適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
ヒント
データフロー Gen2 では、行の変更変換は現在サポートされていません。 サポートされている変換とその同等の変換の一覧については、 データ フロー ユーザーのマッピングに関する Dataflow Gen2 のガイドを参照してください。
行の変更変換を使用して、行の挿入、削除、更新、アップサート ポリシーを設定します。 一対多の条件を式として追加できます。 各行は最初に一致した式に対応するポリシーでマークされるので、これらの条件は優先度の順に指定する必要があります。 これらの条件によってそれぞれ、行が挿入、更新、削除、アップサートされます。 行の変更では、ご利用のデータベースに対して DDL と DML の両方を生成できます。
![[Alter row settings]\(行の変更の設定\)](media/data-flow/alter-row1.png)
行の変更変換は、データ フロー内のデータベース、REST、またはAzure Cosmos DBシンクでのみ動作します。 行に割り当てるアクション (挿入、更新、削除、アップサート) は、デバッグ セッションの間には発生しません。 データベース テーブルに対して行の変更ポリシーを適用するには、パイプラインで Data Flow実行アクティビティを実行します。
注意
SQL Serverや SAP などのネイティブ CDC ソースを使用する Change Data Capture データ フローでは、行の変更変換は必要ありません。 それらのインスタンスでは、ADF によって行マーカーが自動的に検出されるため、行の変更ポリシーは必要ありません。
既定の行ポリシーを指定する
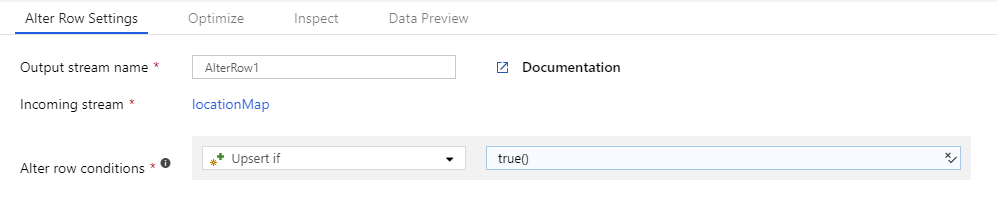
行の変更変換を作成し、true() の条件を持つ行ポリシーを指定します。 前に定義した式のいずれにも一致しない各行は、指定した行ポリシーでマークされます。 既定では、どの条件式にも一致しない各行は、Insert でマークされます。
注意
すべての行を 1 つのポリシーでマークするには、そのポリシーの条件を作成し、条件を true() として指定します。
データのプレビューでポリシーを表示する
デバッグ モードを使用して、[データのプレビュー] ペインで行の変更ポリシーの結果を表示します。 行変更変換のデータ プレビューでは、ターゲットに対する DDL または DML アクションは生成されません。
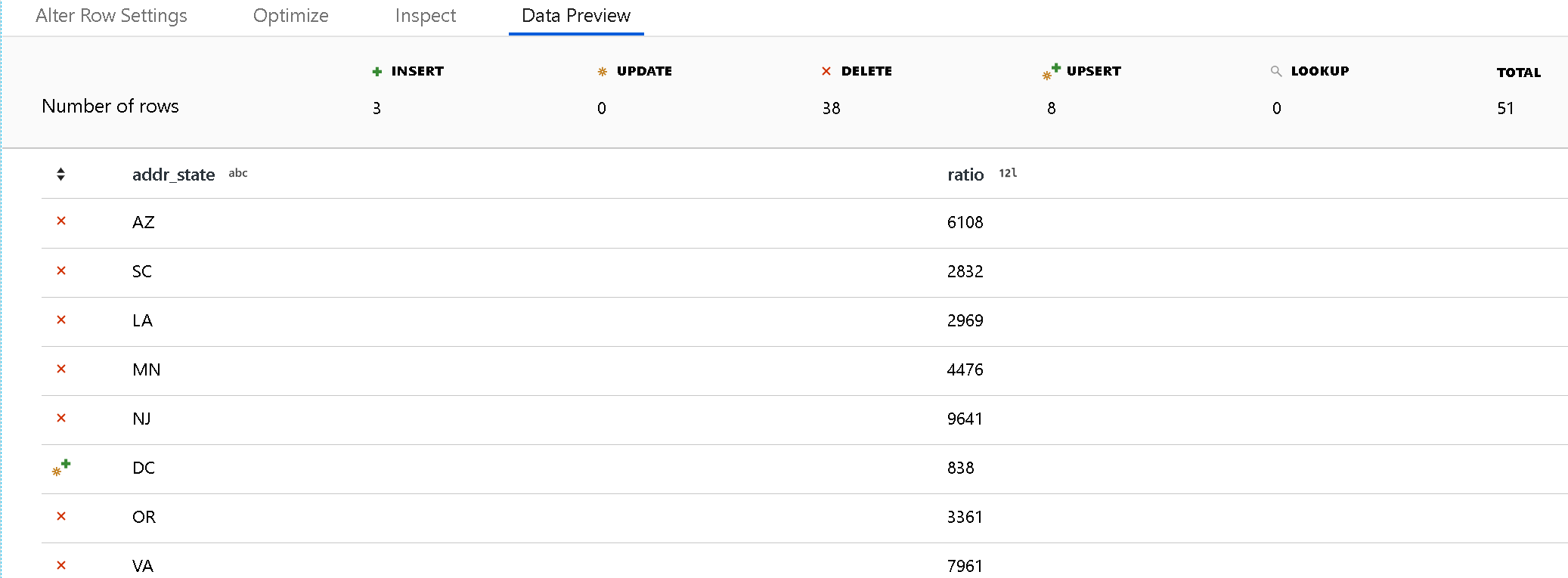
各行変更ポリシーのアイコンは、挿入、更新、アップサート、または削除アクションが発生するかどうかを示します。 上部ヘッダーは、プレビューで各ポリシーが影響を与える行数を示します。
シンクで行の変更ポリシーを許可する
行の変更ポリシーを機能させるには、データ ストリームはデータベースまたはAzure Cosmos DBシンクに書き込む必要があります。 シンクの [設定] タブで、そのシンクで許可する行の変更ポリシーを有効にします。
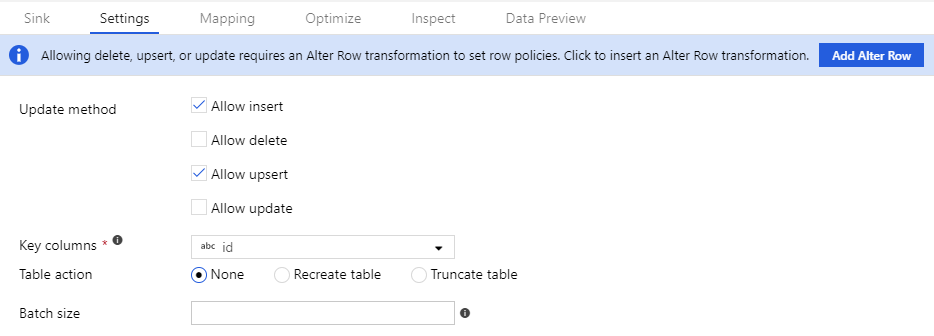
既定の動作では、挿入のみが許可されます。 更新、upsert、または削除を許可するには、その条件に対応する、シンクのチェックボックスをオンにします。 更新、upsert、または削除が有効になっている場合は、シンク内のどのキー列を照合するかを指定する必要があります。
注意
