Azure HDInsight 클러스터에서 Apache Hive 복제를 사용하는 방법
데이터베이스 및 웨어하우스의 컨텍스트에서 복제는 한 웨어하우스의 엔터티를 다른 웨어하우스에 복제하는 프로세스입니다. 중복은 전체 데이터베이스 또는 더 작은 수준(예: 테이블이나 파티션)에 적용할 수 있습니다. 목표는 기본 엔터티가 변경될 때마다 변경되는 복제본을 갖추는 것입니다. Apache Hive의 복제는 재해 복구에 중점을 두고 단방향 기본 복사 복제를 제공합니다. HDInsight 클러스터에서 Hive 복제를 사용하여 Azure Data Lake Storage Gen2에서 Hive 메타스토어 및 연결된 기본 데이터 레이크를 단방향으로 복제할 수 있습니다.
Hive 복제는 몇 년간 더 나은 기능을 제공하며 더 빠르고 리소스를 덜 사용하는 최신 버전으로 발전했습니다. 이 문서에서는 HDInsight 3.6 및 HDInsight 4.0 클러스터 유형에서 모두 지원되는 Hive 복제(Replv2)에 대해 설명합니다.
replv2의 장점
Hive ReplicationV2(Replv2라고도 함)는 Hive IMPORT-EXPORT를 사용한 Hive 복제의 첫 번째 버전과 비교해 볼 때 다음과 같은 이점이 있습니다.
- 이벤트 기반 증분 복제
- 지정 시간 복제
- 대역폭 요구 사항 감소
- 중간 복사본의 수 감소
- 복제 상태가 유지됨
- 제한된 복제
- 허브 및 스포크 모델 지원
- ACID 테이블 지원(HDInsight 4.0)
복제 단계
Hive 이벤트 기반 복제는 주 클러스터와 보조 클러스터 사이에 구성됩니다. 이 복제는 부트스트랩과 증분 실행의 두 가지 별도 단계로 구성됩니다.
부트스트래핑
부트스트랩은 주 데이터베이스의 기본 상태를 보조 데이터베이스로 복제하기 위해 한 번 실행됩니다. 필요한 경우 복제를 사용하도록 설정해야 하는 대상 데이터베이스에 테이블 하위 집합을 포함하도록 부트스트랩을 구성할 수 있습니다.
증분 실행
부트스트랩 후에는 증분 실행이 주 클러스터에서 자동으로 실행되고, 이러한 증분 실행 중에 생성된 이벤트가 보조 클러스터에서 다시 재생됩니다. 보조 클러스터가 주 클러스터를 따라잡으면 보조 클러스터는 주 클러스터의 이벤트와 일치하게 됩니다.
복제 명령
Hive는 이벤트 흐름을 오케스트레이션하는 REPL 명령 집합(DUMP, LOAD, STATUS)을 제공합니다. DUMP 명령은 주 클러스터에 있는 모든 DDL/DML 이벤트의 로컬 로그를 생성합니다. LOAD 명령은 추출된 복제 덤프 출력에 기록된 메타데이터와 데이터를 지연 복사하는 접근 방식으로, 대상 클러스터에서 실행됩니다. STATUS 명령은 대상 클러스터에서 실행되어 최근의 복제 로드가 성공적으로 복제된 최신 이벤트 ID를 제공합니다.
복제 원본 설정
복제를 시작하기 전에 복제할 데이터베이스가 복제 원본으로 설정되어 있는지 확인합니다. DESC DATABASE EXTENDED <db_name> 명령을 사용하여 repl.source.for 매개 변수가 정책 이름으로 설정되어 있는지 확인할 수 있습니다.
