、以下を参照してください:
Prompt API の代替手段と利点
Web サイトとブラウザー拡張機能で AI 機能を活用するには、次のメソッドも使用できます:
Azure AI ソリューションなどのクラウドベースの AI サービスにネットワーク要求を送信します。
Web Neural Network (WebNN) API または ONNX Runtime for Web を使用してローカル AI モデルを実行します。
Prompt API は、モデルの入力と出力が使用されるのと同じデバイス (つまりローカル) で実行される SLM を使用します。 これには、クラウドベースのソリューションと比較して次の利点があります:
コスト削減: クラウド AI サービスの使用に関連するコストはありません。
ネットワークの独立性: 初期モデルのダウンロードを超えて、モデルを要求するときにネットワーク待ち時間は発生せず、デバイスがオフラインのときにも使用される可能性があります。
プライバシーの強化: モデルへのデータ入力はデバイスから離れることはなく、AI モデルをトレーニングするために収集されることはありません。
Prompt API は、Microsoft Edge によって提供され、ブラウザーに組み込まれているモデルを使用します。このモデルには、WebGPU、WebNN、WebAssembly 6に基づくカスタム ローカル ソリューションよりも優れた利点があります:
共有の 1 回限りのコスト: ブラウザーで実行されているすべての Web サイトで API が初めて呼び出されて共有されるときに、ブラウザーが提供するモデルがダウンロードされ、ユーザーと開発者のネットワーク コストが削減されます。
Web 開発者向けの簡略化された使用: 組み込みモデルは、単純な Web API を使用して実行でき、AI/ML の専門知識やサードパーティのフレームワークを使用する必要はありません。
Microsoft Edge に組み込まれている小さな言語モデル
Microsoft Edge Canary チャネルと Dev チャネルでは、バージョン 138.0.3309.2 以降では、Prompt API は、Microsoft Edge に組み込まれている Phi-4-mini モデルを使用します。
バージョン 150.0.4070 以降では、Prompt API は、Microsoft Edge にも組み込まれているプレリリース Aion-1.0-Instruct モデルでも使用できます。 Aion-1.0-Instruct は Phi-4-mini よりも小さく、高速で効率的なモデルであり、CPU 推論を使用して、GPU の能力が低いデバイスまたは GPU がないデバイスでサポートされています。 デバイスのパフォーマンス クラスが Phi-4-mini をサポートするのに十分な高さでない場合は、プレリリース Aion-1.0-Instruct モデルをテストできます。
両方のモデルの詳細と、Aion-1.0-Instruct を有効にする方法については、以下のセクションを参照してください。
Phi-4 ミニ モデル
Prompt API を使用すると、Microsoft Edge に組み込まれている Phi-4-mini をプロンプトできます。 Phi-4-mini は、テキストベースのタスクに優れた強力な小さな言語モデルです。 Phi-4-mini とその機能の詳細については、microsoft/Phi-4-mini-instruct のモデル カードを参照してください。
