適用されるのは Power Platform Well-Architected Securityチェックリストの推奨事項です:
| SE:11 | 局所的な問題から災害復旧まで、さまざまなインシデントをカバーする効果的なインシデント対応手順を定義およびテストします。 手順を実行するチームまたは個人を明確に定義します。 |
|---|
このガイドでは、ワークロードのセキュリティ インシデント対応を実装するための推奨事項について説明します。 システムにセキュリティ侵害が発生した場合、体系的なインシデント対応アプローチは、セキュリティ インシデントの特定、管理、緩和にかかる時間の短縮に役立ちます。 これらのインシデントは、ソフトウェア システムとデータの機密性、完全性、可用性を脅かす可能性があります。
ほとんどの企業には、中央のセキュリティ運用チーム (セキュリティ オペレーション センター (SOC) または SecOps) があります。 セキュリティ運用チームの責任は、潜在的な攻撃を迅速に検出し、優先順位を付け、優先順位を付けることです。 また、チームはセキュリティ関連のテレメトリ データを監視し、セキュリティ侵害を調査します。
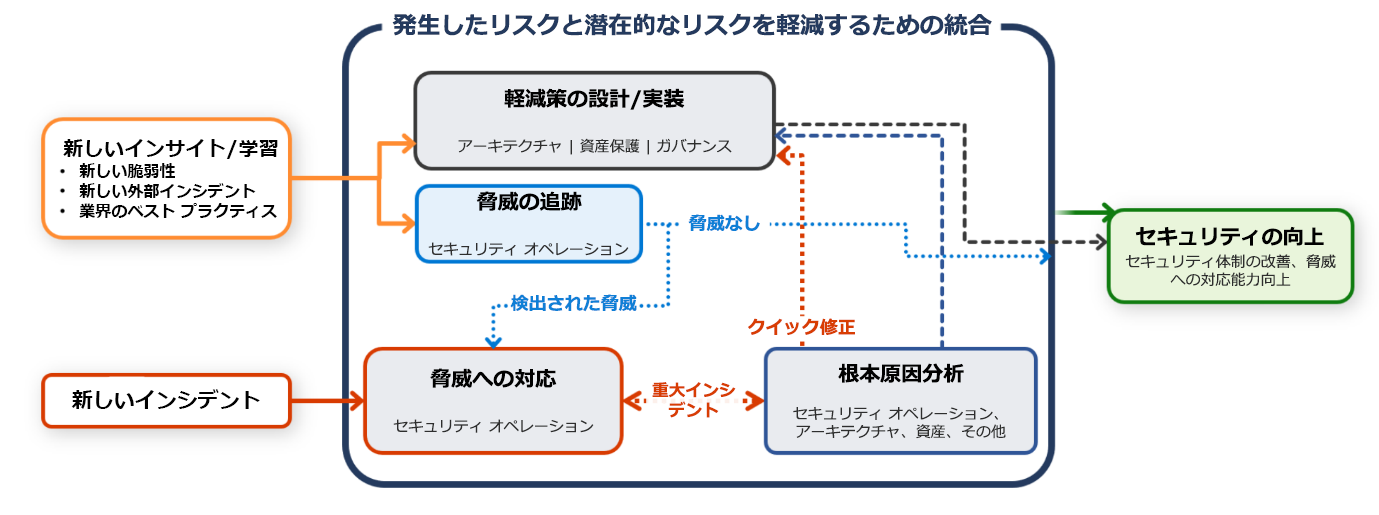
ただし、ワークロードを保護する責任もあります。 あらゆるコミュニケーション、調査、ハンティング活動は、ワークロード チームと SecOps チームの共同作業であることが重要です。
このガイドでは、攻撃を迅速に検出、トリアージ、調査できるように、ユーザーとワークロード チーム向けの推奨事項を示します。
定義
| 任期 | Definition |
|---|---|
| アラート | インシデントに関する情報が含まれる通知。 |
| アラートの忠実度 | アラートを決定するデータの精度。 高忠実度のアラートには、即時のアクションを実行するために必要なセキュリティ コンテキストが含まれています。 忠実度の低いアラートには情報が不足しているか、ノイズが含まれています。 |
| 誤検知 | 発生しなかったインシデントを示すアラート。 |
| インシデント | システムへの不正アクセスを示すイベント。 |
| インシデントの応答 | インシデントに関連するリスクを検出し、対応し、軽減するプロセス。 |
| トリアージ | セキュリティの問題を分析し、その軽減策を優先順位付けするインシデント対応操作。 |
主要な設計戦略
信号またはアラートが潜在的なセキュリティ インシデントを示している場合、皆さんと皆さんのチームはインシデント対応操作を実行します。 忠実度の高いアラートには、アナリストが意思決定を下すのに役立つ十分なセキュリティ コンテキストが含まれています。 忠実度の高いアラートにより、誤検知の数が少なくなります。 このガイドでは、アラート システムが低忠実度の信号をフィルターし、実際のインシデントを示す可能性のある高忠実度のアラートに焦点を当てていることを前提としています。
インシデント通知の割り当て
セキュリティ アラートは、チームや組織内の適切な人々に届く必要があります。 インシデント通知を受け取るための指定された連絡先をワークロード チームに確立します。 これらの通知には、侵害されたリソースとシステムに関する可能な限り多くの情報を含める必要があります。 チームが迅速に対応できるように、アラートには次のステップを含める必要があります。
監査証跡を残す専用のツールを使用して、インシデントの通知とアクションを記録および管理することをお勧めします。 標準ツールを使用することで、潜在的な法的調査に必要となる可能性のあるエビデンスを保存できます。 責任のある当事者の責任に基づいて通知を送信できる自動化を実装する機会を探してください。 インシデント発生中は、明確なコミュニケーションと報告の連鎖を維持します。
組織が提供するセキュリティ情報イベント管理 (SIEM) ソリューションやセキュリティ オーケストレーション自動応答 (SOAR) ソリューションを活用してください。 あるいは、インシデント管理ツールを調達し、組織がすべてのワークロード チームに対してそれらを標準化するように促すこともできます。
トリアージ チームによる調査
