적용 대상:![]() Azure SQL Database
Azure SQL Database
이 문서에서는 Azure SQL Database의 리소스 관리에 대한 개요를 제공합니다. 리소스 제한에 도달할 때 발생하는 사항에 대한 정보를 제공하고 해당 한도를 적용하는 데 사용되는 리소스 거버넌스 메커니즘을 설명합니다.
단일 데이터베이스에 대한 가격 책정 계층당 특정 리소스 제한은 다음 중 하나를 참조하세요.
Elastic Pool 리소스 제한은 다음 중 하나를 참조하세요.
Azure Synapse Analytics에 대한 전용 SQL 풀의 한도는 다음 중 하나를 참조하세요.
하위 지역당 구독 vCore 제한
2024년 3월부터 구독에 다음과 같은 구독 및 하위 지역에 따른 vCore 제한이 있습니다.
| 구독 유형 | 기본 vCore 제한 |
|---|---|
| EA(기업 계약) | 2000 |
| 무료 평가판 | 10 |
| 신생 기업용 Microsoft | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| PAYG(종량제) | 백오십 |
다음을 고려하십시오.
- 이러한 제한은 신규 및 기존 구독에 적용할 수 있습니다.
- DTU 구매 모델로 프로비전된 데이터베이스와 Elastic Pool도 vCore 할당량에 대해 계산되며 그 반대의 경우도 마찬가지입니다. 사용된 각 vCore는 서버 수준 할당량에 사용된 100개의 DTU와 동일한 것으로 간주됩니다.
- 기본 제한에는 프로비전된 컴퓨팅 데이터베이스/탄력적 풀에 대해 구성된 vCore와 서버리스 데이터베이스에 대해 구성된 최대 vCore 모두 포함됩니다.
- 구독 사용-받기 REST API 호출을 사용하여 구독에 대한 현재 vCore 사용량을 확인할 수 있습니다.
- 기본값보다 높은 vCore 할당량을 요청하려면 Azure Portal에서 새 지원 요청을 제출합니다. 자세한 내용은 Azure SQL Database 및 SQL Managed Instance대한
요청 할당량 증가를 참조하세요.
논리 서버 제한
| 리소스 | 제한 |
|---|---|
| 논리 서버당 데이터베이스 | 5,000 |
| 한 지역에서 구독당 논리 서버의 기본 수 | 250 |
| 한 지역에서 구독당 논리 서버의 최대 수 | 250 |
| 논리 서버당 최대 탄력적 풀 | DTU 또는 vCore의 수로 제한됩니다. 예를 들어 각 풀에 DTU가 1000개인 경우 서버는 54개 풀을 지원할 수 있습니다. |
중요
데이터베이스 수가 논리 서버당 한도에 근접하면 다음이 발생할 수 있습니다.
-
master데이터베이스에 대해 쿼리를 실행할 때 대기 시간이 증가합니다. 여기에는sys.resource_stats같은 리소스 사용률 통계 보기도 포함됩니다. - 관리 작업을 수행하고 서버의 데이터베이스 열거와 관련된 포털 뷰 포인트를 렌더링할 때 대기 시간이 증가합니다.
리소스 제한에 도달하면 어떻게 되나요?
컴퓨팅 CPU
데이터베이스 컴퓨팅 CPU 사용률이 높아지면 쿼리 대기 시간이 길어지고 쿼리가 시간 초과할 수도 있습니다. 이와 같은 조건에서 쿼리는 서비스에 의해 큐에 대기하게 될 수 있으며 리소스가 사용 가능해지면 실행에 필요한 리소스를 제공받습니다.
높은 컴퓨팅 사용률이 관찰되는 경우 완화 옵션에는 다음이 포함됩니다.
- 데이터베이스 또는 탄력적 풀의 컴퓨팅 크기를 늘려 데이터베이스에 더 많은 컴퓨팅 리소스를 제공합니다. 단일 데이터베이스 리소스 확장 및 탄력적 풀 리소스 확장을 참조하세요.
- 쿼리를 최적화하여 쿼리당 CPU 리소스 사용률을 줄입니다. 자세한 내용은 쿼리 튜닝/힌트를 참조하세요.
스토리지
사용된 데이터 공간이 데이터베이스 수준 또는 탄력적 풀 수준에서 최대 데이터 크기 제한에 도달하면 데이터 크기를 증가시키는 삽입 및 업데이트가 실패하고 클라이언트는
프리미엄 및 중요 비즈니스용 서비스 계층에서 클라이언트는 단일 데이터베이스 또는 탄력적 풀에 대한 데이터, 트랜잭션 로그 및 tempdb에 의한 결합된 스토리지 사용이 최대 로컬 스토리지 크기를 초과하는 경우에도 오류 메시지를 받습니다. 자세한 내용은 스토리지 공간 거버넌스를 참조하세요.
높은 저장소 공간 사용률이 관찰되는 경우 완화 옵션에는 다음이 포함됩니다.
- 데이터베이스 또는 탄력적 풀의 최대 데이터 크기를 늘리거나 더 높은 최대 데이터 크기 제한으로 서비스 목표를 스케일 업합니다. 단일 데이터베이스 리소스 확장 및 탄력적 풀 리소스 확장을 참조하세요.
- 데이터베이스가 탄력적 풀에 속하는 경우 데이터베이스를 풀 외부로 이동하여 스토리지 공간이 다른 데이터베이스와 공유되지 않도록 할 수 있습니다.
- 데이터베이스를 축소하여 사용하지 않는 공간을 회수합니다. 자세한 내용은 데이터베이스파일 공간 관리를 참조하세요.
- 탄력적 풀에서 데이터베이스를 축소하면 풀의 다른 데이터베이스에 더 많은 스토리지가 제공됩니다.
