Azure Cosmos DB Async Java SDK v2에 대한 성능 팁
적용 대상: ![]() NoSQL
NoSQL
Important
Azure Cosmos DB의 최신 Java SDK가 아닙니다! Azure Cosmos DB Java SDK v4로 프로젝트를 업그레이드한 다음, Azure Cosmos DB Java SDK v4 성능 팁 가이드를 참조하세요. 업그레이드하려면 Azure Cosmos DB Java SDK v4로 마이그레이션 가이드 및 Reactor 및 RxJava 가이드의 지침을 따르세요.
이 문서의 성능 팁은 Azure Cosmos DB Async Java SDK v2에만 해당됩니다. 자세한 내용은 Azure Cosmos DB Async Java SDK v2 릴리스 정보, Maven 리포지토리 및 Azure Cosmos DB Async Java SDK v2 문제 해결 가이드를 참조하세요.
Important
2024년 8월 31일에 Azure Cosmos DB Async Java SDK v2.x가 사용 중지됩니다. SDK 및 SDK를 사용하는 모든 애플리케이션은 계속 작동합니다. Azure Cosmos DB는 이 SDK에 대한 추가 유지 관리 및 지원을 제공을 중단합니다. 위의 지침에 따라 Azure Cosmos DB Java SDK v4로 마이그레이션하는 것이 좋습니다.
Azure Cosmos DB는 보장된 대기 시간 및 처리량으로 매끄럽게 크기가 조정되는 빠르고 유연한 분산 데이터베이스입니다. Azure Cosmos DB를 사용하여 데이터베이스의 크기를 조정하기 위해 주요 아키텍처를 변경하거나 복잡한 코드를 작성할 필요는 없습니다. 규모를 확장 및 축소하는 것은 단일 API 호출 또는 SDK 메서드 호출을 수행하는 것만큼 쉽습니다. 그러나 네트워크 호출을 통해 Azure Cosmos DB에 액세스하기 때문에 Azure Cosmos DB Async Java SDK v2를 사용할 때 최대 성능을 얻기 위해 클라이언트 쪽에서 최적화를 지정할 수 있습니다.
"내 데이터베이스 성능을 향상시키는 방법"을 물으면 다음 옵션을 고려합니다.
네트워킹
연결 모드: 직접 모드 사용
클라이언트에서 Azure Cosmos DB에 연결하는 방법은 특히 클라이언트 쪽 대기 시간 측면에서 성능에 중요한 영향을 미칩니다. ConnectionMode는 클라이언트 ConnectionPolicy를 구성하는 데 사용할 수 있는 핵심 구성 설정입니다. Azure Cosmos DB Async Java SDK v2의 경우 사용 가능한 두 ConnectionModes는 다음과 같습니다.
게이트웨이 모드는 모든 SDK 플랫폼에서 지원되며 기본적으로 구성되는 옵션입니다. 엄격한 방화벽으로 제한된 회사 네트워크 내에서 애플리케이션을 실행하는 경우, 표준 HTTPS 포트 및 단일 엔드포인트를 사용하기 때문에 게이트웨이 모드가 최상의 선택입니다. 그러나 게이트웨이 모드의 경우 성능 유지를 위해 Azure Cosmos DB에서 데이터를 읽거나 쓸 때마다 네트워크 홉이 추가됩니다. 이 때문에 직접 모드는 네트워크 홉이 적기 때문에 더 나은 성능을 제공합니다.
ConnectionMode는 ConnectionPolicy 매개 변수로 DocumentClient 인스턴스를 생성하는 동안 구성됩니다.
