Azure Cloud Service を使用して Web サイトをホストしたり、データ プロセスを続行したりする場合は、ログ システムを統合して、より詳細な情報とログ レコードを収集することをお勧めします。 Application Insights は、この目的のために設計されています。 このドキュメントでは、Application Insights とクラウド サービスを統合することでメリットを得られる一般的なシナリオについて説明します。
Cloud Service での Application Insights の使用の詳細については、 機能の概要を参照してください。
診断設定と Application Insights
Cloud Service で Application Insights が有効になっている場合は、診断設定を同時に有効にする必要があります。 診断設定によって収集される一部のメトリック データとログは、Application Insights に送信されます。 詳細については、「 Azure Cloud Services の診断を設定するを参照してください。
診断設定が有効になっている場合、 パフォーマンス カウンター 設定は Web ロールと Worker ロールで動作が異なります。
Web ロールの場合
次の 9 つのメトリックには、診断設定でパフォーマンス カウンターが無効になっている場合でも自動的に収集されるデータがあります。 これら 9 つのメトリックのデータは、Application Insights の performanceCounter テーブルに保存されます。 パフォーマンス カウンターが有効になっていると、 \Process(w3wp)\% Processor Timeなどのその他のメトリックが customMetrics テーブルに保存されます。
\Process(??APP_WIN32_PROC??)\% Processor Time
\Memory\Available Bytes
.NET CLR Exceptions(??APP_CLR_PROC??)# # of Exceps Thrown / sec
\Process(??APP_WIN32_PROC??)\Private Bytes
\Process(??APP_WIN32_PROC??)\IO Data Bytes/sec
\Processor(_Total)% Processor time
\ASP.NET Applications(??APP_W3SVC_PROC??)\Requests/sec
\ASP.NET Applications(??APP_W3SVC_PROC??)\Request Execution Time
\SP.NET Applications(??APP_W3SVC_PROC??)\Requests In Application Queue
Worker ロールの場合
診断設定でパフォーマンス カウンターが無効になっている場合、パフォーマンス メトリック データは自動的に収集され、Application Insights に保存されません。
Web ロールと Worker ロールの両方
HeartBeatState メトリック データは、常に Application Insights に自動的に保存されます。 このメトリックは、サーバー レベルでインスタンスがまだ正常かどうかを識別するために使用されます。 15 分ごとにトリガーされ、 customMetrics テーブルに保存されます。 その他のパフォーマンス メトリック データは、[診断] 設定のパフォーマンス カウンターで手動で有効にする必要があります。
重要
Application Insights では、実際のデータが収集された場合にのみレコードが生成されます。 Web ロールが要求を受け取らない場合、Worker ロールはディスクからのデータの読み取りまたはディスクへのデータの書き込みを行いません。 データ IO の量が非常に少ない場合は、Application Insights で情報が記録されない可能性があります。
次の表に、診断設定のオプションと Application Insights ログのテーブル名のマッピングを示します。
| Application Insights のテーブル | 診断設定のログ |
|---|---|
| traces | アプリケーション ログ |
| traces | ETW ログ |
| traces | インフラストラクチャ ログ |
| traces/custom イベント | Windows イベント ログ |
| カスタム メトリック | パフォーマンス カウンター |
クラウド サービスで Application Insights を使用する高度な方法
Application Insights をクラウド サービスで使用するには、いくつかの一般的な高度な方法があります。 たとえば、ユーザーはクラウド サービス プロジェクトで Azure アプリlication Insights SDK を使用して、Application Insights に保存されたデータを生成または変更できます。
カスタム ログの追加
アプリケーションにカスタム ログを追加するには、次の手順に従います。
ロール プロジェクトを右クリックし、 Manage NuGet パッケージを選択します。
Microsoft.ApplicationInsights がインストールされていることを確認します。
Application Insights 構成を .cscfg および .csdef ファイルに追加します。
Note
- インストルメンテーション キーベースのグローバル インジェストのテクニカル サポートは、2025 年 3 月 31 日に終了します。 その日付より前に Application Insights に接続するのではなく、接続文字列を使用することをお勧めします。 詳細については、「2025 年 3 月 31 日までにデータ インジェストに接続文字列を使用するを参照してください。
- Application Insights がクラウド サービス プロジェクトにリンクされると、
APPINSIGHTS_INSTRUMENTATIONKEYが自動的に追加されます。 詳細については、「 Application Insights を使用した Cloud Services アプリのトラブルシューティング - 機能の概要を参照してください。
.csdef ファイルの例を次に示します。
