このチュートリアルの前のステージでは、お使いのコンピューターに PyTorch をインストールしました。 次に、それを使用して、モデルを作成するために使用するデータを使用してコードを設定します。
Visual Studio 内で新しいプロジェクトを開きます。
- Visual Studio を開き、[
create a new project] を選択します。
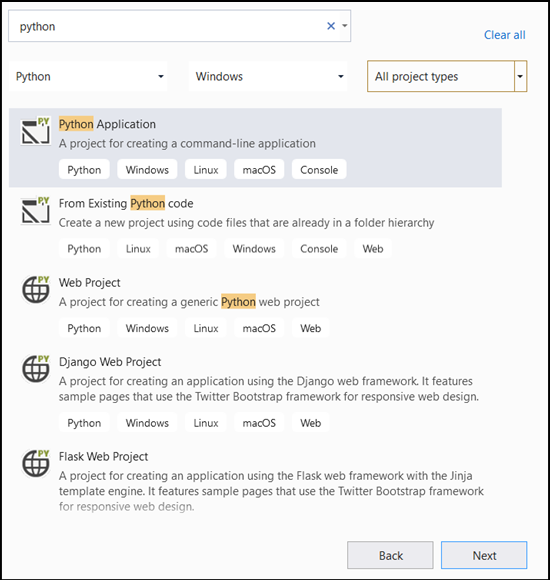
- 検索バーに「
Python」と入力し、プロジェクト テンプレートPython Application選択します。
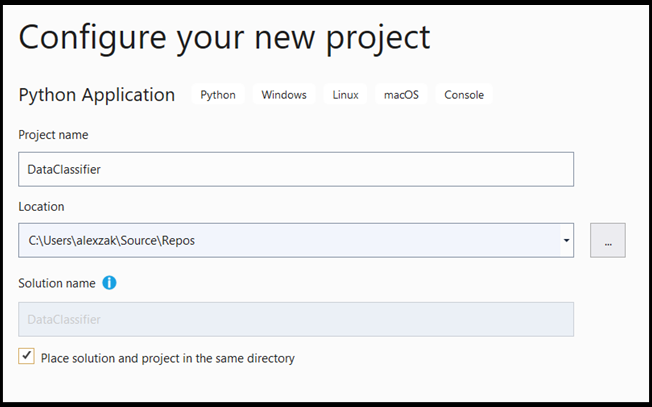
- 構成ウィンドウで、次の手順を実行します。
- プロジェクトに名前を付けます。 ここでは、 DataClassifier と呼びます。
- プロジェクトの場所を選択します。
- VS2019 を使用している場合は、
Create directory for solutionがオンになっていることを確認します。 - VS2017 を使用している場合は、
Place solution and project in the same directoryがオフになっていることを確認します。
createキーを押してプロジェクトを作成します。
Python インタープリターを作成する
次に、新しい Python インタープリターを定義する必要があります。 これには、最近インストールした PyTorch パッケージが含まれている必要があります。
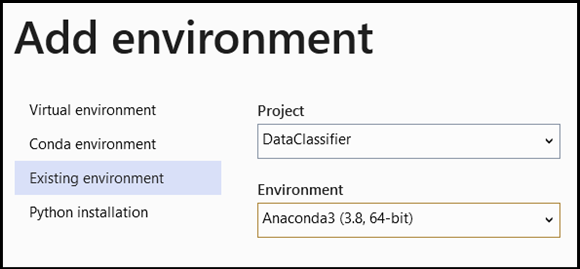
- インタープリターの選択に移動し、
Add Environmentを選択します。

- [
Add Environment] ウィンドウで [Existing environment] を選択し、[Anaconda3 (3.6, 64-bit)] を選択します。 これには、PyTorch パッケージが含まれます。
新しい Python インタープリターと PyTorch パッケージをテストするには、 DataClassifier.py ファイルに次のコードを入力します。
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
出力は、次のようなランダムな 5x3 テンソルである必要があります。
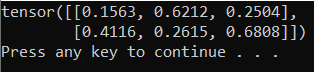
注
もっと詳しく知りたいですか? PyTorch 公式 Web サイトを参照してください。
データの説明
フィッシャーのあやめの花データセットでモデルをトレーニングします。 この有名なデータセットには、Iris setosa、Iris virginica、Iris versicolor の 3 つのあやめの種ごとに 50 個のレコードが含まれています。
データセットのいくつかのバージョンが公開されています。 UCI Machine Learning リポジトリで Iris データセットを見つけたり、Python Scikit-learn ライブラリから直接データセットをインポートしたり、以前に公開された他のバージョンを使用したりできます。 あやめの花データセットの詳細については、 Wikipedia のページを参照してください。
このチュートリアルでは、表形式の入力を使用してモデルをトレーニングする方法を紹介するために、Excel ファイルにエクスポートされた Iris データセットを使用します。
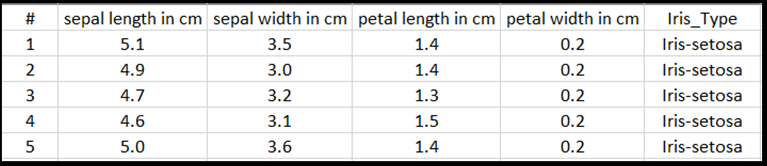
Excel テーブルの各行には、アヤメの特徴として、4 つの要素「セパルの長さ」、「セパルの幅」、「花弁の長さ」、「花弁の幅」がセンチメートル(cm)単位で表示されます。これらの特徴は入力として使用されます。 最後の列には、これらのパラメーターに関連する Iris 型が含まれており、回帰出力を表します。 このデータセットには、4 つの特徴の入力が合計 150 件含まれており、関連するアヤメの種類にそれぞれが一致しています。