Async Java SDK V2(Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
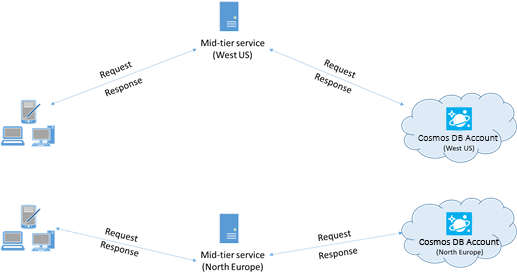
성능을 위해 동일한 Azure 지역에 클라이언트 배치
가능한 경우 Azure Cosmos DB를 호출하는 모든 애플리케이션을 Azure Cosmos DB 데이터베이스와 동일한 지역에 배치합니다. 대략적으로 비교한다면, 동일한 지역 내의 Azure Cosmos DB 호출은 1-2밀리초 내에 완료되지만 미국 서부와 동부 해안 간의 대기 시간은 50밀리초보다 큽니다. 클라이언트에서 Azure 데이터 센터 경계로 요청이 전달되는 경로에 따라 이러한 요청 간 대기 시간은 달라질 수 있습니다. 호출하는 애플리케이션이 프로비전된 Azure Cosmos DB 엔드포인트와 동일한 Azure 지역 내에 있도록 하면 가능한 최저 대기 시간을 얻을 수 있습니다. 사용 가능한 영역 목록은 Azure 지역을 참조하세요.
SDK 사용
최신 SDK 설치
Azure Cosmos DB SDK는 최상의 성능을 제공하기 위해 지속적으로 향상됩니다. Azure Cosmos DB Async Java SDK v2 릴리스 정보 페이지를 참조하여 최신 SDK를 확인하고 향상된 기능을 검토하세요.
애플리케이션 수명 동안 싱글톤 Azure Cosmos DB 클라이언트 사용
각 AsyncDocumentClient 인스턴스는 스레드로부터 안전하고 효율적인 연결 관리와 주소 캐싱을 수행합니다. AsyncDocumentClient에 의해 연결을 효율적으로 관리하고 성능을 개선하려면 애플리케이션 수명 동안 AppDomain당 AsyncDocumentClient의 단일 인스턴스를 사용하는 것이 좋습니다.
ConnectionPolicy 튜닝
기본적으로 Azure Cosmos DB Async Java SDK v2를 사용하는 경우 직접 모드 Azure Cosmos DB 요청이 TCP를 통해 수행됩니다. 내부적으로 SDK는 특별한 직접 모드 아키텍처를 사용하여 네트워크 리소스를 동적으로 관리하고 최고의 성능을 얻습니다.
Azure Cosmos DB Async Java SDK v2에서 직접 모드는 대부분의 워크로드에서 데이터베이스 성능을 향상시키는 가장 좋은 방법입니다.
- 직접 모드 개요
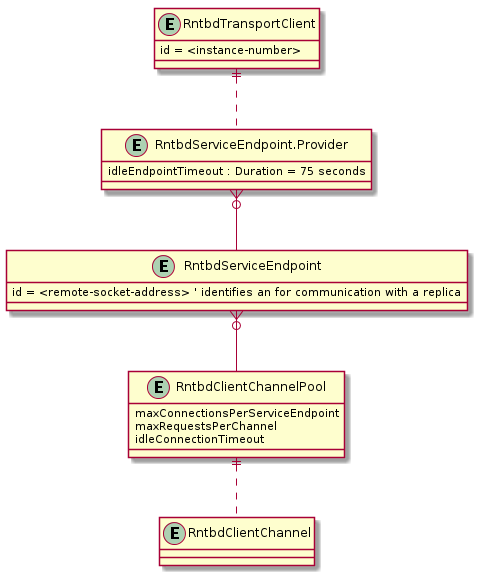
직접 모드에서 사용되는 클라이언트 쪽 아키텍처를 사용하면 네트워크 사용률을 예측할 수 있고 Azure Cosmos DB 복제본에 멀티플렉싱 방식으로 액세스할 수 있습니다. 위의 다이어그램에서는 직접 모드에서 Azure Cosmos DB 백 엔드를 통해 클라이언트 요청을 복제본으로 라우팅하는 방법을 보여 줍니다. 직접 모드 아키텍처는 DB 복제본당 최대 10개의 채널을 클라이언트 쪽에 할당합니다. 채널은 요청 깊이가 30개인 요청 버퍼 뒤에 오는 TCP 연결입니다. 복제본에 속하는 채널은 복제본의 서비스 엔드포인트에서 필요에 따라 동적으로 할당됩니다. 사용자가 직접 모드에서 요청을 실행하면 TransportClient에서 파티션 키에 따라 요청을 적절한 서비스 엔드포인트로 라우팅합니다. 요청 큐는 서비스 엔드포인트 앞에 요청을 버퍼링합니다.
