Azure Cosmos DB Python SDK에 대한 성능 팁
적용 대상: ![]() NoSQL
NoSQL
Important
이 문서의 성능 팁은 Azure Cosmos DB Python SDK에만 적용됩니다. 자세한 내용은 Azure Cosmos DB Python SDK 추가 정보 릴리스 정보, 패키지(PyPI), 패키지(Conda) 및 문제 해결 가이드를 참조하세요.
Azure Cosmos DB는 보장된 대기 시간 및 처리량으로 매끄럽게 크기가 조정되는 빠르고 유연한 분산 데이터베이스입니다. Azure Cosmos DB를 사용하여 데이터베이스의 크기를 조정하기 위해 주요 아키텍처를 변경하거나 복잡한 코드를 작성할 필요는 없습니다. 규모를 확장 및 축소하는 것은 단일 API 호출 또는 SDK 메서드 호출을 수행하는 것만큼 쉽습니다. 그러나 네트워크 호출을 통해 Azure Cosmos DB에 액세스하므로 Azure Cosmos DB Python SDK를 사용할 때 최대 성능을 얻기 위해 클라이언트 쪽에서 최적화를 수행할 수 있습니다.
"내 데이터베이스 성능을 향상시키는 방법"을 물으면 다음 옵션을 고려합니다.
네트워킹
- 성능을 위해 동일한 Azure 지역에 클라이언트 배치
가능한 경우 Azure Cosmos DB를 호출하는 모든 애플리케이션을 Azure Cosmos DB 데이터베이스와 동일한 지역에 배치합니다. 대략적으로 비교한다면, 동일한 지역 내의 Azure Cosmos DB 호출은 1-2밀리초 내에 완료되지만 미국 서부와 동부 해안 간의 대기 시간은 50밀리초보다 큽니다. 클라이언트에서 Azure 데이터 센터 경계로 요청이 전달되는 경로에 따라 이러한 요청 간 대기 시간은 달라질 수 있습니다. 호출하는 애플리케이션이 프로비전된 Azure Cosmos DB 엔드포인트와 동일한 Azure 지역 내에 있도록 하면 가능한 최저 대기 시간을 얻을 수 있습니다. 사용 가능한 영역 목록은 Azure 지역을 참조하세요.
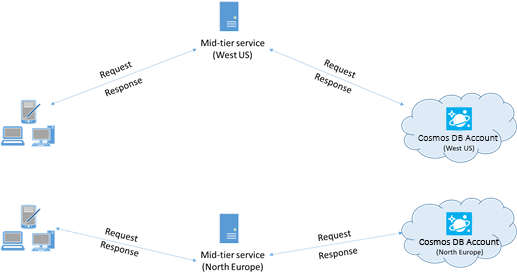
다중 지역 Azure Cosmos DB 계정과 상호 작용하는 앱은 요청이 배치된 지역으로 전달되도록 기본 설정 위치를 구성해야 합니다.
가속화된 네트워킹을 사용하도록 설정하여 대기 시간 및 CPU 지터 줄이기
성능을 최대화하려면(대기 시간 및 CPU 지터 줄이기) 지침에 따라 Windows(지침을 보려면 선택) 또는 Linux(지침을 보려면 선택) Azure VM에서 가속화된 네트워킹을 사용하도록 설정하는 것이 좋습니다.
가속화된 네트워킹을 사용하지 않으면 Azure VM과 다른 Azure 리소스 간에 전송되는 IO가 VM과 해당 네트워크 카드 사이에 위치한 호스트 및 가상 스위치를 통해 불필요하게 라우팅될 수 있습니다. 데이터 경로에 호스트 및 가상 스위치를 인라인으로 두면 통신 채널의 대기 시간과 jitter가 증가할 뿐만 아니라 VM의 CPU 사이클도 도용합니다. 가속화된 네트워킹을 사용하면 VM에서 중간자 없이 NIC와 직접 상호 작용합니다. 호스트와 가상 스위치에서 처리되었던 네트워크 정책 세부 정보는 이제 NIC의 하드웨어에서 처리되며, 호스트와 가상 스위치가 무시됩니다. 일반적으로 가속화된 네트워킹을 사용하도록 설정하는 경우 대기 시간이 줄어들고 처리량이 향상될 뿐만 아니라 더 일관된 대기 시간이 유지되며 CPU 사용률이 줄어들 수도 있습니다.
제한 사항: 가속화된 네트워킹은 VM OS에서 지원되어야 하며, VM이 중지 및 할당 취소된 경우에만 사용하도록 설정할 수 있습니다. VM은 Azure Resource Manager를 사용하여 배포할 수 없습니다. App Service 가속화된 네트워크를 사용할 수 없습니다.
자세한 내용은 Windows 및 Linux 지침을 참조하세요.
