Azure Synapse Analytics を使用してデータを準備および変換する
マッピング データ フロー タスクを使用して、Azure Synapse パイプライン コードでデータ変換をネイティブで実行できます。 Mapping Data Flows は、コーディングを必要としない、完全に視覚的なエクスペリエンスを提供します。 データ フローは独自の実行クラスター上で実行されるため、データ処理をスケールアウトできます。 データ フロー アクティビティは、既存の Data Factory のスケジュール設定、制御、フロー、および監視機能を通して運用可能にすることができます。
データ フローを構築するときに、デバッグ モードを有効にすることができます。これにより、小規模な対話型の Spark クラスターが有効になります。 デバッグ モードを有効にするには、作成モジュールの上部にあるスライダーを切り替えます。 デバッグ クラスターのウォームアップには数分かかりますが、変換ロジックの出力を対話形式でプレビューするために使用できます。

マッピング データ フローを追加し、Spark クラスターを実行していれば、変換を実行し、データを実行およびプレビューできます。 コードの翻訳、パスの最適化、およびデータ フロー ジョブの実行は、すべて Azure Data Factory によって処理されるため、コードの記述は必要ありません。
マッピング データ フローにソース データを追加する
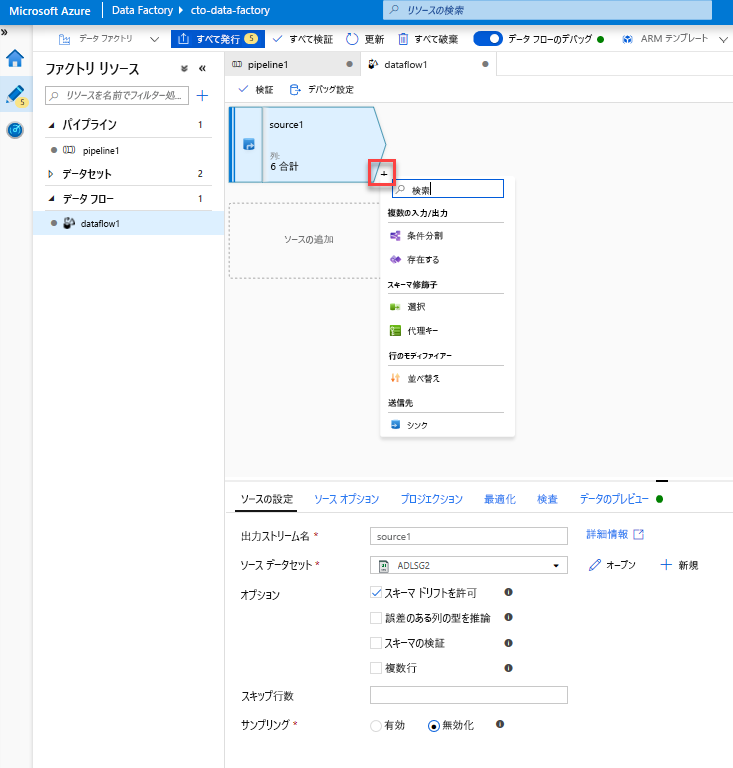
マッピング データ フロー キャンバスを開きます。 データ フロー キャンバスの [ソースの追加] ボタンをクリックします。 ソース データセット ドロップダウンで、データ ソースを選択します。この例では、ADLS Gen2 データセットが使用されます
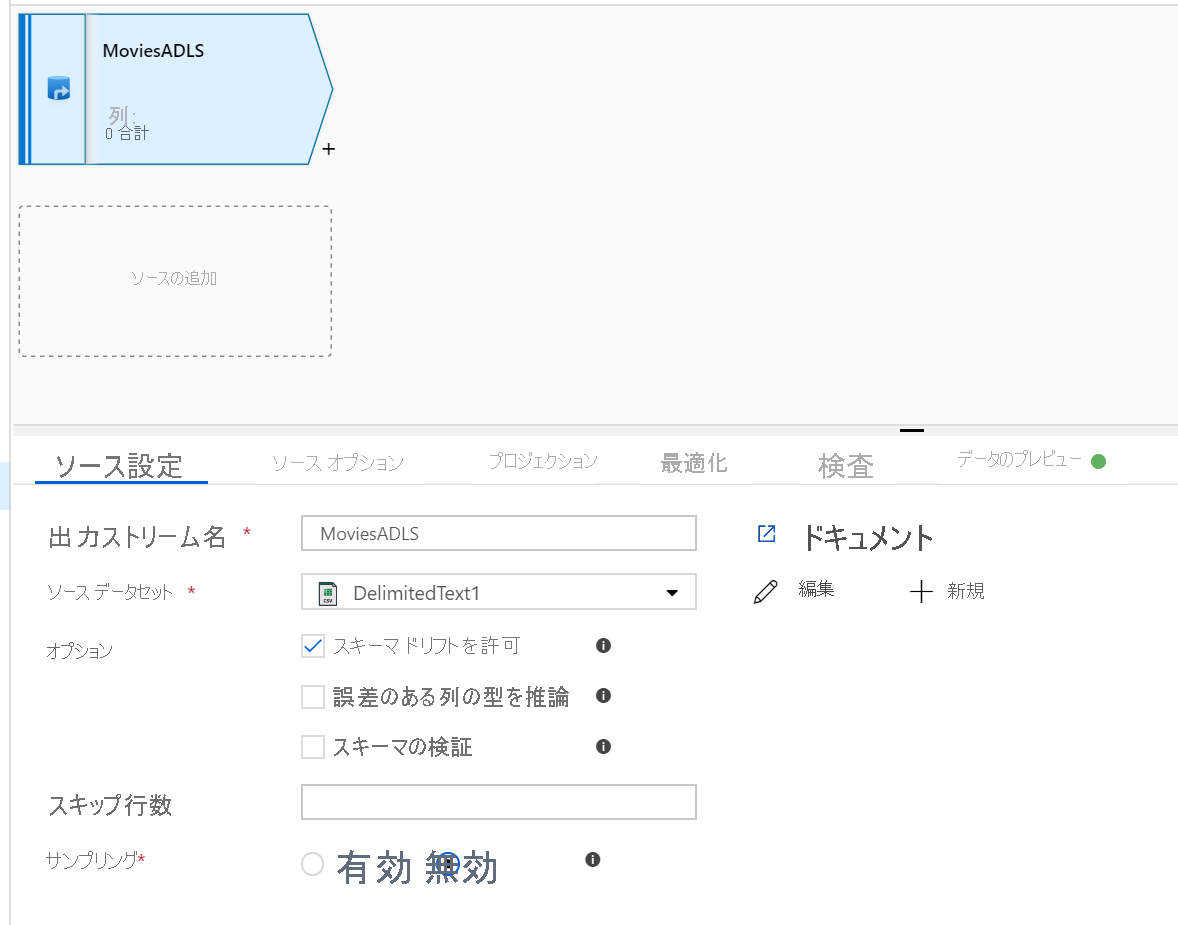
いくつかの注意点があります。
