적용 대상:![]() Azure SQL Database
Azure SQL Database
이 문서에서는 Azure SQL Database에 대한 vCore 구매 모델을 검토합니다.
개요
vCore(가상 코어)는 논리적 CPU를 나타내며, 하드웨어의 물리적 특성(예: 코어 수, 메모리 및 스토리지 크기)을 선택할 수 있는 옵션을 제공합니다. vCore 기반 구매 모델은 개별 리소스 사용에 대한 유연성, 제어, 투명성 및 온-프레미스 워크로드 요구 사항을 클라우드로 전환하는 직관적인 방법을 제공합니다. 이 모델은 비용을 최적화하고 워크로드 필요에 따라 컴퓨팅, 메모리, 스토리지 리소스를 선택할 수 있습니다.
vCore 기반 구매 모델에서 비용은 다음의 선택 및 사용량에 따라 달라집니다.
- 서비스 계층
- 하드웨어 구성
- 컴퓨팅 리소스(vCore 수 및 메모리 양)
- 예약된 데이터베이스 스토리지
- 실제 백업 스토리지
중요합니다
컴퓨팅 리소스, I/O 및 데이터 및 로그 스토리지는 데이터베이스 또는 탄력적 풀당 요금이 청구됩니다. 백업 스토리지는 각 데이터베이스당 요금이 청구됩니다. 가격 책정에 대한 자세한 내용은 Azure SQL Database 가격 책정 페이지를 참조하세요.
vCore 및 DTU 구매 모델 비교
Azure SQL Database에서 사용하는 vCore 구매 모델은 DTU 기반 구매 모델에 비해 다음과 같은 몇 가지 이점을 제공합니다.
- 컴퓨팅, 메모리, I/O 및 스토리지 제한이 높아집니다.
- 워크로드의 컴퓨팅 및 메모리 요구 사항과 더 잘 일치하도록 하드웨어 구성을 선택합니다.
- AHB(Azure 하이브리드 혜택)를 사용한 가격 책정 할인.
- 온-프레미스 배포에서 마이그레이션을 쉽게 계획할 수 있도록 컴퓨팅을 구동하는 하드웨어 세부 정보의 투명성을 높입니다.
- 예약 인스턴스 가격은 vCore 구매 모델에만 사용할 수 있습니다.
- 여러 컴퓨팅 크기를 사용할 수 있는 크기 조정 세분성이 향상됩니다.
vCore 및 DTU 구매 모델 중에서 선택하는 방법에 대한 도움말 은 vCore와 DTU 기반 구매 모델 간의 차이점을 참조하세요.
컴퓨팅
vCore 기반 구매 모델에는 프로비전된 컴퓨팅 계층과 서버리스 컴퓨팅 계층이 있습니다. 프로비전된 컴퓨팅 계층에서 컴퓨팅 비용은 워크로드 작업과 관계없이 애플리케이션에 대해 지속적으로 프로비전되는 총 컴퓨팅 용량을 반영합니다. vCore 및 메모리 요구 사항에 따라 비즈니스 요구 사항에 가장 적합한 리소스 할당을 선택한 다음 워크로드에서 필요에 따라 리소스를 확장 및 축소합니다. Azure SQL Database에 대한 서버리스 컴퓨팅 계층에서 컴퓨팅 리소스는 워크로드 용량에 따라 자동 크기 조정되며 사용된 컴퓨팅 양(초당)에 대한 요금이 청구됩니다.
요약:
- 프로비전된 컴퓨팅 계층은 워크로드 활동과 독립적으로 지속적으로 프로비전되는 특정 양의 컴퓨팅 리소스를 제공하지만, 서버리스 컴퓨팅 계층은 워크로드 활동에 따라 컴퓨팅 리소스를 자동으로 크기 조정합니다.
- 프로비전된 컴퓨팅 계층은 시간당 고정 가격으로 프로비전된 컴퓨팅 양에 대해 요금을 청구하지만, 서버리스 컴퓨팅 계층은 사용되는 컴퓨팅 양(초당)에 대해 요금을 청구합니다.
컴퓨팅 계층에 관계없이 3개의 추가 고가용성 보조 복제본이 중요 비즈니스용 서비스 계층에 자동으로 할당되어 오류 및 빠른 장애 조치(failover)에 대한 높은 복원력을 제공합니다. 이러한 추가 복제본을 사용하면 범용 서비스 계층보다 약 2.7배 높은 비용이 듭니다. 마찬가지로 중요 비즈니스용 서비스 계층에서 GB당 스토리지 비용이 높을수록 로컬 SSD 스토리지의 대기 시간 및 IO 한도가 높아집니다.
