適用対象:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric の SQL データベース
Microsoft Fabric の SQL データベース
「欠落したインデックス」の機能は、クエリのパフォーマンスを大幅に向上する可能性があるインデックスの欠落を検索する簡易ツールです。 この記事では、不足しているインデックス候補を使用して、インデックスを効果的にチューニングし、クエリのパフォーマンスを向上させる方法について説明します。
不足しているインデックス機能の制限事項
クエリ オプティマイザーでは、クエリ プランを生成するときに、特定のフィルター条件に対する最適なインデックスを分析します。 最適なインデックスが存在しない場合でも、クエリ オプティマイザーでは、利用できる最もコストの低いアクセス方法を使用してクエリ プランを生成するだけでなく、これらのインデックスに関する情報も格納します。 不足しているインデックス機能を使用すると、考えられる最適なインデックスに関するその情報にアクセスし、インデックスを実装する必要があるかどうかを判断することができます。
クエリ最適化は時間の影響を受けるプロセスであるため、不足しているインデックス機能には制限があります。 制限は以下のとおりです。
- 不足しているインデックス候補は、クエリの実行前は、1 つのクエリの最適化時の推定値に基づきます。 クエリの実行後は、不足しているインデックス候補のテストや更新は行われません。
- 不足しているインデックス機能では、非クラスター化ディスクベースの行ストア インデックスのみが候補として示されます。 一意 の インデックスとフィルター付きインデックス は推奨されません。
- キー列が推奨されますが、提案ではそれらの列の順序は指定されません。 列の順序付けについては、この記事の「不足しているインデックス候補を適用する」セクションを参照してください。
- 付加列は候補として示されますが、多数の付加列が候補として示された場合、SQL Server では結果のインデックスのサイズに関するコスト メリット分析は実行されません。
- 不足しているインデックス要求では、クエリ全体で同じテーブルと列に対して同様のバリエーションのインデックスが提供される場合があります。 インデックス候補を確認し、可能であれば結合することが重要です。
- 単純なクエリ プランでは、候補は示されません。
- 不等述語のみを含むクエリでは、コスト情報の精度が低くなります。
- 最大 600 の欠けているインデックス グループについて、候補が収集されます。 このしきい値に達すると、欠けているインデックス グループ データはそれ以上収集されなくなります。
これらの制限により、不足しているインデックス候補は、インデックス分析、設計、チューニング、およびテストを行うときに、いくつかの情報ソースの 1 つとして最適に扱われます。 インデックス候補が見つからない場合、インデックスを提案されたとおりに作成するための処方箋はありません。
Note
Azure SQL Database では、自動インデックス チューニングが提供されます。 自動インデックス チューニングでは機械学習を使用して、AI を介して Azure SQL Database 内のすべてのデータベースから水平方向に学習し、そのチューニング アクションを動的に改善します。 インデックスの自動チューニングには、作成されたインデックスからワークロードのパフォーマンスが確実に向上することを確認する検証プロセスが含まれています。
不足しているインデックスに関する推奨事項を表示する
不足しているインデックス機能は次の 2 つのコンポーネントで構成されています。
-
MissingIndexesの XML の 要素。 これにより、クエリ オプティマイザーが不足していると判断したインデックスと、インデックスが不足しているクエリを関連付けることができます。 - 不足しているインデックスに関する情報を返すためにクエリを実行できる動的管理ビュー (DMV) のセット。 これにより、データベースの不足しているインデックスに関する推奨事項をすべて表示できます。
実行プランで不足しているインデックス候補を表示する
実行プランの概要 は、複数の方法で生成または取得できます。