- データセットが他のファイルを含むフォルダーを指しているものの、1 つのファイルのみを使用したい場合は、別のデータセットを作成するか、パラメーター化を使用して特定のファイルのみが読み取られるようにしなければならない場合があります
- ADLS にスキーマをインポートしていないのに、既にデータを取り込んだ場合は、データセットの [スキーマ] タブに移動し、[スキーマのインポート] をクリックして、データ フローでスキーマ プロジェクションが認識されるようにします。
Mapping Data Flow は、抽出、読み込み、変換 (ELT) のアプローチに従い、すべて Azure に存在する "ステージング" データセットを操作します。 現在は、次のデータセットをソース変換で使用できます。
- Azure Blob Storage (JSON、Avro、テキスト、Parquet)
- Azure Data Lake Storage Gen1 (JSON、Avro、テキスト、Parquet)
- Azure Data Lake Storage Gen2 (JSON、Avro、テキスト、Parquet)
- Azure Synapse Analytics
- Azure SQL データベース
- Azure Cosmos DB
Azure Data Factory は、80 を超えるネイティブ コネクタにアクセスできます。 それらの他のソースからのデータをデータ フローに含めるには、コピー アクティビティを使用して、サポートされているステージング領域のいずれかにそのデータを読み込みます。
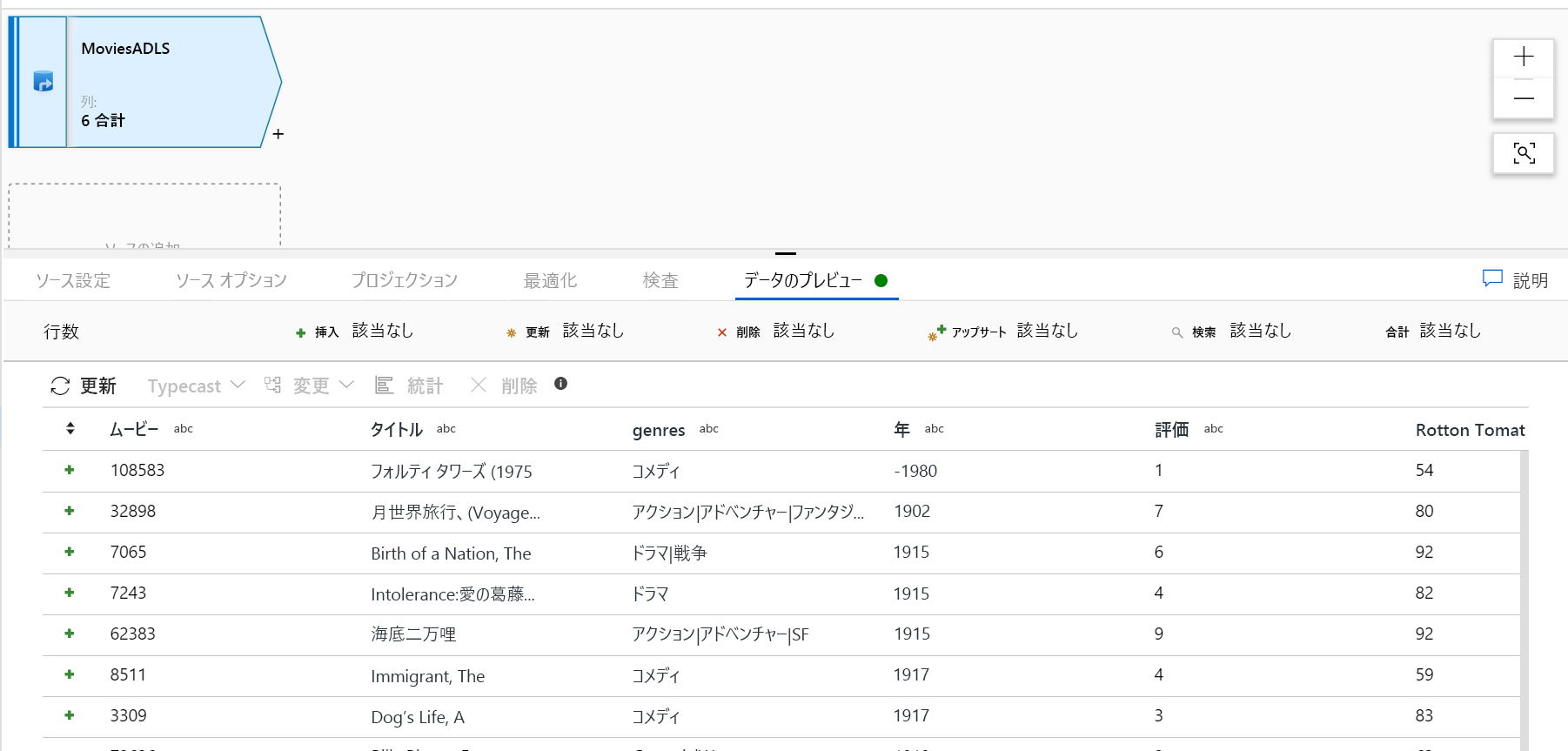
デバッグ クラスターがウォームアップしたら、[データのプレビュー] タブで、データが正しく読み込まれていることを確認します。[最新の情報に更新] ボタンをクリックすると、マッピング データ フローによって、データが各変換時にどのようになるかを示すスナップショットが表示されます。