免責事項
他の言語モデルと同様に、Phi ファミリのモデルは、不公平、信頼性の低い、または不快感を与える方法で動作する可能性があります。 モデルの AI に関する考慮事項の詳細については、応答可能な AI に関する考慮事項を参照してください。
ハードウェア要件
Prompt API 開発者プレビューは、予測可能な品質と待機時間を備えた SLM 出力を生成するハードウェア機能を備えたデバイスで動作することを目的としています。 Prompt API は現在、以下に制限されています:
オペレーティング システム: Windows 10 または 11 および macOS 13.3 以降。
ストレージ: Edge プロファイルを含むボリュームで 20 GB 以上使用できます。 使用可能なストレージが 10 GB を下回ると、他のブラウザー機能が機能するのに十分な領域を確保するためにモデルが削除されます。
GPU: 5.5 GB 以上の VRAM。
ネットワーク: 無制限データ プランまたは測定されていない接続。 従量制課金接続を使用している場合、モデルはダウンロードされません。
お使いのデバイスが Prompt API 開発者プレビューをサポートしているかどうかを確認するには、以下の「Prompt API を有効にする」を参照し、デバイスのパフォーマンス クラスを確認してください。
Prompt API の実験的な性質により、特定のハードウェア構成で問題が発生する場合があります。 特定のハードウェア構成に関する問題が発生した場合は、MSEdgeExplainers リポジトリで新しいイシューを開いてフィードバックをお寄せください。
Phi-4-mini モデルの可用性
Web サイトがデバイス上のモデルを必要とする API を初めて呼び出す場合は、Phi-4-mini モデルの初期ダウンロードが必要です。 新しい Prompt API セッションの作成時に monitor オプションを使用して、Phi-4-mini モデルのダウンロードを監視できます。 詳細については、以下の「モデルのダウンロードの進行状況を監視する」を参照してください。
Aion-1.0-Instruct モデル
Microsoft Edge Canary または Edge Dev では、バージョン 150.0.4070 以降では、Microsoft Edge に組み込まれているプレリリース Aion-1.0-Instruct モデルでも Prompt API を使用できます。
この Aion-1.0-Instruct モデルは、Phi-4-mini よりも大幅に小さく、高速で効率的であり、CPU 推論を介して、GPU の能力が低いデバイスまたは GPU がないデバイスでサポートされています。
Aion-1.0-Instruct は、2026 年 7 月にオープンソース モデルとして使用できるようになる予定です。
プロンプト API に対して Aion-1.0-Instruct を有効にする