- クエリを作成またはチューニングするときに、 SQL Server Management Studio (SSMS) を 使用して、クエリを実行せずに 推定実行プランを表示 したり、クエリを実行して 実際の実行プランを表示したりできます。
- クエリ ストアを使用してパフォーマンスを監視すると、有効にすると実行プランが収集されます。
- sys.dm_exec_text_query_plan など、DMV に対してクエリを実行することでキャッシュされた実行プランを特定できます。
たとえば、次のクエリを使用して、 AdventureWorks サンプル データベースに対して不足しているインデックス要求を生成できます。
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
不足しているインデックス要求を生成して表示するには:
SSMS を開き、 セッションを AdventureWorks サンプル データベースのコピーに接続します。
セッションにクエリを貼り付け、[推定実行プランの表示] ツール バー ボタンを選択して、SSMS でクエリの推定実行プランを生成します。 実行プランは、現在のセッションのペインに表示されます。 グラフィック プランの上部付近に、緑色の Missing Index というステートメントが示されます。
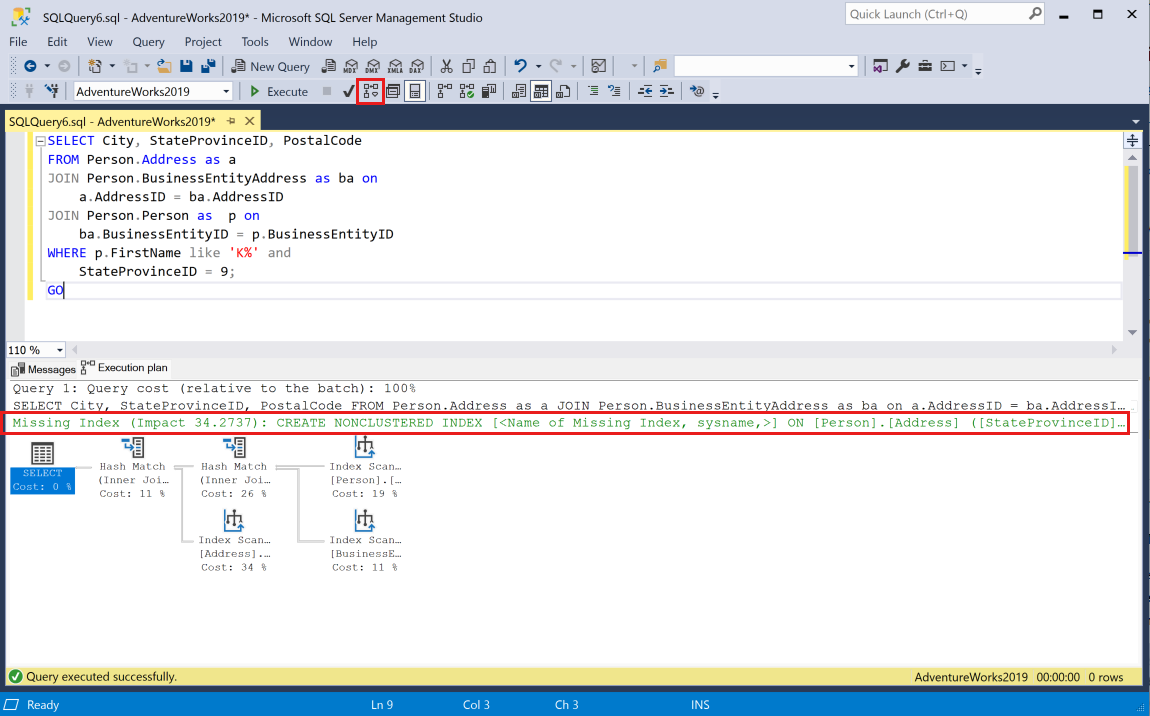
1 つの実行プランに、不足しているインデックス要求が複数含まれる場合がありますが、グラフィック実行プランに表示できる不足しているインデックス要求は 1 つだけです。 実行プランの不足しているインデックスの完全なリストを表示する 1 つのオプションは、実行プラン XML を表示することです。
実行プランを右クリックし、メニューから [実行プラン XML の表示] を選択します。
実行プラン XML は、SSMS 内に新しいタブとして開きます。
Note
実行プラン XML に複数の候補が存在する場合でも、[不足しているインデックスの詳細] メニュー オプションに表示される不足しているインデックス候補は 1 つのみです。 表示される不足しているインデックス候補は、クエリの推定改善率が最も高いものではない可能性があります。
Ctrl + F ショートカットを使用して、[検索] ダイアログを表示します。
MissingIndexを検索します。![実行プランの XML のスクリーンショット。[検索] ダイアログが開き、ドキュメントで MissingIndex という用語が検索されています。](media/missing-index-node-in-execution-plan-xml.png?view=sql-server-ver17)
この例では、2 つの
MissingIndex要素があります。- 最初の不足しているインデックスは、
Person.Address列での等値検索をサポートするStateProvinceIDテーブルのインデックスをクエリで使用する可能性があることを示しています。これには、さらに 2 つの列 (CityとPostalCode) が含まれます。 最適化の時点で、クエリ オプティマイザーでは、このインデックスによってクエリの推定コストが 34.2737% 削減される可能性があると確信していました。 - 2 つ目の不足しているインデックスは、FirstName 列での不等値検索をサポートする
Person.Personテーブルでインデックスがクエリで使用される可能性があることを示しています。 最適化の時点で、クエリ オプティマイザーでは、このインデックスによってクエリの推定コストが 18.1102% 削減される可能性があると確信していました。
- 最初の不足しているインデックスは、

![実行プランの XML のスクリーンショット。[検索] ダイアログが開き、ドキュメントで MissingIndex という用語が検索されています。](media/missing-index-node-in-execution-plan-xml.png?view=sql-server-ver17#lightbox)
データベース内の各ディスクベースの非クラスター化インデックスは、スペースを占有し、挿入、更新、および削除のオーバーヘッドが追加されるため、メンテナンスが必要になる可能性があります。 このような理由から、クエリ実行プランに基づいてインデックスを追加する前に、テーブルの不足しているすべてのインデックス要求とテーブル上の既存のインデックスを確認することをお勧めします。
