このトピックには、ディザスター リカバリー用にハイパーコンバージド インフラストラクチャ (HCI) を構成する方法に関するシナリオが記載されています。
多くの企業がハイパーコンバージド ソリューションを実行しています。災害に備えた計画を立てておくと、災害が発生した場合に、実稼働を維持したり、すぐに実稼働に戻したりすることができます。 ディザスター リカバリー用に HCI を構成する方法は複数ありますが、このドキュメントでは、現在、選択できる方法について説明します。
障害が発生した場合の可用性の復元に関する議論は、目標復旧時間 (RTO) と呼ばれるものを中心に展開されます。 これは、ビジネスにとって許容できない結果を忌避するために、サービスが復元される必要のある目標期間です。 状況によっては、ほぼ瞬時に実稼働環境が復元され、このプロセスが自動的に発生することがあります。 その他の状況では、管理者が手動で介入して復元サービスを実行する必要があります。
現在のハイパーコンバージドでのディザスター リカバリーの方法は、次のとおりです。
- 記憶域レプリカを使用する複数のクラスター
- クラスター間の Hyper-V レプリカ
- バックアップと復元
記憶域レプリカを使用する複数のクラスター
記憶域レプリカを使用すると、ボリュームのレプリケーションが可能になり、同期レプリケーションと非同期レプリケーションの両方がサポートされます。 同期レプリケーションと非同期レプリケーションのどちらを選択するかを検討している場合は、自分の目標復旧時点 (RPO) を考慮する必要があります。 目標復旧時点とは、大きな損失と見なされず、発生が許容されるデータ損失の量です。 同期レプリケーションを使用する場合、これは、同時に両端で実行される順次書き込みです。 非同期レプリケーションを使用する場合は、書き込みが非常に高速でレプリケートされますが、それでも失われる可能性があります。 どちらが最適かを調べるには、アプリケーションまたはファイルの使用状況を考慮する必要があります。
記憶域レプリカは、ファイル レベルではなく、ブロック レベルのコピー メカニズムです。つまり、レプリケートされるデータの種類は関係ありません。 このため、ハイパーコンバージド インフラストラクチャで一般的に使用されています。 記憶域レプリカは、さまざまな種類のドライブをレプリケーション パートナー間で利用することもできます。そのため、1 つの HCI 上に 1 種類の記憶域すべてを、もう一方の HCI 上に別の種類の記憶域を使用しても、まったく問題はありません。
記憶域レプリカの重要な機能の 1 つは、Azure とオンプレミスで実行できる点です。 オンプレミスからオンプレミスへ、Azure から Azure へと設定でき、オンプレミスから Azure (またはその逆) へと設定することもできます。
このシナリオでは、2 つの独立したクラスターがあります。 HCI 間で記憶域レプリカを構成する場合は、「クラスター間の記憶域レプリケーション」の手順に従います。

記憶域レプリカのデプロイ時には、以下を考慮する必要があります。
- レプリケーションの構成は、フェールオーバー クラスタリングの外側で実行されます。
- 選択すべきレプリケーション方法は、ネットワーク待機時間と RPO 要件によって異なります。 同期レプリケーションでは、クラッシュ整合性のある、待機時間の短いネットワーク上でデータがレプリケートされるため、障害が発生した時点でデータが失われることはありません。 非同期レプリケーションでは、待機時間が長いネットワーク上でデータがレプリケートされますが、障害が発生した時点での各サイトのコピーが同じではない可能性があります。