- 높은 공간 사용률이 PVS(영구 버전 저장소) 크기의 스파이크 때문인지 확인합니다. PVS는 각 데이터베이스의 일부이며 가속 데이터베이스 복구구현하는 데 사용됩니다. 현재 PVS 크기를 확인하려면 가속 데이터베이스 복구문제 해결을 참조하세요. PVS 크기가 큰 일반적인 이유는 트랜잭션이 장시간(시) 열려 있어서 PVS의 이전 버전의 행을 정리하지 못했기 때문입니다.
- 많은 양의 저장소를 사용하는 프리미엄 및 중요 비즈니스용 서비스 계층의 데이터베이스 및 Elastic Pool의 경우 데이터베이스 또는 Elastic Pool에서 사용된 공간이 최대 데이터 크기 제한보다 낮은 경우에도 공간 부족 오류가 발생할 수 있습니다. 이는
tempdb또는 트랜잭션 로그 파일이 최대 로컬 저장소 제한에 대해 많은 양의 저장소를 사용하는 경우에 발생할 수 있습니다. 데이터베이스 또는 탄력적 풀을 장애 조치(failover)하여tempdb를 초기 더 작은 크기로 재설정하거나 트랜잭션 로그를 축소하여 로컬 스토리지 소비를 줄입니다.
세션, 작업자 및 요청
세션, 작업자 및 요청은 다음과 같이 정의됩니다.
- 세션은 데이터베이스 엔진에 연결된 프로세스를 나타냅니다.
- 요청은 쿼리 또는 일괄 처리의 논리적 표현입니다. 요청은 세션에 연결된 클라이언트에서 발급합니다. 시간이 지남에 따라 동일한 세션에서 여러 요청이 발급될 수 있습니다.
- 작업자 스레드(작업자 또는 스레드라고도 함)는 운영 체제 스레드의 논리적 표현입니다. 요청은 병렬 쿼리 실행 계획으로 실행될 때 많은 작업자가 있을 수 있고, 직렬(단일 스레드) 실행 계획으로 실행될 때 단일 작업자가 있을 수 있습니다. 작업자는 요청 외부의 활동도 지원해야 합니다. 예를 들어 작업자는 세션이 연결되는 동안 로그인 요청을 처리해야 합니다.
이러한 개념에 대한 자세한 내용은 스레드 및 작업 아키텍처 가이드참조하세요.
최대 작업자 수는 서비스 계층 및 컴퓨팅 크기에 따라 결정됩니다. 세션 또는 작업자 제한에 도달하면 새 요청이 거부되고 클라이언트에 오류 메시지가 표시됩니다. 연결 수는 애플리케이션에서 제어할 수 있지만, 동시 작업자 수는 예측하고 제어하기가 어렵습니다. 이는 최고 부하 기간에 특히 심하며 이때는 오랫동안 실행 중인 쿼리나 큰 차단 체인, 또는 과도한 쿼리 병렬화 때문에 데이터베이스 리소스 한도에 도달하고 작업자가 누적됩니다.
참고
Azure SQL Database의 초기 제품은 단일 스레드 쿼리만 지원했습니다. 당시 요청 수는 항상 작업자 수와 동일했습니다. Azure SQL 데이터베이스의 오류 메시지 10928에는 이전 버전과의 호환성을 위해 The request limit for the database is *N* and has been reached라는 문구가 포함되어 있습니다. 도달한 제한은 실제로 작업자 수입니다.
최대 병렬 처리 수준(MAXDOP) 설정이 0과 같거나 1보다 큰 경우 작업자 수가 요청 수보다 훨씬 많을 수 있으며 MAXDOP가 1과 같을 때보다 훨씬 더 빨리 제한에 도달할 수 있습니다.
- 리소스 거버넌스 오류에서 오류 10928에 대해 자세히 알아보세요.
- 오류 10928 및 10936에서 요청 제한 소진에 대해 자세히 알아봅니다.
다음을 통해 작업자 또는 세션 제한 접근 또는 도달을 완화할 수 있습니다.
- 데이터베이스 또는 탄력적 풀의 서비스 계층 또는 컴퓨팅 크기를 늘립니다. 단일 데이터베이스 리소스 확장 및 탄력적 풀 리소스 확장을 참조하세요.
- 작업자가 증가하는 원인이 계산 리소스 경합일 경우 리소스 사용률을 줄이도록 쿼리 최적화. 자세한 내용은 쿼리 튜닝/힌트를 참조하세요.
- 쿼리 워크로드를 최적화하여 쿼리 차단 발생 횟수와 기간을 줄입니다. 자세한 내용은 차단 문제 이해 및 해결을 참조하세요.
- 해당하는 경우 MAXDOP 설정 축소.
Azure SQL Database의 서비스 계층 및 컴퓨팅 크기별 작업자 및 세션 제한을 확인하세요.
- vCore 구매 모델을 사용한 단일 데이터베이스에 대한 리소스 제한
- vCore 구매 모델을 사용하여 탄력적 풀에 대한 리소스 제한
- DTU 구매 모델을 사용한 단일 데이터베이스에 대한 리소스 제한
- DTU 구매 모델 사용하여 탄력적 풀에 대한 리소스 제한
리소스 거버넌스 오류에서 세션 또는 작업자 제한에 대한 특정 오류를 해결하는 방법에 대해 자세히 알아보세요.
외부 연결
sp_invoke_external_rest_endpoint를 통해 수행되는 외부 엔드포인트에 대한 동시 연결 수는 작업자 스레드의 10%, 최대 150명의 작업자로 제한됩니다.