<ConfigurationSettings> <Setting name="APPLICATIONINSIGHTS_CONNECTION_STRING" /> <Setting name="APPINSIGHTS_INSTRUMENTATIONKEY" /> </ConfigurationSettings>.cscfg ファイルの例を次に示します。
<ConfigurationSettings> <Setting name="APPINSIGHTS_INSTRUMENTATIONKEY" value="{Instrumentation_key}" /> <Setting name="APPLICATIONINSIGHTS_CONNECTION_STRING" value="{Connection_String}" /> </ConfigurationSettings>接続文字列は、Application Insights の概要ページにあります。 詳細については、「 Application Insights インストルメンテーション キーから 接続文字列 へのアクセス」を参照してください。
ロールのスタートアップ関数に次のコードを追加します。 Web ロールのスタートアップ関数は、Global.asax で
Application_Start()。 worker ロールの場合は、WorkerRoleName.csでOnStart()。TelemetryConfiguration.Active.ConnectionString = RoleEnvironment.GetConfigurationSettingValue("APPLICATIONINSIGHTS_CONNECTION_STRING");テレメトリ クライアントを作成し、ログ コンテキストを記録します。
using Microsoft.ApplicationInsights; TelemetryClient ai = new TelemetryClient(); ai.TrackTrace("The custom log context");トレース ログに加えて、次のメソッドを使用して処理された例外を記録することもできます。
ai.TrackException(exception);
実行中の Worker ロール アプリケーションを要求として記録する
設計上、Web ロールの要求は、関連付けを識別するためにクラウド サービスの一意の ID で自動的にマークされます。 Worker ロールには、このようなシステムはありません。 ただし、Worker ロール アプリケーションの進行状況の結果を要求としてシミュレートし、この要求を Application Insights に記録することができます。 そのため、Worker ロールでアプリケーションの動作状態を確認する方法を簡略化できます。 Worker ロール アプリケーションの例を次に示します。
この worker ロールは、30 秒ごとにトレース ログを Application Insights に追加し続けます。 ただし、Run 関数が 2 つのループごとに処理済み例外を返すように、1 つの変更ブール変数が選択されているため、ログは常に正常に追加されるとは限りません。 Application Insights に記録されたトレース ログには、要求レコードと他のレコードの関係を識別するための関連付け ID として、タイムスタンプ (完全にランダムな GUID) が含まれます。 すべてのループは要求と見なされるため、開始タイムスタンプ、期間、成功状態、応答コード (成功の場合は 200、例外の場合は 500)、関連付け ID を含む要求のレコードが生成されます。
要求レコードを生成するには、 Duration 状態と成功状態 のみが必要です。 他の情報は、次の理由で要求レコードに保持されます。
開始タイムスタンプと応答コードを使用すると、実際の要求にすることができます。また、失敗した要求の場合はさまざまな応答コード (たとえば、400 と 500) は、ユーザーがさまざまなエラーの理由を特定する場合に役立ちます。
アプリケーションが複数のスレッドを使用している場合は、同時に異なるスレッドのトレース ログ、例外、要求レコードが存在する可能性があるため、ユーザーはタイムスタンプで追跡できなくなります。 すべての手順で使用される関連付け ID が重要です。 ドキュメントによると、要求の ID はグローバルに一意である必要があります。 この例が完全に動作することを確認するには、Application Insights の要求レコードで新しく生成されたランダム GUID が既に使用されているかどうかを確認する関数を追加する必要があります (これは次のコード例では実装されていません)。
using Microsoft.WindowsAzure.ServiceRuntime;
using System;
using System.Diagnostics;
using Microsoft.ApplicationInsights; //Import the Application Insight SDK
using Microsoft.ApplicationInsights.Extensibility;
using Microsoft.ApplicationInsights.DataContracts;
namespace Worker Role1
{
public class Worker Role : RoleEntryPoint
{
private TelemetryClient ai = new TelemetryClient(); //Define a private TelemetryClient
private bool select = true;
private int a = 0;
private int b;
private volatile bool onStopCalled = false;
private volatile bool returnedFromRunMethod = false;
private Stopwatch requestTimer;
private bool requestResult;
public override void Run()
{
ai.TrackTrace("Worker Role1 is running AI");
var request = new RequestTelemetry(); // Generate a RequestTelemetry. Once it's created, all the changes should be saved into this RequestTelemetry and SDK will save this RequestTelemetry into Application Insight.
