Устранение неполадок с бессерверным пулом SQL в Azure Synapse Analytics
В этой статье содержатся сведения по устранению часто возникающих проблем с бессерверным пулом SQL в Azure Synapse Analytics.
Дополнительные сведения о Azure Synapse Analytics см. в статье "Обзор" и "Новые возможности Azure Synapse Analytics?".
Synapse Studio
Synapse studio — это простая в использовании программа, позволяющая получать доступ к данным с помощью браузера без установки инструментов доступа к базам данных. Synapse Studio не предназначено для чтения большого набора данных или полного управления SQL-объектами.
Бессерверный пул SQL неактивен в Synapse Studio
Если в Synapse Studio не удается установить подключение к бессерверному пулу SQL, вы заметите, что бессерверный пул SQL неактивен или отображается статус Отключено.
Как правило, эта проблема возникает по одной из двух причин:
- Сеть запрещает обмен данными с серверной частью Azure Synapse Analytics. Наиболее частым случаем является блокировка TCP-порта 1443. Чтобы бессерверный пул SQL заработал, разблокируйте этот порт. Работе бессерверного пула SQL могут препятствовать другие проблемы. Дополнительные сведения см. в руководстве по устранению неполадок.
- У вас нет разрешения на вход в бессерверный пул SQL. Чтобы получить доступ, один из администраторов рабочей области Azure Synapse должен добавить вас в роль администратора рабочей области или администратора SQL. Дополнительные сведения см. в статье Управление доступом на основе ролей в Azure.
Подключение WebSocket было неожиданно закрыто
Запрос может завершиться ошибкой с сообщением об ошибке Это сообщение Websocket connection was closed unexpectedly. означает, что подключение браузера к Synapse Studio было прервано, например из-за проблемы с сетью.
- Чтобы устранить эту проблему, повторите запрос.
- Попробуйте вместо Synapse Studio использовать Azure Data Studio или SQL Server Management Studio для тех же запросов с целью дальнейшего изучения проблемы.
- Если это сообщение часто появляется в вашей среде, обратитесь за помощью к сетевому администратору. Кроме того, можно проверить параметры брандмауэра и сравнить с инструкциями вруководстве по устранению неполадок.
- Если проблема остается, создайте запрос в службу поддержки на портале Azure.
Бессерверные базы данных не отображаются в Synapse Studio
Если вы не видите баз данных, созданных в бессерверном пуле SQL, убедитесь, что ваш бессерверный пул SQL запущен. Если бессерверный пул SQL отключен, базы данных не будут отображаться. Выполните любой запрос, например SELECT 1 в бессерверном пуле SQL, чтобы активировать его, и базы данных отобразятся.
Бессерверный пул SQL Synapse отображается как недоступный
Причиной часто является неправильная конфигурация сети. Убедитесь, что порты настроены правильно. Если вы используете брандмауэр или частные конечные точки, проверьте эти параметры также.
Наконец, убедитесь, что соответствующие роли предоставлены и не были отозваны.
Не удается создать новую базу данных, так как запрос будет использовать старый или просроченный ключ
Эта ошибка вызвана изменением управляемого клиентом рабочей области ключа, используемого для шифрования. Вы можете повторно зашифровать все данные в рабочей области с использованием последней версии активного ключа. Чтобы повторно зашифровать данные, смените ключ на временный на портале Azure, а затем снова смените ключ на тот, который хотите использовать для шифрования. Узнайте, как управлять ключами рабочей области.
Бессерверный пул SQL Synapse недоступен после передачи подписки другому клиенту Microsoft Entra
При перемещении подписки в другой клиент Microsoft Entra может возникнуть некоторые проблемы с бессерверным пулом SQL. Создайте запрос в службу поддержки и поддержка Azure обратитесь к вам, чтобы устранить проблему.
Доступ к хранилищу
Если при попытке получить доступ к файлам в хранилище Azure возникают ошибки, убедитесь, что у вас есть разрешение на доступ к данным. У вас должна быть возможность доступа к общедоступным файлам. Если вы пытаетесь получить доступ к данным без учетных данных, убедитесь, что удостоверение Microsoft Entra может напрямую получить доступ к файлам.
Если у вас есть ключ подписанного URL-адреса, который необходимо использовать для доступа к файлам, убедитесь, что вы создали учетные данные уровня сервера или уровня базы данных, которые содержат эти учетные данные. Учетные данные необходимы для доступа к данным с помощью управляемого удостоверения рабочей области и настраиваемого имени субъекта-службы (SPN).
Не удается прочитать файлы в хранилище Azure Data Lake Storage, вывести их список или получить доступ к ним
Если вы используете имя входа Microsoft Entra без явных учетных данных, убедитесь, что удостоверение Microsoft Entra может получить доступ к файлам в хранилище. Чтобы получить доступ к файлам, удостоверение Microsoft Entra должно иметь разрешение средства чтения данных BLOB-объектов или разрешения для списков управления доступом для списка и чтения (ACL) в ADLS. Дополнительные сведения см. в разделе Сбой запроса из-за невозможности открытия файла.
Если вы обращаетесь к хранилищу с помощью учетных данных, убедитесь, что у управляемого удостоверения или имени субъекта-службы есть роль средства чтения данных или участника или определенные разрешения ACL. Если вы использовали маркер подписанного URL-адреса, убедитесь, что он имеет разрешение rl и срок его действия не истек.
Если вы используете имя входа SQL и OPENROWSET функцию без источника данных, убедитесь, что у вас есть учетные данные уровня сервера, соответствующие URI хранилища и имеющие разрешение на доступ к хранилищу.
Сбой запроса из-за невозможности открыть файл
Если запрос завершается ошибкой File cannot be opened because it does not exist or it is used by another process , и вы уверены, что оба файла существуют и не используются другим процессом, бессерверный пул SQL не может получить доступ к файлу. Эта проблема обычно возникает, так как удостоверение Microsoft Entra не имеет прав доступа к файлу или потому, что брандмауэр блокирует доступ к файлу.
По умолчанию бессерверный пул SQL пытается получить доступ к файлу с помощью удостоверения Microsoft Entra. Чтобы устранить эту проблему, необходимо получить соответствующие права доступа к файлу. Проще всего предоставить себе роль "Участник данных BLOB-объектов хранилища" в учетной записи хранения, с которой вы пытаетесь выполнить запрос.
Дополнительные сведения см. в разделе:
- Управление доступом к идентификаторам Microsoft Entra для хранилища
- Управление доступом к учетной записи хранения в бессерверном пуле SQL в Azure Synapse Analytics
Альтернатива роли участника для данных BLOB-объектов хранилища
Вместо предоставления себе роли "Участник данных BLOB-объектов хранилища" можно предоставить более детализированные разрешения для доступа к подмножеству файлов.
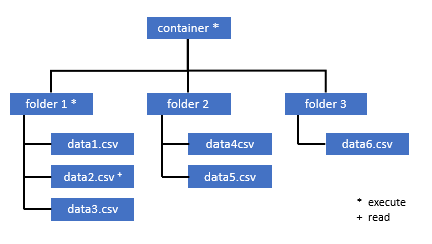
Всем пользователям, которым необходим доступ к некоторым данным в этом контейнере, также необходимо разрешение EXECUTE (ВЫПОЛНЕНИЕ) для всех родительских папок вплоть до корневой (контейнера).
Дополнительные сведения о настройке списков управления доступом в Azure Data Lake Storage 2-го поколения.
Примечание.
Разрешение на выполнение на уровне контейнера должно быть задано в Azure Data Lake Storage 2-го поколения. Разрешения для папки можно задать в Azure Synapse.
Если в этом примере вы хотите запросить файл data2.csv, необходимы следующие разрешения:
- разрешение на выполнение для контейнера
- разрешение на выполнение для папки1
- разрешение на чтение для файла data2.csv
Войдите в Azure Synapse с помощью учетной записи администратора, обладающей полными правами доступа к данным, к которым вы хотите получить доступ.
