このドキュメントでは、 データ重複除去 のしくみについて説明します。
データ重複除去のしくみ
Windows Server のデータ重複除去は、次の 2 つの原則をもとに作成されました。
最適化はディスクへの書き込みの妨げになってはならない データ重複除去は、後処理モデルを使用してデータを最適化します。 すべてのデータは最適化されないままディスクに書き込まれ、後でデータ重複除去によって最適化されます。
最適化によってアクセスのセマンティクスが変更されてはならない 最適化されたボリューム上のデータにアクセスするユーザーとアプリケーションは、アクセスしているファイルが重複除去されていることをまったく認識しません。
ボリュームでデータ重複除去を有効にすると、バックグラウンドで次の処理が行われます。
- そのボリューム上のファイル全体で繰り返されるパターンを特定します。
- そのチャンクの一意のコピーを指す 再解析ポイント と呼ばれる特別なポインターを使用して、それらの部分 (チャンク) をシームレスに移動します。
これは、次の 4 つの手順で行われます。
- 最適化ポリシーを満たすファイルについて、ファイル システムをスキャンします。

- ファイルをさまざまなサイズのチャンクに分割します。

- 一意のチャンクを識別します。
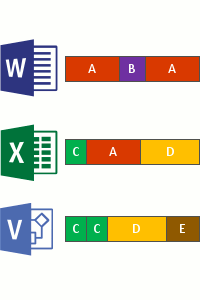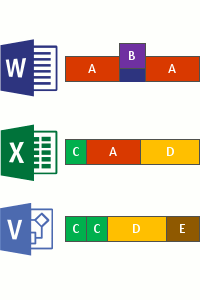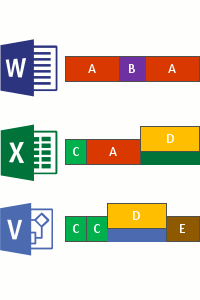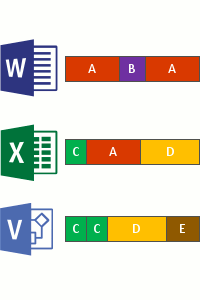
- チャンクをチャンク ストアに配置し、必要に応じて圧縮します。
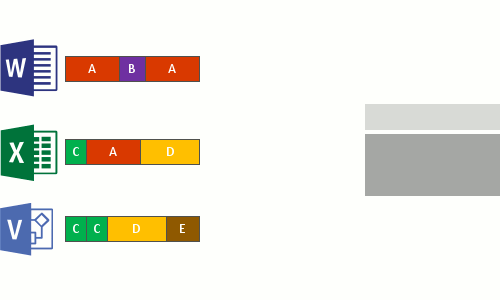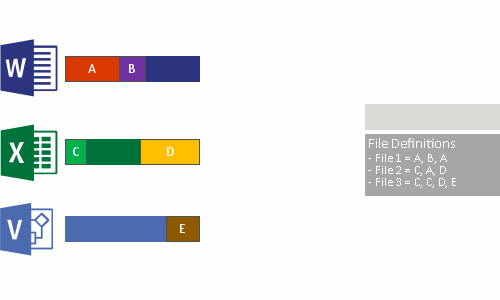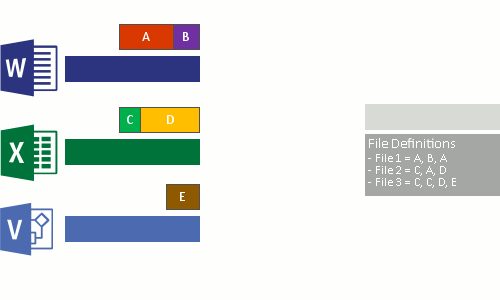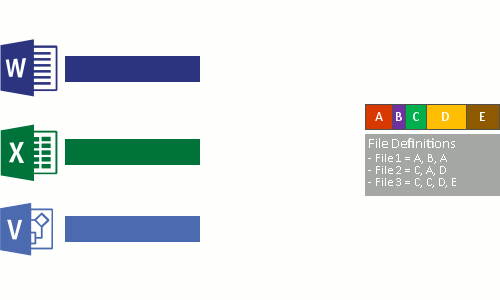
- 最適化されたファイルの元のファイル ストリームをチャンク ストアへの再解析ポイントに置き換えます。
最適化されたファイルが読み取られると、再解析ポイントを使用して、ファイル システムからファイルがデータ重複除去ファイル システム フィルター (Dedup.sys) に送信されます。 フィルターによって、読み取り操作は適切なチャンクにリダイレクトされ、チャンク ストア内のそのファイル用のストリームが構成されます。 重複除去されたファイルの範囲に対する変更は、最適化されていないディスクに書き込まれ、次回の実行時に 最適化ジョブ によって最適化されます。
使用法の種類
次の使用法の種類は、一般的なワークロードに対して合理的なデータ重複除去の構成を提供します。
| 使用法の種類 | 理想的なワークロード | 何が異なるのか |
|---|---|---|
| デフォルト | 汎用ファイル サーバー:
|
|
| Hyper-V | 仮想デスクトップ インフラストラクチャ (VDI) サーバー |
|
| バックアップ | Microsoft Data Protection Manager (DPM) などの仮想化バックアップ アプリケーション |
|
Jobs
データ重複除去は、処理後の戦略を使用してボリュームのスペース効率を最適化および維持します。
| ジョブ名 | 職務記述書 | 既定のスケジュール |
|---|---|---|
| 最適化 | 最適化ジョブは、ボリューム ポリシー設定に従ってボリューム上のデータをチャンクし、必要に応じてそれらのチャンクを圧縮し、チャンクをチャンク ストアに一意に格納することで重複除去します。 データ重複除去が使用する最適化プロセスの詳細については、「データ重複除去のしくみ」を参照してください。 | 1 時間ごと |
| ガベージ コレクション | ガベージ コレクション ジョブは、最近変更または削除されたファイルによって参照されなくなった不要なチャンクを削除することで、ディスク領域を解放します。 | 毎週土曜日、午前 2 時 35 分 |