직접 모드에 대한 ConnectionPolicy 구성 옵션
첫 번째 단계로 아래 추천 구성 설정을 사용합니다. 이 특정 항목에서 문제가 발생하는 경우 Azure Cosmos DB 팀에 문의하세요.
Azure Cosmos DB를 참조 데이터베이스로 사용하는 경우, 즉 데이터베이스가 많은 지점 읽기 작업 및 적은 쓰기 작업에 사용되는 경우 idleEndpointTimeout을 0(시간 제한 없음)으로 설정하는 것이 허용될 수 있습니다.
구성 옵션 기본값 bufferPageSize 8192 connectionTimeout "PT1M" idleChannelTimeout "PT0S" idleEndpointTimeout "PT1M10S" maxBufferCapacity 8388608 maxChannelsPerEndpoint 10 maxRequestsPerChannel 30 receiveHangDetectionTime "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" requestTimerResolution "PT0.5S" sendHangDetectionTime "PT10S" shutdownTimeout "PT15S"
직접 모드를 위한 프로그래밍 팁
SDK 이슈를 해결하기 위한 기준으로 Azure Cosmos DB Async Java SDK v2 문제 해결 문서를 검토합니다.
직접 모드를 사용하는 경우의 몇 가지 중요한 프로그래밍 팁:
효율적인 TCP 데이터 전송을 위해 애플리케이션에서 다중 스레딩 사용 - 요청을 수행한 후 애플리케이션은 다른 스레드에서 데이터를 받도록 구독해야 합니다. 이렇게 하지 않으면 의도하지 않은 "반이중" 작업이 강제로 수행되고 이전 요청의 응답을 기다리느라 후속 요청이 차단됩니다.
전용 스레드에서 컴퓨팅 집약적 워크로드 수행 - 이전 팁과 비슷한 이유로, 복잡한 데이터 처리와 같은 작업을 별도의 스레드에 배치하는 것이 가장 좋습니다. 다른 데이터 저장소에서 데이터를 끌어오는 요청(예: 스레드에서 Azure Cosmos DB 및 Spark 데이터 저장소를 동시에 활용하는 경우)은 대기 시간이 증가하므로 다른 데이터 저장소의 응답을 기다리는 추가 스레드를 생성하는 것이 좋습니다.
- Azure Cosmos DB Async Java SDK v2의 기본 네트워크 IO는 Netty에서 관리됩니다. Netty IO 스레드를 차단하는 코딩 패턴을 방지하기 위한 팁을 참조하세요.
데이터 모델링 - Azure Cosmos DB SLA는 문서 크기를 1KB 미만이라고 가정합니다. 더 작은 문서 크기에 적합하게 데이터 모델 및 프로그래밍을 최적화하면 일반적으로 대기 시간이 감소합니다. 1KB보다 큰 문서를 저장하고 검색해야 하는 경우 문서를 Azure Blob Storage의 데이터에 연결하는 것이 좋습니다.
분할된 컬렉션에 대한 병렬 쿼리 튜닝
Azure Cosmos DB Async Java SDK v2는 분할된 컬렉션을 병렬로 쿼리할 수 있는 병렬 쿼리를 지원합니다. 자세한 내용은 SDK 사용과 관련된 코드 샘플을 참조하세요. 병렬 쿼리는 해당 직렬 대응을 통해 쿼리 대기 시간 및 처리량을 개선하기 위해 설계되었습니다.
setMaxDegreeOfParallelism 튜닝:
병렬 쿼리는 여러 파티션을 병렬로 쿼리하여 작동합니다. 그러나 개별 분할된 컬렉션의 데이터는 쿼리와 관련하여 순차적으로 가져오기 됩니다. 따라서 setMaxDegreeOfParallelism을 사용하여 파티션 수를 설정하면 다른 모든 시스템 조건을 동일하게 유지하는 동시에 가장 성능이 뛰어난 쿼리를 달성할 수 있는 가능성을 극대화합니다. 파티션 수를 모르는 경우 setMaxDegreeOfParallelism을 사용하여 더 높은 값을 설정할 수 있습니다. 그러면 시스템에서 최소값(사용자가 제공한 입력인 파티션 수)을 최대 병렬 처리 수준으로 선택합니다.