В области данных нажмите правой кнопкой мыши на файле и выберите Manage access (Управление доступом).
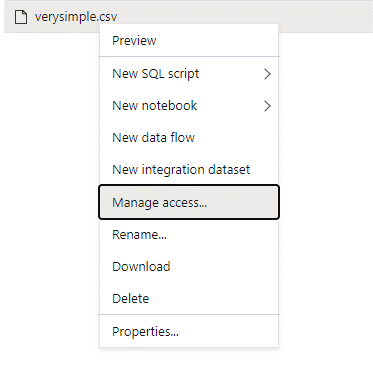
Выберите по крайней мере разрешение Read (Чтение). Введите имя участника-пользователя или идентификатор объекта, например
user@contoso.com. Выберите Добавить.Предоставьте разрешение на чтение этому пользователю.

Примечание.
Для гостевых пользователей это необходимо сделать непосредственно с помощью службы Azure Data Lake, так как напрямую через Azure Synapse это выполнить невозможно.
Невозможно создать список содержимого каталога, к которому ведет путь
Эта ошибка означает, что пользователь, который запрашивает Azure Data Lake, не может вывести список файлов в хранилище. Существует несколько сценариев, в которых может возникнуть эта ошибка:
- Пользователь Microsoft Entra, использующий сквозную проверку подлинности Microsoft Entra, не имеет разрешения на перечисление файлов в Data Lake служба хранилища.
- Идентификатор Microsoft Entra или пользователь SQL, который считывает данные с помощью ключа подписанного URL-адреса или управляемого удостоверения рабочей области, и этот ключ или удостоверение не имеет разрешения на перечисление файлов в хранилище.
- Пользователь, обращающийся к данным Dataverse, не имеет разрешения на запрос данных в Dataverse. Этот сценарий может произойти при использовании пользователей SQL.
- Пользователь, обращающийся к Delta Lake, может не иметь разрешения на чтение журнала транзакций Delta Lake.
Самый простой способ устранить эту проблему — предоставить себе роль участника данных больших двоичных объектов служба хранилища в учетной записи хранения, которую вы пытаетесь запросить.
Дополнительные сведения см. в разделе:
- Управление доступом к идентификаторам Microsoft Entra для хранилища
- Управление доступом к учетной записи хранения в бессерверном пуле SQL в Azure Synapse Analytics
Невозможно вывести список содержимого таблицы Dataverse
Если вы используете Azure Synapse Link для Dataverse для чтения связанных таблиц DataVerse, необходимо использовать учетную запись Microsoft Entra для доступа к связанным данным с помощью бессерверного пула SQL. Дополнительные сведения см. в статье Azure Synapse Link для Dataverse с Azure Data Lake.
При попытке использовать учетные данные для входа в SQL для чтения внешней таблицы, ссылающейся на таблицу Dataverse, возникнет следующая ошибка: External table '???' is not accessible because content of directory cannot be listed.
Внешние таблицы dataverse всегда используют сквозную проверку подлинности Microsoft Entra. Вы не можете настроить их для использования ключа подписанного URL-адреса или управляемого удостоверения рабочей области.
Невозможно вывести список содержимого журнала транзакций Delta Lake
Следующая ошибка возвращается, если бессерверный пул SQL не может выполнить чтение папки журнала транзакций Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Убедитесь, что папка _delta_log существует. Возможно, вы запрашиваете обычные файлы Parquet, которые не преобразованы в формат Delta Lake. _delta_log Если папка существует, убедитесь, что у вас есть разрешение на чтение и список в базовых папках Delta Lake. Попробуйте считывать json-файлы непосредственно с помощью FORMAT='csv'. Поместите универсальный код ресурса (URI) в параметр BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
В случае сбоя этого запроса вызывающий объект не имеет разрешения на чтение базовых файлов хранилища.
Выполнение запросов
Ошибки могут возникнуть во время выполнения запроса в следующих случаях:
- Вызывающий объект не может получить доступ к некоторым объектам.
- Запрос не может получить доступ к внешним данным.
- Запрос содержит некоторые функции, которые не поддерживаются в бессерверных пулах SQL.
Сбой выполнения запроса из-за текущих ограничений ресурсов
Запрос может завершиться ошибкой с сообщением об ошибке This query cannot be executed due to current resource constraints. Это сообщение означает, что бессерверный пул SQL не может выполняться в данный момент. Вот несколько вариантов устранения неполадок:
- Убедитесь, что используются типы данных допустимого размера.
- Если запрос предназначен для файлов Parquet, рекомендуем определить явные типы для строковых столбцов, так как по умолчанию они будут иметь тип VARCHAR(8000). Проверка выводимых типов данных.
- Если запрос предназначен для CSV-файлов, создайте статистику.
- Сведения о том, как оптимизировать создание запросов см. в рекомендациях по повышению производительности для бессерверного пула SQL.
Время ожидания запроса истекло
Ошибка Query timeout expired возвращается, если запрос выполнялся более 30 минут в бессерверном пуле SQL. Это ограничение для бессерверного SQL пула невозможно изменить.
- Попробуйте оптимизировать свой запрос, применяя рекомендации.
- Попробуйте материализовать части запросов с помощью создания внешней таблицы в виде выбора (CETAS).
- Убедитесь в отсутствии параллельной рабочей нагрузки в бессерверном пуле, так как ресурсы могут быть заняты другими запросами. В этом случае рабочую нагрузку можно разделить на несколько рабочих областей.
Недопустимое имя объекта
Ошибка Invalid object name 'table name' указывает, что вы используете объект, например таблицу или представление, которая не существует в базе данных бессерверного пула SQL. Попробуйте выполнить следующие действия:
Выведите список таблиц или представлений и убедитесь, что объект существует. Используйте SQL Server Management Studio или Azure Data Studio, так как Synapse Studio может отображать некоторые таблицы, недоступные в бессерверном пуле SQL.
Если вы видите объект, проверьте, используются ли параметры сортировки с учетом регистра / параметры двоичной сортировки базы данных. Возможно, имя объекта не совпадает с именем, использованным в запросе. При использовании параметров двоичной сортировки базы данных
Employeeиemployee— два разных объекта.Если объект не отображается, возможно, вы пытаетесь запросить таблицу из базы данных Lake или Spark. Таблица может быть недоступна в бессерверном пуле SQL, так как:
- Таблица содержит некоторые типы столбцов, которые не могут быть представлены в бессерверном пуле SQL.
- Формат таблицы не поддерживается в бессерверном пуле SQL. Примерами являются Avro или ORC.
Строковые или двоичные данные будут усечены
Эта ошибка возникает, если длина типа строки или двоичного столбца (например VARCHAR, VARBINARYили NVARCHAR) короче фактического размера данных, которые вы читаете. Эту ошибку можно исправить, увеличив длину типа столбца:
- Если строковый столбец определен как
VARCHAR(32)тип, а текст равен 60 символам, используйтеVARCHAR(60)тип (или длиннее) в схеме столбца. - Если вы используете вывод схемы (без
WITHсхемы), все строковые столбцы автоматически определяются какVARCHAR(8000)тип. Если вы получаете эту ошибку, явным образом определите схему вWITHпредложении с более крупнымVARCHAR(MAX)типом столбца, чтобы устранить эту ошибку. - Если таблица находится в базе данных Lake, попробуйте увеличить размер строкового столбца в пуле Spark.
SET ANSI_WARNINGS OFFПопробуйте включить бессерверный пул SQL для автоматического усечения значений VARCHAR, если это не повлияет на ваши функциональные возможности.