메모리
다른 리소스(CPU, 작업자, 스토리지)와 달리 메모리 제한에 도달하면 쿼리 성능에 부정적인 영향을 주지 않으며 오류 및 오류가 발생하지 않습니다. 메모리 관리 아키텍처 가이드자세히 설명한 대로 데이터베이스 엔진은 기본적으로 사용 가능한 모든 메모리를 사용하는 경우가 많습니다. 메모리는 스토리지 액세스 속도가 느려지지 않도록 데이터를 캐싱하는 데 주로 사용됩니다. 스토리지에서 읽는 속도에 비해 메모리에서 읽는 속도가 빠르기 때문에 메모리 사용률이 높으면 대체로 쿼리 성능이 향상됩니다.
데이터베이스 엔진이 시작된 후 워크로드가 스토리지에서 데이터를 읽기 시작하면 데이터베이스 엔진은 메모리에 데이터를 적극적으로 캐시합니다. 이 초기 램프업 기간이 지나면 일반적으로 avg_memory_usage_percent에서 avg_instance_memory_percent 및 열과 sql_instance_memory_percent Azure Monitor 메트릭이 100%에 가까울 것으로 예상됩니다. 특히 유휴 상태가 아니고 메모리에 완전히 들어가지 않는 데이터베이스의 경우에는 더욱 그렇습니다.
참고
sql_instance_memory_percent 메트릭은 데이터베이스 엔진의 총 메모리 사용량을 반영합니다. 고강도 워크로드가 실행되는 경우에도 이 메트릭은 100%에 도달하지 못할 수 있습니다. 이는 사용 가능한 메모리의 작은 부분이 스레드 스택 및 실행 가능한 모듈과 같은 데이터 캐시 이외의 중요한 메모리 할당을 위해 예약되었기 때문입니다.
데이터 캐시 외에도 메모리는 데이터베이스 엔진의 다른 구성 요소에서 사용됩니다. 메모리에 대한 수요가 있는데 데이터 캐시가 사용 가능한 모든 메모리를 사용했을 때 데이터베이스 엔진은 데이터 캐시 크기를 축소하여 다른 구성 요소가 메모리를 사용할 수 있게 하고 다른 구성 요소가 메모리를 릴리스하면 데이터 캐시를 동적으로 확장합니다.
드문 경우지만 상당히 까다로운 워크로드로 인해 메모리 부족 상태가 생기고 메모리 부족 오류가 발생할 수 있습니다. 메모리리 부족 오류는 메모리 사용률 0%에서 100%까지 모든 수준에서 발생할 수 있습니다. 메모리 부족 오류는 메모리 한도가 상대적으로 작은 컴퓨팅 크기 및/또는 쿼리 처리에 더 많은 메모리를 사용하는 워크로드(예: 조밀한 Elastic Pool)에서 발생할 가능성이 더 큽니다.
메모리 부족 오류가 발생할 경우 완화 옵션에는 다음이 포함됩니다.
- sys.dm_os_out_of_memory_events에서 OOM 조건의 세부 정보를 검토합니다.
- 데이터베이스 또는 탄력적 풀의 서비스 계층 또는 컴퓨팅 크기를 늘립니다. 단일 데이터베이스 리소스 확장 및 탄력적 풀 리소스 확장을 참조하세요.
- 메모리 사용률을 줄이기 위해 쿼리와 구성을 최적화합니다. 공통 솔루션은 다음 표에 설명되어 있습니다.
| 해결 방법 | 설명 |
|---|---|
| 메모리 부여 크기 줄이기 | 메모리 부여에 대한 자세한 내용은 SQL Server 메모리 부여 이해하기 블로그 게시물을 참조하세요. 너무 큰 메모리 부여를 방지 하는 일반적인 솔루션은 최신 기본적으로 호환성 수준 140 이상을 사용하는 데이터베이스에서 데이터베이스 엔진은 일괄 처리 모드 메모리 부여 피드백을 사용하여 메모리 부여 크기를 자동으로 조정할 수 있습니다. 마찬가지로 호환성 수준 150 이상을 사용하는 데이터베이스에서 데이터베이스 엔진은 더 일반적인 행 모드 쿼리를 위해 행 모드 메모리 부여 피드백도 사용합니다. 해당 기본 제공 기능을 사용하면 큰 메모리 부여로 인한 메모리 부족 오류를 방지할 수 있습니다. |
| 쿼리 계획 캐시 크기 줄이기 | 데이터베이스 엔진은 쿼리를 실행할 때마다 쿼리 계획을 컴파일하지 않으려고 메모리에 쿼리 계획을 캐시합니다. 한 번만 사용되는 캐싱 계획으로 인해 쿼리 계획 캐시가 팽창하지 않도록 하려면 매개 변수화된 쿼리를 사용하고 OPTIMIZE_FOR_AD_HOC_WORKLOADS 데이터베이스 범위 구성을 사용하도록 설정하는 것이 좋습니다. |
| 잠금 메모리 크기 줄이기 | 데이터베이스 엔진은 잠금에 메모리를 사용합니다. 가능한 경우, 많은 수의 잠금을 가져오고 잠금 메모리 사용량을 늘릴 수 있는 큰 트랜잭션은 피하세요. |
사용자 워크로드 및 내부 프로세스별 리소스 사용량
Azure SQL 데이터베이스는 핵심 서비스 기능(예: 고가용성 및 재해 복구, 데이터베이스 백업 및 복원, 모니터링, 쿼리 저장소, 자동 튜닝 등)을 구현하기 위해 컴퓨팅 리소스를 필요로 합니다. 시스템은 리소스 거버넌스 메커니즘을 사용하여 해당 내부 프로세스를 위해 전체 리소스의 제한된 부분을 확보해 두고, 나머지 리소스는 사용자 워크로드에 사용될 수 있게 합니다. 내부 프로세스에서 컴퓨팅 리소스를 사용하지 않는 경우, 시스템은 사용자 워크로드에서 컴퓨팅 리소스를 사용할 수 있도록 합니다.