既定では、Prompt API は Phi-4-mini モデルを使用します。 Microsoft Edge Canary または Edge Dev で Aion-1.0-Instruct を使用するには、次の手順で説明するように、[ デバイス上のプレリリース言語モデルを有効にする] フラグを有効にします 。 このフラグを有効にすると、Aion-1.0-Instruct によって、Prompt API の既定のモデルとして Phi-4-mini がオーバーライドされます。
最新バージョンの Edge Canary または Edge Dev (バージョン 150.0.4070 以降) を使用していることを確認します。 「Microsoft Edge Insider になる」を参照してください。
Edge Canary または Edge Dev で、新しいタブまたはウィンドウを開き、[
edge://flags] に移動します。ページの上部にある検索ボックスに、「 デバイス上のプレリリース言語モデルを有効にする」と入力します。
[ デバイス上でプレリリースを有効にする言語モデル ] ドロップダウン リストで、[ 有効] を選択し、[ 再起動 ] ボタンをクリックします。
![プレリリースオンデバイス言語モデル フラグを示す [フラグ] ページ](prompt-api-images/prerelease-model-flag-for-prompt-api.png)
Aion-1.0-Instruct がデバイス上の言語モデルとして使用されていることをチェックするには、[
edge://on-device-internals] に移動し、[モデルの状態] をクリックし、[モデル名] が Aion-1.0-Instruct に設定されていることをチェックします。
免責事項
Aion-1.0-Instruct モデルは、Microsoft Edge 150.0.4070 で早期開発者のテストとフィードバックのために利用できます。 上記の責任ある AI に関する考慮事項に加えて、プレリリース状態を考慮すると、モデルの動作と機能が変更される可能性があることに注意してください。
Aion-1.0-Instruct モデルの可用性
Aion-1.0-Instruct モデルの最初のダウンロードは、Web サイトがデバイス上のモデルを必要とする API を初めて呼び出す際に必要です。 新しい Prompt API セッションの作成時に monitor オプションを使用して、Aion-1.0-Instruct モデルのダウンロードを監視できます。 詳細については、以下の「モデルのダウンロードの進行状況を監視する」を参照してください。
Prompt API を有効にする
Microsoft Edge で Prompt API を使用するには:
最新バージョンの Microsoft Edge Canary または Edge Dev (バージョン 138.0.3309.2 以降) を使用していることを確認します。 「Microsoft Edge Insider になる」を参照してください。
Edge Canary または Edge Dev で、新しいタブまたはウィンドウを開き、[
edge://flags/] に移動します。検索ボックスのページの上部に、「 デバイス上の言語モデルの API のプロンプト」と入力します。
ページがフィルター処理され、一致するフラグが表示されます。
[ オンデバイス言語モデルの API のプロンプト] で、[ 有効] を選択します。
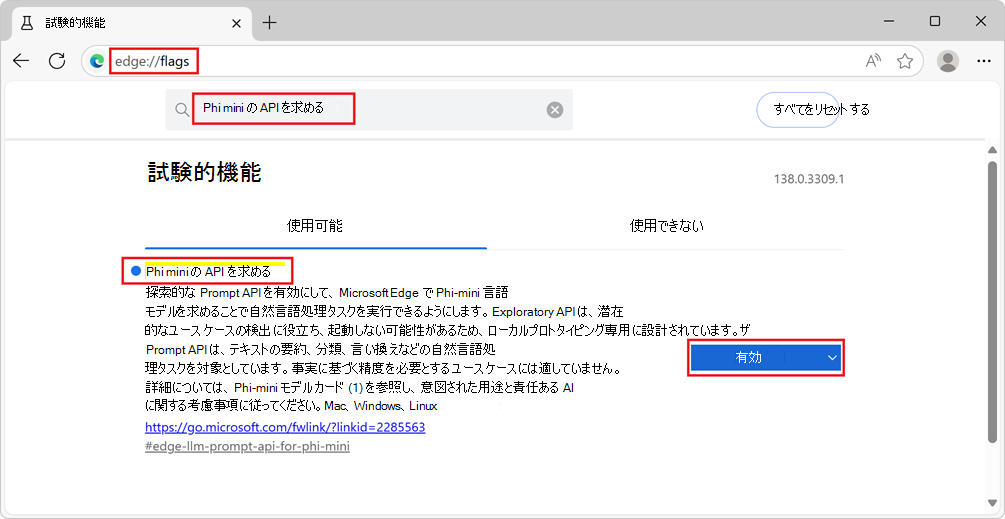