DMV で不足しているインデックス候補を表示する
次の表に一覧表示されている動的管理オブジェクトに対してクエリを実行することで、不足しているインデックスに関する情報を得ることができます。
| 動的管理ビュー | 返される情報 |
|---|---|
| sys.dm_db_missing_index_group_stats | 欠けているインデックス グループに関する概要情報を返します。たとえば、欠けているインデックスの特定のグループを実装することで得られるパフォーマンスの向上などです。 |
| sys.dm_db_missing_index_groups | グループ識別子や、そのグループに含まれるすべての欠けているインデックスの識別子など、欠けているインデックスの特定のグループに関する情報を返します。 |
| sys.dm_db_missing_index_details | 欠けているインデックスに関する詳細情報を返します。たとえば、インデックスがないテーブルの名前と識別子、および欠けているインデックスを構成する列と列の型を返します。 |
| sys.dm_db_missing_index_columns | インデックスがないデータベース テーブル列に関する情報を返します。 |
次のクエリでは、不足しているインデックス DMV を使用して、 CREATE INDEX ステートメントを生成します。 ここで示すインデックス作成ステートメントは、テーブル上の既存のインデックスと共にテーブルのすべての要求を調べた後に、独自の DDL を作成するのをサポートすることを目的としています。
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
このクエリでは、estimated_improvement という名前の列で候補を並べ替えます。 推定改善は次の組み合わせに基づいています。
- 不足しているインデックス要求に関連付けられているクエリの推定クエリ コスト。
- インデックスを追加した場合の推定される影響。 これは、非クラスター化インデックスによってクエリ コストがどれだけ削減されるかを推定したものです。
- 不足しているインデックス要求に関連付けられているクエリに対して実行されたクエリ演算子 (seek と scan) の実行の合計。 「クエリ ストアを使用して不足しているインデックスを保持する」の説明のとおり、この情報は定期的にクリアされます。
Note
Microsoft の Tiger ツールボックスの Index-Creation スクリプトでは、不足しているインデックス DMV を調べ、冗長なインデックス候補を自動的に削除し、影響の少ないインデックスを解析して、確認用のインデックス作成スクリプトを生成します。 上記のクエリと同様に、インデックス作成コマンド NOT 実行されます。
Index-Creation スクリプトは、SQL Server および Azure SQL Managed Instance に適しています。 Azure SQL Database の場合は、自動インデックス チューニングの実装を検討してください。
インデックスを作成する前に、不足しているインデックス機能の制限事項と不足しているインデックス候補を適用する方法を確認し、データベースの名前付け規則に合わせてインデックス名を変更します。
クエリ ストアを使用して不足しているインデックスを保持する
DMV の不足しているインデックス候補は、インスタンスの再起動、フェールオーバー、およびデータベースのオフライン設定などのイベントによってクリアされます。 さらに、テーブルのメタデータが変更されると、そのテーブルに関するすべての不足しているインデックス情報はこれらの動的管理オブジェクトから削除されます。 テーブル メタデータの変更は、テーブルに対して列が追加または削除された場合や、テーブルの列にインデックスが作成された場合などに発生する可能性があります。 テーブルのインデックスに対して ALTER INDEX 操作を実行すると、そのテーブルに対する不足しているインデックス要求もクリアされます。
同様に、プラン キャッシュに格納されている実行プランは、インスタンスの再起動、フェールオーバー、データベースのオフライン設定などのイベントによってクリアされます。 メモリ負荷と再コンパイルにより、実行プランがキャッシュから削除される場合があります。