데이터가 쿼리와 관련하여 모든 파티션에 균등하게 분산되어 있는 경우 병렬 쿼리가 최고의 성능을 발휘한다는 것이 중요합니다. 쿼리에서 반환된 전체 또는 대부분 데이터가 몇 개의 파티션(최악의 경우 하나의 파티션)에 집중되는 것처럼 분할된 컬렉션이 분할되는 경우 해당 파티션으로 인해 쿼리의 성능에는 장애가 발생합니다.
setMaxBufferedItemCount 튜닝:
병렬 쿼리는 클라이언트에서 현재 결과 일괄 처리를 처리하는 동안 결과를 프리페치하도록 설계되었습니다. 프리페치는 쿼리의 전체 대기 시간 개선 사항에 도움이 됩니다. setMaxBufferedItemCount는 프리페치된 결과의 수를 제한합니다. setMaxBufferedItemCount를 설정하면 반환된 결과의 예상 수(또는 더 높은 수)로 설정하면 쿼리가 프리페치의 최대 이점을 얻을 수 있습니다.
프리페치는 MaxDegreeOfParallelism에 관계없이 동일한 방식으로 작동하고 여기에는 모든 파티션의 데이터에 대한 단일 버퍼가 있습니다.
getRetryAfterInMilliseconds 간격으로 백오프 구현
성능 테스트 중에는 작은 비율의 요청이 제한될 때까지 로드를 늘려야 합니다. 제한될 경우 클라이언트 애플리케이션은 서버에서 지정한 재시도 간격 제한을 백오프해야 합니다. 백오프를 통해 재시도 간 기간을 최소화할 수 있습니다.
클라이언트 워크로드 규모 확장
높은 처리량 수준에서 테스트하는 경우(>50,000 RU/s) 머신의 CPU 또는 네트워크 사용률이 최대화되므로 클라이언트 애플리케이션은 병목 상태가 될 수 있습니다. 이 시점에 도달하면 여러 서버에 걸쳐 클라이언트 애플리케이션을 확장하여 Azure Cosmos DB 계정을 계속 추가할 수 있습니다.
이름 기반 주소 지정 사용
링크를 생성하는 데 사용된 모든 리소스의 ResourceId를 검색하지 않도록 링크 형식이
dbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>인 SelfLinks(_self) 대신 링크 형식이dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId인 이름 기반 주소 지정을 사용합니다. 또한 이러한 리소스는 (동일한 이름을 사용하여) 다시 생성되므로 이를 캐싱하는 것이 별 도움이 되지 않을 수도 있습니다.성능 향상을 위해 쿼리/읽기 피드에 맞게 페이지 크기 조정
읽기 피드 기능을 사용하여 대량의 문서 읽기를 수행하거나(예: readDocuments) SQL 쿼리를 실행하면 결과 집합이 너무 큰 경우 결과가 분할되어 반환됩니다. 기본적으로, 100개의 항목 또는 1MB 단위(둘 중 먼저 도달하는 단위)로 결과가 반환됩니다.
모든 적용 가능한 결과를 검색하는 데 필요한 네트워크 왕복 횟수를 줄이려면 x-ms-max-item-count 요청 헤더를 사용하는 페이지 크기를 최대 1000으로 늘릴 수 있습니다. 사용자 인터페이스 또는 애플리케이션 API가 한 번에 10개의 결과만 반환하는 것처럼 몇 가지 결과만 표시해야 하는 경우, 읽기 및 쿼리에 사용되는 처리량을 줄이기 위해 페이지 크기를 10으로 줄일 수도 있습니다.
setMaxItemCount 메서드를 사용하여 페이지 크기를 설정할 수도 있습니다.
적절한 스케줄러 사용(이벤트 루프 IO Netty 스레드 도용 방지)
Azure Cosmos DB Async Java SDK v2는 비블록킹 IO에 netty를 사용합니다. SDK는 IO 작업을 실행하기 위해 고정된 수의 IO netty 이벤트 루프 스레드(시스템에 있는 CPU 코어 수만큼)를 사용합니다. API에서 반환된 Observable은 공유 IO 이벤트 루프 netty 스레드 중 하나에서 결과를 도출합니다. 따라서 이 공유 IO 이벤트 루프 netty 스레드를 차단하지 않는 것이 중요합니다. IO 이벤트 루프 netty 스레드에서 CPU 집약적인 작업 또는 차단 작업을 수행하면 교착 상태가 발생하거나 SDK 처리량이 크게 저하될 수 있습니다.