하이퍼스케일에서 고객은 비용을 제어하면서 애플리케이션에 필요한 복원력 수준을 얻기 위해 추가 고가용성 복제본 수를 0에서 4로 제어합니다.
Azure SQL Database의 컴퓨팅에 대한 자세한 내용은 컴퓨팅 리소스(CPU 및 메모리)를 참조하세요.
리소스 제한
vCore 리소스 제한의 경우 사용 가능한 하드웨어 구성을 검토한 다음 리소스 제한을 검토합니다.
데이터 및 로그 스토리지
다음 요소는 데이터 및 로그 파일에 사용되는 스토리지의 양에 영향을 주며 범용 및 중요 비즈니스 계층에 적용됩니다.
- 각 컴퓨팅 크기는 구성 가능한 최대 데이터 크기를 지원하며 기본값은 32GB입니다.
- 최대 데이터 크기를 구성하면 로그 파일에 대해 청구 가능한 스토리지의 30%가 자동으로 추가됩니다.
- 범용 서비스 계층의 경우
tempdb에서 로컬 SSD를 사용하며, 이 스토리지의 비용이 vCore 가격에 포함됩니다. - 중요 비즈니스 서비스 계층의 경우
tempdb에서 데이터 및 로그 파일이 포함된 로컬 및 SSD 스토리지를 사용하고tempdb스토리지의 비용이 vCore 가격에 포함됩니다. - 범용 및 중요 비즈니스용 계층에서는 데이터베이스 또는 탄력적 풀에 대해 구성된 최대 스토리지 크기에 대한 요금이 청구됩니다.
- SQL Database의 경우 1GB에서 지원되는 최대 스토리지 크기 사이의 최대 데이터 크기를 1GB씩 증분하여 선택할 수 있습니다.
하이퍼스케일에는 다음과 같은 스토리지 고려 사항이 적용됩니다.
- 최대 데이터 스토리지 크기는 128TB로 설정되며 구성할 수 없습니다.
- 최대 데이터 스토리지가 아닌 할당된 데이터 스토리지에 대해서만 요금이 청구됩니다.
- 로그 스토리지에 대한 요금은 청구되지 않습니다.
-
tempdb는 로컬 SSD 스토리지를 사용하며 해당 비용은 vCore 가격에 포함됩니다. SQL Database에서 현재 할당되고 사용된 데이터 스토리지 크기를 모니터링하려면 allocated_data_storage 및 스토리지 Azure Monitor 메트릭을 각각 사용합니다.
T-SQL을 사용하여 데이터베이스에서 개별 데이터 및 로그 파일의 현재 할당 및 사용된 스토리지 크기를 모니터링하려면 sys.database_files 보기와 FILEPROPERTY(... , 'SpaceUsed') 함수를 사용합니다.
팁 (조언)
경우에 따라 사용하지 않는 공간을 회수하기 위해 데이터베이스를 축소해야 할 수도 있습니다. 자세한 내용은 Azure SQL 데이터베이스의 파일 공간 관리를 참조하세요.
백업 스토리지
데이터베이스 백업을 위한 스토리지는 SQL Database의 PITR(지정 시간 복원) 및 LTR(장기 보존) 기능을 지원하기 위해 할당됩니다. 이 스토리지는 데이터 및 로그 파일 스토리지와는 별개이며 별도로 청구됩니다.
- PITR: 범용 및 중요 비즈니스용 계층에서는 개별 데이터베이스 백업이 Azure Storage 에 자동으로 복사됩니다. 스토리지 크기는 새 백업이 생성될 때 동적으로 늘어납니다. 전체, 차등 및 트랜잭션 로그 백업에 스토리지를 사용합니다. 스토리지 사용량은 백업에 대해 구성된 데이터베이스 변동률과 보존 기간에 따라 다릅니다. SQL Database에 대해 1~35일 사이에 각 데이터베이스에 대해 별도의 보존 기간을 구성할 수 있습니다. 구성된 최대 데이터 크기와 같은 백업 스토리지 용량이 추가 요금 없이 제공됩니다.