Незакрытые кавычки в конце строки символов
В некоторых редких случаях, когда вы используете оператор LIKE в строковом столбце или при некотором сравнении со строковыми литералами, может возникнуть следующая ошибка:
Unclosed quotation mark after the character string
Эта ошибка может произойти при использовании параметра сортировки Latin1_General_100_BIN2_UTF8 в столбце. Попробуйте задать параметр сортировки Latin1_General_100_CI_AS_SC_UTF8 для столбца вместо Latin1_General_100_BIN2_UTF8, чтобы устранить проблему. Если ошибка по-прежнему проявляется, отправьте запрос в службу поддержки через портал Azure.
Не удалось выделить пространство tempdb при передаче данных из одного распределения в другое
Ошибка Could not allocate tempdb space while transferring data from one distribution to another возвращается, когда подсистема выполнения запросов не может обрабатывать данные и передавать их между узлами, выполняющими запрос. Это частный случай стандартной ошибки Сбой выполнения запроса из-за текущих ограничений ресурсов. Она возникает, когда ресурсов, выделенных для базы данных tempdb, недостаточно для выполнения запроса.
Перед отправкой запроса в службу поддержки воспользуйтесь рекомендациями по устранению проблемы.
Сбой запроса с ошибкой при обработке внешнего файла (достигнуто максимальное число ошибок)
Если запрос завершается ошибкой с сообщением error handling external file: Max errors count reachedоб ошибке, это означает, что несоответствие указанного типа столбца и данных, которые необходимо загрузить.
Чтобы получить дополнительные сведения об ошибке и о том, какие строки и столбцы следует искать, измените версию средства синтаксического анализа с 2.0 на 1.0.
Пример
Если вы хотите запросить файл names.csv с помощью этого запроса 1, бессерверный пул SQL Azure Synapse возвращается со следующей ошибкой: Например: Error handling external file: 'Max error count reached'. File/External table name: [filepath].
Файл names.csv содержит следующее:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Запрос 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Причина
После изменения версии средства синтаксического анализа с 2.0 на 1.0 сообщения об ошибках помогают определить проблему. Новое сообщение об ошибке теперь Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Усечение говорит о том, что наш тип столбца слишком мал для размещения наших данных. Самое длинное имя в этом names.csv файле имеет семь символов. Поэтому соответствующий используемый тип данных должен быть по меньшей мере VARCHAR(7). Эта ошибка вызвана следующей строкой кода:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Изменение запроса соответствующим образом устраняет ошибку. После отладки измените версию средства синтаксического анализа на 2.0, чтобы добиться максимальной производительности.
Дополнительные сведения об использовании версии средства синтаксического анализа см. в статье Использование OPENROWSET с использованием бессерверного пула SQL в Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Массовая загрузка невозможна, так как файл не удалось открыть
Ошибка Cannot bulk load because the file could not be opened возвращается, если файл изменяется во время выполнения запроса. Как правило, может возникнуть ошибка Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Бессерверные пулы SQL не поддерживают считывание файлов, изменяемых во время выполнения запроса. Запрос не может снять блокировку файлов. Если вы знаете, что операция изменения добавляется, можно попробовать задать следующий параметр: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}
Дополнительные сведения о том, как запрашивать файлы только для добавления данных или создавать таблицы для файлов только для добавления данных.
Сбой запроса с ошибкой преобразования данных
Запрос может завершиться ошибкой с сообщением Об ошибке Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Это сообщение означает, что типы данных не соответствуют фактическим данным для номера строки n и столбца m.
Например, это сообщение об ошибке будет получено, если в данных предполагается использовать только целые числа, но в строке n присутствует текстовый фрагмент.
Чтобы устранить эту проблему, проверьте файл и выбранные типы данных. Убедитесь, что разделитель строк и признак конца поля были указаны правильно. В следующем примере показано выполнение проверки, используя VARCHAR в качестве типа столбца.
Дополнительные сведения о признаках конца поля, разделителях строк и escape-кавычках см. в разделе Запрос CSV-файлов.
Пример
Если вы хотите запросить файл names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
С помощью следующего запроса:
Запрос 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Бессерверный пул SQL Azure Synapse возвращает ошибку Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Необходимо просмотреть данные и принять обоснованное решение для устранения этой проблемы. Чтобы просмотреть данные, вызывающие эту проблему, необходимо сначала изменить тип данных. Теперь для анализа этой проблемы вместо запроса столбца «ID» с типом данных SMALLINT используется VARCHAR(100).
Используя немного измененный запрос 2, можно обработать данные и вывести список имен.
Запрос 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Вы можете заметить, что данные имеют непредвиденные значения идентификатора в пятой строке. В таком случае важно согласовать с бизнес-владельцем данных, как избегать поврежденных данных, подобных этим. Если этого невозможно избежать на уровне приложений, единственным вариантом является VARCHAR разумного размера.
Совет
Попробуйте сделать VARCHAR() как можно меньше. По возможности избегайте использования VARCHAR(MAX), так как это может снизить производительность.
Результат запроса выглядит не так, как ожидалось
Запрос может не завершиться ошибкой, но будет видно, что результирующий набор не такой, как ожидалось. Полученные столбцы могут быть пустыми или с неожиданными данными. В этом сценарии, вероятно, неправильно выбран разделитель строк или признак конца поля.
Чтобы устранить эту проблему, необходимо еще раз просмотреть данные и изменить эти параметры. Отладка этого запроса проста, как показано в следующем примере.
Пример
Если вы хотите запросить файл names.csv с помощью запроса «Запрос 1», бессерверный пул SQL Azure Synapse возвращается с результатом, который выглядит непривычно:
В names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Вероятно, в столбце Firstname значения отсутствуют. Вместо этого все значения находятся в столбце ID. Значения разделяются запятыми. Проблема вызвана этой строкой кода, так как в качестве признака конца поля необходимо выбрать запятую вместо точки с запятой:
FIELDTERMINATOR =';',
Изменение этого символа решит проблему.
FIELDTERMINATOR =',',
Результирующий набор, созданный с помощью запроса «Запрос 2», теперь выглядит, как ожидалось:
Запрос 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Возвращает:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Столбец с типом несовместим с внешним типом данных
Если запрос завершается ошибкой с сообщением Column [column-name] of type [type-name] is not compatible with external data type […], об ошибке, скорее всего, тип данных PARQUET сопоставлен с неправильным типом данных SQL.
Например, это сообщение об ошибке будет получено, если в файле parquet существует столбец цены с числами с плавающей запятой (например, 12,89), и вы попытаетесь сопоставить его с типом INT (целые числа).
Чтобы устранить эту проблему, проверьте файл и выбранные типы данных. Эта таблица сопоставления помогает корректно выбрать тип данных SQL. Рекомендация: укажите сопоставление только для тех столбцов, которые в противном случае были бы преобразованы в тип данных VARCHAR. Можно повысить производительность запросов, по возможности избегая использования VARCHAR.
Пример
Если вы хотите запросить файл taxi-data.parquet с помощью этого запроса 1, бессерверный пул SQL Azure Synapse возвращает следующую ошибку:
taxi-data.parquet Файл содержит следующее:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Запрос 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Это сообщение об ошибке говорит о том, что типы данных несовместимы, и сразу предлагается использовать тип FLOAT (числа с плавающей точкой) вместо INT (целые числа). Эта ошибка вызвана следующей строкой кода:
SumTripDistance INT,
Используя немного измененный запрос «Запрос 2», можно обработать данные и отобразить все три столбца:
Запрос 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Запрос ссылается на объект, который не поддерживается в режиме распределенной обработки
Ошибка The query references an object that is not supported in distributed processing mode указывает, что вы использовали объект или функцию, которую нельзя использовать при запросе данных в служба хранилища Azure или аналитическом хранилище Azure Cosmos DB.