정책이 예약되어 있고 repl.source.for 매개 변수가 설정되지 않은 경우 먼저 ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>')를 사용하여 이 매개 변수를 설정해야 합니다.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
데이터 레이크에 메타데이터 덤프
REPL DUMP [database name]. => location / event_id 명령은 부트스트랩 단계에서 Azure Data Lake Storage Gen2에 관련 메타데이터를 덤프하는 데 사용됩니다. event_id는 관련 메타데이터가 Azure Data Lake Storage Gen2에 배치된 최소 이벤트를 지정합니다.
repl dump tpcds_orc;
예제 출력:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
대상 클러스터에 데이터 로드
REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } 명령은 복제의 부트스트랩 및 증분 단계에서 모두 대상 클러스터에 데이터를 로드하는 데 사용됩니다. [database name]은 대상 클러스터의 원본 또는 다른 이름과 같을 수 있습니다. [location]은 이전 REPL DUMP 명령의 출력에서 위치를 나타냅니다. 즉, 대상 클러스터가 원본 클러스터와 통신할 수 있어야 합니다. WITH 절은 주로 대상 클러스터를 다시 시작할 수 없도록 하기 위해 추가되며 복제를 허용합니다.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
마지막으로 복제된 이벤트 ID 출력
REPL STATUS [database name] 명령은 대상 클러스터에서 실행되고 마지막으로 복제된 event_id를 출력합니다. 또한 이 명령을 통해 사용자는 대상 클러스터가 복제된 상태를 알 수 있습니다. 이 명령의 출력을 사용하여 증분 복제 시 다음 REPL DUMP 명령을 구성할 수 있습니다.
repl status tpcds_orc;
예제 출력:
| last_repl_id |
|---|
| 2925 |
데이터 레이크에 관련 데이터 및 메타데이터 덤프
REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } 명령은 관련 메타데이터 및 데이터를 Azure Data Lake Storage 덤프하는 데 사용됩니다. 이 명령은 증분 단계에서 사용되며 원본 웨어하우스에서 실행됩니다. 증분 단계에서 FROM [event-id]가 필요하며, 대상 웨어하우스에서 REPL STATUS [database name] 명령을 실행하여 event-id 값을 파생할 수 있습니다.
repl dump tpcds_orc from 2925;
예제 출력:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
Hive 복제 프로세스
다음 단계는 Hive 복제 프로세스 중에 발생하는 순차적인 이벤트입니다.
복제할 테이블이 특정 정책의 복제 원본으로 설정되어 있는지 확인합니다.
REPL_DUMP명령은 데이터베이스 이름, 이벤트 ID 범위 및 Azure Data Lake Storage Gen2 스토리지 URL 같은 관련된 제약 조건이 있는 주 클러스터에 실행됩니다.시스템은 메타스토어에서 추적된 모든 이벤트의 덤프를 최신 이벤트의 덤프로 직렬화합니다. 이 덤프는
REPL_DUMP에서 지정한 URL의 기본 클러스터에 있는 Azure Data Lake Storage Gen2 스토리지 계정에 저장됩니다.주 클러스터는 복제 메타데이터를 주 클러스터의 Azure Data Lake Storage Gen2 스토리지에 유지합니다. 경로는 Ambari의 Hive 구성 UI에서 구성할 수 있습니다. 이 프로세스는 메타데이터가 저장되는 경로와 추적된 최신 DML/DDL 이벤트의 ID를 제공합니다.
REPL_LOAD명령은 보조 클러스터에서 실행됩니다. 명령은 3단계에서 구성된 경로를 가리킵니다.보조 클러스터는 3단계에서 만든 추적된 이벤트가 있는 메타데이터 파일을 읽습니다. 보조 클러스터는
REPL_DUMP에서 추적된 이벤트가 저장되는 기본 클러스터의 Azure Data Lake Storage Gen2 스토리지에 네트워크 연결이 있는지 확인합니다.보조 클러스터는 분산 복사(
DistCP) 컴퓨팅을 생성합니다.보조 클러스터는 주 클러스터의 스토리지에서 데이터를 복사합니다.
보조 클러스터의 메타스토어가 업데이트됩니다.
마지막으로 추적된 이벤트 ID는 기본 메타스토어에 저장됩니다.
증분 복제는 동일한 프로세스를 따르며, 입력으로 마지막에 복제된 이벤트 ID가 필요합니다. 이렇게 하면 마지막 복제 이벤트 이후 증분 복사본이 만들어집니다. 증분 복제는 일반적으로 필요한 RPO(복구 지점 목표)를 달성하기 위해 미리 결정된 빈도로 자동화됩니다.