- LTR: 최대 10년 동안 전체 백업의 장기 보존을 구성할 수도 있습니다. LTR 정책을 설정하는 경우 이러한 백업은 Azure Blob Storage에 자동으로 저장되지만 백업이 복사되는 빈도를 제어할 수 있습니다. 서로 다른 준수 요구 사항을 충족하려면 주별, 월별 또는 연도별 백업에 대해 다른 보존 기간을 선택할 수 있습니다. 선택한 구성에 따라 LTR 백업에 사용되는 스토리지의 양이 결정됩니다. 자세한 내용은 장기 백업 보존을 참조하세요.
하이퍼스케일의 백업 스토리지는 하이퍼스케일 데이터베이스에 대한 자동화된 백업을 참조하세요.
서비스 계층
vCore 구매 모델의 서비스 계층 옵션에는 범용, 중요 비즈니스용 및 하이퍼스케일이 포함됩니다. 서비스 계층은 일반적으로 스토리지 유형 및 성능, 고가용성 및 재해 복구 옵션 및 In-Memory OLTP와 같은 특정 기능의 가용성을 결정합니다.
| 사용 사례 | 범용 목적 | 비즈니스 필수 | 하이퍼스케일 |
|---|---|---|---|
| 가에 적합한 | 대부분의 비즈니스 워크로드. 예산에 맞게 균형 있고 확장 가능한 컴퓨팅 및 스토리지 옵션을 제공합니다. | 여러 고가용성 보조 복제본을 사용하여 비즈니스 애플리케이션에 오류에 대한 가장 높은 복원력을 제공하고 가장 높은 I/O 성능을 제공합니다. | 확장성이 뛰어난 스토리지 및 읽기 확장 요구 사항이 있는 워크로드를 포함하여 다양한 워크로드를 제공합니다. 둘 이상의 고가용성 보조 복제본 구성을 허용하여 오류에 대한 복원력을 높입니다. |
| 컴퓨팅 크기 | vCore 2~128개 | vCore 2~128개 | vCore 2~128개 |
| 스토리지 유형 | 프리미엄 원격 스토리지(인스턴스별) | 초고속 로컬 SSD 스토리지(인스턴스별) | 컴퓨트 복제본당 로컬 SSD 캐시를 사용한 분리된 스토리지 |
| 스토리지 크기 | 1GB – 4TB | 1GB – 4TB | 10GB – 128TB |
| IOPS | vCore당 320 IOPS(최대 16,000 IOPS) | vCore당 4,000 IOPS(최대 327,680 IOPS) | 최대 로컬 SSD를 사용하는 327,680 IOPS 하이퍼스케일은 여러 수준에서 캐싱을 사용하는 다중 계층 아키텍처입니다. 효과적인 IOPS는 워크로드에 따라 달라집니다. |
| 메모리/vCore | 5.1GB | 5.1GB | 5.1GB 또는 10.2GB |
| Backup | 지역 중복, 영역 중복 또는 로컬 중복 백업 스토리지 선택, 1-35일 보존(기본값 7일) 최대 10년까지 사용할 수 있는 장기 보존 |
지역 중복, 영역 중복 또는 로컬 중복 백업 스토리지 선택, 1-35일 보존(기본값 7일) 최대 10년까지 사용할 수 있는 장기 보존 |
LRS(로컬 중복), ZRS(영역 중복) 또는 GRS(지역 중복) 스토리지의 선택 항목 1~35일(기본적으로 7일) 보존, 최대 10년의 장기 보존 가능 |
| 가용성 | 하나의 복제본, 읽기 확장 복제본 없음, HA(영역 중복 고가용성) |
3개의 복제본, 하나의 읽기 확장 복제본, HA(영역 중복 고가용성) |
HA(영역 중복 고가용성) |
| 가격 책정 및 청구 |
vCore, 예약된 스토리지 및 백업 스토리지가 청구됩니다. IOPS는 청구되지 않습니다. |
vCore, 예약된 스토리지 및 백업 스토리지가 청구됩니다. IOPS는 청구되지 않습니다. |
각 복제본 및 사용된 스토리지에 대한 vCore 요금이 청구됩니다. IOPS는 청구되지 않습니다. |
| 할인 모델 |
Azure Reservations Azure 하이브리드 혜택(개발/테스트 구독에서 사용할 수 없음) Enterprise 및 사용량 기반 Dev/Test 제안 구독 |
Azure Reservations Azure 하이브리드 혜택(개발/테스트 구독에서 사용할 수 없음) Enterprise 및 사용량 기반 Dev/Test 제안 구독 |