必要に応じて、問題のデバッグに役立つ可能性がある情報をローカルにログに記録するには、デバイス AI モデルのデバッグ ログ フラグを有効にします。
Edge Canary または Edge Dev を再起動します。
お使いのデバイスが Prompt API 開発者プレビューのハードウェア要件を満たしているかどうかを確認するには、新しいタブを開き、
edge://on-device-internalsに移動して、デバイス パフォーマンス クラス値を確認します。デバイス パフォーマンス クラスが "高" 以上の場合は、Prompt API がデバイスでサポートされている必要があります。
デバイス のパフォーマンス クラスが [中] または [低] の場合、Prompt API はプレリリース Aion-1.0-Instruct モデル (Edge バージョン 150.0.4070 以降) でのみサポートされます。 Aion-1.0-Instruct モデルをテストするには、上記の 「プロンプト API に対して Aion-1.0-Instruct を有効にする」を参照してください。
これらのモデルで問題が発生した場合は、MSEdgeExplainers リポジトリに 新しい問題を作成 してください。
動作する例を見る
Prompt API の動作を確認し、API を使用する既存のコードを確認するには:
前述のように、Prompt API を有効にします。
[Edge Canary] または [Edge Dev] で、タブまたはウィンドウを開き、[ プロンプト API] プレイグラウンドに移動します。
左側の [組み込み AI プレイグラウンド] ナビゲーションで、Prompt が選択されています。
上部の情報バナーで、状態を確認します。最初に Model のダウンロードが読み込まれます。しばらくお待ちください:
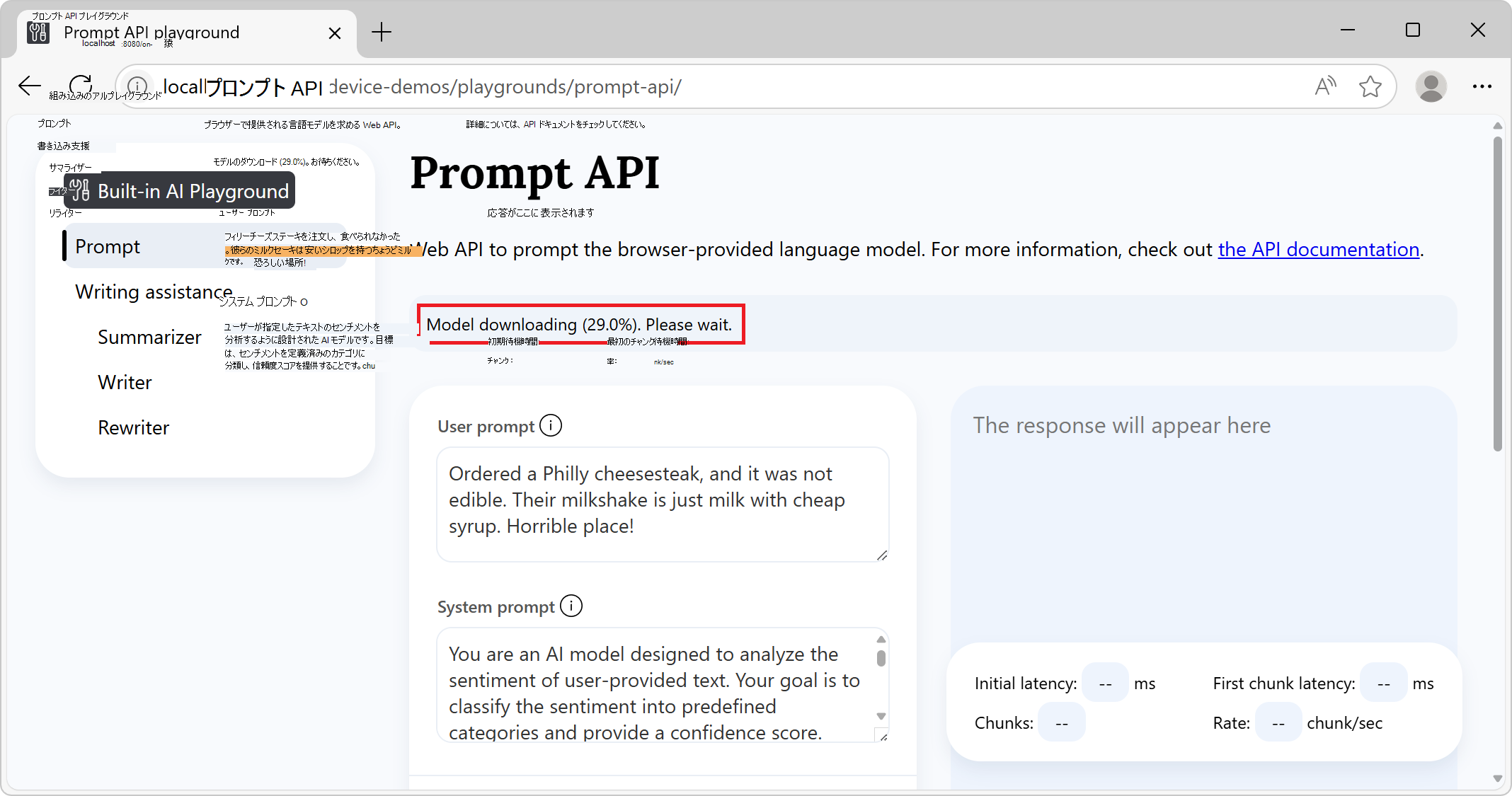
モデルがダウンロードされると、情報バナーには "API とモデルの準備完了" と表示されます。これは、API とモデルを使用できることを示します。
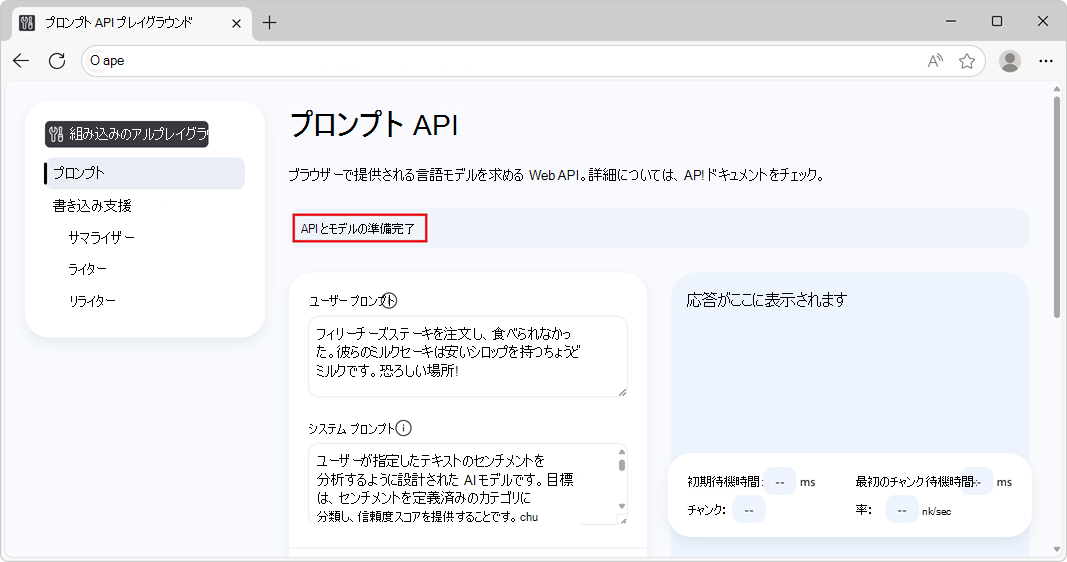
モデルのダウンロードが開始されない場合は、Microsoft Edge を再起動して、もう一度やり直してください。
Prompt API は、特定のハードウェア要件を満たすデバイスでのみサポートされます。 詳細については、上記の「ハードウェア要件」を参照してください。
必要に応じて、次のようなプロンプト設定の値を変更します:
- ユーザー プロンプト
- システム プロンプト
- 応答制約スキーマ
- [その他の設定]>[N ショット プロンプトの手順]
ページの下部にある [プロンプト] ボタンをクリックします。
応答は、ページの応答セクションで生成されます:
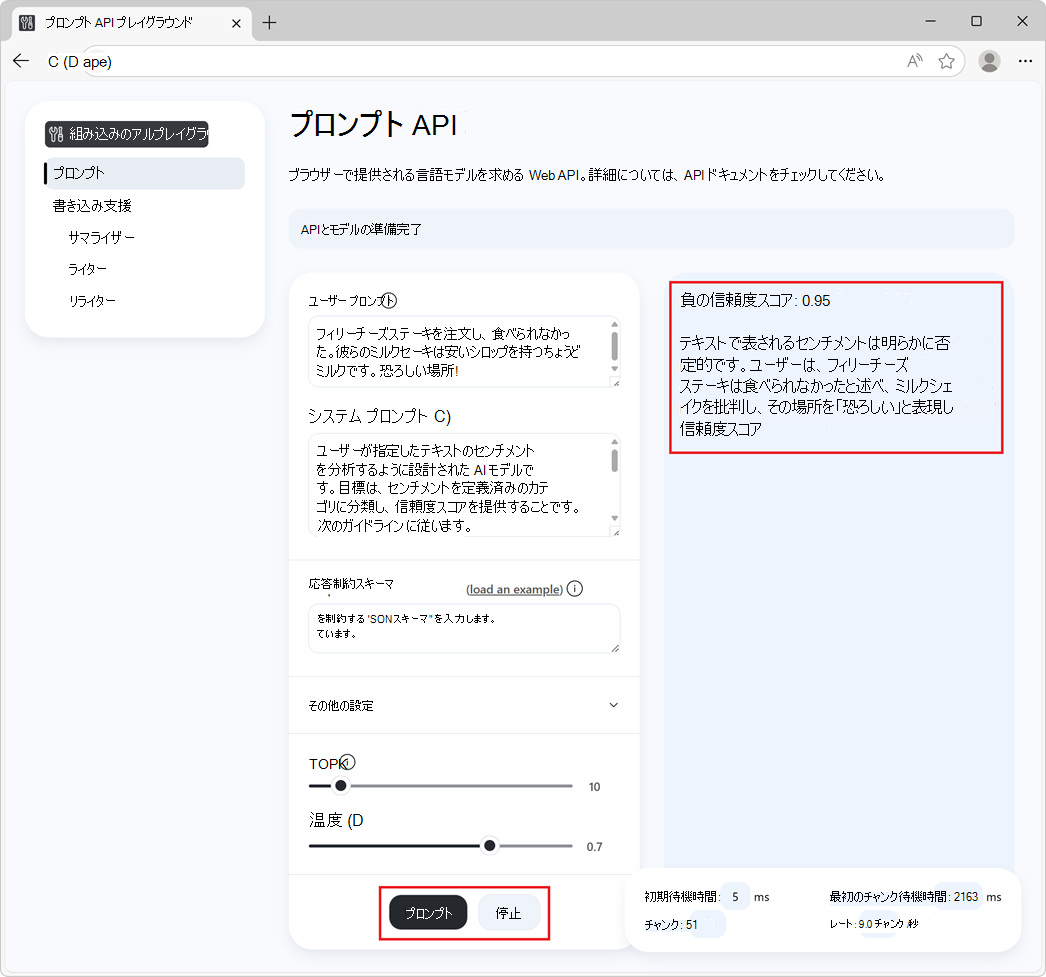
応答の生成を停止するには、いつでも [停止] ボタンをクリックします。
関連項目:
- /built-in-ai/ - Prompt API プレイグラウンドを含む組み込みの AI プレイグラウンドのソース コードと Readme。
Prompt API を使用する
API が有効かどうかを確認する