インシデント通知を受け取ったチーム メンバーは、入手可能なデータに基づいて適切な担当者が関与するトリアージ プロセスを設定する責任があります。 トリアージ チーム (別称 ブリッジチーム) とのコミュニケーションの方法とプロセスについて合意する必要があります。 このインシデントには非同期ディスカッションまたはブリッジ呼び出しが必要ですか? チームは調査の進行状況をどのように追跡し、伝達する必要がありますか? チームはどこからインシデント資産にアクセスできますか?
インシデント対応は、システムのアーキテクチャ レイアウト、コンポーネント レベルの情報、プライバシーまたはセキュリティの分類、所有者、主要な連絡先などのドキュメントを最新の状態に保つ重要な理由です。 情報が不正確であったり、古かったりすると、ブリッジ チームは、システムの仕組み、各エリアの責任者、イベントの影響などを理解するために貴重な時間を浪費することになります。
さらなる調査については、適切な関係者にご相談ください。 インシデント マネージャー、セキュリティ担当者、またはワークロード中心のリーダーを含めることもできます。 トリアージを集中的に行うために、問題の範囲外の人を除外する必要があります。 場合によっては、別々のチームがインシデントを調査することがあります。 最初に問題を調査してインシデントの軽減を試みるチームと、広範な問題を確認するために詳細な調査のためのフォレンジックを実行する別の専門チームが存在する可能性があります。 ワークロード環境を隔離して、フォレンジック チームが調査できるようにすることができます。 場合によっては、同じチームが調査全体を担当することもあります。
初期段階では、トリアージ チームは潜在的なベクトルと、それがシステムの機密性、整合性、可用性 (別称 CIA) に与える影響を判断する責任を負います。
CIA のカテゴリ内で、被害の深さと修復の緊急性を示す初期重大度レベルを割り当てます。 トリアージのレベルでより多くの情報が発見されるにつれて、このレベルは時間の経過とともに変化することが予想されます。
発見のフェーズでは、即時の行動方針とコミュニケーション計画を決定することが重要です。 システムの実行状態に変化はありますか? さらなる悪用を阻止するために、攻撃を封じ込めるにはどうすればよいでしょうか? チームは責任ある開示などの内部または外部のコミュニケーションを送信する必要がありますか? 検出と応答時間を考慮してください。 一部の種類の違反については、特定の期間 (多くの場合、数時間または数日) 以内に規制当局に報告することが法的に義務付けられている場合があります。
システムをシャットダウンすることにした場合、次のステップはワークロードの災害復旧 (DR) プロセスにつながります。
システムをシャットダウンしない場合は、システムの機能に影響を与えずにインシデントを修復する方法を決定します。
インシデントからの回復
セキュリティ インシデントを災害のように扱います。 修復に完全な回復が必要な場合は、セキュリティの観点から適切な DR メカニズムを使用してください。 回復プロセスでは再発の可能性を防ぐ必要があります。 これができない場合、破損したバックアップからの回復によって問題が再発します。 同じ脆弱性を持つシステムを再導入すると、同じインシデントが発生します。 フェールオーバーとフェールバックの手順とプロセスを検証します。
システムが機能し続けている場合は、システムの稼働部分への影響を評価します。 適切な劣化プロセスを実施することで、その他の信頼性と性能目標が達成または再調整されるよう、システムの監視を継続します。 緩和のためにプライバシーを犠牲にしてはいけません。
診断は、ベクトル、潜在的な修正およびフォールバックが特定されるまで、対話型のプロセスです。 診断後、チームは修復に取り組み、許容期間内に必要な修正を特定して適用します。
回復メトリックは、問題を解決するのにかかる時間を測定します。 シャットダウンが発生した場合、修復時間に関して緊急性が生じる可能性があります。 システムを安定させるには、修正、パッチ、テストを適用し、更新プログラムを展開するまで時間がかかります。 さらなる被害と事件の拡大を防ぐための封じ込め戦略を決定します。 環境から脅威を完全に除去するための駆除手順を開発します。