Некоторые объекты, такие как системные представления и функции, не могут использоваться при запросе данных, хранящихся в Azure Data Lake или в хранилище аналитики Azure Cosmos DB. Старайтесь не использовать запросы, которые объединяют внешние данные с системными представлениями, загружают внешние данные во временную таблицу или используют некоторые функции безопасности или метаданных для фильтрации внешних данных.
Сбой вызова WaitIOCompletion
Сообщение WaitIOCompletion call failed об ошибке указывает, что запрос завершился, пока не завершится операция ввода-вывода, которая считывает данные из удаленного хранилища Azure Data Lake.
Сообщение об ошибке имеет следующий шаблон: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Убедитесь, что хранилище находится в том же регионе, что и бессерверный пул SQL. Проверьте метрики хранилища и убедитесь, что на уровне хранения другие рабочие нагрузки отсутствуют, такие как отправка новых файлов, которые могут перегружать запросы ввода-вывода.
Поле HRESULT содержит код результата. Ниже приведены наиболее распространенные коды ошибок вместе с их возможными способами устранения.
Этот код ошибки означает, что исходного файла нет в хранилище.
Такой код ошибки может возникать по нескольким причинам:
- Файл удален другим приложением.
- В этом распространенном сценарий начинается выполнение запроса, в нем перечисляются файлы, и выполняется поиск файлов. Позже, во время выполнения запроса, файл удаляется. Например, его можно удалить с помощью Databricks, Spark или Фабрики данных Azure. Запрос завершается с ошибкой, так как файл не найден.
- Эта проблема также может возникать в формате Delta. Запрос может быть успешно выполнен при повторной попытке, так как использует новую версия таблицы, а удаленный файл больше не запрашивается.
- Кэшируется недопустимый план выполнения.
- В качестве временного решения проблемы выполните команду
DBCC FREEPROCCACHE. Если проблема осталась, отправьте запрос в службу поддержки.
- В качестве временного решения проблемы выполните команду
Неправильный синтаксис около «NOT»
Ошибка Incorrect syntax near 'NOT' указывает на наличие некоторых внешних таблиц со столбцами, содержащими ограничение NOT NULL в определении столбца.
- Обновите таблицу, чтобы удалить NOT NULL из определения столбца.
- Эта ошибка иногда также может возникать при работе с таблицами, созданными на основе инструкции CETAS. Если проблема осталась, можно попытаться удалить и повторно создать внешнюю таблицу.
Столбец секционирования возвращает значения NULL
Если запрос возвращает значения NULL, а не столбцы секционирования или не удается найти столбцы секционирования, то существует несколько вариантов решения проблемы:
- Если вы используете таблицы для запроса секционированного набора данных, помните, что таблицы не поддерживают секционирование. Замените таблицу секционированными представлениями.
- Если вы используете секционированные представления с функцией OPENROWSET, которая запрашивает секционированные файлы с помощью функции FILEPATH(), убедитесь, что вы правильно указали шаблон из подстановочных знаков в нужном месте и использовали правильный индекс для ссылки на подстановочный знак.
- Если вы запрашиваете файлы непосредственно в секционированной папке, обратите внимание, что столбцы секционирования не входят в состав столбцов файла. Значения секционирования указываются в пути к папке, а не в файлах. По этой причине файлы не содержат значения секционирования.
Не удалось вставить значение в пакет для столбца типа DATETIME2
Ошибка Inserting value to batch for column type DATETIME2 failed указывает, что бессерверный пул не может считывать значения даты из базовых файлов. Значение даты и времени, хранящееся в файле Parquet или Delta Lake, невозможно представить как столбец DATETIME2.
Проанализируйте минимальное значение в файле с помощью Spark и проверьте, есть ли даты до 0001-01-03. Если вы сохранили файлы с помощью версии Spark 2.4 (неподдерживаемой версии среды выполнения) или более поздней версии Spark, которая по-прежнему использует устаревший формат хранилища datetime, значения даты и времени, прежде чем записываться с помощью календаря Джулиана, который не соответствует пролептическому григорианскому календарю, используемому в бессерверных пулах SQL.
В некоторых версиях Spark может существовать разница в 2 дня между юлианским календарем, используемым для записи значений в Parquet (в некоторых версиях Spark), и григорианским пролептическим календарем, используемым в бессерверном пуле SQL. Это различие может привести к преобразованию в отрицательное значение даты, которое является недопустимым.
Попробуйте обновить эти значения с помощью Spark, так как в SQL они считаются недопустимыми значениями даты. В следующем примере показано, как обновить значения, которые выходят за пределы диапазона дат SQL, на NULL в Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Это изменение удаляет значения, которые не могут быть представлены. Другие значения даты могут быть загружены правильно, но представлены неправильно, так как по-прежнему существует разница между юлианским календарем и григорианским пролептическим календарем. При использовании Spark 3.0 или более ранних версий могут появиться непредвиденные сдвиги даты даже для дат, предшествующих 1900-01-01.
Рассмотрите возможность миграции в Spark 3.1 или более поздней версии и переключения на пролептический григорианский календарь. Последние версии Spark по умолчанию используют пролептический григорианский календарь, который соответствует календарю в бессерверном пуле SQL. Вам необходимо повторно загрузить устаревшие данные в более поздней версии Spark и использовать следующий параметр для корректировки дат:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Ошибка запроса из-за изменения топологии или сбоя контейнера вычислений
Эта ошибка может означать, что произошла внутренняя ошибка в бессерверном пуле SQL. Отправьте запрос в службу поддержки со всеми необходимыми сведениями, которые помогут группе поддержки Azure изучить проблему.
Опишите все, что может быть необычным по сравнению с обычной рабочей нагрузкой. Например, возможно, было большое количество параллельных запросов или особая рабочая нагрузка или запрос запустились перед появлением этой ошибки.
Время ожидания расширения wild карта
Как описано в разделе "Папки запросов" и нескольких файлов, бессерверный пул SQL поддерживает чтение нескольких файлов и папок с помощью wild карта. Максимально допустимое число подстановочных знаков для каждого запроса — 10. Вы должны знать, что эта функциональность приходится на стоимость. Для бессерверного пула требуется время для перечисления всех файлов, которые могут соответствовать диким карта. Это приводит к задержке, и эта задержка может увеличиться, если количество файлов, которые вы пытаетесь запросить, высокий. В этом случае можно столкнуться со следующей ошибкой:
"Wildcard expansion timed out after X seconds."
Существует несколько шагов по устранению рисков, которые можно сделать, чтобы избежать этого:
- Применение рекомендаций, описанных в разделе "Рекомендации по бессерверному пулу SQL".
- Попробуйте уменьшить количество файлов, которые вы пытаетесь запросить, за счет сжатия файлов в более крупные. Попробуйте сохранить размер файла выше 100 МБ.
- Убедитесь, что фильтры по столбцам секционирования используются везде, где это возможно.
- Если используется разностный формат файла, используйте функцию оптимизации записи в Spark. Это может повысить производительность запросов, уменьшая объем данных, которые необходимо считывать и обрабатывать. Использование оптимизации записи описано в разделе "Использование оптимизации записи в Apache Spark".
- Чтобы избежать некоторых диких элементов верхнего уровня карта путем эффективной жесткой кодировки неявных фильтров по столбцам секционирования используют динамический SQL.
Отсутствующий столбец при использовании автоматического вывода схемы
Вы можете легко запрашивать файлы, не зная или указывая схему, не указывая предложение WITH. В этом случае имена столбцов и типы данных будут выводиться из файлов. Имейте в виду, что при одновременном чтении количества файлов схема будет выводиться из первой файловой службы из хранилища. Это может означать, что некоторые из ожидаемых столбцов опущены, все потому, что файл, используемый службой для определения схемы, не содержал этих столбцов. Чтобы явно указать схему, используйте предложение OPENROWSET WITH. Если указать схему (используя внешнюю таблицу или предложение OPENROWSET WITH), будет использоваться режим lax пути по умолчанию. Это означает, что столбцы, которые не существуют в некоторых файлах, будут возвращены как NULLs (для строк из этих файлов). Чтобы понять, как используется режим пути, проверка приведенную ниже документацию и пример.