Web サイトまたは拡張機能のコードで API を使用する前に、LanguageModel オブジェクトの存在をテストして API が有効になっていることを確認します:
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
モデルを使用できるかどうかを確認する
Prompt API は、デバイスがモデルの実行をサポートし、言語モデルとモデル ランタイムが Microsoft Edge によってダウンロードされた場合にのみ使用できます。
API を使用できるかどうかを確認するには、LanguageModel.availability() メソッドを使用します:
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
新しいセッションを作成する
セッションを作成すると、言語モデルをメモリに読み込んで使用できるようにブラウザーに指示されます。 言語モデルを確認する前に、create() メソッドを使用して新しいセッションを作成します:
// Create a LanguageModel session.
const session = await LanguageModel.create();
モデル セッションをカスタマイズするには、create() メソッドにオプションを渡します:
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
利用可能なオプションは以下のとおりです。
monitor:モデルのダウンロードの進行状況を追跡します。initialPrompts: モデルに送信されるプロンプトに関するモデル コンテキストを提供し、今後のプロンプトに対してモデルが従う必要があるユーザー/アシスタント操作のパターンを確立します。
これらのオプションについては、以下で説明します。
モデルのダウンロードの進行状況を監視する
monitor オプションを使用して、モデルのダウンロードの進行状況を追跡できます。 これは、モデルが使用されるデバイスにまだ完全にダウンロードされていない場合に役立ち、ユーザーが待機する必要があることを Web サイトに通知します。
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
モデルにシステム プロンプトを提供する
プロンプトに応答してテキストを生成する際に、モデルに使用する命令を与える方法であるシステム プロンプトを定義するには、initialPrompts オプションを使用します。
新しいセッションを作成するときに指定するシステム プロンプトは、プロンプトの数が多すぎるためにコンテキスト ウィンドウがオーバーフローした場合でも、セッションの存在全体に対して保持されます。
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
initialPrompts の 0 番目の位置以外の任意の場所に { role: "system", content: "You are a helpful assistant." } プロンプトを配置すると、TypeError で拒否されます。
initialPrompts を使用した N ショット プロンプト
initialPrompts オプションを使用すると、プロンプトが表示されたときにモデルで引き続き使用するユーザー/アシスタント操作の例を提供することもできます。