マッピング データ フローで変換を使用する
データを Azure Data Lake Store Gen2 に移動したので、Spark クラスターを使用して大量のデータを変換し、データ ウェアハウスに読み込むためのマッピング データ フローを構築する準備ができました。
そのための主なタスクは、次のとおりです。
環境の準備
データ ソースの追加
マッピング データ フロー変換の使用
データ シンクへの書き込み
タスク 1: 環境の準備
データ フローのデバッグを有効にする 作成モジュールの上部にある [Data Flow Debug](データ フローのデバッグ) スライダーをオンにします。
Note
データ フロー クラスターのウォームアップには、5 分から 7 分かかります。
データ フロー アクティビティを追加します。 [アクティビティ] ペインで [Move and Transform](移動と変換) アコーディオンを開き、[データ フロー] アクティビティをパイプライン キャンバスにドラッグします。 ポップアップ表示されたブレードで、[Create new Data Flow](新しいデータ フローの作成) をクリックし、[マッピング データ フロー] を選択して、[OK] をクリックします。 [pipeline1] タブをクリックし、緑色のボックスを Copy アクティビティからデータ フロー アクティビティにドラッグして、成功時の条件を作成します。 キャンバスに、次のように表示されます。
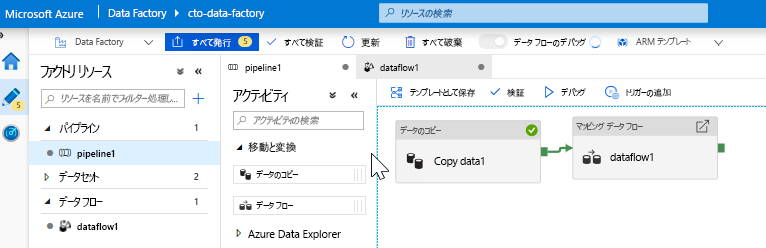
タスク 2: データ ソースの追加
ADLS ソースを追加します。 キャンバスで、マッピング データ フロー オブジェクトをダブルクリックします。 データ フロー キャンバスの [ソースの追加] ボタンをクリックします。 [Source dataset](ソース データセット) ドロップダウンで、Copy アクティビティで使用する ADLSG2 データセットを選択します