Настройка
Бессерверные пулы SQL позволяют использовать T-SQL для настройки объектов базы данных. Ниже приведены некоторые ограничения:
- Невозможно создавать объекты в базах данных
masterиlakehouseили Spark. - Для создания учетных данных необходимо иметь главный ключ.
- У вас должно быть разрешение на ссылку на данные, используемые в объектах.
Невозможно создать базу данных
Если вы получите ошибку CREATE DATABASE failed. User database limit has been already reached., вы создали максимальное количество баз данных, поддерживаемых в одной рабочей области. Дополнительные сведения см. в статье Ограничения.
- Если необходимо разделить объекты, используйте схемы в базах данных.
- Если нужно просто сослаться на хранилище Azure Data Lake, создайте базы данных lakehouse или базы данных Spark, которые будут синхронизироваться в бессерверном пуле SQL.
Не удалось создать или изменить таблицу, так как минимальный размер строки превышает максимальный допустимый размер строки таблицы размером 8060 байт
Любая таблица может иметь до 8 КБ размер каждой строки (не включая данные off-row VARCHAR(MAX)/VARBINARY(MAX). Если создать таблицу, в которой общий размер ячеек в строке превышает 8060 байт, вы получите следующую ошибку:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Эта ошибка также может произойти в базе данных Lake, если вы создаете таблицу Spark с размерами столбцов, превышающими 8060 байт, и бессерверный пул SQL не может создать таблицу, которая ссылается на данные таблицы Spark.
В качестве устранения рисков избегайте использования таких типов фиксированного размера, как CHAR(N) и заменяйте их типами переменных или VARCHAR(N) уменьшайте размер в CHAR(N). См. ограничения группы строк 8 КБ в SQL Server.
Создайте главный ключ в базе данных или откройте его в сеансе до выполнения этой операции
Если запрос завершается ошибкой с сообщением Please create a master key in the database or open the master key in the session before performing this operation.об ошибке, это означает, что у вашей пользовательской базы данных нет доступа к главному ключу в данный момент.
Вероятно, вы только что создали новую пользовательскую базу данных и пока не создали главный ключ.
Чтобы устранить эту проблему, создайте главный ключ с помощью следующего запроса:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Примечание.
Замените 'strongpasswordhere' другим секретом.
Инструкция CREATE не поддерживается в базе данных master
Если запрос завершается сбоем с сообщением Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.об ошибке, это означает, что master база данных в бессерверном пуле SQL не поддерживает создание:
- Внешние таблицы.
- Внешние источники данных.
- Учетные данные для базы данных.
- Форматы внешних файлов.
Решение:
Создание пользовательской базы данных:
CREATE DATABASE <DATABASE_NAME>Выполните инструкцию CREATE в контексте <DATABASE_NAME>, работа которого ранее завершилась сбоем для базы данных
master.Ниже приведен пример создания формата внешнего файла:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Не удается создать имя входа или пользователя Microsoft Entra
Если при попытке создать имя входа Или пользователя Microsoft Entra в базе данных возникает ошибка, проверка имя входа, используемое для подключения к базе данных. Имя входа, пытающееся создать нового пользователя Microsoft Entra, должно иметь разрешение на доступ к домену Microsoft Entra и проверка, если пользователь существует. Обратите внимание на следующее:
- Имена входа SQL не имеют этого разрешения, поэтому при использовании проверки подлинности SQL вы всегда получите эту ошибку.
- Если вы используете имя входа Microsoft Entra для создания новых имен входа, проверка, чтобы узнать, есть ли у вас разрешение на доступ к домену Microsoft Entra.
Azure Cosmos DB
Бессерверные пулы SQL позволяют запрашивать аналитическое хранилище Azure Cosmos DB с помощью функции OPENROWSET. Убедитесь, что контейнер Azure Cosmos DB содержит аналитическое хранилище. Убедитесь, что учетная запись, база данных и имя контейнера указаны правильно. Кроме того, убедитесь, что ключ учетной записи Azure Cosmos DB является допустимым. Дополнительные сведения см. в разделе Необходимые условия.
Не удается запросить базу данных Azure Cosmos с помощью функции OPENROWSET
Если вы не можете подключиться к своей учетной записи Azure Cosmos DB, ознакомьтесь с предварительными требованиями. В следующей таблице перечислены возможные ошибки и действия по устранению неполадок.
| Ошибка | Основная причина |
|---|---|
| Синтаксические ошибки: – Неправильный синтаксис рядом с OPENROWSET.- ... не является распознанным поставщиком BULK OPENROWSET.– Неправильный синтаксис рядом с .... |
Возможные первопричины: – В качестве первого параметра не используется Azure Cosmos DB. – В третьем параметре используется строковый литерал вместо идентификатора. – Третий параметр (имя контейнера) не указан. |
| Произошла ошибка в строке подключения Azure Cosmos DB. | – Не указана учетная запись, база данных или ключ. – В строке подключения существует нераспознанный параметр. – В конце строки подключения поставлена точка с запятой ( ;). |
| Не удалось распознать путь к Azure Cosmos DB с ошибкой «Неправильное имя учетной записи» или «Неправильное имя базы данных» | Указанное имя учетной записи, имя базы данных или контейнера не удается найти, либо аналитическое хранилище не включено для указанной коллекции. |
| Не удалось распознать путь к Azure Cosmos DB с ошибкой «Неправильное значение секрета» или «Секрет пустой или имеет значение NULL» | Ключ учетной записи недействителен или отсутствует. |
При чтении строковых типов Azure Cosmos DB возвращается предупреждение о параметрах сортировки UTF-8
Если параметры сортировки столбцов в OPENROWSET имеют кодировку не UTF-8, то бессерверный пул SQL будет выдавать предупреждение во время компиляции. Параметры сортировки по умолчанию для всех OPENROWSET функций, выполняемых в текущей базе данных, можно легко изменить с помощью инструкции T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Параметры сортировки Latin1_General_100_BIN2_UTF8 обеспечивают максимальную производительность при фильтрации данных с использованием предикатов строк.
Отсутствующие строки в аналитическом хранилище Azure Cosmos DB
Функция OPENROWSET может не возвращать некоторые элементы из Azure Cosmos DB. Обратите внимание на следующее:
- Существует задержка синхронизации между транзакционным и аналитическим хранилищем. Документ, помещенный в транзакционное хранилище Azure Cosmos DB, может появиться в аналитическом хранилище через 2–3 минуты.
- Документ может нарушать некоторые ограничения схемы.
Запрос возвращает для некоторых элементов Azure Cosmos DB значения NULL
Azure Synapse SQL возвратит NULL вместо значений, которые можно увидеть в хранилище транзакций, в следующих случаях:
- Существует задержка синхронизации между транзакционным и аналитическим хранилищем. Значение, введенное в транзакционное хранилище Azure Cosmos DB, может появиться в аналитическом хранилище через 2–3 минуты.
- Возможно, неправильное имя столбца или выражение пути в предложении WITH. Имя столбца (или выражение пути после типа столбца) в предложении WITH должно соответствовать имени свойства в коллекции Azure Cosmos DB. Сравнение производится с учетом регистра. Например,
productCodeиProductCodeсчитаются разными свойствами. Убедитесь, что имена столбцов точно соответствуют именам свойств Azure Cosmos DB. - Свойство не может быть перемещено в аналитическое хранилище, так как оно нарушает некоторые ограничения схемы, например превышение 1000 свойств или 127 уровней вложенности.