Azure 하이브리드 혜택 (개발/테스트 구독에서는 사용할 수 없음) 1 Enterprise 및 사용량 기반 Dev/Test 제안 구독 |
| 메모리 내 OLTP 테이블 | 아니오 | 예 | 아니요 |
1 SQL Database 하이퍼스케일의 간소화된 가격 책정이 곧 제공될 예정입니다. 자세한 내용은 하이퍼스케일 가격 책정 블로그를 검토하세요.
자세한 내용은 논리 서버, 단일 데이터베이스 및 풀된 데이터베이스에 대한 리소스 제한을 검토합니다.
비고
SLA(서비스 수준 계약)에 대한 자세한 내용은 Azure SQL Database용 SLA를 참조하세요.
일반적인 목적
범용 서비스 계층의 아키텍처 모델은 컴퓨팅과 스토리지 분리를 기반으로 합니다. 이 아키텍처 모델은 데이터베이스 파일을 확실하게 복제하고 내부 인프라 오류가 발생하는 경우에도 데이터 무손실을 보장하는 Azure Blob Storage의 고가용성 및 안정성을 기반으로 합니다.
다음 그림은 분리된 컴퓨팅 및 스토리지 레이어가 있는 표준 아키텍처 모델의 4개 노드를 보여줍니다.
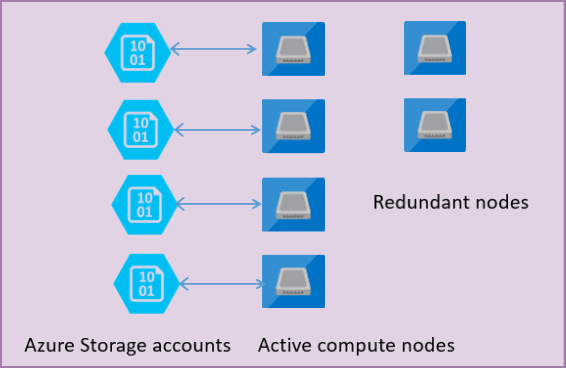
범용 서비스 계층의 아키텍처 모델에는 두 개의 계층이 있습니다.
- 상태 비저장 컴퓨팅 레이어는
sqlservr.exe프로세스를 실행하고 일시적인 데이터와 캐시된 데이터(예: 계획 캐시, 버퍼 풀, 열 저장 풀)만 포함합니다. 이 상태 비저장 노드는 프로세스를 초기화하고 노드의 상태를 제어하며 필요한 경우 다른 위치로 장애 조치(failover)를 수행하는 Azure 서비스 패브릭에 의해 운영됩니다. - 상태 저장 데이터 계층에는 데이터베이스 파일(.mdf/.ldf)이 있으며 Azure Blob Storage에 저장됩니다. Azure Blob Storage는 데이터베이스 파일에 배치된 레코드의 데이터 손실이 없음을 보장합니다. Azure Storage에는 프로세스가 충돌하는 경우에도 데이터 파일의 로그 파일 또는 페이지의 모든 레코드가 유지되도록 하는 기본 제공 데이터 가용성/중복성이 있습니다.
데이터베이스 엔진 또는 운영 체제가 업그레이드될 때마다 기본 인프라의 일부 부분이 실패하거나 프로세스에서 sqlservr.exe 중요한 문제가 발견되면 Azure Service Fabric은 상태 비저장 프로세스를 다른 상태 비저장 컴퓨팅 노드로 이동합니다. 장애 조치(failover) 시간을 최소화하기 위해 주 노드의 장애 조치(failover)가 발생하는 경우 새 컴퓨팅 서비스를 실행하기 위해 대기 중인 예비 노드 집합이 있습니다. Azure Storage 계층의 데이터는 영향을 받지 않으며 데이터/로그 파일은 새로 초기화된 프로세스에 연결됩니다. 이 프로세스는 기본적으로 99.99% 가용성을 보장하고 영역 중복성을 사용하는 경우 99.995% 가용성을 보장합니다. 전환 시간과 새 노드가 콜드 캐시로 시작된다는 사실로 인해 처리 중인 대형 워크로드에 성능 저하가 약간 발생할 수 있습니다.
