[この記事はプレリリース ドキュメントであり、変更されることがあります。]
Power Automate Process Mining では、Fabric Lakehouse を経由して、Fabric OneLake からイベント ログ データ ファイルを直接保存し、読み込むことができます。 この機能は、OneLake に直接接続することで、抽出、変換、読み込み (ETL) 管理を簡素化します。
この機能は現在、以下の取り込みをサポートしています:
-
CSV
- ひとつの CSV ファイル。
- 同じ構造を持つ複数の CSV ファイルを含むフォルダー。 すべてのファイルが取り込まれます。
-
Parquet
- ひとつの parquet ファイル。
- 同じ構造を持つ複数の Parquet ファイルを含むフォルダー。 すべてのファイルが取り込まれます。
-
Delta-parquet
- delta-parquet 構造を含むフォルダ。
重要
- これはプレビュー機能です。
- プレビュー機能は運用環境での使用を想定しておらず、機能が制限されている可能性があります。 これらの機能を公式リリースの前に使用できるようにすることで、顧客が事前にアクセスし、そこからフィードバックを得ることができます。
- 詳細については、条件のプレビュー を参照してください。
前提条件
OneLake テナント設定で、ユーザーが Fabric 以外のアプリから OneLake に保存されたデータにアクセスできるようにする オプションがオンになっていることを確認します。
既定の マイ ワークスペース とは異なる Fabric ワークスペース。
管理者ロールは、同じ環境にいる他のユーザーのために、環境のワークスペースの初期セットアップを実行するユーザーに割り当てられている必要があります。
Fabric ワークスペースは、Process Insight Prod サービス プリンシパルに管理者ロールで共有する必要があります。 プロセス分析 Prod のサービス プリンシパルを登録するには、Azure ツールのインストールの手順に従ってください。
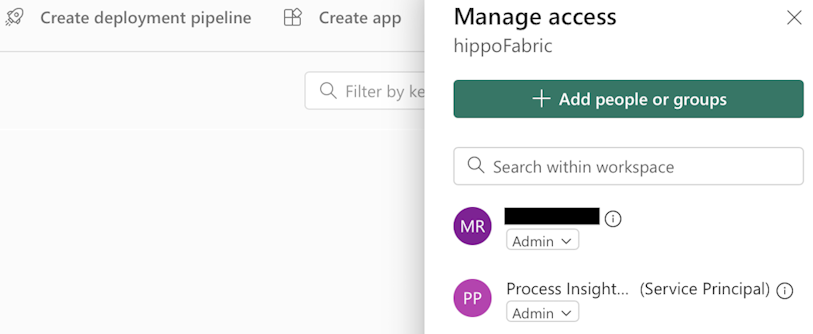
Fabric Lakehouse は、レイクハウスの ファイル フォルダにあるサポートされているフォーマットのデータと一緒に、このワークスペースで作成する必要があります。
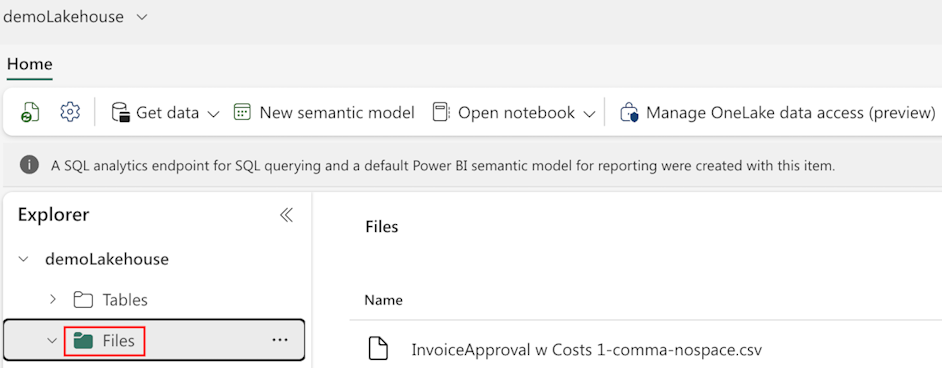
重要
以下の項目は現在サポートされていません:
- スキーマ サポートが有効になっている Fabric レイクハウス。
- レイクハウス の差分テーブル。
レイクハウス の CSV データは、次の CSV ファイル形式の要件を満たしている必要があります。
- 圧縮の種類: なし
- 列区切り記号: カンマ (,)
- 行区切り文字: 既定およびエンコード。 例: 既定 (\r、\n、または \r\n)
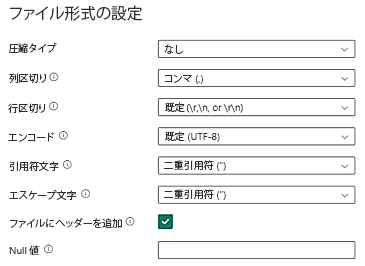
