Configure and run data profiling for a data asset
Data profiling is the process of examining the data available in different data sources and collecting statistics and information about this data. Data profiling helps to assess the quality level of the data according to defined set of goals. If data is of a poor quality, or managed in structures that can't be integrated to meet the needs of the enterprise, business processes and decision-making suffer. Data profiling allows you to understand the trustworthiness and quality of your data, which is a prerequisite for making data-driven decisions that boost revenue and foster growth.
Prerequisites
- To run and schedule data quality assessment scans, your users must be in the data quality steward role.
- Currently, the Microsoft Purview account can be set to allow public access or managed vNet access so data quality scans can run.
Data quality life cycle
Data profiling is the fifth step the data quality life cycle for a data asset. Previous steps are:
- Assign users(s) data quality steward permissions in your data catalog to use all data quality features.
- Register and scan a data source in your Microsoft Purview Data Map.
- Add your data asset to a data product
- Set up a data source connection to prepare your source for data quality assessment.
Supported multi-cloud data sources
- Azure Data Lake Storage (ADLS Gen2)
- File Types: Delta Parquet and Parquet
- Azure SQL Database
- Fabric data estate in OneLake is including shortcut and mirroring data estate. Data profiling is supported only for Lakehouse delta tables and parquet files.
- Mirroring data estate: CosmosDB, Snowflake, Azure SQL
- Shortcut data estate: AWS S3, GCS, AdlsG2, and dataverse
- Azure Synapse serverless and data warehouse
- Azure Databricks Unity Catalog
- Snowflake
- Google Big Query (Private Preview)
Important
Data Quality for Parquet file is designed to support:
- A directory with Parquet Part File. For example: ./Sales/{Parquet Part Files}. The Fully Qualified Name must follow
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}. Make sure we do not have {n} patterns in directory/sub-directory structure, must rather be a direct FQN leading to {SparkPartitions}. - A directory with Partitioned Parquet Files, partitioned by Columns within the dataset like sales data partitioned by year and month. For example: ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}.
Both of these essential scenario which present a consistent parquet dataset schema are supported.
Limitation: It is not designed to or will not support N arbitrary Hierarchies of Directories with Parquet Files. We advise the customer to present data in (1) or (2) constructed structure.
Supported authentication methods
Currently, Microsoft Purview can only run data quality scans using Managed Identity as authentication option. Data Quality services run on Apache Spark 3.4 and Delta Lake 2.4. For more information about supported regions, see data quality overview.
Important
If the schema is updated on the data source, it is necessary to rerun data map scan before running a data profiling.
Steps to configure data profiling Job
Configure a data source connection to the asset if you haven't already created one.
From Microsoft Purview Data Catalog, select the Health Management menu and Data quality submenu.
In the data quality submenu, select the Governance domain for data profiling.
Select a data product to profile a data asset linked to that product.
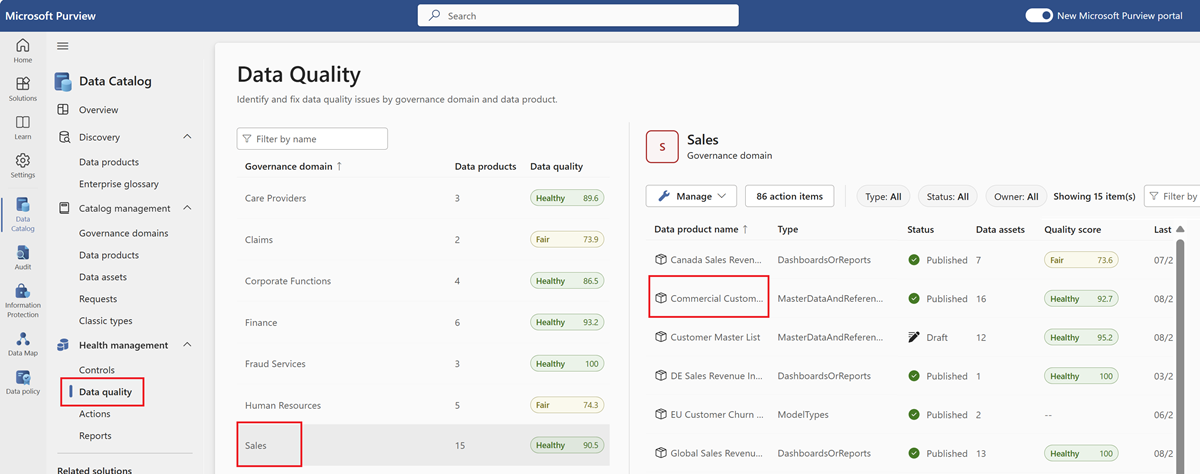
Select a data asset to navigate into data quality Overview page for profiling.
Select the Profile button to run profiling job for the selected data asset.