범용 서비스 계층을 선택하는 경우
범용 서비스 계층은 대부분의 일반 워크로드용으로 설계된 Azure SQL Database의 기본 서비스 계층입니다. 기본 SLA 및 스토리지 대기 시간이 5ms에서 10ms 사이인 완전 관리형 데이터베이스 엔진이 필요한 경우 범용 계층이 옵션입니다.
비즈니스에 필수적
중요 비즈니스용 서비스 계층 모델은 데이터베이스 엔진 프로세스의 클러스터를 기반으로 합니다. 이 아키텍처 모델은 유지 관리 작업 중에도 워크로드에 대한 성능 영향을 최소화하기 위해 데이터베이스 엔진 노드의 쿼럼을 사용합니다. 기본 운영 체제, 드라이버 및 데이터베이스 엔진의 업그레이드 및 패치는 최종 사용자의 가동 중지 시간을 최소화하면서 투명하게 수행됩니다.
중요 비즈니스용 모델에서 컴퓨팅 및 스토리지는 각 노드에 통합됩니다. 4개 노드 클러스터의 각 노드에 있는 데이터베이스 엔진 프로세스 간에 데이터를 복제하고 각 노드는 로컬로 연결된 SSD를 데이터 스토리지로 사용하여 고가용성을 달성합니다. 다음 다이어그램에서는 중요 비즈니스용 서비스 계층이 가용성 그룹 복제본의 데이터베이스 엔진 노드 클러스터를 구성하는 방법을 보여 줍니다.

데이터베이스 엔진 프로세스와 기본 .mdf/.ldf 파일은 모두 로컬로 연결된 SSD 스토리지가 있는 동일한 노드에 배치되어 워크로드에 짧은 대기 시간을 제공합니다. SQL Server Always On 가용성 그룹과 유사한 기술을 사용하여 고가용성이 구현됩니다. 모든 데이터베이스는 고객 워크로드에 액세스할 수 있는 하나의 주 복제본과 데이터 복사본을 포함하는 3개의 보조 복제본이 있는 데이터베이스 노드의 클러스터입니다. 주 복제본은 어떤 이유로든 주 복제본이 실패할 경우 보조 복제본에서 데이터를 사용할 수 있도록 보조 복제본에 변경 내용을 지속적으로 푸시합니다. 장애 조치(failover)는 Service Fabric 및 데이터베이스 엔진에 의해 처리됩니다. 하나의 보조 복제본이 주 복제본이 되고 클러스터에 충분한 노드가 있는지 확인하기 위해 새 보조 복제본이 만들어집니다. 워크로드는 자동으로 새 주 복제본으로 리디렉션됩니다.
또한 중요 비즈니스용 클러스터에는 주 복제본 워크로드의 성능에 영향을 주지 않는 읽기 전용 쿼리(예: 보고서)를 실행하는 데 사용되는 읽기 전용 복제본을 무료로 제공하는 읽기 확장 기능이 제공됩니다.
중요 비즈니스용 서비스 계층을 선택하는 경우
중요 비즈니스용 서비스 계층은 기본 SSD 스토리지에서 짧은 대기 시간 응답(평균 1-2ms)이 필요하거나, 기본 인프라가 실패할 경우 더 빠른 복구를 요구하거나, 보고서, 분석 및 읽기 전용 쿼리를 주 데이터베이스의 읽기 가능한 무료 보조 복제본으로 오프로드해야 하는 애플리케이션을 위해 설계되었습니다.
범용 계층 대신 중요 비즈니스용 서비스 계층을 선택해야 하는 주요 이유는 다음과 같습니다.
- 낮은 I/O 대기 시간 요구 사항 – 스토리지 계층에서 일관되게 빠른 응답이 필요한 워크로드(평균 1~2밀리초)는 중요 비즈니스용 계층을 사용해야 합니다.
- 단일 무료 읽기 전용 보조 복제본으로도 충분한 보고 및 분석 쿼리 워크로드입니다.
- 더 높은 복원력과 오류로부터의 빠른 복구 시스템 오류가 있는 경우 주 인스턴스의 데이터베이스가 비활성화되고 보조 복제본 중 하나가 즉시 쿼리를 처리할 준비가 된 새 읽기-쓰기 주 데이터베이스가 됩니다.