トレードオフ: 信頼性の目標と修復時間の間にはトレードオフがあります。 インシデント発生中は、他の非機能要件または機能要件を満たさない可能性があります。 たとえば、インシデントを調査する間、システムの一部を無効にする必要があるかもしれませんし、インシデントの範囲を特定するまでシステム全体をオフラインにする必要があるかもしれません。 ビジネスの意思決定者は、インシデント発生時に許容できる目標を明確に決定する必要があります。 その決定に対する責任者を明確に指定してください。
インシデントからの学習
インシデントにより、設計や実装におけるギャップや脆弱な点が明らかになります。 これは、技術的な設計面、自動化、テストを含む製品開発プロセス、インシデント対応プロセスの有効性などの教訓によってもたらされる機会として活用できます。 実行されたアクション、タイムライン、調査結果を含む詳細なインシデント記録を保持します。
根本原因の分析や振り返りなど、構造化されたインシデント後のレビューを実施することを強くお勧めします。 それらのレビューの結果を追跡して優先順位を付け、学んだことを将来のワークロード設計に使用することを検討してください。
改善計画には、ビジネス継続性と災害復旧 (BCDR) 訓練などのセキュリティ訓練とテストの更新を含める必要があります。 BCDR ドリルを実行するシナリオとしてセキュリティ侵害を使用します。 ドリルにより、文書化されたプロセスがどのように機能するかを検証できます。 複数のインシデント対応プレイブックがあってはなりません。 インシデントの規模や、影響がどの程度広がっているか、あるいは局所的であるかによって調整できる単一のソースを使用します。 訓練は仮定の状況に基づいて行われます。 リスクの少ない環境で訓練を実施し、訓練に学習段階を含める必要があります。
インシデント後のレビュー、つまり事後分析を実施して、対応プロセスの弱点と改善の余地がある領域を特定します。 インシデントから学んだ教訓に基づいて、インシデント対応計画 (IRP) とセキュリティ管理策を更新します。
必要な連絡を送信する
ユーザーに中断を通知し、修復と改善について内部関係者に知らせるためのコミュニケーション プランを実装します。 将来のインシデントを防ぐために、ワークロードのセキュリティ ベースラインに変更があった場合は、組織内の他のユーザーに通知する必要があります。
社内で使用するため、また必要に応じて規制遵守や法的目的のためにインシデント レポートを生成します。 また、SOC チームがすべてのインシデントに使用する標準形式のレポート (セクションが定義されたドキュメント テンプレート) を採用します。 調査を終了する前に、すべてのインシデントにレポートが関連付けられていることを確認してください。
Power Platform の促進
次のセクションでは、セキュリティ インシデント対応手順の一部として使用できるメカニズムについて説明します。
Microsoft Sentinel
Microsoft Power Platform 用 Microsoft Sentinel ソリューションを使用すると、顧客は次のようなさまざまな不審なアクティビティを検出できるようになります:
- 未承認地域からの Power Apps の実行
- Power Apps による不審なデータの破棄
- Power Apps の一括削除
- Power Apps を介したフィッシング攻撃
- 退職者による Power Automate フロー活動
- 環境に追加された Microsoft Power Platform コネクター
- Microsoft Power Platform データ損失防止ポリシーの更新または削除
詳細情報については、Microsoft Power Platform のための Microsoft Sentinel ソリューションの概要 を参照してください。
Microsoft Purview のアクティビティ ログ記録
Power Apps、Power Automate コネクター、データ損失防止、Power Platform 管理アクティビティログは、Microsoft Purview コンプライアンス ポータルから追跡および表示されます。