예를 들어 다음 코드는 이벤트 루프 IO netty 스레드에서 CPU 집약적인 작업을 실행합니다.
Async Java SDK V2(Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });결과에 대해 CPU 집약적인 작업을 수행하려는 경우 결과를 수신한 후에는 이벤트 루프 IO netty 스레드에서 이를 수행하지 않아야 합니다. 대신 사용자의 스케줄러를 제공하여 작업 실행을 위해 사용자의 스레드를 제공할 수 있습니다.
Async Java SDK V2(Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });작업 유형에 따라 작업에 적절한 RxJava Scheduler를 사용해야 합니다. 여기
Schedulers를 읽으세요.자세한 내용은 Azure Cosmos DB Async Java SDK v2에 대한 GitHub 페이지를 확인하세요.
Netty 로깅 사용 안 함
Netty 라이브러리 로깅은 대화량이 많으므로 추가 CPU 비용을 피하려면 꺼두어야 합니다(구성에서 로그를 억제하는 것으로 충분하지 않음). 디버깅 모드가 아니라면 netty의 로깅을 모두 해제합니다. 따라서 log4j를 사용하여 netty에서
org.apache.log4j.Category.callAppenders()에 의한 추가 CPU 비용이 발생하지 않도록 하려면 코드베이스에 다음 행을 추가합니다.org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);OS 파일 열기 리소스 제한
일부 Linux 시스템(Red Hat 등)에는 열린 파일 수와 총 연결 수에 대한 상한이 있습니다. 현재 한도를 보려면 다음을 실행합니다.
ulimit -a열린 파일(nofile)의 수는 OS에 의해 구성된 연결 풀 크기와 다른 열린 파일을 위한 공간이 충분할 만큼 커야 합니다. 연결 풀 크기를 더 크게 수정할 수 있습니다.
limits.conf 파일을 엽니다.
vim /etc/security/limits.conf다음 줄을 추가/수정합니다.
* - nofile 100000
인덱싱 정책
쓰기 속도를 높이기 위해 인덱싱에서 사용하지 않는 경로 제외
Azure Cosmos DB의 인덱싱 정책을 통해 인덱싱 경로(setIncludedPaths 및 setExcludedPaths)를 사용하여 인덱싱에 포함하거나 제외할 문서 경로를 지정할 수 있습니다. 인덱싱 비용이 인덱싱된 고유 경로 수와 직접 관련이 있기 때문에, 인덱싱 경로를 사용하면 사전에 알려진 쿼리 패턴의 시나리오에 대해 쓰기 성능을 향상시키고 인덱스 스토리지를 낮출 수 있습니다. 예를 들어, 다음 코드는 "*" 와일드카드를 사용하여 인덱싱에서 문서의 전체 섹션(하위 트리라고도 함)을 제외하는 방법을 보여 줍니다.
Async Java SDK V2(Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);자세한 내용은 Azure Cosmos DB 인덱싱 정책을 참조하세요.
처리량
낮은 요청 단위/초 사용량 측정 및 튜닝
Azure Cosmos DB는 관계형 쿼리와 계층형 쿼리 등 다양한 데이터베이스 작업에 데이터베이스 컬렉션 내부의 문서에서 적용되는 UDF, 저장 프로시저 및 트리거를 제공합니다. 이러한 작업 각각과 관련된 비용은 작업을 완료하는 데 필요한 CPU, IO 및 메모리에 따라 달라집니다. 하드웨어 리소스를 고려하고 관리하는 대신 다양한 데이터베이스 작업을 수행하고 애플리케이션 요청을 처리하는 데 필요한 리소스의 단일 측정값으로 RU(요청 단위)를 고려할 수 있습니다.
처리량은 각 컨테이너에 설정된 요청 단위 수에 따라 프로비전됩니다. 요청 단위 소비는 초당 비율로 평가됩니다. 해당 컨테이너에 프로비전된 요청 단위 비율을 초과하는 애플리케이션은 비율이 컨테이너에 프로비전된 수준 아래로 떨어질 때까지 제한됩니다. 애플리케이션에 더 높은 수준의 처리량이 필요한 경우 추가 요청 단위를 프로비전하여 처리량을 늘릴 수 있습니다.