- データセットが他のファイルを含むフォルダーを指している場合は、別のデータセットを作成するか、パラメーター化を使用して moviesDB.csv ファイルのみが読み取られるようにする必要があります
- ADLS にスキーマをインポートしていないのに、既にデータを取り込んだ場合は、データセットの [スキーマ] タブに移動し、[スキーマのインポート] をクリックして、データ フローでスキーマ プロジェクションが認識されるようにします。
デバッグ クラスターがウォームアップしたら、[データのプレビュー] タブで、データが正しく読み込まれていることを確認します。[最新の情報に更新] ボタンをクリックすると、マッピング データ フローによって、データが各変換時にどのようになるかを示すスナップショットが表示されます。
タスク 3: マッピング データ フロー変換の使用
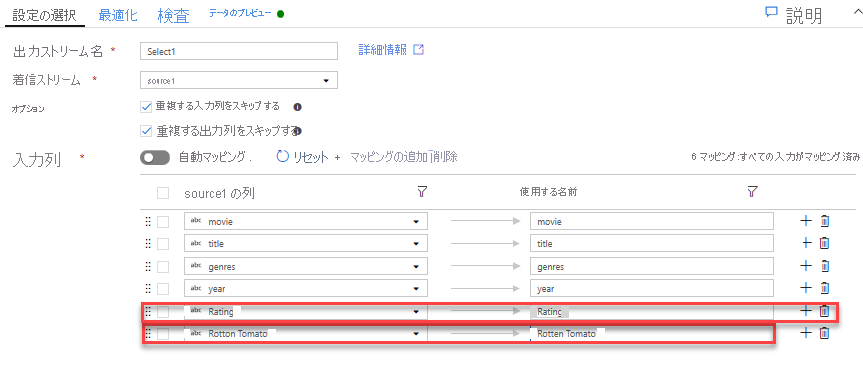
選択変換を追加して、列を名前変更して削除します。 データのプレビューで、"Rotton Tomatoes" 列のスペルが間違っていることに気付いたかもしれません。 名前を正しく指定し、使用されない Rating 列を削除するには、選択変換を追加します。そのためには、ADLS ソース ノードの横にある [+] アイコンをクリックし、[Schema modifier](スキーマ修飾子) で [Select](選択) を選択します。
[Name as](名前) フィールドで、"Rotton" を "Rotten" に変更します。 Rating 列を削除するには、その上にポインターを合わせ、ごみ箱アイコンをクリックします。
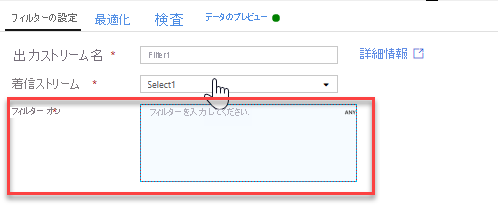
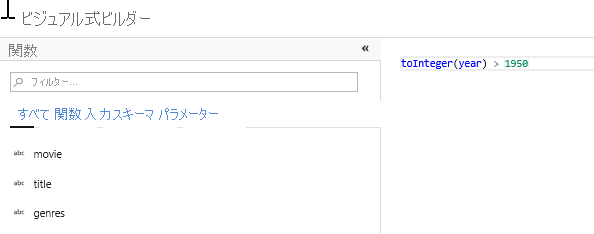