この手法は N ショット プロンプトとも呼ばれ、モデルによって生成される応答をより決定的なものにするのに役立ちます。
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
セッションを複製して、同じオプションを使用して会話を再度開始する
既存のセッションを複製して、前の操作の知識がなくても、同じセッション オプションを使用してモデルにプロンプトを表示します。
セッションの複製は、前のセッションのオプションを使用するが、以前の応答でモデルに影響を与えずに使用する場合に便利です。
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
]
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
モデルにプロンプトを与える
モデルセッションを作成した後、モデルにプロンプトを表示するには、session.prompt() メソッドまたは session.promptStreaming() メソッドを使用します。
最終的な応答を待つ
prompt メソッドは、プロンプトに応答してモデルがテキストの生成を完了すると解決される promise を返します:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
生成されたトークンを表示する
promptStreaming メソッドは、ストリーム オブジェクトをすぐに返します。 そのストリームを使用して、生成中の応答トークンを表示します:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
同じセッション オブジェクト内で prompt メソッドと promptStreaming メソッドを複数回呼び出して、そのセッション内のモデルとの以前の対話に基づくテキストの生成を続けることができます。
JSON スキーマまたは正規表現を使用してモデル出力を制約する
モデル応答の形式をより明確にし、プログラムによる方法で使いやすくするには、モデルにプロンプトを表示するときに responseConstraint オプションを使用します。
responseConstraint オプションは、JSON スキーマまたは正規表現を受け入れます:
特定のスキーマに従う文字列化された JSON オブジェクトでモデルが応答するようにするには、使用する JSON スキーマに
responseConstraintを設定します。正規表現に一致する文字列でモデルが応答するようにするには、
responseConstraintをその正規表現に設定します。
次の例は、特定のスキーマに従う JSON オブジェクトを使用して、モデルがプロンプトに応答する方法を示しています:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
上記のコードを実行すると、次のような文字列化された JSON オブジェクトを含む応答が返されます:
{"sentiment": "negative", "confidence": 0.95}
その後、JSON.parse() 関数を使用して解析することで、コード ロジックで応答を使用できます:
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