SDK 사용
- 최신 SDK 설치
Azure Cosmos DB SDK는 최상의 성능을 제공하기 위해 지속적으로 향상됩니다. 최신 SDK를 확인하고 개선 사항을 검토하려면 Azure Cosmos DB SDK 릴리스 정보를 참조하세요.
- 애플리케이션 수명 동안 싱글톤 Azure Cosmos DB 클라이언트 사용
각 Azure Cosmos DB 클라이언트 인스턴스는 스레드로부터 안전하며 연결 관리와 주소 캐싱을 효율적으로 수행합니다. Azure Cosmos DB 클라이언트에서 연결을 효율적으로 관리하고 성능을 향상시키려면 애플리케이션 수명 동안 단일 Azure Cosmos DB 클라이언트 인스턴스를 사용하는 것이 좋습니다.
- 시간 제한 및 다시 시도 구성 조정
시간 제한 구성 및 다시 시도 정책은 애플리케이션 요구 사항에 따라 사용자 지정할 수 있습니다. 사용자 지정할 수 있는 전체 구성 목록을 보려면 시간 제한 및 다시 시도 구성 문서를 참조하세요.
- 애플리케이션에 필요한 가장 낮은 일관성 수준 사용
CosmosClient를 만들 때 클라이언트 만들 때 아무것도 지정되지 않은 경우 계정 수준 일관성이 사용됩니다. 일관성 수준에 대한 자세한 내용은 일관성 수준 문서를 참조하세요.
- 클라이언트 워크로드 규모 확장
높은 처리량 수준에서 테스트하는 경우 컴퓨터에서 CPU 또는 네트워크 사용률 제한을 초과하여 클라이언트 애플리케이션에서 병목 상태가 발생할 수 있습니다. 이 시점에 도달하면 여러 서버에 걸쳐 클라이언트 애플리케이션을 확장하여 Azure Cosmos DB 계정을 계속 추가할 수 있습니다.
대기 시간을 짧게 유지하려면 지정된 서버에서 CPU 사용률이 50%를 초과하지 않는 것이 좋습니다.
- OS 파일 열기 리소스 제한
일부 Linux 시스템(Red Hat 등)에는 열린 파일 수와 총 연결 수에 대한 상한이 있습니다. 현재 한도를 보려면 다음을 실행합니다.
ulimit -a
열린 파일(nofile)의 수는 OS에 의해 구성된 연결 풀 크기와 다른 열린 파일을 위한 공간이 충분할 만큼 커야 합니다. 연결 풀 크기를 더 크게 수정할 수 있습니다.
limits.conf 파일을 엽니다.
vim /etc/security/limits.conf
다음 줄을 추가/수정합니다.
* - nofile 100000
쿼리 작업
쿼리 작업은 쿼리에 대한 성능 팁을 참조하세요.
인덱싱 정책
- 쓰기 속도를 높이기 위해 인덱싱에서 사용하지 않는 경로 제외
Azure Cosmos DB의 인덱싱 정책을 통해 인덱싱 경로(setIncludedPaths 및 setExcludedPaths)를 활용하여 인덱싱에 포함하거나 제외할 문서 경로를 지정할 수 있습니다. 인덱싱 비용이 인덱싱된 고유 경로 수와 직접 관련이 있기 때문에, 인덱싱 경로를 사용하면 사전에 알려진 쿼리 패턴의 시나리오에 대해 쓰기 성능을 향상시키고 인덱스 스토리지를 낮출 수 있습니다. 예를 들어 다음 코드에서는 "*" 와일드카드를 사용하여 인덱싱에서 문서의 전체 섹션(하위 트리라고도 함)을 포함 및 제외하는 방법을 보여 줍니다.
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
자세한 내용은 Azure Cosmos DB 인덱싱 정책을 참조하세요.
처리량
- 낮은 요청 단위/초 사용량 측정 및 튜닝
Azure Cosmos DB는 관계형 쿼리와 계층형 쿼리 등 다양한 데이터베이스 작업에 데이터베이스 컬렉션 내부의 문서에서 적용되는 UDF, 저장 프로시저 및 트리거를 제공합니다. 이러한 작업 각각과 관련된 비용은 작업을 완료하는 데 필요한 CPU, IO 및 메모리에 따라 달라집니다. 하드웨어 리소스를 고려하고 관리하는 대신 다양한 데이터베이스 작업을 수행하고 애플리케이션 요청을 처리하는 데 필요한 리소스의 단일 측정값으로 RU(요청 단위)를 고려할 수 있습니다.
처리량은 각 컨테이너에 설정된 요청 단위 수에 따라 프로비전됩니다. 요청 단위 소비는 초당 비율로 평가됩니다. 해당 컨테이너에 프로비전된 요청 단위 비율을 초과하는 애플리케이션은 비율이 컨테이너에 프로비전된 수준 아래로 떨어질 때까지 제한됩니다. 애플리케이션에 더 높은 수준의 처리량이 필요한 경우 추가 요청 단위를 프로비전하여 처리량을 늘릴 수 있습니다.