フィルター変換を追加して、不要な年を除外します。 たとえば、1951 年以降に製作された映画のみに関心があるとします。 フィルター変換を追加してフィルター条件を指定するには、選択変換の横にある [+] アイコンをクリックし、[行のモディファイアー] の下の [フィルター] を選択します。 式ボックスをクリックして式ビルダーを開き、フィルター条件を入力します。 マッピング データ フロー式言語の構文を使用すると、toInteger(year) > 1950 では文字列の年の値が整数に変換され、その値が 1950 を超えている場合に行がフィルター処理されます。
式ビルダーの埋め込みデータ プレビュー ペインを使用して、条件が適切に動作することを確認できます
プライマリ ジャンルを計算するために派生変換を追加します。 ご存知かもしれませんが、ジャンル列は "|" 文字で区切られている文字列です。 各列の "最初" のジャンルにのみ関心がある場合は、派生列変換を通じて PrimaryGenre という名前の新しい列を派生させることができます。そのためには、フィルター変換の横にある [+] アイコンをクリックし、[Schema Modifier](スキーマ修飾子) で [派生] を選択します。 フィルター変換と同様に、派生列ではマッピング データ フローの式ビルダーを使用して、新しい列の値を指定します。

このシナリオでは、ジャンル列から最初のジャンルを抽出しようとしています。ジャンル列は、"genre1|genre2|...|genreN" という書式になっています。 ジャンル文字列内の "|" の最初のインデックス (1 から始まる) を取得するには、locate 関数を使用します。 iif 関数を使用する場合、このインデックスが 1 より大きいと、プライマリ ジャンルの計算には left 関数が使用されます。この関数では、文字列内でインデックスの左側にあるすべての文字が返されます。 それ以外の場合、PrimaryGenre の値はジャンル フィールドと同じになります。 出力は、式ビルダーの [データのプレビュー] ペインを使用して確認できます。