사용자 워크로드 및 내부 프로세스의 총 CPU 및 메모리 사용량은 sys.dm_db_resource_stats 및 sys.resource_stats 보기의 avg_instance_cpu_percent 및 avg_instance_memory_percent 열에 보고됩니다. 이 데이터는 sql_instance_cpu_percent와 풀 수준의 sql_instance_memory_percent에 대해서도 sql_instance_cpu_percent 및 sql_instance_memory_percent Azure Monitor 메트릭을 통해 보고됩니다.
참고
sql_instance_cpu_percent 및 sql_instance_memory_percent Azure Monitor 메트릭은 2023년 7월부터 사용할 수 있습니다. 이는 각각 이전에 사용 가능한 sqlserver_process_core_percent 및 sqlserver_process_memory_percent 메트릭과 완전히 동일합니다. 후자의 두 메트릭은 계속 사용할 수 있지만 향후 제거될 예정입니다. 데이터베이스 모니터링이 중단되지 않도록 하려면 이전 메트릭을 사용하지 마세요.
이러한 메트릭은 기본, S1 및 S2 서비스 목표를 사용하는 데이터베이스에 사용할 수 없습니다. 다음 동적 관리 뷰에서 동일한 데이터를 사용할 수 있습니다.
각 데이터베이스의 사용자 워크로드에 의한 CPU 및 메모리 사용량은 sys.dm_db_resource_stats 및 sys.resource_stats 보기의 avg_cpu_percent 및 avg_memory_usage_percent 열에 보고됩니다. 탄력적 풀의 경우 풀 수준 리소스 사용량은 sys.elastic_pool_resource_stats 뷰(기록 보고 시나리오의 경우) 및 sys.dm_elastic_pool_resource_stats(실시간 모니터링용)에 보고됩니다. 사용자 워크로드의 CPU 사용량은 cpu_percent와 풀 수준의 탄력적 풀에 대해서도 cpu_percent Azure Monitor 메트릭을 통해 보고됩니다.
사용자 워크로드 및 내부 프로세스의 최근 리소스 사용량에 대한 자세한 내역은 sys.dm_resource_governor_resource_pools_history_ex 및 sys.dm_resource_governor_workload_groups_history_ex 보기에 보고됩니다. 해당 보기에서 참조되는 리소스 풀과 작업 그룹에 대한 자세한 내용은 리소스 거버넌스를 참조하세요. 해당 보기는 관련 리소스 풀과 작업 그룹에 있는 사용자 워크로드와 특정 내부 프로세스의 리소스 사용률을 보고합니다.
팁
워크로드 성능을 모니터링하거나 문제를 해결할 때 사용자 CPU 사용량(avg_cpu_percent, cpu_percent)과 사용자 워크로드 및 내부 프로세스의 총 CPU 사용량(avg_instance_cpu_percent, sql_instance_cpu_percent)을 모두 고려하는 것이 중요합니다. 이러한 메트릭 중 하나라도 70~100% 범위에 있으면 성능이 눈에 띄게 영향을 받을 수 있습니다.
사용자 CPU 사용량은 각 서비스 목표에서 사용자 워크로드 CPU 한도의 백분율로 정의됩니다. 마찬가지로 총 CPU 사용량은 모든 워크로드의 CPU 제한에 대한 백분율로 정의됩니다. 두 제한은 다르기 때문에 사용자와 총 CPU 사용량은 서로 다른 크기로 측정되며 서로 직접 비교할 수 없습니다.
사용자 CPU 사용량이 100%에 도달하면 총 CPU 사용량이 100% 미만으로 유지되더라도 사용자 워크로드가 선택한 서비스 목표에서 사용 가능한 CPU 용량을 완전히 사용하고 있음을 의미합니다.
총 CPU 사용량이 70~100% 범위에 도달하면 사용자 CPU 사용량이 100%에 훨씬 미치지 못하더라도 사용자 워크로드 처리량이 줄어들고 쿼리 대기 시간이 증가하는 것을 볼 수 있습니다. 이는 컴퓨팅 리소스가 적당히 할당된 소규모 서비스 목표를 사용하면서, 조밀한 탄력적 풀처럼 비교적 강력한 사용자 워크로드를 수행할 때 발생할 가능성이 높습니다. 또한 데이터베이스의 새 복제본을 만들거나 데이터베이스를 백업하는 경우와 같이 내부 프로세스에 일시적으로 더 많은 리소스가 필요한 경우 더 작은 서비스 목표에서 발생할 수 있습니다.
마찬가지로 사용자 CPU 사용량 70-100% 범위에 도달하면 총 CPU 사용량 제한보다 훨씬 낮더라도 사용자 워크로드 처리량이 평평해지고 쿼리 대기 시간이 증가합니다.
사용자 CPU 사용량 또는 총 CPU 사용량이 높은 경우, 완화하는 방법은 컴퓨팅 CPU 섹션에서 설명한 것과 동일하며 서비스 목표 증가 및/또는 사용자 워크로드 최적화도 이에 포함됩니다.
참고
완전히 유휴 상태인 데이터베이스 또는 Elastic Pool에서도 백그라운드 데이터베이스 엔진 활동으로 인해 총 CPU 사용량이 0이 되는 경우는 없습니다. 특정 백그라운드 활동, 컴퓨팅 크기 및 이전 사용자 워크로드에 따라 광범위하게 변동될 수 있습니다.
