この記事では、データマートの重要な概念について説明します。
Von Bedeutung
Power BI データマート機能は、2025 年 10 月に廃止される予定です。 データマート上に構築されたデータが失われ、レポートが壊れないようにするには、 Power BI Datamart を Warehouse にアップグレードする必要があります。 詳細については、「 Datamart と Fabric Data Warehouse の統合」を参照してください。
セマンティック モデル (既定値) の概要
データマートには、セマンティック レイヤーが用意されていて、これは、自動的に生成され、データマート テーブルの内容、その構造、および基になるデータと同期されます。 このレイヤーは、自動的に生成されたセマンティック モデル内で提供されます。 この自動生成と同期により、階層、フレンドリ名、説明などを使用して、データのドメインをさらに詳しく説明できます。 ロケールまたはビジネス要件に固有の書式設定を設定することもできます。 データマートを使用すると、レポート用のメジャーと標準化されたメトリックを作成することができます。 Power BI (およびその他のクライアント ツール) では、ビジュアルを作成し、コンテキスト内のデータに基づいてこのような計算の結果を提供できます。
データマートから作成された既定の Power BI セマンティック モデルを使用すると、個別のセマンティック モデルに接続したり、更新スケジュールを設定したり、複数のデータ要素を管理したりする必要がなくなります。 代わりに、データマートでビジネス ロジックを構築でき、そのデータは Power BI ですぐに使用でき、次の機能が有効になります。
- セマンティック モデル ハブを介したデータマート データ アクセス。
- Excel で分析する機能。
- Power BI サービスでレポートをすばやく作成する機能。
- 更新、データの同期、または接続の詳細を理解する必要はありません。
- Power BI Desktop を必要とせずに Web 上でソリューションを構築する。
プレビュー期間中は、既定のセマンティック モデル接続は DirectQuery のみを使用して使用できます。 次の図は、データへの接続からレポートの作成まで、データマートがプロセス コンティニュアムにどのように適合するかを示しています。
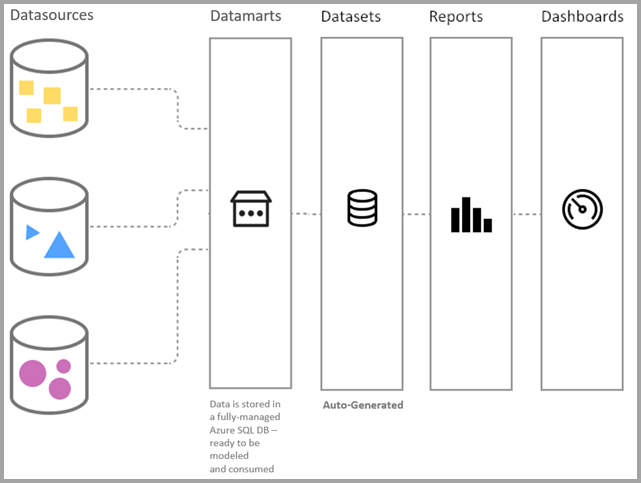
既定のセマンティック モデルは、従来の Power BI セマンティック モデルとは次の点が異なります。
- XMLA エンドポイントでは読み取り専用操作をサポートしており、ユーザーはセマンティック モデルを直接編集できません。 XMLA の読み取り専用アクセス許可を使用すると、クエリ ウィンドウでデータに対してクエリを実行できます。
- 既定のセマンティック モデルにはデータ ソース設定がなく、ユーザーは資格情報を入力する必要はありません。 代わりに、クエリには自動シングル サインオン (SSO) を使用します。
- 更新操作の場合、セマンティック モデルではセマンティック モデル作成者の資格情報を使って、マネージド データマートの SQL エンドポイントに接続します。
Power BI Desktop では、ユーザーは複合モデルを構築できるため、データマートのセマンティック モデルに接続して次の操作を行うことができます。
- 分析する特定のテーブルを選択します。
- データ ソースをさらに追加します。
最後に、既定のセマンティック モデルを直接使用しない場合は、データマートの SQL エンドポイントに接続できます。 詳細については、「データマートを使用してレポートを作成する」を参照してください。
既定のセマンティック モデルの内容を理解する
現在、データマート内のテーブルは既定のセマンティック モデルに自動的に追加されます。 柔軟性を高めるために、ユーザーはモデルに含めるテーブルまたはビューをデータマートから手動で選択することもできます。 既定のセマンティック モデル内にあるオブジェクトは、モデル ビューのレイアウトとして作成されます。