| 整合性スクラブ | 整合性スクラブ ジョブは、ディスク障害または不良セクターによるチャンク ストアの破損を識別します。 可能な場合、データ重複除去は、ボリューム機能 (記憶域スペース ボリューム上のミラーまたはパリティなど) を自動的に使用して、破損したデータを再構築することができます。 また、データ重複除去では、チャンクの参照回数が 100 回を超える場合に、頻繁に参照されるチャンクのバックアップ コピーをホットスポットと呼ばれる領域に保持します。 | 毎週土曜日、午前 3 時 35 分 |
| 最適化の解除 | 最適化 解除 ジョブは、手動でのみ実行する特殊なジョブであり、重複除去によって行われる最適化を元に戻し、そのボリュームのデータ重複除去を無効にします。 | オンデマンドのみ |
データ重複除去の用語
| Term | Definition |
|---|---|
| チャンク | チャンクは、他の同様のファイルで発生する可能性があるとして、データ重複除去のチャンクを行うアルゴリズムによって選択されたファイルのセクションです。 |
| チャンク ストア | チャンク ストアは、データ重複除去がチャンクを一意に格納するために使用する、システム ボリューム情報フォルダー内で編成された一連のコンテナー ファイルです。 |
| 重複除去 | PowerShell、Windows Server API およびコンポーネント、Windows Server コミュニティで一般的に使用されるデータ重複除去の略称。 |
| ファイル メタデータ | すべてのファイルには、ファイルの主要な内容には関連しない、ファイルに関する興味深いプロパティを説明するメタデータが含まれています。 たとえば、作成日、前回の読み取り日、作成者などです。 |
| ファイル ストリーム | ファイル ストリームは、ファイルの主要な内容です。 これが、データ重複除去によって最適化されるファイルの部分です。 |
| ファイル システム | ファイル システムは、オペレーティング システムがストレージ メディア上にファイルを保存できるようにするためのソフトウェアおよびディスク上のデータ構造です。 データ重複除去は、NTFS でフォーマットされたボリュームでサポートされます。 |
| ファイル システム フィルター | ファイル システム フィルターは、ファイル システムの既定の動作を変更するプラグインです。 アクセスのセマンティクスを維持するため、データ重複除去は、ファイル システム フィルター (Dedup.sys) 使用して、読み取り要求を行っているユーザーまたはアプリケーションに対して、読み取りを最適化されたコンテンツに完全に透過的にリダイレクトします。 |
| 最適化 | ファイルは、ファイルがチャンクされ、その固有のチャンクがチャンク ストアに格納されている場合、データ重複除去によって最適化 (または重複除去) されていると見なされます。 |
| 最適化ポリシー | 最適化ポリシーは、データ重複除去を考慮すべきファイルを指定します。 たとえば、ファイルが新しいか、開かれているか、ボリューム上の特定のパスにあるか、または特定のファイルの種類である場合に、ポリシー外として見なされます。 |
| 再解析ポイント | 再解析ポイントは、指定されたファイル システム フィルターに I/O を渡すことをファイル システムに通知する特別なタグです。 ファイルのファイル ストリームが最適化されると、データ重複除去がそのファイル ストリームを再解析ポイントと置き換えることにより、データ重複除去は、そのファイルのアクセス セマンティクスを保持することができます。 |
| 容積 | ボリュームは、1 つまたは複数のサーバー間の複数の物理記憶域デバイスにまたがる可能性がある論理記憶域ドライブの Windows コンストラクトです。 重複除去はボリュームごとに有効にします。 |
| ワークロード | ワークロードは、Windows Server 上で実行されるアプリケーションです。 ワークロードの例には、汎用ファイル サーバー、Hyper-V、SQL Server などがあります。 |
Warning
権限のある Microsoft サポート担当者によって指示された場合を除き、チャンク ストアを手動で変更しようとしないでください。 変更しようとすると、データを破損または消失する可能性があります。