- При использовании четко определенного представления схемы значение в транзакционном хранилище может иметь неверный тип. Четко определенная схема блокирует типы для каждого свойства, выполняя выборку документов. Любое значение, добавленное в транзакционное хранилище, которое не соответствует типу, рассматривается как неверное и не переносится в аналитическое хранилище.
- Если вы используете представление схемы с полной точностью, убедитесь, что после имени свойства добавляется суффикс типа, например
$.price.int64. Если значение для указанного пути не отображается, возможно, оно хранится по другому пути типа, например$.price.float64. Дополнительные сведения см. в статье Запрос коллекций Azure Cosmos DB в схеме полной точности.
Столбец несовместим с типом внешних данных
Ошибка Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. возвращается, если указанный тип столбца в предложении WITH не соответствует типу в контейнере Azure Cosmos DB. Попробуйте изменить тип столбца, как описано в разделе Сопоставления типов Azure Cosmos DB и SQL, или используйте тип VARCHAR.
Устранение ошибки "Сбой разрешения пути Azure Cosmos DB с ошибкой"
Если вы получите ошибку Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. проверка, чтобы узнать, использовали ли вы частные конечные точки в Azure Cosmos DB. Чтобы бессерверный пул SQL мог обращаться к аналитическому хранилищу с частной конечной точкой, необходимо настроить частные конечные точки для аналитического хранилища Azure Cosmos DB.
Проблемы с производительностью Azure Cosmos DB
При возникновении непредвиденных проблем с производительностью воспользуйтесь рекомендациями, в т. ч. приведенными ниже:
- Убедитесь, что клиентское приложение, бессерверный пул и аналитическое хранилище Azure Cosmos DB находятся одном регионе.
- Убедитесь, что используете предложение WITH с оптимальными типами данных.
- При фильтрации данных с использованием предикатов строк убедитесь, что применяются параметры сортировки Latin1_General_100_BIN2_UTF8.
- Если у вас есть повторяющиеся запросы, которые можно кэшировать, попробуйте использовать CETAS для сохранения результатов запроса в Azure Data Lake Storage.
Delta Lake
Существуют некоторые ограничения, которые могут появиться в поддержке Delta Lake в бессерверных пулах SQL:
- Убедитесь, что вы ссылаетесь на корневую папку Delta Lake в функции OPENROWSET или в расположении внешней таблицы.
- Корневая папка должна иметь вложенную папку с именем
_delta_log. Запрос завершается ошибкой, если отсутствует папку_delta_log. Если эта папка не отображается, то вы ссылаетесь на обычные файлы Parquet, которые необходимо преобразовать в Delta Lake с помощью пулов Apache Spark. - Не указывайте подстановочные знаки для описания схемы секционирования. Запрос Delta Lake автоматически определит секции Delta Lake.
- Корневая папка должна иметь вложенную папку с именем
- Таблицы Delta Lake, созданные в пулах Apache Spark, автоматически доступны в бессерверном пуле SQL, но схема не обновляется (ограничение общедоступной предварительной версии). При добавлении столбцов в таблицу Delta с помощью пула Spark изменения не будут отображаться в базе данных бессерверного пула SQL.
- Внешние таблицы не поддерживают секционирование. Выберите секционированные представления в папке Delta Lake, чтобы использовать устранение секций. Известные проблемы и способы их решения описаны далее в этой статье.
- Бессерверные пулы SQL не поддерживают запросы на переходы по времени. Используйте пулы Apache Spark в Azure Synapse Analytics для чтения исторических данных.
- Бессерверные пулы SQL не поддерживают обновление файлов Delta Lake. Для запроса последней версии Delta Lake можно использовать бессерверный пул SQL. Используйте пулы Apache Spark в Synapse Analytics для обновления Delta Lake.
- Результаты запроса невозможно сохранить в хранилище в формате Delta Lake с помощью команды CETAS. Команда CETAS поддерживает только форматы выходных данных Parquet и CSV.
- Бессерверные пулы SQL в Synapse Analytics совместимы с delta reader версии 1. Функции Delta, требующие чтения Delta с версией 2 или выше (например , сопоставление столбцов), не поддерживаются в бессерверных пулах SQL.
- Бессерверные пулы SQL в Synapse Analytics не поддерживают наборы данных с фильтром BLOOM. Бессерверный пул SQL будет игнорировать фильтры BLOOM.
- Поддержка Delta Lake недоступна в выделенных пулах SQL. Убедитесь, что для запроса файлов Delta Lake вы используете бессерверные пулы SQL.
- Дополнительные сведения о известных проблемах с бессерверными пулами SQL см. в известных проблемах Azure Synapse Analytics.
Переименование столбцов в таблице Delta не поддерживается
Бессерверный пул SQL не поддерживает запросы таблиц Delta Lake с переименованными столбцами. Бессерверный пул SQL не может считывать данные из переименованного столбца.
Значение столбца в таблице Delta равно NULL.
Если вы используете набор данных Delta, требующий разностного средства чтения версии 2 или более поздней, и использует функции, неподдерживаемые в версии 1 (например, переименование столбцов, удаление столбцов или сопоставление столбцов), значения в ссылочных столбцах могут не отображаться.
Неверный формат текста JSON
Эта ошибка означает, что бессерверный пул SQL не может читать журнал транзакций Delta Lake. Вероятно, появится следующая ошибка:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Убедитесь, что набор данных Delta Lake не поврежден. Убедитесь, что вам удается прочитать содержимое папки Delta Lake с помощью пула Apache Spark в Azure Synapse. Это позволит удостовериться, что файл _delta_log не поврежден.
Обходное решение
Попробуйте создать контрольную точку в наборе данных Delta Lake с использованием пула Apache Spark и повторно выполните запрос. Контрольная точка будет выполнять статистическую обработку файлов журнала транзакций JSON, и это может решить проблему.
Если набор данных допустимый, создайте запрос в службу поддержки и укажите дополнительные сведения:
- Не вносите никаких изменений, таких как добавление или удаление столбцов или оптимизация таблицы, так как эти операции могут повлиять на состояние файлов журнала транзакций Delta Lake.
- Скопируйте содержимое папки
_delta_logв новую пустую папку. Не копируйте файлы.parquet data. - Попробуйте прочитать содержимое, скопированное в новую папку, и убедитесь, что получаете ту же ошибку.
- Отправьте содержимое скопированного файла
_delta_logв службу поддержки Azure.
Теперь можно продолжать работу с папкой Delta Lake с помощью пула Spark. Можно передать скопированные данные в службу поддержки Майкрософт, если у вас имеются права на предоставление совместного доступа к этой информации. Команда Azure проанализирует содержимое файла delta_log и предоставит вам дополнительные сведения о возможных ошибках и обходных решениях.
Не удалось устранить разностные журналы
Следующая ошибка означает, что бессерверный пул SQL не может разрешить разностные журналы: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder.. Наиболее распространенной причиной является то, что размер файла last_checkpoint_file в _delta_log папке превышает 200 байт из-за поля checkpointSchema, добавленного в Spark 3.3.
Обойти эту ошибку можно двумя способами:
- Измените соответствующую конфигурацию в записной книжке Spark и создайте новую контрольную точку, чтобы она была повторно создана в
last_checkpoint_file. Если вы используете Azure Databricks, конфигурацию нужно изменить следующим образом:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Вернитесь на Spark 3.2.1.
В настоящее время наша команда разработчиков работает над реализацией полной поддержки Spark 3.3.
Разностная таблица, созданная в Spark, не отображается в бессерверном пуле
Примечание.
Репликация таблиц Delta, созданных в Spark, по-прежнему доступна в общедоступной предварительной версии.
Если вы создали таблицу Delta в Spark и не отображается в бессерверном пуле SQL, проверка следующее:
- Подождите некоторое время (обычно 30 секунд), так как таблицы Spark синхронизируются с задержкой.