すべてのデータは最終イベント ログ形式であり、データ要件にリストされている要件を満たしている必要があります。 データをプロセス マイニング スキーマにマッピングする準備ができている必要があります。 インジェスト後に使用できるデータ変換はありません。
ヘッダー行のサイズ (幅) は現在 1 MB に制限されています。
重要
CSV ファイルで表されるタイム スタンプが ISO 8601 標準形式 ( YYYY-MM-DD HH:MM:SS.sss または YYYY-MM-DDTHH:MM:SS.sss など) に従っていることを確認します。
Fabric OneLake への接続
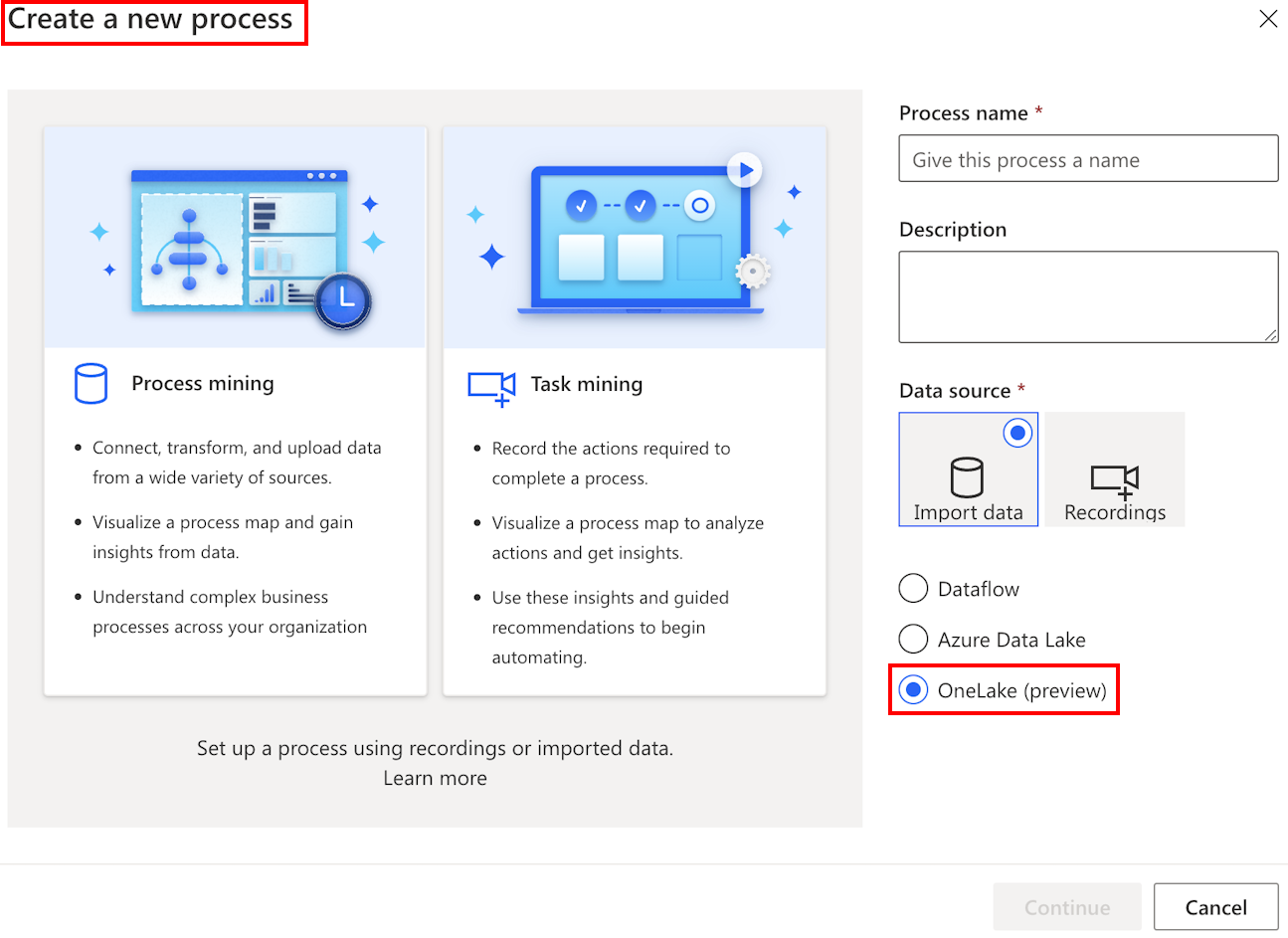
左側のナビゲーション ウィンドウで、プロセス マイニング>ここから開始を選択します。
プロセス名フィールドにプロセスの名前を入力します。
データ ソース ヘッダーの配下で、データのインポート>OneLake (プレビュー)>続けるを選択します。
オプションの Power BI ワークスペースを選択するか、スキップ を選択します。
接続設定画面で、ドロップダウン メニューからファブリック ワークスペースを選択します。 Lakehouse のドロップダウン メニューが表示されます。 メニューからデータ ファイルのあるレイクハウスを選択し、次へを選択します。
Lakehouse のフォルダ構造を参照し、イベント ログ データを含むファイルまたはフォルダを選択します。
単一のファイルを選択することも、複数のファイルが含まれるフォルダーを選択することもできます。 すべてのファイルは同じヘッダーと形式でなければなりません。
次へを選択します。
データのマッピング画面で、データを必要なスキーマにマッピングします。
![[データのマッピング] 画面のスクリーンショット。](media/process-mining-files-fabric-onelake/map.png)
保存して分析を選択して接続を完了します。
増分データ更新の設定を定義する
Fabric OneLake から取り込まれたプロセスは、完全更新または増分更新のいずれかのスケジュールで更新することができます。 保持ポリシーはありませんが、次のいずれかの方法を使用してデータを段階的に取り込むことができます。
前のセクションで 単一ファイル を選択した場合、選択したファイルに他のデータを追加します。
前の画面で フォルダー を選択した場合、選択したフォルダーに増分ファイルを追加します。
重要
選択したフォルダまたはサブフォルダに増分ファイルを追加するときは、YYYYMMDD.csv または YYYYYMMDDHHMMSS.csv などの日付でファイル名を付けることによって、増分順序を示す必要があります。
プロセスを最新の情報に更新するには、次の手順を実行します。
プロセスの詳細ページに移動します。
更新設定を選択します。
スケジュールの更新画面で、次の手順を完了します。
- データを最新に維持するトグル スイッチをオンにします。
- データの更新間隔 ドロップダウン リストで、更新の頻度を選択します。
- 開始時刻フィールドで、更新の日時を選択します。
- 増分更新 トグル スイッチをオンにします。