- 고급 데이터 손상 방지 중요 비즈니스용 계층은 백그라운드에서 데이터베이스 복제본을 사용하므로 서비스는 미러링 및 가용성 그룹과 함께 사용할 수 있는 자동 페이지 복구를 사용하여 데이터 손상을 완화합니다. 복제본이 데이터 무결성 문제로 인해 페이지를 읽을 수 없는 경우 다른 복제본에서 페이지의 새 복사본을 검색하여 데이터 손실 또는 고객의 가동 중지 시간 없이 읽을 수 없는 페이지를 대체합니다. 이 기능은 데이터베이스에 지역 보조 복제본이 있는 경우 범용 계층에서 사용할 수 있습니다.
- 더 높은 가용성 - 다중 가용성 영역 구성의 중요 비즈니스용 계층은 영역 오류 및 고가용성 SLA에 대한 복원력을 제공합니다.
- 빠른 지역 복구 - 활성 지역 복제가 구성된 경우, 중요 비즈니스용 계층은 100%의 배포 시간 동안 RPO(복구 지점 목표) 5초와 RTO(복구 시간 목표) 30초를 보장합니다.
하이퍼스케일
하이퍼스케일 서비스 계층은 모든 워크로드 유형에 적합합니다. 클라우드 네이티브 아키텍처는 독립적으로 확장 가능한 컴퓨팅 및 스토리지를 제공하여 가장 다양한 기존 및 최신 애플리케이션을 지원합니다. 하이퍼스케일의 컴퓨팅 및 스토리지 리소스는 범용 및 중요 비즈니스용 계층에서 사용할 수 있는 리소스를 크게 초과합니다.
자세한 내용은 Azure SQL Database에 대한 하이퍼스케일 서비스 계층을 검토하세요.
하이퍼스케일 서비스 계층을 선택하는 경우
하이퍼스케일 서비스 계층은 클라우드 데이터베이스에서 기존에 확인되던 많은 실제 제한을 없애줍니다. 대부분의 다른 데이터베이스가 단일 노드에서 사용할 수 있는 리소스로 제한되지만 하이퍼스케일 서비스 계층의 데이터베이스에는 이러한 제한이 없습니다. 유연한 스토리지 아키텍처를 사용하면 하이퍼스케일 데이터베이스가 필요에 따라 증가하며 사용하는 스토리지 용량에 대해서만 요금이 청구됩니다.
하이퍼스케일은 고급 크기 조정 기능 외에도 대규모 데이터베이스뿐만 아니라 모든 워크로드에 적합한 옵션입니다. 하이퍼스케일을 사용하면 다음을 수행할 수 있습니다.
- 고가용성 복제본 수를 0에서 4로 선택하여 비용을 제어하면서 높은 복원력과 빠른 오류 복구 를 달성합니다.
- 컴퓨팅 및 스토리지에 대한 영역 중복성을 사용하도록 설정하여 고가용 성을 개선합니다.
- 데이터베이스의 자주 액세스하는 부분에 대해 낮은 I/O 대기 시간 (평균 1-2밀리초)을 달성합니다. 더 작은 데이터베이스의 경우 전체 데이터베이스에 적용될 수 있습니다.
- 명명된 복제본을 사용하여 다양한 읽기 확장 시나리오를 구현합니다.
- 새 노드의 로컬 스토리지에 데이터가 복사될 때까지 기다리지 않고 빠른 크기 조정을 활용합니다.
- 영향을 주지 않으며 연속 데이터베이스 백업 및 빠른 복원을 즐길 수 있습니다.
- 장애 조치(failover) 그룹 및 지역 복제를 사용하여 비즈니스 연속성 요구 사항을 지원합니다.
하드웨어 구성
vCore 모델의 일반적인 하드웨어 구성에는 표준 시리즈(Gen5), 프리미엄 시리즈, 최적화된 프리미엄 시리즈 메모리 및 DC 시리즈가 포함됩니다. 하이퍼스케일은 프리미엄 시리즈 및 프리미엄 시리즈 메모리 최적화 하드웨어에 대한 옵션도 제공합니다. 하드웨어 구성은 워크로드 성능에 영향을 주는 컴퓨팅 및 메모리 제한 및 기타 특성을 정의합니다.
표준 시리즈(Gen5)와 같은 특정 하드웨어 구성은 컴퓨팅 리소스(CPU 및 메모리)에 설명된 대로 둘 이상의 CPU(프로세서) 유형을 사용할 수 있습니다. 지정된 데이터베이스 또는 탄력적 풀은 CPU 유형이 동일한 하드웨어에 오랜 시간 동안 유지되는 경향이 있지만(일반적으로 여러 달 동안) 데이터베이스 또는 풀이 다른 CPU 유형을 사용하는 하드웨어로 이동될 수 있는 특정 이벤트가 있습니다.