- Если таблица не появилась в бессерверном пуле SQL через некоторое время, проверка схему таблицы Spark Delta. Таблицы Spark со сложными типами или типами, которые не поддерживаются бессерверными, недоступны. Попробуйте создать таблицу Spark Parquet с той же схемой в базе данных озера и проверка эта таблица появится в бессерверном пуле SQL.
- Проверьте папку Delta Lake для управляемого удостоверения рабочей области, на которую ссылается таблица. Бессерверный пул SQL использует управляемое удостоверение рабочей области для получения сведений о столбце таблицы из хранилища для создания таблицы.
База данных озера
Таблицы базы данных Lake, созданные с помощью конструктора Spark или Synapse, автоматически становятся доступными для запросов в бессерверном пуле SQL. Бессерверный пул SQL можно использовать для запроса таблиц Parquet, CSV и Delta Lake, созданных с помощью пула Spark, и добавления дополнительных схем, представлений, процедур, функций табличного значения и пользователей Microsoft Entra в db_datareader роли базы данных Lake. В этом разделе перечислены возможные проблемы.
Таблица, созданная в Spark, недоступна в бессерверном пуле
Созданные таблицы могут не сразу становиться доступными в бессерверном пуле SQL.
- Таблицы появляются в бессерверных пулах с некоторой задержкой. Может пройти 5–10 минут после создания таблицы в Spark, прежде чем вы увидите ее в бессерверном пуле SQL.
- В бессерверном пуле SQL доступны только таблицы, основанные на форматах Parquet, CSV и Delta. Другие типы таблиц здесь недоступны.
- Если таблица содержит столбцы с неподдерживаемыми типами, она будет недоступна в бессерверном пуле SQL.
- Доступ к таблицам Delta Lake в базах данных Lake находится в общедоступной предварительной версии. Проверьте другие проблемы, перечисленные в этом разделе или в разделе, посвященном Delta Lake.
Внешняя таблица, созданная в Spark, отображает непредвиденные результаты в бессерверном пуле
Это может произойти, что между исходной внешней таблицей Spark и реплика заданной внешней таблицей в бессерверном пуле может возникнуть несоответствие. Это может произойти, если файлы, используемые при создании внешних таблиц Spark, находятся без расширений. Чтобы получить правильные результаты, убедитесь, что все файлы имеют расширения, такие как PARQUET.
Операция недопустима для реплицируемой базы данных
Эта ошибка возвращается, если вы пытаетесь изменить базу данных Lake, создать внешние таблицы, внешние источники данных, учетные данные базы данных или другие объекты в базе данных Lake. Перечисленные объекты можно создавать только в базах данных SQL.
Базы данных Lake реплицируются из пула Apache Spark и управляются Apache Spark. Это означает, что вы не можете создавать объекты с помощью языка T-SQL, как в базах данных SQL.
В базах данных Azure Data Lake разрешены только следующие операции.
- Создание, удаление или изменение представлений, процедур и встроенных функций табличного значения (iTVF), если схема отлична от
dbo. - Создание и удаление пользователей базы данных из идентификатора Microsoft Entra.
- Добавление или удаление пользователей базы данных из схемы
db_datareader.
Другие операции не допускаются в базах данных Azure Data Lake.
Примечание.
Если вы создаете представление, процедуру или функцию в схеме dbo (или если вы не указали схему, поскольку по умолчанию обычно используется схема dbo), вы получите такое сообщение об ошибке.
Таблицы Delta в базах данных Lake недоступны в бессерверном пуле SQL
Убедитесь, что используемое управляемое удостоверение рабочей области имеет доступ на чтение в хранилище ADLS, которая содержит папку Delta. Бессерверный пул SQL считывает схему таблицы Delta Lake из журналов Delta, размещенных в ADLS, и использует управляемое удостоверение рабочей области для доступа к журналам транзакций Delta.
Попробуйте настроить источник данных в некоторых База данных SQL, ссылающихся на хранилище Azure Data Lake с помощью учетных данных управляемого удостоверения, и попробуйте создать внешнюю таблицу на вершине источника данных с помощью управляемого удостоверения, чтобы убедиться, что таблица с управляемым удостоверением может получить доступ к хранилищу.
Разностные таблицы в базах данных Lake имеют разные схемы в пулах Spark и бессерверных пулах
Бессерверные пулы SQL позволяют получить доступ к таблицам Parquet, CSV и Delta, созданным в базе данных Lake с помощью конструктора Spark или Synapse. Доступ к таблицам Delta по-прежнему находится на этапе общедоступной предварительной версии, и в настоящее время бессерверный пул синхронизирует таблицу Delta со Spark при ее создании. Однако если позже добавить столбцы с помощью инструкции ALTER TABLE в Spark, схема не будет обновлена.
Это ограничение общедоступной предварительной версии. Чтобы устранить эту проблему, удалите и повторно создайте таблицу Delta в Spark (если это возможно) вместо изменения таблиц.
Производительность
Бессерверный пул SQL назначает ресурсы запросам в зависимости от размера набора данных и сложности запроса. Вы не можете изменить или ограничить ресурсы, предоставляемые для запросов. В некоторых случаях могут возникать непредвиденное замедление обработки запросов, и нужно найти первопричины этого.
Длительность запроса слишком велика
При наличии у вас запросов длительностью выполнения больше чем 30 мин, это указывает на то, что результаты клиенту возвращаются медленно. Бессерверный SQL пул имеет 30-минутное ограничение для выполнения. Увеличилось время, затрачиваемое на потоковую передачу результатов. Попробуйте следующие обходные пути.
- Если вы используете Synapse Studio, попробуйте воспроизвести проблемы с помощью другого приложения, например SQL Server Management Studio или Azure Data Studio.
- Если запрос выполняется медленно при использовании SQL Server Management Studio, Azure Data Studio, Power BI или другого приложения, проверьте наличие проблем с сетевым подключением и соответствующие рекомендации.
- Поместите запрос в команду CETAS и оцените длительность запроса. Команда CETAS сохранит результаты в Azure Data Lake Storage, и не будет зависеть от клиентского подключения. Если команда CETAS завершается быстрее исходного запроса, проверьте пропускную способность сети между клиентом и бессерверным пулом SQL.
Запрос выполняется медленно при использовании Synapse Studio
Если вы используете Synapse Studio, попробуйте использовать клиент настольного компьютера, например SQL Server Management Studio или Azure Data Studio. Synapse Studio — это веб-клиент, который подключается к бессерверному пулу SQL по протоколу HTTP, как правило, более медленному, чем собственные подключения SQL, используемые в SQL Server Management Studio или Azure Data Studio.
Запрос выполняется слишком медленно при использовании приложения
Если запросы выполняются медленно:
- Убедитесь, что клиентские приложения размещены в конечной точке бессерверного пула SQL. Выполнение запроса в регионе может вызвать дополнительную задержку и медленную потоковую передачу результирующего набора.
- Убедитесь в отсутствии проблем с сетевым подключением, которое может вызвать медленную потоковую передачу результирующего набора
- Убедитесь, что клиентское приложение имеет достаточно ресурсов (например, не нагружает ЦП на 100 %).
- Убедитесь, что учетная запись хранения или аналитическое хранилище Azure Cosmos DB находится в том же регионе, что и конечная точка бессерверного пула SQL.
Ознакомьтесь с рекомендациями по размещению ресурсов.
Высокие вариации в длительности запросов
Если при выполнении одного и того же запроса наблюдаются изменения в длительности выполнения запроса, у этого может быть несколько причин:
- Проверьте, является ли это первым выполнением запроса. При первом выполнении запроса собираются статистические данные, необходимые для создания плана. Сбор статистики осуществляется путем просмотра базовых файлов, и это может увеличить длительность запроса. В Synapse Studio в списке запросов SQL вы увидите запросы «создания глобальной статистики», которые выполняются перед вашим запросом.