クエリ ストアを使用して Monitor パフォーマンスを有効にすると、実行プランにインデックス候補が見つからない場合は、これらのイベント間で保持できます。
次のクエリでは、クエリの論理読み取りの合計の大まかな見積もりに基づいて、クエリ ストアから不足しているインデックス要求を含む上位 20 個のクエリ プランを取得します。 データは、過去 48 時間以内のクエリ実行に制限されます。
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
不足しているインデックス候補を適用する
不足しているインデックス候補を効果的に使用するには、非クラスター化インデックスの設計ガイドラインに従います。 不足しているインデックス候補を使用して非クラスター化インデックスをチューニングする場合は、ベース テーブルの構造を確認し、インデックスを慎重に結合し、キー列の順序を考慮して、付加列の候補を確認します。
ベース テーブルの構造を確認する
不足しているインデックス候補に基づいてテーブルに非クラスター化インデックスを作成する前に、テーブルのクラスター化インデックスを確認します。
クラスター化インデックスを確認する 1 つの方法は、sp_helpindex システム ストアド プロシージャを使用することです。 たとえば、次のステートメントを実行して、Person.Address テーブルのインデックスの概要を表示することができます。
exec sp_helpindex 'Person.Address';
GO
index_description 列を確認します。 テーブルに含めることができるのは、1 つのクラスター化インデックスのみです。 テーブルにクラスター化インデックスが実装されている場合は、index_description に 'clustered' という単語が含まれます。

クラスター化インデックスが存在しない場合、テーブルはヒープになります。 この場合は、特定のパフォーマンスの問題を解決するために、テーブルがヒープとして意図的に作成されているかどうかを確認します。 ほとんどのテーブルでクラスター化インデックスの利点が得られますが、多くの場合、テーブルは偶発的にヒープとして実装されます。 クラスター化インデックスの設計ガイドラインに基づいてクラスター化インデックスを実装することを検討してください。
不足しているインデックスと既存のインデックスが重複していないどうかを確認する
不足しているインデックスでは、クエリ全体で同じテーブルと列に対して同様のバリエーションの非クラスター化インデックスが提供される場合があります。 不足しているインデックスは、テーブルの既存のインデックスと似ている場合もあります。 最適なパフォーマンスを得るために、不足しているインデックスと既存のインデックスの重複を調べ、重複するインデックスを作成しないようにすることをお勧めします。
テーブルの既存のインデックスをスクリプト化する
テーブルの既存のインデックスの定義を調べる 1 つ方法は、[オブジェクト エクスプローラーの詳細] を使用してインデックスをスクリプト化することです。
- インスタンスまたはデータベースにオブジェクト エクスプローラーを接続します。
- オブジェクト エクスプローラーで該当するデータベースのノードを展開します。
- [テーブル] フォルダーを展開します。
- インデックスをスクリプト化するテーブルを展開します。
- [インデックス] フォルダーを展開します。
- [オブジェクト エクスプローラーの詳細] ウィンドウがまだ開いていない場合は、[ 表示 ] メニューの [オブジェクト エクスプローラーの詳細 ] を選択するか 、F7 キーを押します。
- ショートカット Ctrl + A を使用して、[オブジェクト エクスプローラーの詳細] ペインに一覧表示されているすべてのインデックスを選択します。
- 選択したリージョン内の任意の場所を右クリックし、メニュー オプションの [インデックスのスクリプト] を選択し、[次へ
CREATE] と [ 新しいクエリ エディター] ウィンドウを選択します。
![SSMS の [オブジェクト エクスプローラーの詳細] ペインを使用してテーブルのすべてのインデックスをスクリプト化するスクリーンショット。](media/object-explorer-details-script-all-indexes.png?view=sql-server-ver17#lightbox)
