重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
SQL Server ビッグ データ クラスターでは、HDFS の CSV ファイルからデータを仮想化できます。 このプロセスでは、データを元の場所に維持したまま、他のテーブルと同様に SQL Server インスタンスからクエリを実行することができます。 この機能では PolyBase コネクタを使用して、ETL プロセスの必要性を最小限に抑えます。 データの仮想化に関する詳細については、「PolyBase によるデータ仮想化の概要」を参照してください
[前提条件]
データの仮想化に使用する CSV ファイルを選択またはアップロードする
Azure Data Studio (ADS) で、ご使用のビッグ データ クラスターの SQL Server マスター インスタンスに接続します。 接続したら、オブジェクト エクスプローラーで HDFS 要素を展開して、データを仮想化する CSV ファイルを見つけます。
このチュートリアルでは、Data という名前の新しいディレクトリを作成します。
- HDFS ルート ディレクトリのコンテキスト メニューを右クリックします。
- [新しいディレクトリ] を選びます。
- 新しいディレクトリに "Data" という名前を付けます。
サンプル データをアップロードします。 簡単なチュートリアルの場合は、サンプルの csv データ ファイルを使用できます。 この記事では、米国運輸省の航空会社の遅延の原因データを使用します。 生データをダウンロードし、ご使用のコンピューターにデータを抽出します。 ファイルに airline_delay_causes.csv という名前を付けます。
抽出後にサンプル ファイルをアップロードするには:
- Azure Data Studio で、作成した新しいディレクトリを "右クリック" します。
- [ ファイルのアップロード] を選択します。
Azure Data Studio により、ファイルがビッグ データ クラスターの HDFS にアップロードされます。
ターゲット データベースに記憶域プールの外部データ ソースを作成する
ビッグ データ クラスターでは、記憶域プールの外部データ ソースは、既定ではデータベース内には作成されません。 外部テーブルを作成するには、事前に次の Transact-SQL クエリを使用して、ターゲット データベースに既定の SqlStoragePool 外部データ ソースを作成します。 最初に必ず、クエリのコンテキストを実際のターゲット データベースに変更してください。
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
外部テーブルを作成する
ADS から、CSV ファイルを右クリックして、コンテキスト メニューから [Create External Table From CSV File](CSV ファイルからの外部テーブルの作成) を選択します。 HDFS 内のディレクトリの下にある CSV ファイルが同じスキーマに従っている場合、そのディレクトリのファイルから外部テーブルを作成することもできます。 これにより、個々のファイルを処理する必要なしにディレクトリ レベルでデータを仮想化でき、結合されたデータに対する結合された結果セットを取得できます。 Azure Data Studio では、外部テーブルを作成する手順が示されます。
データベース、データソース、テーブル名、スキーマ、およびテーブルの外部ファイル形式の名前を指定します。
[次へ] を選択します。
データをプレビューする
Azure Data Studio により、インポートされたデータのプレビューが提供されます。
![インポートされたデータのプレビューが含まれる [Create External Table From CSV]\(CSV から外部テーブルを作成する\) ウィンドウを示すスクリーンショット。](media/data-virtualization/130-csv-preview-data.png?view=sql-server-ver15)
プレビューの表示が終わったら、[次へ] を選んで続けます。
列を変更する
次のウィンドウでは、作成する外部テーブルの列を変更できます。 列の名前とデータ型を変更でき、null 許容型の行にすることができます。
![手順 3「列を変更する」が示されている [Create External Table From CSV]\(CSV から外部テーブルを作成する\) ウィンドウのスクリーンショット。](media/data-virtualization/140-csv-modify-columns.png?view=sql-server-ver15)
変換先の列を確認したら、[次へ] を選びます。
概要
このステップでは、選択内容の要約が提供されます。 SQL Server 名、データベース名、テーブル名、テーブル スキーマ、および外部テーブル情報が提供されます。 このステップでは、スクリプトを生成するか、テーブルを作成するかを選択できます。 [スクリプトの生成] では、外部データ ソースを作成するためのスクリプトが T-SQL で生成されます。 [テーブルの作成] では、外部データ ソースが作成されます。
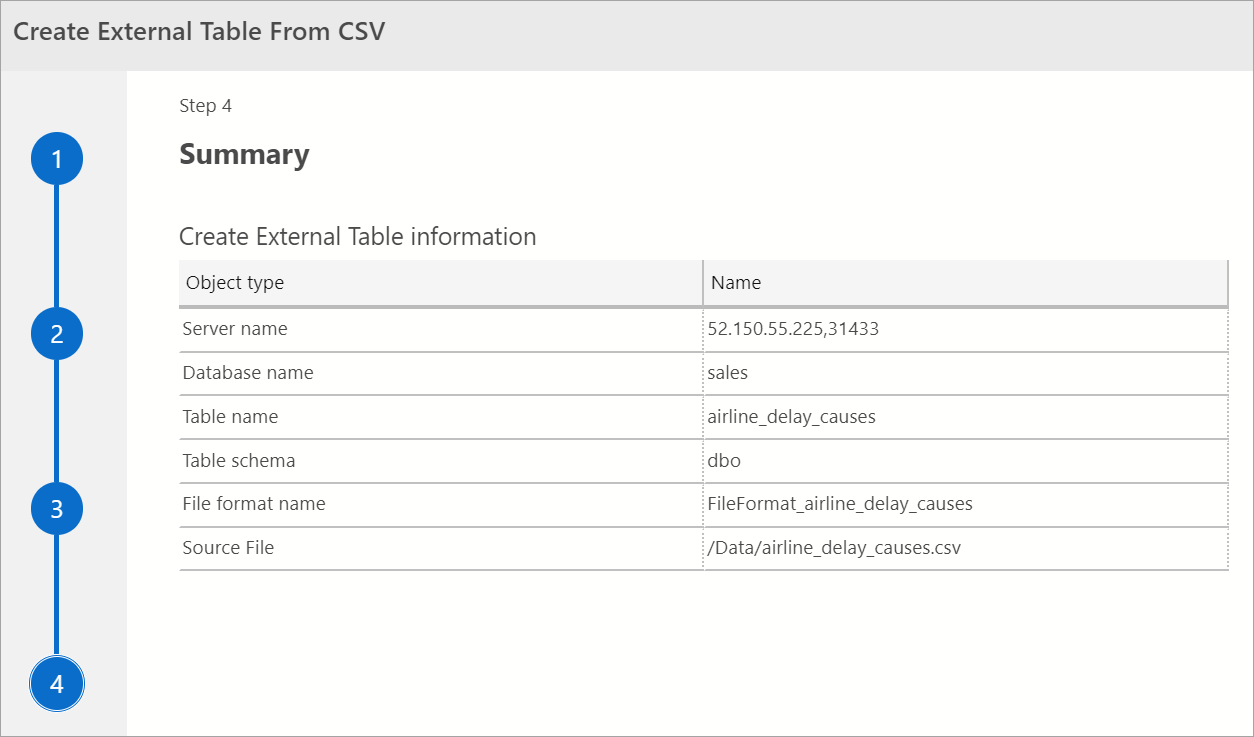
[テーブルの作成] を選ぶと、SQL Server によって出力先のデータベースに外部テーブルが作成されます。
[スクリプトの生成] を選ぶと、Azure Data Studio によって外部テーブルを作成するための T-SQL クエリが作成されます。
テーブルが作成されたら、SQL Server インスタンスから T-SQL を使用して直接クエリを実行できるようになります。
次のステップ
SQL Server ビッグ データ クラスターと関連するシナリオの詳細については、「SQL Server ビッグ データ クラスターとは」を参照してください。