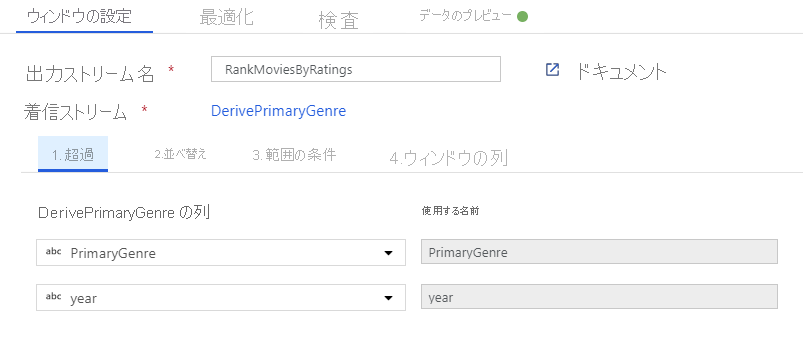
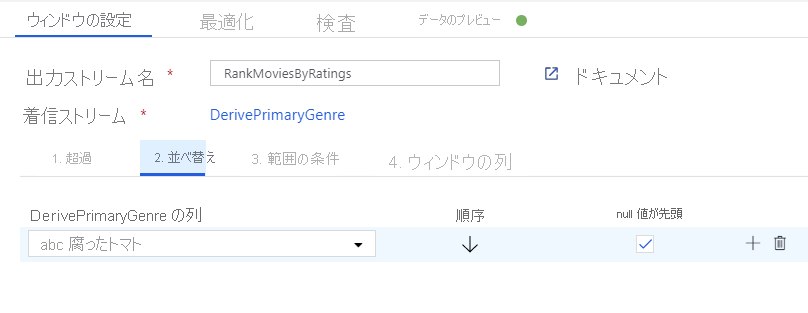
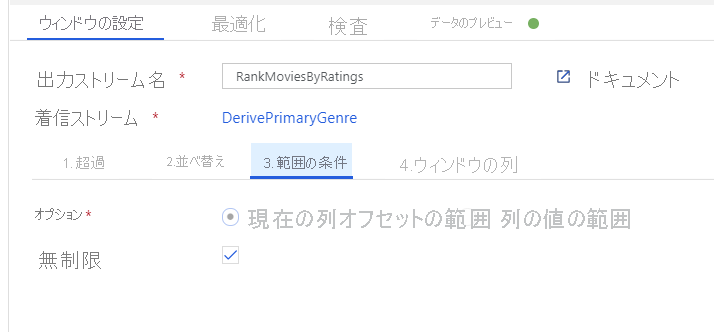
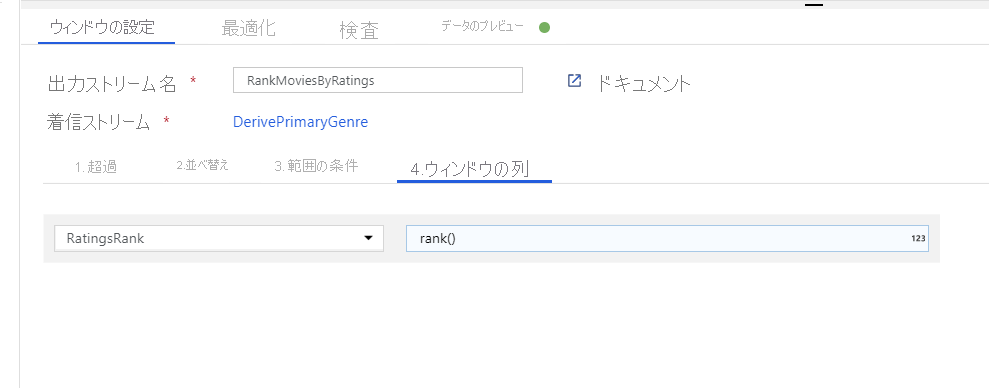
ウィンドウ変換を使用して映画を順位付けします。 ある映画が、その年の特定のジャンル内でどのように順位付けされるかを知りたいとします。 ウィンドウベースの集計を定義するには、ウィンドウ変換を追加します。そうするには、派生列変換の横にある [+] アイコンをクリックし、[Schema modifier](スキーマ修飾子) の [ウィンドウ] をクリックします。 これを完了するには、新しいウィンドウ列のウィンドウの対象、並べ替えの対象、範囲、および計算方法を指定します。 この例では、ウィンドウの対象を PrimaryGenre と非限定範囲の year にし、Rotten Tomato で降順に並べ替え、RatingsRank という名前の新しい列を計算します。この新しい列は、各映画の特定のジャンルおよび年内での順位と等しくなります。
集計変換を使用して評価を集計します。 必要なすべてのデータの収集と派生ができたので、集計変換を追加して、目的のグループに基づくメトリックを計算できます。そのためには、ウィンドウ変換の横にある [+] アイコンをクリックし、[Schema modifier](スキーマ修飾子) の [集計] をクリックします。 ウィンドウ変換で行ったように、PrimaryGenre と year で映画をグループ化しましょう
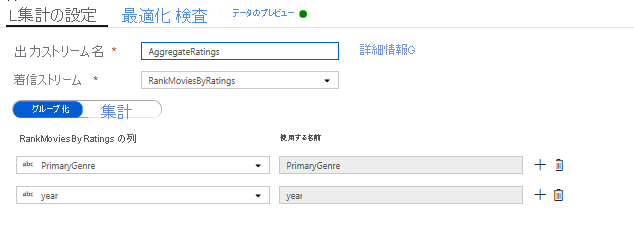
[集計] タブでは、指定したグループ化列で計算される集計を確認できます。 すべてのジャンルと年で、平均 Rotten Tomatoes 評価、最高および最低の評価の映画 (ウィンドウ機能を使用)、および各グループに属する映画の数を取得しましょう。 集計を行うと、変換ストリーム内の行の数が大幅に減少し、変換で指定されたグループ化列と集計列だけが反映されます。