The AI recommendation engine suggests potentially important columns to run data profiling against. You can deselect recommended columns and/or select more columns to be profiled.
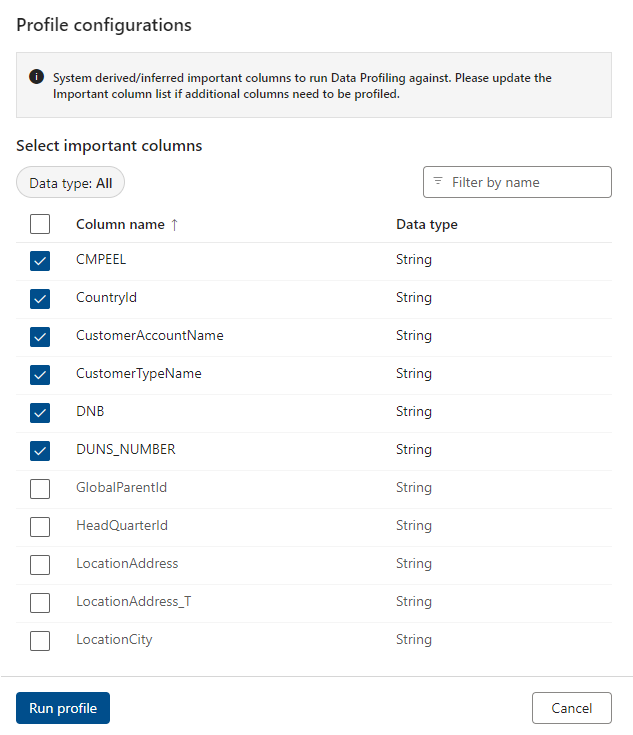
Once you've selected the relevant columns, select Run Profile.
While the job is running, you can track its progress from the data quality monitoring page in the governance domain.
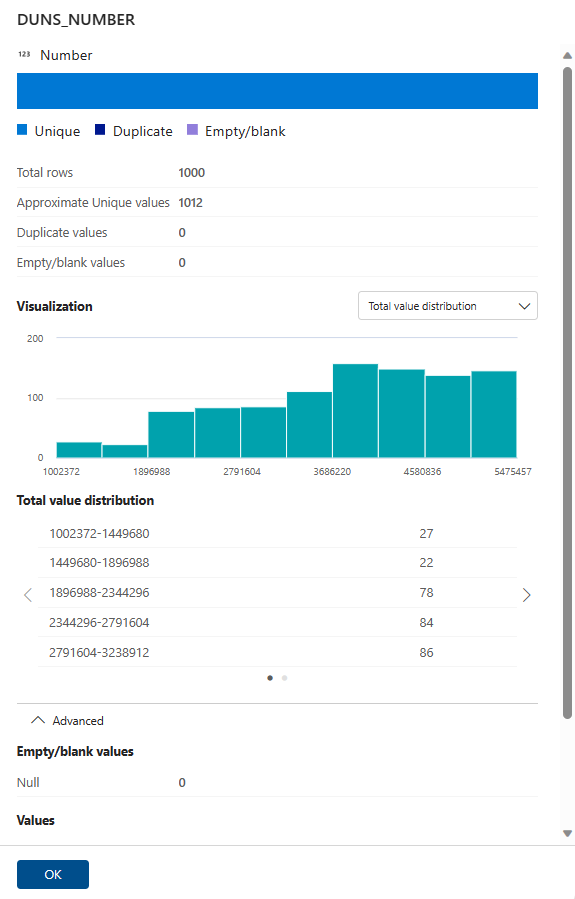
When the job is complete, select the Profile tab from left menu of the asset's data quality page to list browse the profiling result and statistical snapshot. There could be several profile result pages depending on how many columns your data assets have.

Browse the profiling results and statistical measures for each column.



Important
To profile Parquet file you need to change the data asset type to Parquet. See the screen shot below:
As shown in the screenshot below, change the default data asset type delta to Parquet before configuring profiling job.

Related contents
- Data Quality for Fabric Data estate
- Data Quality for Fabric Mirrored data sources
- Data Quality for Fabric shortcut data sources
- Data Quality for Azure Synapse serverless and data warehouses
- Data Quality for Azure Databricks Unity Catalog
- Data Quality for Snowflake data sources
- Data Quality for Google Big Query
Next steps
- Set up data quality rules based on the profiling results, and apply them to your data asset.
- Configure and run a data quality scan on a data product to assess the quality of all supported assets in the data product.
- Review your scan results to evaluate your data product's current data quality.