리소스 거버넌스
Azure SQL Database는 리소스 제한을 적용하기 위해 클라우드에서 실행되도록 수정 및 확장된 SQL Server Resource Governor를 기반으로 한 리소스 거버넌스 구현을 사용합니다. SQL Database에서는 풀 수준과 그룹 수준에서 모두 리소스 한도가 설정된 여러 리소스 풀과 작업 그룹이 균형 잡힌 Database-as-a-Service를 제공합니다. 사용자 워크로드와 내부 워크로드는 별도의 리소스 풀과 작업 그룹으로 분류됩니다. 지역 복제본을 비롯하여 주 복제본 및 읽기 가능한 보조 복제본의 사용자 워크로드는 SloSharedPool1 리소스 풀 및 UserPrimaryGroup.DBId[N] 워크로드 그룹으로 분류됩니다. 여기서 [N]은 데이터베이스 ID 값을 나타냅니다. 또한 다양한 내부 워크로드를 위한 여러 리소스 풀과 작업 그룹이 있습니다.
Resource Governor를 사용하여 데이터베이스 엔진 내의 리소스를 관리하는 것 외에도 Azure SQL Database는 프로세스 수준 리소스 거버넌스를 위해 Windows 작업 개체를 사용하고, 스토리지 할당량 관리를 위해 Windows FSRM(파일 서버 리소스 관리자)을 사용합니다.
Azure SQL Database 리소스 거버넌스는 본질적으로 계층적입니다. OS 수준과 스토리지 볼륨 수준에서 운영 체제 리소스 거버넌스 메커니즘을 사용하여, 그다음에는 리소스 풀 수준에서 Resource Governor를 사용하여, 그다음에는 작업 그룹 수준에서 Resource Governor를 사용하여, 위에서 아래로 한도가 적용됩니다. 현재 데이터베이스 또는 탄력적 풀에 적용되고 있는 리소스 거버넌스 제한은 sys.dm_user_db_resource_governance 뷰에 보고됩니다.
데이터 I/O 거버넌스
데이터 I/O 거버넌스는 데이터베이스의 데이터 파일에 대해 읽기 및 쓰기 물리적 I/O를 제한하는 데 사용되는 Azure SQL Database의 프로세스입니다. IOPS 한도는 각 서비스 수준에서 설정되어 “시끄러운 이웃” 효과를 최소화하고, 멀티 테넌트 서비스에서 리소스를 공정하게 할당하며, 기본 하드웨어 및 스토리지의 기능을 유지합니다.
단일 데이터베이스의 경우 워크로드 그룹 제한은 데이터베이스에 대한 모든 스토리지 I/O에 적용됩니다. 탄력적 풀의 경우 워크로드 그룹 제한이 풀의 각 데이터베이스에 적용됩니다. 또한 리소스 풀 제한은 탄력적 풀의 누적 I/O에 추가로 적용됩니다.
tempdb에서 I/O는 더 높은 tempdb I/O 제한이 적용되는 기본, 표준 및 범용 서비스 계층을 제외하고 워크로드 그룹 제한의 적용을 받습니다. 일반적으로 작업 그룹 한도가 리소스 풀 한도보다 낮고 IOPS/처리량을 더 빨리 제한하므로 데이터베이스(단일 또는 풀)에 대한 워크로드로 리소스 풀 한도를 달성하지 못할 수 있습니다. 그러나 동일한 풀의 여러 데이터베이스에 대해 결합된 워크로드에 의해 풀 제한에 도달할 수 있습니다.
예를 들어 I/O 리소스 거버넌스 없이 쿼리가 1,000IOPS를 생성하는데 작업 그룹의 IOPS 최대한도가 900IOPS로 설정되었다면, 쿼리는 900IOPS를 초과할 수 없습니다. 하지만 리소스 풀의 IOPS 최대한도가 1,500IOPS로 설정되어 있고 리소스 풀과 연결된 모든 작업 그룹의 총 I/O가 1,500IOPS를 초과하는 경우, 동일한 쿼리의 I/O가 작업 그룹 한도인 900IOPS 미만으로 감소할 수 있습니다.
sys.dm_user_db_resource_governance 보기에서 반환된 IOPS 및 처리량 최댓값은 보장되는 것이 아니라 한도/한계입니다. 또한 리소스 거버넌스는 특정 스토리지 대기 시간을 보장하지 않습니다. 특정한 사용자 워크로드에서 달성 가능한 최고의 대기 시간, IOPS, 처리량은 I/O 리소스 거버넌스 한도뿐만 아니라 사용되는 I/O 크기들의 조합, 기본 스토리지의 기능에 따라 달라집니다. SQL 데이터베이스는 512바이트에서 4MB 사이의 다양한 크기의 I/O 작업을 사용합니다. IOPS 한도를 적용하기 위해서 모든 I/O가 크기와 관계없이 계산되지만, Azure Storage에 데이터 파일이 있는 데이터베이스는 예외입니다. 이 경우 Azure Storage I/O 계정에 맞추기 위해 256KB보다 큰 IO는 여러 256KB I/O로 간주됩니다.