쿼리의 복잡성은 작업에 사용되는 요청 단위의 양에 영향을 줍니다. 조건자의 수, 조건자의 특성, UDF 수 및 원본 데이터 집합의 크기는 모두 쿼리 작업의 비용에 영향을 줍니다.
모든 작업(만들기, 업데이트 또는 삭제)에 대한 오버헤드를 측정하려면 x-ms-request-charge 헤더를 검사하여 이 작업에 사용된 요청 단위 수를 측정합니다. 동일한 RequestCharge 속성은 ResourceResponse<T> 또는 FeedResponse<T>에서 확인할 수도 있습니다.
Async Java SDK V2(Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();이 헤더에서 반환된 요청 비용은 프로비전된 처리량의 일부입니다. 예를 들어 RU 2,000개를 프로비전했고 앞의 쿼리에서 1,000개의 1KB 문서를 반환하는 경우 작업 비용은 1,000입니다. 따라서 1초 이내에 서버는 후속 요청의 속도를 제한하기 전에 이러한 두 가지 요청만 인식합니다. 자세한 내용은 요청 단위와 요청 단위 계산기를 참조하세요.
너무 큰 속도 제한/요청 속도 처리
클라이언트가 계정에 대해 예약된 처리량을 초과하려 할 때도 서버의 성능이 저하되거나 예약된 수준 이상의 처리량이 사용되지 않습니다. 서버에서 RequestRateTooLarge(HTTP 상태 코드 429)를 사용하여 선제적으로 요청을 종료하고, 사용자가 요청을 다시 시도할 수 있을 때까지 기다려야 하는 시간을 밀리초 단위로 표시하는 x-ms-retry-after-ms 헤더를 반환합니다.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDK는 이 응답을 암시적으로 모두 catch하고, server-specified retry-after 헤더를 준수하고 요청을 다시 시도합니다. 동시에 여러 클라이언트가 계정에 액세스하지만 않으면 다음 재시도가 성공할 것입니다.
하나 이상의 클라이언트가 누적적으로 요청 속도를 계속 초과하여 작동하는 경우,클라이언트에 의해 현재 내부적으로 9로 설정된 기본 재시도 횟수는 충분하지 않을 수 있습니다. 이 경우 클라이언트는 애플리케이션에 상태 코드가 429인 DocumentClientException을 throw합니다. 기본 재시도 횟수는 ConnectionPolicy 인스턴스에서 setRetryOptions를 설정하여 변경할 수 있습니다. 기본적으로, 요청이 계속 요청 속도 이상으로 작동하는 경우 상태 코드가 429인 DocumentClientException은 누적 대기 시간 30초 후에 반환됩니다. 현재 재시도 횟수가 최대 재시도 횟수보다 작은 경우에도 이러한 현상이 발생하기 때문에 기본값인 9 또는 사용자 정의 값으로 두세요.
자동화된 재시도 동작은 대부분의 애플리케이션에 대한 복원력 및 유용성을 개선하는 데 도움이 되는 반면, 성능 벤치마크 수행 시 특히 대기 시간을 측정할 때 방해가 될 수 있습니다. 실험이 서버 제한에 도달하고 클라이언트 SDK를 자동으로 재시도하는 경우 클라이언트 관찰 대기 시간이 급증합니다. 성능 실험 중 대기 시간 급증을 방지하려면, 각 작업에 의해 반환된 비용을 측정하고 요청이 예약된 요청 속도 이하로 작동하고 있는지 확인합니다. 자세한 내용은 요청 단위를 참조하세요.
처리량을 높이기 위해 문서 크기를 줄이도록 설계
주어진 작업의 요청 비용(요청 처리 비용)은 문서 크기와 직접 관련이 있습니다. 큰 문서에서 작업하는 경우 작은 문서 작업에 비해 비용이 많이 듭니다.
다음 단계
확장성 및 고성능을 위한 애플리케이션 설계 방법에 대한 자세한 내용은 Azure Cosmos DB의 분할 및 크기 조정을 참조하세요.