while (true)
{
request.Name = "A test request"; //the following three lines configure the Name, Id and StartTime property of the request.
request.Id = Guid.NewGuid().ToString();
request.StartTime = DateTimeOffset.UtcNow;
ai.TrackTrace("New cycle. AI " + DateTimeOffset.UtcNow.ToString() + " " + request.Id);
requestTimer = Stopwatch.StartNew();
try
{
if (onStopCalled == true)
{
ai.TrackTrace("Onstopcalled Worker Role AI");
returnedFromRunMethod = true;
return;
}
if (select == true)
{
select = false;
b = 100 / a;
}
else
{
select = true;
b = 100 / 10;
}
ai.TrackTrace("normal Worker Role AI " + DateTimeOffset.UtcNow.ToString() + " " + request.Id);
requestResult = true;
}
catch (Exception ex) // Pay attention to the way that saves the custom Trace log and Exception. The unique specific ID will be helpful for us to track the request workflow in Application Insight if your application is multi thread.
{
ai.TrackTrace("Exception Worker Role AI " + DateTimeOffset.UtcNow.ToString() + " " + request.Id);
ai.TrackException(ex, new Dictionary<string, string>() { { "id", request.Id } });
requestResult = false;
}
request.Success = requestResult; //The following codes set Success, Duration and ResponseCode property of the request, then save it into Application Insight.
request.Duration = requestTimer.Elapsed;
request.ResponseCode = requestResult ? "200" : "500";
ai.TrackRequest(request);
System.Threading.Thread.Sleep(30*1000);
}
}
public override bool OnStart()
{
TelemetryConfiguration.Active.InstrumentationKey = RoleEnvironment.GetConfigurationSettingValue("APPINSIGHTS_INSTRUMENTATIONKEY");
bool result = base.OnStart();
return result;
}
public override void OnStop()
{
onStopCalled = true;
while (returnedFromRunMethod == false)
{
System.Threading.Thread.Sleep(1000);
}
}
}
}
Note
カスタム テレメトリを使用して同じことを行うこともできます。 詳細については、 Work ロールのコード サンプルを参照してください。
失敗した要求と Web ロールの関連する例外を確認する
Web ロールで失敗した要求の場合、 ai.TrackException を含むハンドルされない例外と処理された例外 (try 関数内) が例外テーブルに自動的に収集されます。
Application Insights インスタンスで例外レコードを検索するには、次のいずれかの方法を使用できます。
Azure portal で [エラー] ページを表示する
- Azure portal に移動し、Application insights インスタンスを選択し、 Failures を選択します。
- 時間範囲を調整し、対応する操作を選択して、 Operations タブで失敗した要求を見つけます。
- 操作名を選択します。 特定の例外の種類または応答コードで失敗した要求が自動的に一覧表示されます。
Azure portal でのログのクエリ
2 番目のメソッドでは、Application Insights の Logs オプションを使用します。 このメソッドはより複雑ですが、より多くのカスタム フィルターを使用して特定の種類の例外を検索できます。 また、[エラー] ページには表示されない詳細も表示されます。