쿼리의 복잡성은 작업에 사용되는 요청 단위의 양에 영향을 줍니다. 조건자의 수, 조건자의 특성, UDF 수 및 원본 데이터 집합의 크기는 모두 쿼리 작업의 비용에 영향을 줍니다.
모든 작업(만들기, 업데이트 또는 삭제)에 대한 오버헤드를 측정하려면 x-ms-request-charge 헤더를 검사하여 이 작업에 사용된 요청 단위 수를 측정합니다.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
이 헤더에서 반환된 요청 비용은 프로비전된 처리량의 일부입니다. 예를 들어 RU 2000개를 프로비전했고 앞의 쿼리에서 1000개의 1KB 문서를 반환하는 경우 작업 비용은 1000입니다. 따라서 1초 이내에 서버는 후속 요청의 속도를 제한하기 전에 이러한 두 가지 요청만 인식합니다. 자세한 내용은 요청 단위와 요청 단위 계산기를 참조하세요.
- 너무 큰 속도 제한/요청 속도 처리
클라이언트가 계정에 대해 예약된 처리량을 초과하려 할 때도 서버의 성능이 저하되거나 예약된 수준 이상의 처리량이 사용되지 않습니다. 서버에서 RequestRateTooLarge(HTTP 상태 코드 429)를 사용하여 선제적으로 요청을 종료하고, 사용자가 요청을 다시 시도할 수 있을 때까지 기다려야 하는 시간을 밀리초 단위로 표시하는 x-ms-retry-after-ms 헤더를 반환합니다.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK는 이 응답을 암시적으로 모두 catch하고, server-specified retry-after 헤더를 준수하고 요청을 다시 시도합니다. 동시에 여러 클라이언트가 계정에 액세스하지만 않으면 다음 재시도가 성공할 것입니다.
하나 이상의 클라이언트에서 요청 속도가 점증적으로 일관되게 초과하여 작동하는 경우 클라이언트에서 현재 내부적으로 9로 설정한 기본 재시도 횟수가 충분하지 않을 수 있습니다. 이 경우 클라이언트에서 상태 코드가 429인 CosmosHttpResponseError를 애플리케이션에 throw합니다. 기본 다시 시도 횟수는 retry_total 구성을 클라이언트에 전달하여 변경할 수 있습니다. 기본적으로 요청이 요청 속도 이상으로 계속 작동하는 경우 누적 대기 시간 30초 후에 상태 코드가 429인 CosmosHttpResponseError가 반환됩니다. 현재 재시도 횟수가 최대 재시도 횟수보다 작은 경우에도 이러한 현상이 발생하기 때문에 기본값인 9 또는 사용자 정의 값으로 두세요.
자동화된 재시도 동작은 대부분의 애플리케이션에 대한 복원력 및 유용성을 개선하는 데 도움이 되는 반면, 성능 벤치마크 수행 시 특히 대기 시간을 측정할 때 방해가 될 수 있습니다. 실험이 서버 제한에 도달하고 클라이언트 SDK를 자동으로 재시도하는 경우 클라이언트 관찰 대기 시간이 급증합니다. 성능 실험 중 대기 시간 급증을 방지하려면, 각 작업에 의해 반환된 비용을 측정하고 요청이 예약된 요청 속도 이하로 작동하고 있는지 확인합니다. 자세한 내용은 요청 단위를 참조하세요.
- 처리량을 높이기 위해 문서 크기를 줄이도록 설계
주어진 작업의 요청 비용(요청 처리 비용)은 문서 크기와 직접 관련이 있습니다. 큰 문서에서 작업하는 경우 작은 문서 작업에 비해 비용이 많이 듭니다. 항목 크기가 최대 1KB이거나 비슷한 순서 또는 크기가 되도록 애플리케이션과 워크플로를 설계하는 것이 가장 좋습니다. 대기 시간이 중요한 애플리케이션의 경우 많은 항목을 사용하지 않도록 방지합니다. 다중 MB 크기의 문서는 애플리케이션 속도를 낮춥니다.
다음 단계
확장성 및 고성능을 위한 애플리케이션 설계 방법에 대한 자세한 내용은 Azure Cosmos DB의 분할 및 크기 조정을 참조하세요.
Azure Cosmos DB로 마이그레이션하기 위한 용량 계획을 수행하려고 하시나요? 용량 계획을 위해 기존 데이터베이스 클러스터에 대한 정보를 사용할 수 있습니다.
- 기존 데이터베이스 클러스터의 vCore 및 서버의 수만 알고 있는 경우 vCore 또는 vCPU를 사용하여 요청 단위 예측을 참조하세요
- 현재 데이터베이스 워크로드에 대한 일반적인 요청 비율을 알고 있는 경우 Azure Cosmos DB 용량 계획 도구를 사용하여 요청 단위 예측에 대해 읽어보세요.