- 障害が発生した場合は、クラスター間のフェールオーバーが自動では実行されないため、記憶域レプリカ PowerShell コマンドレットを使用して手動でフェールオーバーを調整する必要があります。 上の図では、ClusterA がプライマリで、ClusterB がセカンダリです。 ClusterA がダウンした場合は、手動で ClusterB をプライマリとして設定してから、各リソースを起動する必要があります。 ClusterA は、バックアップしたら、セカンダリにする必要があります。 すべてのデータが同期された後は、変更を加え、役割を元の設定に戻します。
- 記憶域レプリカはデータをレプリケートしているだけであるため、このデータを使用する新しい仮想マシンまたはスケール アウト ファイル サーバー (SOFS) を、レプリカ パートナーのフェールオーバー クラスター マネージャー内に作成する必要があります。
仮想マシンまたは SOFS がクラスターで実行されている場合は、記憶域レプリカを使用できます。 PowerShell スクリプトを使用すると、レプリカ HCI でリソースを、手動または自動でオンラインにすることができます。
Hyper-V レプリカ
Hyper-V レプリカは、ハイパーコンバージド インフラストラクチャでのディザスター リカバリーのための仮想マシン レベルのレプリケーションを提供します。 Hyper-V レプリカで実行できる操作は、仮想マシンを使用して、セカンダリ サイトまたは Azure (レプリカ) にレプリケートすることです。 その後、セカンダリ サイトから、Hyper-V レプリカで仮想マシンを 3 番目のサイトにレプリケートできます (拡張レプリカ)。
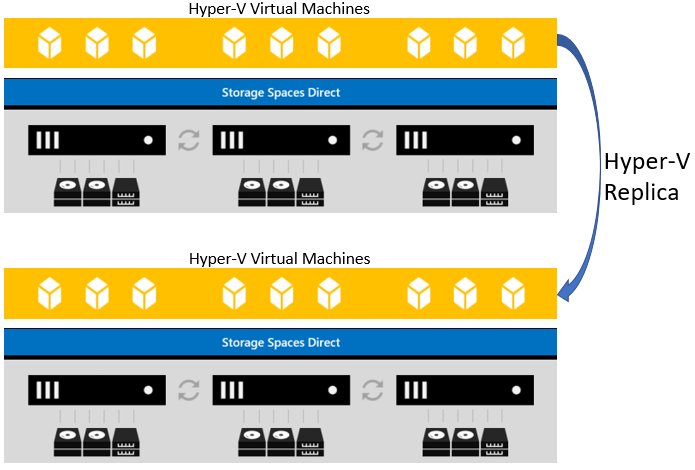
Hyper-V レプリカでは、レプリケーションが Hyper-V によって行われます。 仮想マシンを初めてレプリケーション可能にするときは、対応するレプリカ クラスターに初期コピーを送信する方法を、次の 3 つから選択します。
- ネットワークを使用して初期コピーを送信する
- サーバーに手動でコピーできるように初期コピーを外部メディアに送信する
- レプリカ ホストで既に作成されている既存の仮想マシンを使用する
さらに、この初期レプリケーションを実行するタイミングも選択する必要があります。
- すぐにレプリケーションを開始する
- 初期レプリケーションを実行する時刻を設定する
その他に考慮する必要のある事項は、次のとおりです。
- どの VHD/VHDX をレプリケートするか。 すべてをレプリケートするか、1 つのみをレプリケートするかを選択できます。
- 保存する復旧時点の数。 復元する時点に関する複数の選択肢を希望する場合は、必要な数を指定することができます。 復元する時点が 1 つのみの場合は、その時点も選択できます。
- ボリューム シャドウ コピー サービス (VSS) でインクリメンタル シャドウ コピーをレプリケートする頻度。
- 変更がレプリケートされる頻度 (30 秒、5 分、15 分)。
HCI が Hyper-V レプリカに参加する場合は、各クラスターに Hyper-V レプリカ ブローカー リソースが作成されている必要があります。 このリソースの機能は、次のとおりです。
- Hyper-V レプリカが接続するクラスターごとに 1 つの名前空間を提供します。
- レプリカ (または拡張レプリカ) がコピーを最初に受信するときに、そのクラスター内に存在するノードを決定します。
- 仮想マシンが別のノードに移動した場合に備えて、どのノードがレプリカ (または拡張レプリカ) を所有するかを追跡します。 この追跡は、レプリケーションの実行時に、適切なノードに情報を送信するために必要です。
バックアップと復元
従来のディザスター リカバリー オプションには、あまり話題に上らないが、同様に重要であるものもあります。それは、クラスター全体、またはクラスター内の 1 ノードの障害です。 このシナリオでは、どちらのオプションでも、Windows Server Backup を使用します。