Azure Storage의 데이터 파일을 사용하는 기본, 표준, 범용 데이터베이스의 경우 데이터베이스에 이 IOPS 수를 누적적으로 제공할 수 있는 데이터 파일이 충분하지 않거나 데이터가 파일에 고르게 배포되어 있지 않거나 기본 Blob의 성능 계층이 IOPS/처리량을 리소스 거버넌스 한도 이하로 제한하면 primary_group_max_io 값을 달성할 수 없습니다. 마찬가지로 빈번한 트랜잭션 커밋으로 생성된 소규모 로그 IO 작업에서는 기본 Azure Storage Blob의 IOPS 한도로 인해 워크로드에서 primary_max_log_rate 값을 달성할 수 없습니다. Azure Premium Storage를 사용하는 데이터베이스의 경우 Azure SQL Database는 데이터베이스 크기와 관계없이 필요한 IOPS/처리량을 얻기 위해 충분히 큰 스토리지 Blob을 사용합니다. 큰 데이터베이스의 경우 총 IOPS/처리량의 용량을 늘리기 위해 여러 개의 데이터 파일이 생성됩니다.
avg_data_io_percent, avg_log_write_percent, sys.dm_elastic_pool_resource_stats 및 sys.elastic_pool_resource_stats 뷰에 보고된 와 같은 리소스 사용률 값은 리소스 거버넌스 최대한도의 백분율로 계산됩니다. 따라서 리소스 거버넌스를 제외한 다른 요소가 IOPS/처리량을 제한하면, 보고된 리소스 사용률이 100% 밑으로 유지되더라도 워크로드가 증가함에 따라 IOPS/처리량이 줄어들고 대기 시간이 증가하는 것을 확인할 수 있습니다.
데이터베이스 파일당 대기 시간, 읽기 및 쓰기 IOPS, 처리량을 모니터링하려면 sys.dm_io_virtual_file_stats() 함수를 사용합니다. 이 함수는 avg_data_io_percent에 계산되지 않는 백그라운드 I/O를 비롯하여, 데이터베이스에 대한 모든 I/O를 표시하지만, 기본 저장소의 IOPS 및 처리량을 사용하며, 관찰된 저장소 대기 시간에 영향을 줄 수 있습니다. 이 함수는 읽기 및 쓰기에 대한 I/O 리소스 거버넌스에 의해 도입될 수 있는 추가 대기 시간을 각각 io_stall_queued_read_ms 열과 io_stall_queued_write_ms 열에서 보고합니다.
트랜잭션 로그 속도 거버넌스
트랜잭션 로그 속도 거버넌스는 Azure SQL Database의 프로세스이며, 대량 삽입, SELECT INTO, 인덱스 빌드 같은 워크로드에 대한 높은 수집 속도를 제한하는 데 사용됩니다. 해당 한도는 로그 레코드 생성 속도에 맞춰 초 단위 미만의 수준에서 추적되고 적용되므로 데이터 파일에 대해 발급될 수 있는 IO 수와 관계없이 처리량을 제한합니다. 트랜잭션 로그 생성 속도는 현재 하드웨어 종속 및 서비스 계층 종속 지점까지 선형으로 확장됩니다.
로그 속도는 다양한 시나리오에서 달성하고 유지할 수 있도록 설정되며, 전체 시스템은 사용자 로드에 미치는 영향을 최소화하면서 기능을 유지할 수 있습니다. 로그 속도 거버넌스는 트랜잭션 로그 백업이 게시된 복구성 SLA 내에 유지되도록 합니다. 또한 이 거버넌스를 통해 보조 복제본에 대한 과도한 백로그가 방지됩니다. 그렇지 않으면 장애 조치(failover) 중에 예상된 가동 중지 시간보다 길어질 수 있습니다.
트랜잭션 로그 파일에 대한 실제 물리적 IO는 통제되거나 제한되지 않습니다. 로그 레코드가 생성되면 각 작업을 계산하고 최대 로그 속도(초당 MB/s)를 유지하기 위해 작업을 지연해야 하는지 여부를 평가합니다. 로그 레코드가 스토리지로 플러시될 때 지연 시간은 추가되지 않고, 로그 속도가 생성되는 동안 로그 속도 거버넌스가 적용됩니다.
런타임에 적용되는 실제 로그 생성 속도는 피드백 메커니즘의 영향을 받아 시스템이 안정화될 수 있도록 허용 로그 속도를 일시적으로 줄일 수도 있습니다. 로그 파일 공간 관리를 사용하여 로그 공간 부족 상태를 방지하고 데이터 복제 메커니즘을 통해 전체적인 시스템 한도를 일시적으로 낮출 수 있습니다.
로그 속도 관리자 트래픽 셰이핑은 다음 대기 유형을 통해 표시됩니다(sys.dm_exec_requests 및 sys.dm_os_wait_stats 보기에 노출됨).
| 대기 유형 | 주의 |
|---|---|
LOG_RATE_GOVERNOR |
데이터베이스 제한 |
POOL_LOG_RATE_GOVERNOR |
풀 제한 |
INSTANCE_LOG_RATE_GOVERNOR |
인스턴스 수준 제한 |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
피드백 컨트롤, 프리미엄/중요 비즈니스용에서 가용성 그룹의 물리적 복제를 유지하지 않음 |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
피드백 컨트롤, 로그 공간 부족 상태를 방지하기 위해 속도 제한 |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
지역 복제 피드백 컨트롤, 긴 데이터 대기 시간 및 지역 보조 복제본의 비가용성을 방지하기 위해 로그 속도 제한 |
원하는 확장성을 방해하는 로그 속도 제한이 발생하는 경우 다음 옵션을 고려하세요.
- 서비스 계층의 최대 로그 속도를 얻으려면 더 높은 서비스 수준으로 스케일 업하거나 다른 서비스 계층으로 전환하세요.
- 로드 중인 데이터가 ETL 프로세스의 준비 데이터와 같이 임시 데이터인 경우
tempdb(최소 로그됨)로 로드할 수 있습니다. - 분석 시나리오의 경우 클러스터된 columnstore 테이블 또는 데이터 압축을 사용하는 색인이 있는 테이블에 로드합니다. 이렇게 하면 필요한 로그 속도가 줄어듭니다. 이 기술은 CPU 사용률을 높이므로 클러스터된 columnstore 인덱스 또는 데이터 압축의 이점을 누리는 데이터 세트에만 적용됩니다.