挿入、更新、または upsert によりシンクのターゲット テーブルのスキーマが変更される場合、データ フローは失敗します。 データベース内のターゲット スキーマを変更するには、テーブル アクションとして [Recreate table](テーブルの再作成) を選択します。 これにより、新しいスキーマ定義でご利用のテーブルがドロップされ、再作成されます。
シンク変換では、一意の行 ID を表す 1 つのキーまたは一連のキーがターゲット データベースに必要です。 SQL シンクの場合は、[シンク設定] タブでキーを設定します。Azure Cosmos DBの場合は、設定でパーティション キーを設定し、シンク マッピングの Azure Cosmos DB システム フィールド "ID" も設定します。 Azure Cosmos DBの場合は、更新、アップサート、および削除のシステム列 "ID" を含める必要があります。
Azure SQL DatabaseとAzure Synapseとのマージとアップサート
データ フローでは、アップサート オプションを使用して、Azure SQL DatabaseおよびAzure Synapse データベース プール (データ ウェアハウス) に対するマージがサポートされます。
しかし、ターゲット データベース スキーマでキー列の ID プロパティが使われているシナリオが発生する場合があります。 サービスでは、ユーザーは更新とアップサートの行の値を一致させるために使用するキーを識別する必要があります。 ただし、ターゲット列に ID プロパティが設定されていて、アップサート ポリシーを使っている場合、ターゲット データベースでは列への書き込みが許可されません。 分散テーブルのディストリビューション列に対して upsert を実行しようとすると、エラーが発生する場合もあります。
これを修正する方法を次に示します。
シンク変換の設定に移動し、"キー列の書き込みのスキップ" を設定します。 これにより、マッピングのキー値として選んだ列を書き込まないようにサービスに通知します。
そのキー列が ID 列の問題の原因になっている列でない場合は、シンク変換前処理の SQL オプション
SET IDENTITY_INSERT tbl_content ONを使用できます。 次に、後処理の SQL プロパティSET IDENTITY_INSERT tbl_content OFFを指定してこれをオフにします。ID ケースとディストリビューション列ケースの両方について、条件分割変換を使用して別の更新条件と別の挿入条件を使用する Upsert からロジックを切り替えることができます。 この方法では、更新パスにマッピングを設定して、キー列のマッピングを無視できます。
データ フローのスクリプト
構文
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
例
以下の例は、受信ストリーム CleanData を受け取り、行の変更条件を 3 つ作成する、SpecifyUpsertConditions という行の変更変換です。 前の変換では、データベース内で行の挿入、更新、削除を実行するかどうかを決定する alterRowCondition という列が計算されます。 列の値に、行変更ルールと一致する文字列値が含まれている場合は、そのポリシーが割り当てられています。
UI では、この変換は次の図のようになります。
この変換のデータ フロー スクリプトは、次のスニペットに含まれています。
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
関連するコンテンツ
行変更変換の後で、データをターゲットのデータ ストアにシンクすることが必要な場合があります。