よく寄せられる質問
データ重複除去は他の最適化製品とどのように違いますか。 データ重複除去とその他の一般的な記憶域最適化製品の間にはいくつかの重要な違いがあります。
データ重複除去は単一インスタンス ストアとどのように違いますか。 単一インスタンス ストア (SIS) は、Windows Storage Server 2008 R2 で初めて導入された、データ重複除去に先行するテクノロジでした。 単一インスタンス ストアは、ボリュームを最適化するために、完全に同一のファイルを特定して、それらのファイルを SIS の共通ストアに格納されているファイルの単一のコピーへの論理リンクに置き換えます。 単一インスタンス ストアとは異なり、データ重複除去は、同一ではないが、多くの共通するパターンを共有するファイルや、ファイル自体に多くの繰り返しパターンが含まれているファイルから、スペースを節約することができます。 単一インスタンス ストアは、Windows Server 2012 R2 で非推奨とされ、データ重複除去を優先するため Windows Server 2016 で削除されました。
データ重複除去は NTFS 圧縮とどのように違いますか。 NTFS 圧縮は、必要に応じてボリューム レベルで有効にできる NTFS の機能です。 NTFS 圧縮では、書き込み時の圧縮によって、各ファイルが個別に最適化されます。 NTFS 圧縮とは異なり、データ重複除去はボリューム上のすべてのファイルにまたがってスペースを節約できます。 これは、ファイルに内部重複 (NTFS 圧縮によって対処される) とボリューム上の他のファイル (NTFS 圧縮では対処されない) の 両方 が含まれる可能性があるため、NTFS 圧縮よりも優れています。 さらに、データ重複除去は処理後のモデルを採用しています。つまり、新規のファイルまたは変更されたファイルは最適化されていない状態でディスクに書き込まれ、データ重複除去によって後で最適化されます。
データ重複除去は zip、rar、7 z、cab などのアーカイブ ファイル形式とどのように違いますか。 zip、rar、7 z、cab などのアーカイブ ファイル形式は、指定されたファイルのセットに対して圧縮を実行します。 データ重複除去と同様に、ファイル内の重複するパターンとファイル全体の重複するパターンは最適化されます。 ただし、アーカイブに含めるファイルは選択する必要があります。 また、アクセスのセマンティクスも異なります。 アーカイブ内の特定のファイルにアクセスするには、アーカイブを開き、特定のファイルを選択し、そのファイルを展開して使用する必要があります。 データ重複除去はユーザーと管理者に対して透過的に動作し、手動で開始する必要はありません。 さらに、データ重複除去では、アクセスのセマンティクスが保持されます。最適化されたファイルは、最適化後も変更されていません。
選択した使用法の種類のデータ重複除去設定を変更することができますか。 Yes. データ重複除去は 推奨されるワークロードに適切な既定値を提供しますが、データ重複除去の設定を調整してストレージを最大限に活用したい場合があります。 また、他のワークロードでは、データ重複除去によってワークロードが妨げられないようにするために、一定の調整を行う必要があります。
データ重複除去ジョブを手動で実行できますか。 はい、すべてのデータ重複除去ジョブを手動で実行することができます。 これは、スケジュールされたジョブがシステム リソースの不足、またはエラーにより実行されなかった場合に望ましいことがあります。 また、非最適化ジョブは手動でのみ実行できます。
データ重複除去ジョブの履歴結果を監視できますか。 はい、すべてのデータ重複除去ジョブは Windows イベント ログにエントリが作成されます。
システムでデータ重複除去ジョブの既定のスケジュールを変更できますか。 はい、すべてのスケジュールは設定可能です。 既定のデータ重複除去のスケジュールを変更することは、特にデータ重複除去ジョブを完了するための時間を確保し、ワークロードのリソースと競合しないようにするために望ましい変更です。