詳細については、以下を参照してください。
- Power Apps アクティビティログ
- Power Automate アクティビティログ
- Copilot Studio アクティビティログ
- Power Pages アクティビティログ
- Power Platform コネクタアクティビティログ
- データ損失防止アクティビティログ
- Power Platform 管理アクションアクティビティログ
- Microsoft Dataverse モデル駆動型アプリのアクティビティログ
カスタマー ロックボックス
Microsoft のスタッフ (代わりの処理者を含む) が実行する操作、サポート、およびトラブルシューティングの多くは、顧客データにアクセスする必要がありません。 Power Platform Customer Lockbox により、マイクロソフトは、顧客データへのデータアクセスが必要な場合に、顧客がデータアクセス要求を確認し、承認 (または拒否) するためのインターフェイスを提供します。 顧客が開始したサポート チケットまたは Microsoft によって特定された問題に応答する場合、Microsoft のエンジニアが顧客データにアクセスする必要がある場合に使用されます。 詳細情報については、Power Platform と Dynamics 365 で Customer Lockbox を使用して顧客データに安全にアクセスするを参照してください。
セキュリティ更新プログラム
サービス チームは、システムのセキュリティを確保するために定期的に以下を実行します:
- 可能性のあるセキュリティ脆弱性を特定するためのサービスのスキャン。
- キー セキュリティ管理が効果的に動作していることを確認するサービスの評価。
- 外部のセキュリティ脆弱性が認められているサイトを定期的に監視する Microsoft セキュリティ レスポンス センター (MSRC) によって識別された脆弱性にさらされていないかを判断するためのサービスの評価。
これらのチームは問題を特定された問題を識別および追跡して、必要な時にリスクを軽減するために素早く行動することもします。
セキュリティ更新プログラムの詳細はどのように分かりますか?
サービス チームはサービスのダウンタイムを必要としない方法でリスク軽減を図るので、管理者は通常セキュリティ更新のメッセージ センター通知を受信しません。 セキュリティ更新プログラムがサービスを必要とする場合、これは計画済みメンテナンスとして考慮され、影響を受ける推定時間と、作業が始まる際にウィンドウで投稿されます。
セキュリティの詳細については、マイクロソフト トラスト センター を参照してください。
メンテナンス ウィンドウの管理
マイクロソフトは、セキュリティ、パフォーマンス、可用性を確保し、新機能を提供するために、定期的に更新と保守を行っています。 この更新プロセスは、毎週セキュリティとマイナーなサービスの改善を提供し、各更新はステーションに配置された安全な展開スケジュールに基づいて地域ごとに展開されます。 環境の既定メンテナンス ウィンドウについては、サービス インシデントのポリシーとコミュニケーションを参照してください。 メンテナンス期間の管理 もご参照ください。
内部プロセスを介してセキュリティ操作に直接通知できるように、Azure 登録ポータルに 管理者の連絡先情報が含まれていることを確認します。 詳細については、通知設定の更新 を参照してください。
組織の整合性
Azure 向けクラウド導入フレームワークは、インシデント対応計画とセキュリティ運用に関するガイダンスを提供します。 詳細については、セキュリティ運用 を参照してください。
関連情報
- Microsoft Sentinelソリューション Microsoft Power Platform 概要
- Microsoftセキュリティアラートからインシデントを自動的に作成する
- ハント機能を使用してエンドツーエンドの脅威ハンティングを実施します
- Microsoft SentinelでHuntsを使用してエンドツーエンドのプロアクティブな脅威ハンティングを実行します
- インシデント 応答 の概要
セキュリティ チェックリスト
完全なレコメンデーションのセットを参照してください。