回帰分析では、入力変数と結果の関係が確認されます。 入力に基づいて、モデルは正しい出力の種類 (Iris-setosa、Iris-versicolor、Iris-virginica の 3 種類のいずれか) を予測することを学習します。
重要
他のデータセットを使用して独自のモデルを作成する場合は、シナリオに応じてモデルの入力変数と出力を指定する必要があります。
データセットを読み込みます。
Iris データセットを Excel 形式でダウンロードします。 ここで見つけることができます。
DataClassifier.pyファイル フォルダーの ファイルで、次の import ステートメントを追加して、必要なすべてのパッケージにアクセスします。
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
ご覧のように、pandas (Python データ分析) パッケージを使用して、データを読み込んで操作し、ニューラル ネットワークを構築するためのモジュールと拡張可能なクラスを含む torch.nn パッケージを操作します。
- データをメモリに読み込み、クラスの数を確認します。 各アイリスのタイプにおいて50個のアイテムがあることを期待しています。 必ず、PC 上のデータセットの場所を指定してください。
次のコードを DataClassifier.py ファイルに追加します。
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
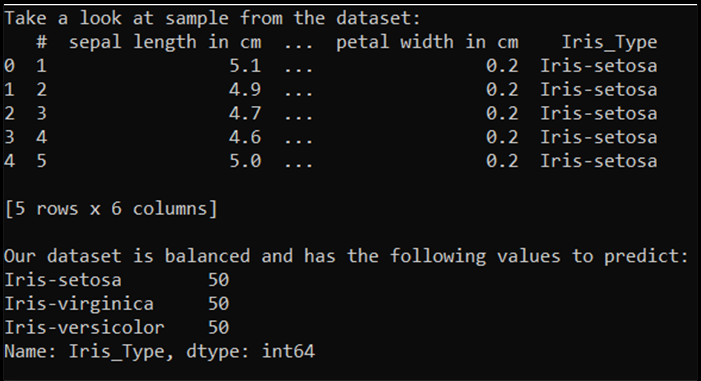
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
このコードを実行すると、予想される出力は次のようになります。
データセットを使用してモデルをトレーニングできるようにするには、入力と出力を定義する必要があります。 入力には 150 行の特徴が含まれており、出力はアヤメの種類の列です。 使用するニューラル ネットワークには数値変数が必要であるため、出力変数を数値形式に変換します。
- 出力を数値形式で表し、回帰の入力と出力を定義する新しい列をデータセットに作成します。
次のコードを DataClassifier.py ファイルに追加します。
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
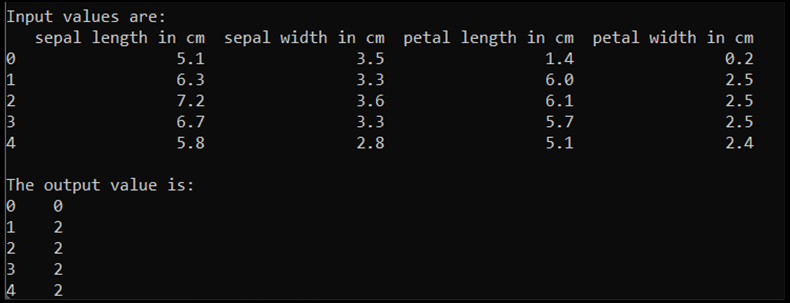
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
このコードを実行すると、予想される出力は次のようになります。
モデルをトレーニングするには、モデルの入力と出力を Tensor 形式に変換する必要があります。
- Tensor に変換する:
次のコードを DataClassifier.py ファイルに追加します。
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
コードを実行すると、次のように、予想される出力に入力と出力の形式が表示されます。

150 個の入力値があります。 約 60% がモデル トレーニング データになります。 検証には 20%、テストには 30% を保持します。
このチュートリアルでは、トレーニング データセットのバッチ サイズを 10 として定義します。 トレーニング セットには 95 個の項目があります。つまり、トレーニング セットを 1 回 (1 エポック) 反復処理する完全なバッチが平均で 9 つあります。 検証セットとテスト セットのバッチ サイズは 1 のままにします。
- データを分割して、セットをトレーニング、検証、テストします。
次のコードを DataClassifier.py ファイルに追加します。
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
次のステップ
データの準備ができたら、PyTorch モデルをトレーニングします