스토리지 공간 거버넌스
프리미엄 및 중요 비즈니스용 서비스 계층에서 데이터 파일, 트랜잭션 로그 파일 및 tempdb 파일을 포함한 고객 데이터는 데이터베이스 또는 탄력적 풀을 호스팅하는 컴퓨터의 로컬 SSD 스토리지에 저장됩니다. 로컬 SSD 스토리지는 높은 IOPS 및 처리량과 낮은 I/O 대기 시간을 제공합니다. 고객 데이터 외에도 로컬 스토리지는 운영 체제, 관리 소프트웨어, 데이터 및 로그 모니터링 및 시스템 작업에 필요한 기타 파일에 사용됩니다.
로컬 스토리지의 크기는 한정되어 있으며 최대 로컬 스토리지 제한 또는 고객 데이터 용으로 따로 설정한 로컬 스토리지를 결정하는 하드웨어 기능에 따라 다릅니다. 이 제한은 안전하고 신뢰할 수 있는 시스템 작업을 보장하면서 고객 데이터 스토리지를 최대화하도록 설정되어 있습니다. 각 서비스 목표에 대한 최대 로컬 스토리지 값을 찾으려면 단일 데이터베이스 및 탄력적 풀에 대한 리소스 제한 문서를 참조하세요.
다음 쿼리를 사용하여 이 값 및 지정된 데이터베이스 또는 탄력적 풀에서 현재 사용하는 로컬 스토리지의 양을 확인할 수도 있습니다.
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| 열 | 설명 |
|---|---|
server_name |
논리 서버 이름 |
database_name |
데이터베이스 이름 |
slo_name |
하드웨어 생성을 포함한 서비스 목표 이름 |
user_data_directory_space_quota_mb |
최대 로컬 스토리지(MB) |
user_data_directory_space_usage_mb |
데이터 파일, 트랜잭션 로그 파일 및 tempdb 파일의 현재 로컬 스토리지 사용량(MB)입니다. 5분마다 업데이트됩니다. |
이 쿼리는 master 데이터베이스가 아닌 user 데이터베이스에서 실행해야 합니다. 탄력적 풀의 경우 풀의 모든 데이터베이스에서 쿼리를 실행할 수 있습니다. 보고된 값은 전체 풀에 적용합니다.
중요
프리미엄 및 중요 비즈니스용 서비스 계층에서 워크로드가 데이터 파일, 트랜잭션 로그 파일 및 tempdb 파일의 결합된 로컬 스토리지 소비를 최대 로컬 스토리지 제한을 초과하여 늘리려 고 하면 공간 부족 오류가 발생합니다. 이 문제는 데이터베이스 파일의 사용된 공간이 파일의 최대 크기에 도달하지 않은 경우에도 발생합니다.
로컬 SSD 스토리지는 tempdb 데이터베이스 및 Hyperscale RBPEX 캐시에 대해 Premium 및 중요 비즈니스용 이외의 서비스 계층에 있는 데이터베이스에서도 사용됩니다. 데이터베이스를 만들고, 삭제하고, 크기를 늘리거나 줄이면 시간이 지남에 따라 컴퓨터의 총 로컬 스토리지 사용량이 변동됩니다. 시스템에서 컴퓨터의 사용 가능한 로컬 저장소가 부족하고 데이터베이스 또는 Elastic Pool에 공간이 부족할 위험이 있음을 감지하면 데이터베이스 또는 Elastic Pool을 사용 가능한 로컬 저장소가 충분한 다른 컴퓨터로 이동합니다.
이와 같은 이동은 데이터베이스 스케일링 작업과 유사하게 온라인 방식으로 진행되며, 작업 끝에 발생하는 몇 초의 짧은 장애 조치(failover) 등 유사한 영향을 미칩니다. 이 장애 조치(failover)는 열려 있는 연결을 종료하고 트랜잭션을 롤백하여 해당 시점의 데이터베이스를 사용하는 애플리케이션에 영향을 줄 수 있습니다.
모든 데이터가 다른 컴퓨터의 로컬 저장소 볼륨에 복사되기 때문에 프리미엄 및 중요 비즈니스용 서비스 계층에서 더 큰 데이터베이스를 이동하려면 상당한 시간이 필요할 수 있습니다. 그동안 데이터베이스 또는 탄력적 풀 또는 tempdb 데이터베이스의 로컬 공간 사용량이 빠르게 증가하면, 공간 부족의 위험이 증가합니다. 시스템은 공간 부족 오류를 최소화하고 불필요한 장애 조치(failover)를 피하기 위해 균형 잡힌 방식으로 데이터베이스 이동을 시작합니다.
tempdb 크기
Azure SQL Database의 tempdb에 대한 크기 제한은 구매 및 배포 모델에 따라 다릅니다.
자세한 내용은 tempdb 크기 제한을 검토합니다.
- vCore 구매 모델: 단일 데이터베이스, 풀링된 데이터베이스
- DTU 구매 모델: 단일 데이터베이스, 풀링된 데이터베이스
이전에 사용 가능한 하드웨어
이 섹션에는 이전에 사용 가능한 하드웨어에 대한 세부 정보가 포함되어 있습니다.
- Gen4 하드웨어가 사용 중지되었으며 프로비전, 업 스케일링 또는 다운스컬링에는 사용할 수 없습니다. 더 넓은 범위의 vCore 및 스토리지 확장성, 가속화된 네트워킹, 최고의 IO 성능, 최소 지연 시간을 위해 데이터베이스를 지원되는 하드웨어 세대로 마이그레이션합니다. 자세한 내용은 Azure SQL 데이터베이스의 Gen4 하드웨어에 대한 지원 종료를 참조하세요.