設計上、Web ロールの要求は、関連付けを識別するためにクラウド サービスの一意の ID で自動的にマークされます。 要求の ID を見つけるには、次の手順に従います。
requests テーブルで失敗した要求を見つけて、その ID を記録します。
requests | where resultCode == "500"例外テーブルで、同じ ID を持つ例外を見つけます。
exceptions | where operation_ParentId == "8d1adf11abf73c42"
失敗した要求に基づいて例外を追跡すると、その要求の完全な CallStack が含まれるため、断続的なエラーの問題のトラブルシューティングに役立ちます。
失敗した要求と Worker ロールの関連する例外を確認する
ワーカー ロールのハンドルされない例外により、アプリケーション全体でダウンタイムが発生する可能性があるため、Worker ロールのすべての例外を処理することをお勧めします。 つまり、 try 関数を含める必要があります。 Web ロールで処理された例外については、Application Insights に例外を記録するために ai.TrackException が必要です。
Worker ロールで例外を確認する手順は、Web ロールの例外と似ています。 唯一の違いは、例外を自動的に記録する組み込みシステムがないため、目標をアーカイブするために追加のコードがいくつか必要であるという点です。
考えられる状況を次に示します。
Worker ロールには、カスタム要求を記録するためのシステムは含まれません。 アプリケーション内の例外レコードと実際の操作の関係を追跡するために使用できる唯一のデータは、タイムスタンプです。
この状況では、[失敗] ページを確認することはできますが、[例外] ページに切り替えて、タイムスタンプを手動で確認する必要があります。 [ログ] ページでデータの精度を確認することもできます。 特定の時間範囲の例外を確認するクエリの例を次に示します。
exceptions | where timestamp between (datetime(2022-05-11 00:00) .. datetime(2022-05-13 00:00))Worker ロールには、カスタム ID を持つカスタム要求を記録するシステムが含まれていますが、例外レコードには含まれません。 これは、前の状況と同じになります。
Worker ロールには、カスタム ID を持つカスタム要求を記録するシステムが含まれており、この例の 62 行目など、例外レコードに含まれています。 Worker ロール アプリケーションの機能を要求として記録する方法は、Web ロールの状況と同じです。 Failures ページまたは Logs ページを確認して、関連する要求と例外を見つけることができます。 [ログ] ページで使用されるクエリは次のようになります。
requests | where success == Falseexceptions | where * contains "<request ID>"
一般的なシナリオとガイドライン
このセクションでは、いくつかの一般的なシナリオと、Application Insights を使用して要件を満たすための関連ガイドラインについて説明します。
Web ロールのメモリと要求の状態を監視する
クラウド サービスの Web ロールのメモリと要求の状態を監視するには、メトリック データを収集するロールで Application Insights を有効にする必要があります。 その後、Web ロールのメモリ使用量と要求状態のデータが自動的に収集されます。
収集されたデータを表示するには、Application Insights の Metrics ページを使用することをお勧めします。 詳細については、「Application Insights の System パフォーマンス カウンター」を参照してください。
Web ロールと同様に、Worker ロールのメモリと要求の状態を監視することもできますが、いくつかの制限があります。
Worker ロールの場合、メモリ メトリック データは既定では自動的に収集されません。 メモリの状態を監視するには、診断設定のパフォーマンス カウンターから
\Memory\Available MBytesを有効にする必要があります。 収集されたデータは、[ログ] ページのcustommetricsテーブルに表示されます。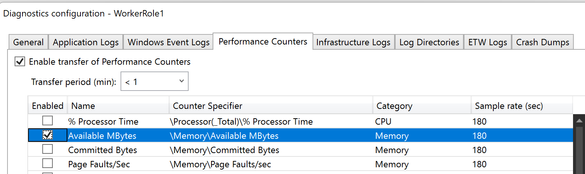
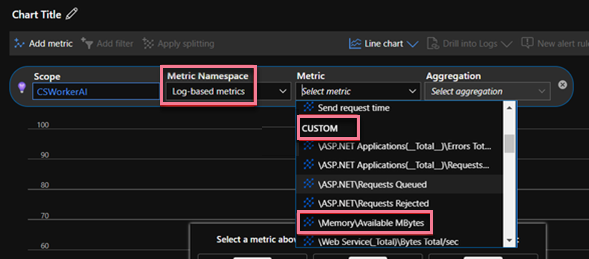
収集されたメモリ データのメトリック グラフを表示するには、Application Insights の Metrics ページに移動し、[メトリック名前空間] で Log ベースのメトリックを選択し、[メトリック] の [パフォーマンスの下にある Available Memory を選択します。 グラフには、選択した時間範囲の使用可能なメモリが表示されます。 グラフの点線は、データがデータを生成するのに十分な精度が得られないか、その時間の範囲内にデータが不足していることを意味します。 ログから、メモリ データを収集する間隔は約 3 分です。 上のグラフでは、時間範囲が [過去 1 時間] に設定されているため、2 つのポイントごとの時間差は 3 分未満になるため、収集されたデータの精度が十分ではありません。 したがって、点線です。