インデックスを確認し、可能であれば結合する
テーブルの既存のインデックスの定義と共に、グループとしてのテーブルの不足しているインデックスに関する推奨事項を確認します。 インデックスを定義する場合、通常は等値列を非等値列の前に配置し、それらを組み合わせてインデックスのキーを形成する必要があることに注意してください。 等値列の有効な順序を決定するには、選択度に基づいて列を並べ替えます。最も選択的な列を最初に一覧表示します (列リストの左端)。 一意の列の選択度が最も高いのに対して、繰り返し値が多数ある列の選択度は低くなります。
含まれる列は、CREATE INDEX句を使用して INCLUDE ステートメントに追加する必要があります。 付加列の順序は、クエリのパフォーマンスに影響しません。 そのため、インデックスを結合する場合、順序を気にせずに付加列を結合させることができます。 詳細については、付加列のガイドラインを参照してください。
たとえば、キー列 Person.Address に既存のインデックスが含まれているテーブル StateProvinceID があるとします。 次の列については、Person.Address テーブルの不足しているインデックスに関する推奨事項が表示されることがあります。
-
StateProvinceIDおよびCityの等値フィルター -
StateProvinceIDとCityの EQUALITY フィルターINCLUDEPostalCode
2 番目の推奨事項 (StateProvinceID を含む City および PostalCode にキーがあるインデックス) に合わせて既存のインデックスを変更すると、両方のインデックス候補を生成したクエリを満たす可能性があります。
トレードオフはインデックスのチューニングでよく見られます。 多くのデータセットでは、 City 列が StateProvinceID 列よりも選択的である可能性があります。 ただし、 StateProvinceID に対する既存のインデックスが頻繁に使用され、他の要求が主に StateProvinceID と Cityの両方で検索される場合、一般に、データベースがキー内の両方の列を持つ単一のインデックスを持つことはオーバーヘッドが低くなり、 StateProvinceIDが最も選択的な列ではありません。
インデックスは、次の複数の方法で変更できます。
- DROP_EXISTING 句と共に CREATE INDEX ステートメントを使用できます。 変更後にインデックスの名前を変更しても、名前付け規則に応じて、その名前でインデックスの定義が正確に示されるようにしたい場合があります。
- DROP INDEX (Transact-SQL) ステートメントの後に CREATE INDEX ステートメントを使用することができます。
インデックス候補を結合する際にインデックス キーの順序が重要になります。つまり、先頭列としての City は、先頭列としての StateProvinceID とは異なります。 詳細については、非クラスター化インデックスの設計ガイドラインを参照してください。
インデックスを作成するときに、使用可能な場合はオンライン インデックス操作を使うことを検討してください。
インデックスにより、クエリのパフォーマンスが大幅に向上する場合がありますが、インデックスのオーバーヘッドと管理コストも発生します。 インデックスを作成する前に、その利点を評価するのに役立つ一般的なインデックスの設計ガイドラインを確認してください。
インデックスの変更に成功したかどうかを確認する
インデックスの変更に成功したかどうかを確認することが重要です。クエリ オプティマイザーでインデックスが使用されていますか?
インデックスの変更を検証する方法 1 つの方法は、クエリ ストアを使用して、不足しているインデックス要求のあるクエリを特定することです。 クエリの query_id に注意してください。 クエリ ストアの [追跡対象のクエリ] ビューを使用して、クエリの実行プランが変更されたかどうか、およびオプティマイザーで新しいまたは変更されたインデックスを使用しているかどうかを確認します。 追跡対象のクエリの詳細については、「クエリ パフォーマンスのトラブルシューティングを開始する」を参照してください。