Azure Resource Graph Explorer를 사용하여 현재 Gen4 하드웨어를 사용하는 모든 Azure SQL 데이터베이스 리소스를 식별하거나 Azure Portal에서 특정 논리 서버에 대한 리소스가 사용하는 하드웨어를 확인할 수 있습니다.
Azure Resource Graph Explorer에서 결과를 보려면 Azure 개체 또는 개체 그룹에 대해 최소한 read 권한이 있어야 합니다.
Resource Graph Explorer를 사용하여 여전히 Gen4 하드웨어를 사용하는 Azure SQL 리소스를 식별하려면 다음 단계를 수행합니다.
Azure Portal로 이동합니다.
검색 상자에서
Resource graph를 검색하고 검색 결과에서 Resource Graph Explorer 서비스를 선택합니다.쿼리 창에서 다음 쿼리를 입력하고 쿼리 실행을 선택합니다.
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"결과 창에는 Gen4 하드웨어를 사용하는 Azure에서 현재 배포된 모든 리소스가 표시됩니다.
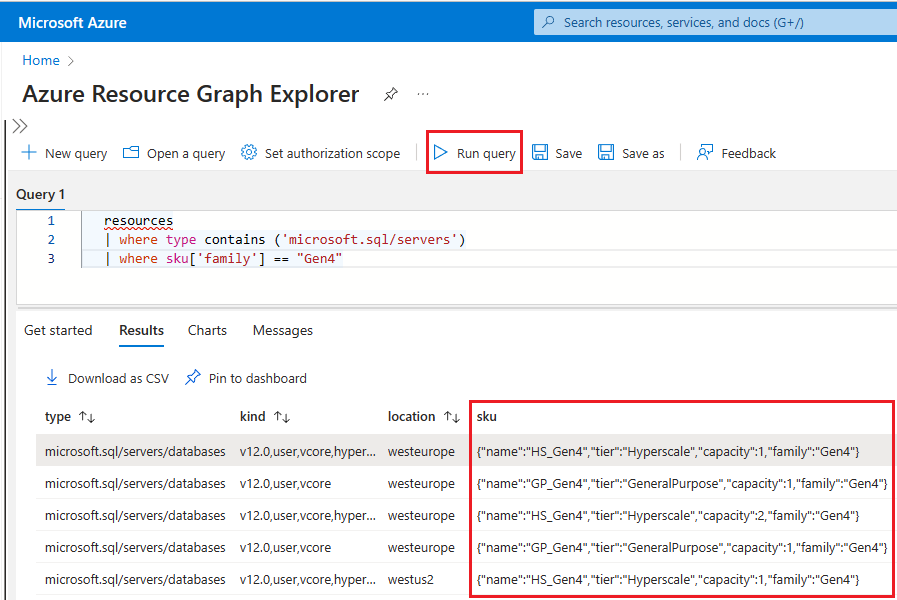
Azure의 특정 논리 서버에 대한 리소스에서 사용하는 하드웨어를 검사하려면 다음 단계를 수행합니다.
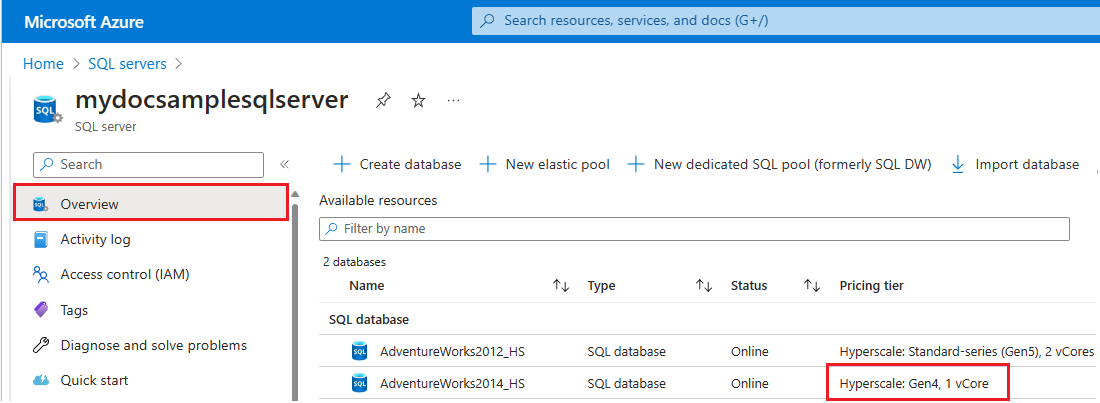
- Azure Portal로 이동합니다.
- 검색 상자에서
SQL servers를 검색하고 검색 결과에서 SQL Server를 선택하여 SQL Server 페이지를 열고 선택한 구독에 대한 모든 서버를 봅니다. - 관심 있는 서버를 선택하여 서버에 대한 개요 페이지를 엽니다.
- 사용 가능한 리소스까지 아래로 스크롤하고 Gen4 하드웨어를 사용하는 리소스에 대한 가격 책정 계층 열을 확인합니다.
리소스를 표준 시리즈 하드웨어로 마이그레이션하려면 하드웨어 변경을 검토하세요.
관련 콘텐츠
- 일반 Azure 제한에 대한 자세한 내용은 Azure 구독 및 서비스 제한, 할당량 및 제약 조건을 참조하세요.
- DTU 및 eDTU에 대한 자세한 내용은 DTU 및 eDTU를 참조하세요.
-
tempdb크기 제한에 대한 자세한 내용은 단일 vCore 데이터베이스, 풀링된 vCore 데이터베이스, 단일 DTU 데이터베이스 및 풀링된 DTU 데이터베이스를 참조하세요.