プロンプトごとに複数のメッセージを送信する
文字列に加えて、prompt メソッドと promptStreaming メソッドは、カスタム ロールを持つ複数のメッセージを送信するために使用されるオブジェクトの配列も受け取ります。 送信するオブジェクトは { role, content } 形式にする必要があります。なお、role は user または assistantで、content はメッセージです。
たとえば、同じプロンプトで複数のユーザー メッセージとアシスタント メッセージを提供するには:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
テキストの生成を停止する
session.prompt() によって返される promise が解決される前、または session.promptStreaming() によって返されるストリームが終了する前にプロンプトを中止するには、AbortController シグナルを使用します:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
セッションを破棄する
セッションを破棄して、言語モデルが不要であることをブラウザーに知らせ、モデルをメモリからアンロードできるようにします。
セッションは、次の 2 つの方法で破棄できます:
-
destroy()メソッドを使用すると。 -
AbortControllerを使用すると。
destroy() メソッドを使用してセッションを破棄する
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
AbortController を使用してセッションを破棄する
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
フィードバックの送信
Prompt API 開発者プレビューは、ブラウザーが提供する言語モデルのユース ケースを検出するのに役立ちます。
次のことについて学習することに興味があります。
- Prompt API を使用するシナリオの範囲。
- Prompt API に関する問題。
- 言語モデルに関する問題。
- 新しいタスク固有の API が役に立つかどうか。
シナリオと達成したいタスクに関するフィードバックを送信するには、Prompt API フィードバック イッシューにコメントを追加してください。
代わりに API を使用する際に問題が発生した場合は、リポジトリに報告してください。
また、W3C Web Machine Learning Working Group リポジトリで Prompt API の設計に関するディスカッションに投稿することもできます。
関連項目
- プロンプト API ドラフト仕様
- webmachinelearning/prompt-api GitHub リポジトリ
- Writing Assistance API を使用してテキストを書き、リライトし、要約する
- Proofreader API を使用してテキストの文法、スペル、句読点のエラーを修正する
- Translator API を使用してテキストを翻訳する
- /built-in-ai/ - Prompt API プレイグラウンドを含む組み込みの AI プレイグラウンドのソース コードと Readme。