オブジェクト (テーブルとビュー) を含むバックグラウンド同期は、ダウンストリーム セマンティック モデルがセマンティック モデルの更新に使用されないのを待機し、有界整合性制約を受け入れられます。 ユーザーは常に、セマンティック モデル内で必要なテーブルまたは不要なテーブルを手動で選択できます。
増分更新とデータマートについて
データマート エディターを使用して、データフローやセマンティック モデルの増分更新と同様に、増分データ更新を作成および変更できます。 増分更新では、新規および更新されたデータを頻繁に読み込むデータマート テーブルの自動パーティション作成と管理を行うことによって、スケジュールされた更新操作を拡張します。
ほとんどのデータマートでは、増分更新には、頻繁に変化し、リレーショナル データベース スキーマやスター データベース スキーマのファクト テーブルなど、指数関数的に増加する可能性があるトランザクション データを含む 1 つ以上のテーブルが含まれます。 増分更新ポリシーを使用してテーブルをパーティション分割し、最新のインポート パーティションのみを更新すると、更新する必要があるデータの量を大幅に削減できます。
データマートの増分更新とリアルタイム データには、次の利点があります。
- 高速に変化するデータの更新サイクルを減らす
- 更新が速くなる
- 更新の信頼性が高くなる
- リソースの消費量が減る
- 大規模なデータマートを作成できる
- 構成が容易
プロアクティブ キャッシュについて
プロアクティブ キャッシュを使用すると、既定のセマンティック モデルの基になるデータを自動的にインポートできるため、ストレージ モードを管理または調整する必要がなくなります。 既定のセマンティック モデルのインポート モードでは、高速 Vertipaq エンジンを使うことで、データマートのセマンティック モデルのパフォーマンスが高速化されます。 プロアクティブ キャッシュを使用すると、Power BI によってインポートするモデルのストレージ モードが変更され、Power BI と Analysis Services でメモリ内エンジンが使われるようになります。
プロアクティブ キャッシュは次のように機能します。更新のたびに、既定のセマンティック モデルのストレージ モードが DirectQuery に変更されます。 プロアクティブ キャッシュは、サイドバイサイド インポート モデルを非同期的に構築し、データマートによって管理され、データマートの可用性やパフォーマンスには影響しません。 既定のセマンティック モデルの完成後に受け取るクエリでは、インポート モデルが使用されます。
インポート モデルの自動生成は、データマートで変更が検出されなくなってから約 10 分以内に行われます。 インポート セマンティック モデルは、次の方法で変更されます。
- 更新
- 新しいデータ ソース
- スキーマの変更:
- 新しいデータ ソース
- Power Query Online のデータ準備手順の更新
- 次のようなモデリングの更新:
- メジャー
- 階層
- 説明
プロアクティブ キャッシュに関するベスト プラクティス
パフォーマンスを最高にし、ユーザーがインポート モデルを確実に使うようにするため、変更には "デプロイ パイプライン" を使います。 "デプロイ パイプライン" の使用は既にデータマートを構築するためのベスト プラクティスですが、そのようにすると、プロアクティブ キャッシュのメリットをより頻繁に得られます。
プロアクティブ キャッシュに関する考慮事項と制限
- 現在、Power BI ではキャッシュ操作の継続時間が 10 分に制限されています。
- インポート モデルでは、特定の列に対する一意性/null 以外の制約が適用され、データが準拠していない場合、キャッシュの構築は失敗します。
関連するコンテンツ
この記事では、理解すべき重要なデータマートの概念の概要について説明しました。
データマートと Power BI の詳細については、以下の記事を参照してください。
データフローとデータ変換の詳細については、次の記事を参照してください。