Tip
Power BI Dataflow Gen1 は従来の状態になり、新機能への投資を受け取ることはありません。 Fabric アクセス権を持つ Premium のお客様には、 Dataflow Gen2 が推奨されるパスであり、パフォーマンス、スケール、信頼性、機能、および組み込みの AI の改善が提供されます。 Pro/PPU のお客様は、これらのシナリオの Gen2 ガイダンスが進化するため、引き続き Gen1 を使用できます。 アップグレードのガイダンスについては、「 Dataflow Gen1 から Dataflow Gen2 への アップグレード」を参照してください。
データフロー実装のベスト プラクティスの 1 つは、データフローの責任をデータ インジェストとデータ変換の 2 つのレイヤーに分離することです。 このパターンは、1 つのデータフローで低速なデータ ソースの複数のクエリを処理する場合や、同じデータ ソースに対してクエリを実行する複数のデータフローを処理する場合に特に役立ちます。 低速なデータ ソースからクエリごとに何度もデータを取得する代わりに、データ インジェスト プロセスを 1 回実行し、そのプロセスに基づいて変換を実行できます。 この記事では、このプロセスについて説明します。
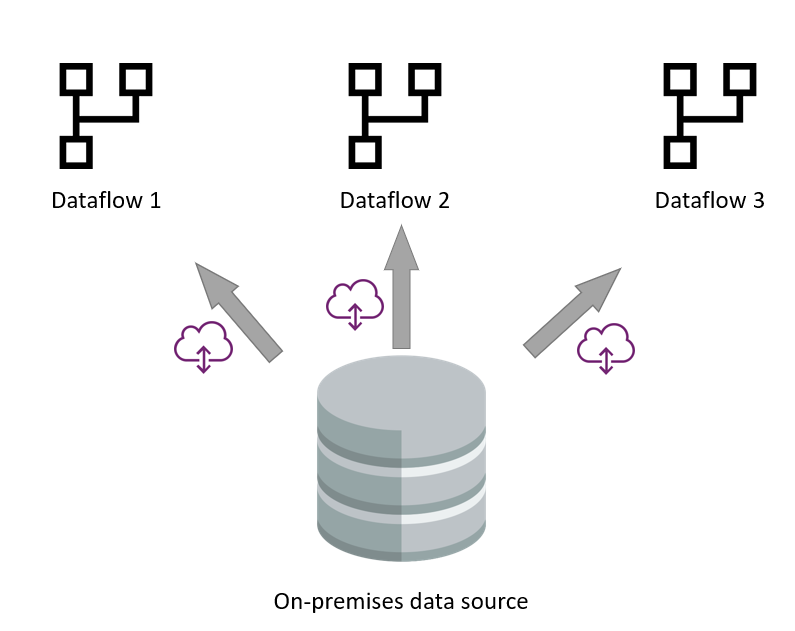
オンプレミスのデータ ソース
多くのシナリオでは、オンプレミスのデータ ソースは低速なデータ ソースです。 特に、ゲートウェイがデータフローとデータ ソースの間の中間層として存在することを考慮してください。
データ インジェストに分析データフローを使用すると、ソースからのデータ取得プロセスを最小限に抑え、Azure Data Lake Storage へのデータの読み込みに重点を置いています。 ストレージに入ると、インジェスト データフローの出力を利用する他のデータフローを作成できます。 データフロー エンジンは、元のデータ ソースまたはゲートウェイに接続することなく、データを読み取り、データ レイクから直接変換を実行できます。
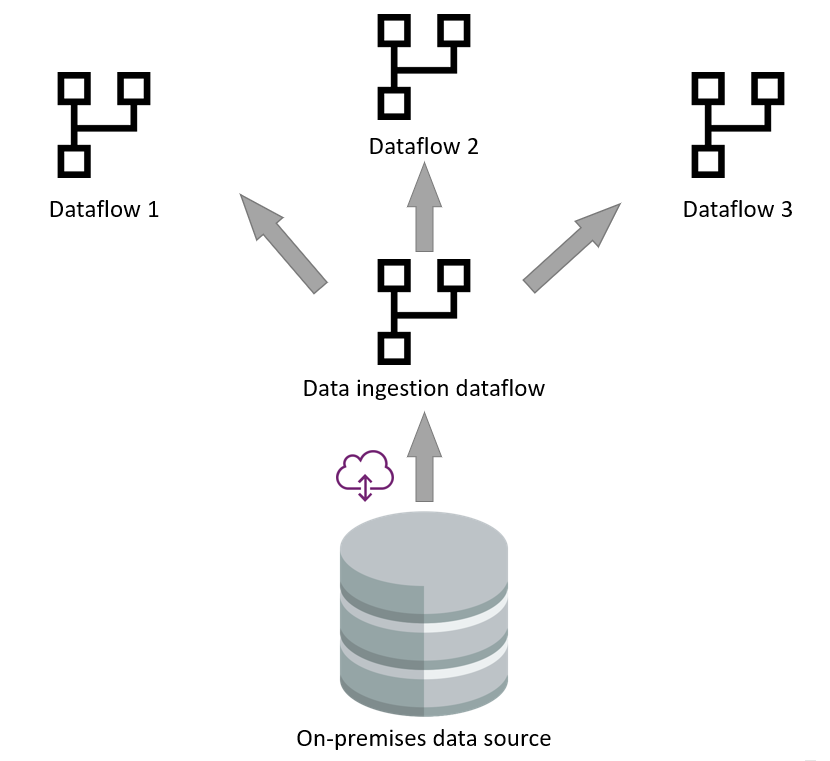
低速データソース