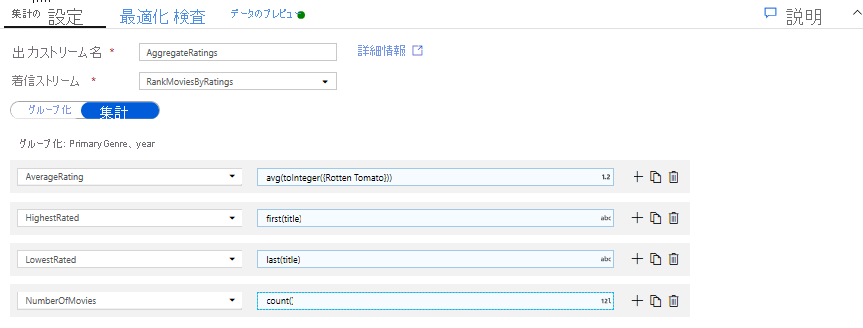
- 集計変換によってデータがどのように変更されるかを確認するには、[データのプレビュー] タブを使用します
行の変更変換を使用して、アップサート条件を指定します。 表形式シンクに書き込む場合は、行の変更変換を使用して、行に対する挿入、削除、更新、およびアップサートの各ポリシーを指定できます。そのためには、集計変換の横にある [+] アイコンをクリックし、[Row modifier](行のモディファイアー) の [行の変更] をクリックします。 挿入と更新は常に行うため、すべての行が常にアップサートされるように指定できます。

タスク 4: データ シンクへの書き込み
- Azure Synapse Analytics シンクに書き込みます。 すべての変換ロジックが完了したので、シンクに書き込む準備ができました。
アップサート変換の横にある [+] アイコンをクリックし、[Destination](ターゲット) の [シンク] をクリックして、シンクを追加します。
[シンク] タブで [+ 新規作成] ボタンを使用して、新しいデータ ウェアハウス データセットを作成します。
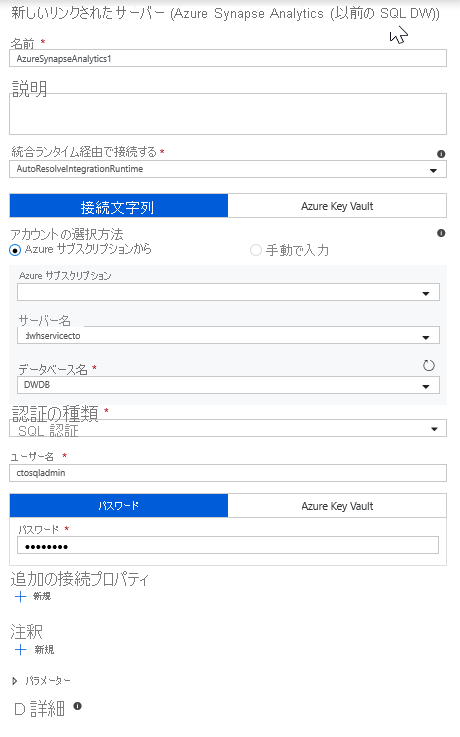
タイルの一覧から [Azure Synapse Analytics] を選択します。
新しいリンクされたサービスを選択し、モジュール 5 で作成した DWDB データベースに接続するように Azure Synapse Analytics 接続を構成します。 完了したら [作成] をクリックします。
データセットの構成で [新しいテーブルの作成] を選択し、スキーマに「dbo」、テーブル名に「Ratings」と入力します。 完了したら、[OK] をクリックします。