応答時間の遅いなどのパフォーマンスの問題のトラブルシューティング
たとえば、クラウド サービス Web ロールが要求を受信した場合、SQL Database などのリモート サーバーからデータを取得し、Web ページでデータを生成してユーザーに返す必要があります。 この進行状況が予想よりもはるかに遅いが、それでも成功したとします。 ユーザーが、SQL Database との通信中またはクラウド サービス内の進行状況の間に費やされた時間の大部分を明確にすることが望まれるのは妥当です。 そのためには、進行状況の開始、SQL Database との通信の開始、SQL Database との通信の終了、Web ページの生成の終了など、各ステップのタイムスタンプを記録するための追加のカスタム ログを追加する必要があります。
Worker ロールと Web ロールの両方で、プロセスの各開始手順でトレース ログを保存することをお勧めします。 たとえば、上記のコード例では、次の場合にトレース ログを追加できます。
- WebRole は要求を受け取ります。
- WebRole は SQL Server との通信の構築を開始します。
- WebRole は SQL Server から返されたデータを受け取り、Web ページの生成を開始します。
- WebRole によって Web ページが生成され、ユーザーに返されます。
メイン プロセスが Worker ロールのアプリケーションである場合は、カスタムの関連付け ID をカスタム要求レコードと例外レコードに追加する要求として Worker ロール アプリケーションの関数を記録します。
ロジックが実装されたら、Application Insights の Performance ページで要求を確認し、次の手順に従って要求の期間に注目できます。
- 確認する操作を選択します。
- 期間分布グラフを最も長い期間の部分にスケーリングします。
- サンプルに[ドリル]を選択。
- 例として要求を選択し、この要求の組み込み ID またはカスタム ID を取得します。
システムが過度に複雑でない場合は、さまざまな手順で費やされた時間がエンドツーエンドのトランザクション チャートに表示されます。 システムが複雑な場合、またはグラフにデータを表示できないカスタム ID を使用している場合は、次のクエリを使用して、同じ関連付け ID を含むすべての関連トレース ログを取得します。
traces
| where * contains "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
これにより、すべてのトレース ログ間の差を計算して、すべてのステップで費やされた時間を取得できます。
Worker ロールの高い CPU/メモリなどのパフォーマンスの問題のトラブルシューティング
場合によっては、非常に高い CPU/メモリを消費する Worker ロールなどの問題を特定する必要があります。 クラウド サービスの外部から観察できる唯一の点は、Worker ロールが CPU/メモリを消費しすぎているということですが、このインスタンスで何が起こっているのかまったく分かりません。
この種の問題をトラブルシューティングするには、次の 2 つの手順があります。
カスタム ログを追加して、Worker ロール アプリケーションが実行するすべてのステップを追跡します。 この手順では、アプリケーションがまだ正常に実行されているかどうかを特定し、各ステップで費やされた時間を通常の状況と比較できるため、これは非常に重要です。 これは、アプリケーションが高い CPU/メモリの問題の影響を受けるかどうかを識別するのに役立ちます。 カスタム ログ システムを追加する方法については、カスタム ログの追加を参照してください。
ダンプ ファイルをキャプチャします。 いくつかのヒントを次に示します。
リモート デスクトップを使用して、CPU/メモリの問題が高いインスタンスに接続し、CPU/メモリの大部分を消費しているプロセスを確認できます。 プロセスが WaWorkerHost の場合は、アプリケーションが過剰な CPU/メモリを消費することを意味します。
インスタンスの CPU/メモリの問題が高く、アプリケーションのパフォーマンスが低くてもクラッシュしていない場合は、リモート デスクトップを使用してインスタンスに接続し、ダンプ ファイルをキャプチャできます。 procdumps を使用して、WaWorkerHost プロセスによって消費される CPU が少なくとも 3 秒間 85% を超える場合にダンプ ファイルをキャプチャできます。 5 つのダンプ ファイルがキャプチャされ、 c:\procdumps ディレクトリに保存されます。
procdump.exe -accepteula -c 85 -s 3 -n 5 WaWorkerHost.exe c:\procdumps
クラウド サービスの [診断設定] ページでは、クラッシュ ダンプ ファイルの自動生成を設定することもできます。 詳細については、「 Azure Cloud Services と仮想マシンの診断を設定するを参照してください。