ハイパーコンバージド インフラストラクチャの定期的なバックアップは常に推奨されています。 クラスター サービスの実行中に、システム状態のバックアップを実行すると、クラスター レジストリ データベースがバックアップに含まれます。 クラスターまたはデータベースの復元には、2 つの異なる方法 (権限のない、および権限のある) があります。
権限のない復元
権限のない復元は、Windows Server Backup を使用して実行でき、クラスター ノード自体の完全な復元と同じです。 クラスター ノード (およびクラスター レジストリ データベース) と、現在のすべてのクラスター情報のみの復元が必要である場合は、権限のない復元を実行します。 権限のない復元は、Windows Server Backup インターフェイスまたはコマンド ライン WBADMIN.EXE を使用して実行できます。
ノードを復元したら、クラスターに参加させます。 このとき、ノードは、実行中の既存のクラスターにアクセスし、ノード自体のすべての情報を、クラスターにある現在の情報に更新します。
権限のある復元
一方、権限のある復元をクラスター構成に実行すると、クラスター構成が時間内に元に戻ります。 この種類の復元を実行する必要があるのは、クラスター情報自体が失われ、復元が必要である場合のみです。 たとえば、1,000 を超える共有を含むファイル サーバーが誤って削除され、それを元に戻す必要がある場合です。 権限のある復元をクラスターで完了するには、コマンド ラインでバックアップを実行する必要があります。
権限のある復元がクラスター ノードで開始されると、クラスター ビュー内の他のすべてのノードでクラスター サービスが停止され、クラスター構成が固定されます。 復元が実行されたノード上のクラスター サービスを最初に開始する必要があるのは、このためです。こうすると、クラスター構成の新しいコピーを使用してクラスターが形成されます。
権限のある復元を実行するには、次の手順を実行します。
管理コマンド プロンプトで WBADMIN.EXE を実行して、インストールするバックアップの最新バージョンを取得し、システム状態が、復元可能なコンポーネントの 1 つであることを確認します。
wbadmin get versions既にあるバージョン バックアップに、クラスター レジストリ情報がコンポーネントとして含まれるかどうかを特定します。 このコマンドから必要な項目は、手順 3 で使用するバージョンとアプリケーション/コンポーネントの 2 つです。 バージョンの例を挙げます。バックアップが 2018 年 1 月 3 日の午前 2:04 に実行され、これを復元する必要があるとします。
wbadmin get items -backuptarget:\\backupserver\location権限のある復元を開始して、必要なクラスター レジストリ バージョンのみを復元します。
wbadmin start recovery -version:01/03/2018-02:04 -itemtype:app -items:cluster
復元が実行された後は、このノードが、最初にクラスター サービスを開始し、クラスターを形成するノードである必要があります。 その後に、他のすべてのノードを開始し、クラスターに参加させる必要があります。
まとめ
これを要約すると、ハイパーコンバージド ディザスター リカバリーは、慎重に計画する必要のある作業です。 ニーズに最適なシナリオはいくつかあり、十分にテストする必要があります。 過去にフェールオーバー クラスターをよく使用していた場合に注意が必要なのは、長い間、非常に一般的な方法であったストレッチ クラスターです。 ハイパーコンバージド ソリューションでは、回復性に基づいて設計が少し変更されています。 ハイパーコンバージド クラスターで 2 つのノードが失われた場合は、クラスター全体がダウンします。 この場合、ハイパーコンバージド環境では、ストレッチのシナリオがサポートされません。