データ ソースが低速の場合も、同じプロセスが有効です。 サービスとしてのソフトウェア (SaaS) データ ソースの一部は、API 呼び出しの制限によりパフォーマンスが低下します。
データ インジェストとデータ変換データフローの分離
データ ソースが遅いシナリオでは、データ インジェストと変換という 2 つのレイヤーの分離が役立ちます。 データ ソースとの対話を最小限に抑えるのに役立ちます。
この分離は、パフォーマンスの向上のために役立つだけでなく、古いレガシ データ ソース システムが新しいシステムに移行されたシナリオにも役立ちます。 このような場合は、データ インジェスト データフローのみを変更する必要があります。 この種類の変更では、データ変換データフローはそのまま残ります。
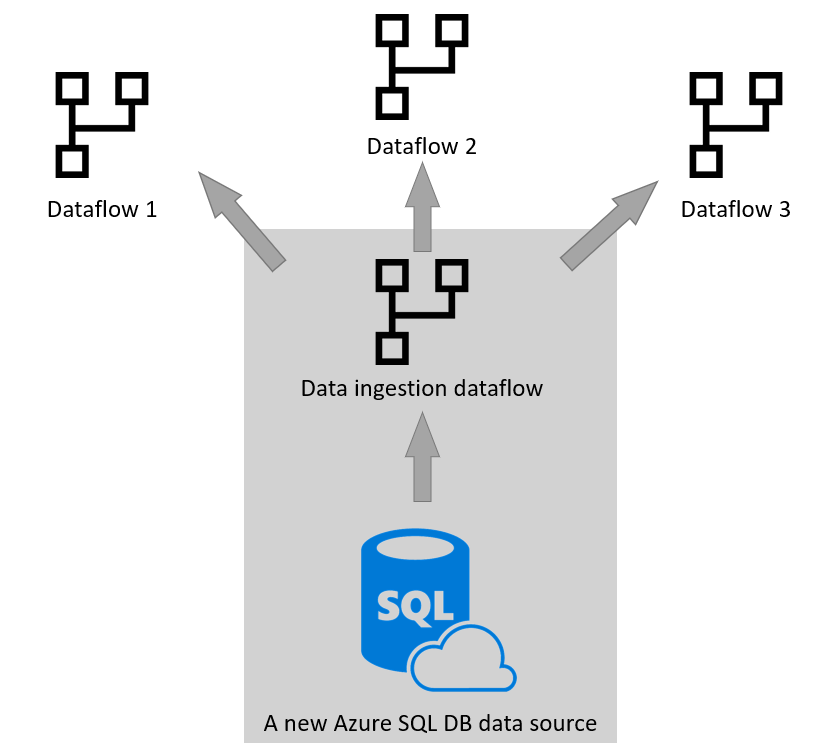
他のツールやサービスで再利用する
データ変換データフローからのデータ インジェスト データフローの分離は、多くのシナリオで役立ちます。 このパターンのもう 1 つのユース ケース シナリオは、他のツールやサービスでこのデータを使用する場合です。 このため、分析データフローを使用し、独自の Data Lake Storage をストレージ エンジンとして使用することをお勧めします。 詳細情報: 分析データフロー
データ インジェスト データフローを最適化する
可能な限り、データ インジェスト データフローを最適化することを検討してください。 たとえば、ソースからのすべてのデータが不要で、データ ソースがクエリ フォールディングをサポートしている場合は、データをフィルター処理し、必要なサブセットのみを取得することをお勧めします。 クエリ フォールディングの詳細については、 Power Query でのクエリ評価とクエリ フォールディングの概要に関するページを参照してください。
分析データフローとしてデータ インジェスト データフローを作成する
分析データフローとしてデータ インジェスト データフローを作成することを検討してください。 これは特に、他のサービスやアプリケーションがこのデータを使用するのに役立ちます。 また、これにより、データ変換データフローが分析インジェスト データフローからデータを取得しやすくなります。 詳細については、「 分析データフロー」を参照してください。