복제 패턴
복제는 일반적으로 주 복제본과 보조 복제본 사이에서 단방향 방식으로 구성되며, 주 복제본은 읽기/쓰기 요청을 처리합니다. 보조 클러스터는 읽기 요청에만 적합합니다. 재해가 있는 경우 보조 데이터베이스에서 쓰기가 허용되지만, 역방향 복제를 주 복제본으로 다시 구성해야 합니다.
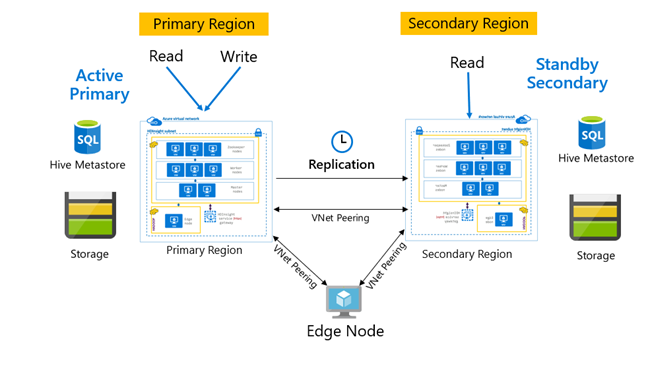
주 – 보조, 허브 및 스포크, 릴레이 등 Hive 복제에 적합한 많은 패턴이 있습니다.
HDInsight 활성 주 – 대기 보조는 일반적인 BCDR(비즈니스 연속성 및 재해 복구) 패턴이며, HiveReplicationV2는 VNet 피어링을 통해 지역적으로 분리된 HDInsight Hadoop 클러스터에서 이 패턴을 사용할 수 있습니다. 두 클러스터에 피어링된 공통 가상 머신을 사용하여 복제 자동화 스크립트를 호스트할 수 있습니다. 가능한 HDInsight BCDR 패턴에 대한 자세한 내용은 HDInsight 비즈니스 연속성 설명서를 참조하세요.
Enterprise Security Package가 있는 Hive 복제
Enterprise Security Package가 있는 HDInsight Hadoop 클러스터에서 Hive 복제를 계획하는 경우, Ranger 메타스토어 및 Microsoft Entra Domain Services의 복제 메커니즘을 고려해야 합니다.
Microsoft Entra Domain Services 복제본 세트 기능을 사용하여 여러 지역에 걸쳐 Microsoft Entra 테넌트당 둘 이상의 Microsoft Entra Domain Services 복제본 세트를 만듭니다. 각 개별 복제본 세트는 해당 지역의 HDInsight VNet과 피어링되어야 합니다. 이 구성에서는 구성, 사용자 ID 및 자격 증명, 그룹, 그룹 정책 개체, 컴퓨터 개체 및 기타 변경 내용을 포함한 Microsoft Entra Domain Services에 대한 변경 사항이 Microsoft Entra Domain Services 복제를 사용하여 관리되는 도메인의 모든 복제본 세트에 적용됩니다.
Ranger 정책은 Ranger Import-Export 기능을 사용하여 주기적으로 백업하고 주 정책에서 보조로 복제할 수 있습니다. 보조 클러스터에서 구현하려는 권한 부여 수준에 따라 Ranger 정책의 전체 또는 하위 집합을 복제하도록 선택할 수 있습니다.
샘플 코드
다음 코드 시퀀스에는 부트스트랩 및 증분 복제를 tpcds_orc라는 샘플 테이블에 구현하는 방법에 대한 예제가 나와 있습니다.
테이블을 복제 정책의 원본으로 설정합니다.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');주 클러스터에서 부트스트랩 덤프합니다.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');예제 출력:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 보조 클러스터에서 부트스트랩 로드합니다.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';보조 클러스터에서
REPL상태를 확인합니다.repl status tpcds_orc;last_repl_id 2925 주 클러스터에서 증분 덤프합니다.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');예제 출력:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 보조 클러스터에서 증분 로드합니다.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';보조 클러스터에서
REPL상태를 확인합니다.repl status tpcds_orc;last_repl_id 2960
다음 단계
이 문서에서 설명한 항목에 관해 자세히 알아보려면 다음을 참조하세요.