- Срок действия статистики может истекать через некоторое время. Периодически производительность может снижаться, так как бессерверный пул должен сканировать и повторно создавать статистику. Можно заметить другие запросы «создания глобальной статистики» в списке запросов SQL, которые выполняются перед вашим запросом.
- Проверьте наличие рабочей нагрузки, которая выполняется в той же конечной точке при выполнении запроса с большей длительностью. Конечная точка бессерверного SQL будет равномерно распределять ресурсы по всем запросам, выполняемым параллельно, и запрос может быть отложен.
Связи
Бессерверный пул SQL позволяет подключаться с помощью протокола TDS и использовать язык T-SQL для запроса данных. Большинство инструментов, которые подключаются к SQL серверу или базе данных Azure SQL, также могут подключаться к бессерверному пулу SQL.
Выполняется прогрев пула SQL
После длительного периода бездействия бессерверный SQL пул будет отключен. Активация будет выполняться автоматически при первом следующем действии, например при первой попытке подключения. Процесс активации может занять немного больше времени, чем один интервал попытки подключения, поэтому отображается сообщение об ошибке. Данная проблема должна исчезнуть после повторной попытки подключения.
Если клиенты поддерживают такую функцию, рекомендуется использовать ключевые слова строки подключения ConnectionRetryCount и ConnectRetryInterval для управления поведением повторного подключения.
Если сообщение об ошибке продолжает появляться, отправьте запрос в службу поддержки через портал Azure.
Невозможно подключиться из Synapse Studio
Не удается подключиться к пулу Azure Synapse из инструмента
Некоторые инструменты могут не иметь явного параметра для подключения к бессерверному пулу SQL Azure Synapse. Используйте параметр, который использовался бы для подключения к серверу SQL Server или базе данных SQL. Диалоговое окно подключения необязательно должно называться «Synapse», так как бессерверный пул SQL использует тот же протокол, что и сервер SQL Server или база данных SQL.
Даже если инструмент позволяет вводить только имя логического сервера, предварительно определяет домен database.windows.net, укажите имя рабочей области Azure Synapse, а затем — суффикс -ondemand и домен database.windows.net.
Безопасность
Убедитесь, что у пользователя имеются разрешения на доступ к базам данных, разрешения на выполнение команд и разрешения на доступ к Azure Data Lake или хранилищу Azure Cosmos DB.
Невозможен доступ к учетной записи Azure Cosmos DB
Для доступа к аналитическому хранилищу необходимо использовать ключ Azure Cosmos DB только для чтения, поэтому убедитесь, что срок его действия не истек или он не был создан повторно.
Если появляется сообщение об ошибке «Не удалось распознать путь к Azure Cosmos DB», убедитесь, что вы настроили брандмауэр.
Не удается получить доступ к базе данных lakehouse или Spark
Если пользователь не может получить доступ к базе данных lakehouse или Spark, возможно, у него отсутствует разрешение на доступ к базе данных и ее чтение. Пользователь с разрешением CONTROL SERVER должен иметь полный доступ ко всем базам данных. В качестве частичного решения вы можете попытаться использовать CONNECT ANY DATABASE и SELECT ALL USER SECURABLES.
SQL-пользователь не может получить доступ к таблицам Dataverse
Таблицы dataverse получают доступ к хранилищу с помощью удостоверения Microsoft Entra вызывающего средства. SQL-пользователь с высоким уровнем разрешений может попытаться выбрать данные из таблицы, но таблица не сможет получить доступ к данным Dataverse. Этот сценарий не поддерживается.
Сбои входа субъекта-службы Microsoft Entra при создании назначения ролей SPI
Если вы хотите создать назначение ролей для идентификатора субъекта-службы (SPI) или приложения Microsoft Entra с помощью другого SPI или вы уже создали его, и вы не войдите в систему, вероятно, вы получите следующую ошибку: Login error: Login failed for user '<token-identified principal>'.
Для субъектов-служб необходимо создать данные для входа с идентификатором приложения в качестве идентификатора безопасности (SID), а не с идентификатором объекта. Существует известное ограничение для субъектов-служб, которое не позволяет службе Azure Synapse получать идентификатор приложения из Microsoft Graph при создании назначения ролей для другого SPI или приложения.
Решение 1
Перейдите на портал Azure>Synapse Studio>Управление>Управление доступом и вручную добавьте администратора Synapse или администратора Synapse SQL для нужного субъекта-службы.
Решение 2
Необходимо вручную создать правильное имя входа с помощью кода SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Решение 3
Кроме того, можно настроить администратора Azure Synapse субъекта-службы с помощью PowerShell. У вас должен быть установлен AZ.Synapse.
Решение заключается в использовании командлета New-AzSynapseRoleAssignment с -ObjectId "parameter". В этом поле параметра укажите идентификатор приложения вместо идентификатора объекта с помощью учетных данных субъекта-службы администратора рабочей области Azure.
Сценарий PowerShell.
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Проверка
Подключение на бессерверную конечную точку SQL и убедитесь, что внешний вход с идентификатором безопасности (app_id_to_add_as_adminв предыдущем примере) создается:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Или попробуйте войти в бессерверную конечную точку SQL с помощью приложения администрирования set.
Ограничения
Существуют некоторые общие системные ограничения, которые могут повлиять на вашу рабочую нагрузку:
| Свойство | Ограничение |
|---|---|
| Максимальное число рабочих областей Azure Synapse на одну подписку | См. ограничения. |
| Максимальное количество баз данных на один бессерверный пул | 100 (не включая базы данных, синхронизированные из пула Apache Spark). |
| Максимальное число баз данных, синхронизируемых из пула Apache Spark | Не ограничено. |
| Максимальное количество объектов баз данных на одну базу | Суммарное число всех объектов в базе данных не может превышать 2 147 483 647. См. Ограничения в ядре СУБД SQL Server. |
| Максимальная длина идентификатора (в символах) | 128. См. Ограничения в ядре СУБД SQL Server. |
| Максимальная длительность запроса | 30 мин. |
| Максимальный размер результирующего набора | До 400 ГБ (в совокупности для всех одновременно выполняемых запросов). |
| Максимальный параллелизм | Без ограничений; зависит от сложности запросов и объема проверяемых данных. Один бессерверный пул SQL может одновременно обрабатывать 1000 активных сеансов, которые выполняют простые запросы. Но этот показатель падает, если запросы усложняются или сканируют больший объем данных. В таком случае рекомендуется сократить параллелизм и выполнить запросы в течение более длительного периода времени (если это возможно). |
| Максимальный размер имени внешней таблицы | 100 символов. |
Не удается создать базу данных в бессерверном пуле SQL
Бессерверные пулы SQL имеют ограничения, и вы не можете создавать более 100 баз данных на рабочую область. Если необходимо разделить объекты и изолировать их, используйте схемы.
Если вы получите сообщение об ошибке CREATE DATABASE failed. User database limit has been already reached , которое вы создали максимальное количество баз данных, поддерживаемых в одной рабочей области.
Для изоляции данных для разных арендаторов не нужно использовать отдельные базы данных. Все данные хранятся во внешних озерах данных и Azure Cosmos DB. Метаданные, такие как таблицы, представления, определения функций, могут быть успешно изолированы с помощью схем. Изоляция на основе схем также используется в Spark, где базы данных и схемы имеют аналогичную концепцию.
Следующие шаги
- Рекомендации по использованию бессерверного пула SQL в Azure Synapse Analytics
- Часто задаваемые вопросы о Azure Synapse Analytics
- Хранение результатов запросов в хранилище с помощью бессерверного пула SQL в Azure Synapse Analytics
- Устранение неполадок с Synapse Studio
- Устранение неполадок медленного запроса в выделенном пуле SQL