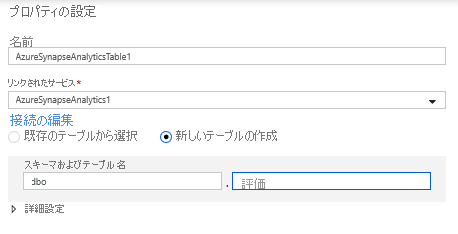
アップサート条件が指定されているため、[設定] タブにアクセスし、キー列の PrimaryGenre および year に対して [Allow upsert](アップサートを許可) を選択する必要があります。
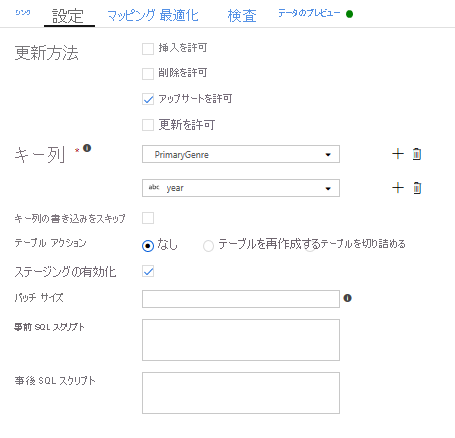
この時点で、8 つの変換マッピング データ フローの構築が完了しました。 パイプラインを実行し、結果を確認できるようになりました。

タスク 5: パイプラインの実行
キャンバスの [pipeline1] タブにアクセスします。 データ フローの Azure Synapse Analytics では PolyBase を使用するため、BLOB または ADLS ステージング フォルダーを指定する必要があります。 "データ フローの実行" アクティビティの設定タブで、PolyBase アコーディオンを開き、ADLS のリンクされたサービスを選択して、ステージング フォルダーのパスを指定します。
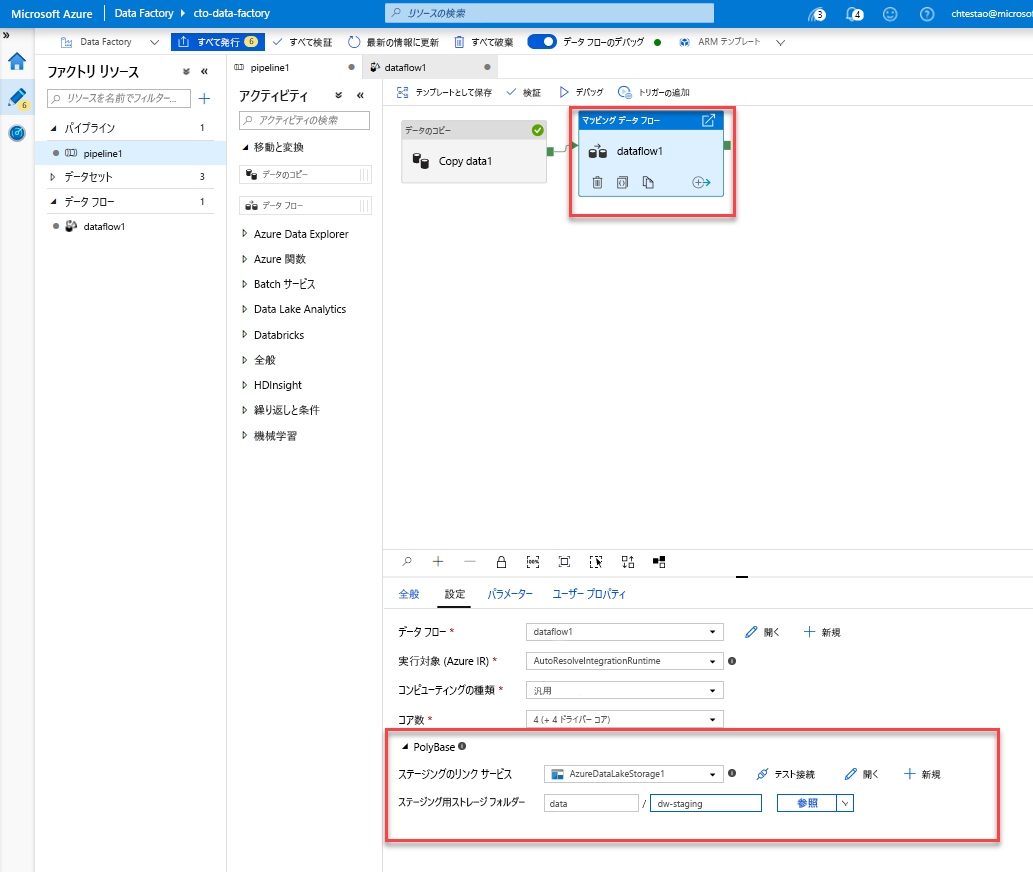
パイプラインを発行する前に、別のデバッグ実行を実行して、予期したとおりに動作していることを確認します。 [出力] タブを見ると、実行中の両方のアクティビティの状態を監視できます。
両方のアクティビティが成功したら、データ フロー アクティビティの横にある眼鏡アイコンをクリックして、データ フローの実行をより詳しく調べることができます。
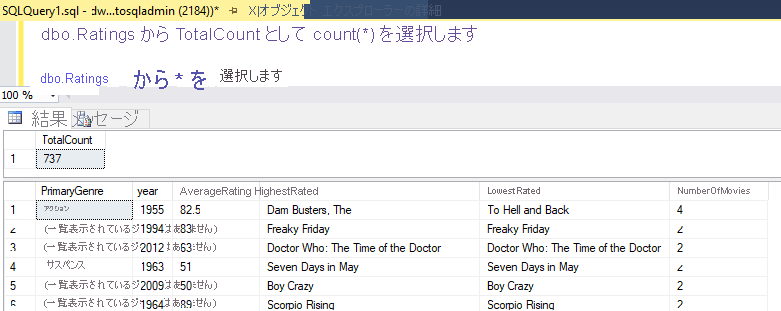
このラボで説明したのと同じロジックを使用した場合、データ フローは SQL DW に 737 行を書き込みます。 SQL Server Management Studio にアクセスすると、パイプラインが正しく動作したことを確認し、書き込まれた内容を表示できます。