데이터베이스 또는 풀은 다음과 같은 경우를 포함하지만 제한되지 않는 다양한 시나리오에 대해 이동할 수 있습니다.
- 서비스 목표가 변경됨
- 데이터 센터의 현재 인프라가 용량 제한에 근접하고 있습니다.
- 현재 사용되는 하드웨어는 수명이 종료되어 서비스 해제되고 있습니다.
- 영역 중복 구성을 사용하도록 설정하여 사용 가능한 용량으로 인해 다른 하드웨어로 이동
일부 워크로드의 경우 다른 CPU 유형으로 이동하면 성능이 변경됩니다. SQL Database는 CPU 유형이 변경되더라도 예측 가능한 워크로드 성능을 제공하기 위해 하드웨어를 구성하여 좁은 대역 내에서 성능 변경을 유지합니다. 그러나 SQL Database의 광범위한 고객 워크로드에서 새로운 유형의 CPU를 사용할 수 있게 되면 데이터베이스 또는 풀이 다른 CPU 유형으로 이동하는 경우 성능이 더 눈에 띄게 변경될 수 있습니다.
사용된 CPU 유형에 관계없이 데이터베이스 또는 탄력적 풀에 대한 리소스 제한(예: 코어 수, 메모리, 최대 데이터 IOPS, 최대 로그 속도 및 최대 동시 작업자 수)은 데이터베이스가 동일한 서비스 목표에 유지되는 한 동일하게 유지됩니다.
컴퓨팅 리소스(CPU 및 메모리)
다음 표에서는 다양한 하드웨어 구성 및 컴퓨팅 계층의 컴퓨팅 리소스를 비교합니다.
| 하드웨어 구성 | CPU (중앙 처리 장치) | 메모리 |
|---|---|---|
| 표준 시리즈(Gen5) |
프로비저닝된 컴퓨팅 - Intel® E5-2673 v4(Broadwell) 2.3GHz, Intel® SP-8160(Skylake)*, Intel® 8272CL(Cascade Lake) 2.5GHz*, Intel® Xeon® Platinum 8370C(Ice Lake)*, AMD EPYC 7763v(밀라노) 프로세서 - 최대 128개의 가상 코어(vCore) 프로비전 (하이퍼스레딩) 서버리스 컴퓨팅 - Intel® E5-2673 v4(Broadwell) 2.3GHz, Intel® SP-8160(Skylake)*, Intel® 8272CL(Cascade Lake) 2.5GHz*, Intel® Xeon® Platinum 8370C(Ice Lake)*, AMD EPYC 7763v(밀라노) 프로세서 - 최대 80개의 vCore 자동크기조정(하이퍼 스레드) - 메모리 대 vCore 비율은 워크로드 수요에 따라 메모리 및 CPU 사용량에 동적으로 적응하며 vCore당 최대 24GB일 수 있습니다. 예를 들어 지정된 시점에 워크로드가 240GB 메모리 및 10개 vCore에 대해서만 사용 및 요금이 청구될 수 있습니다. |
프로비저닝된 컴퓨팅 - vCore당 5.1GB - 최대 625GB 프로비전 서버리스 컴퓨팅 - vCore당 최대 24GB까지 자동크기조정 - 최대 240GB까지 자동크기조정 |
| Fsv2 시리즈** | - Intel® 8168(Skylake) 프로세서 - 3.4GHz의 지속형 모든 코어 터보 클록 속도와 최대 3.7GHz의 단일 코어 터보 클록 속도를 특징으로 합니다. - 최대 72개의 하이퍼스레드 vCore를 제공 |
- vCore당 1.9GB - 최대 136GB 프로비전 |
| DC 시리즈 | - Intel® Xeon® E-2288G 프로세서 - Intel SGX(Intel Software Guard 확장) 기능 - 최대 8개의 vCore(물리적) 프로비전 |
vCore당 4.5GB |
* sys.dm_user_db_resource_governance 동적 관리 보기에서는 Intel® SP-8160(Skylake) 프로세서를 사용하는 데이터베이스의 하드웨어 생성이 Gen6으로 표시되고, Intel® 8272CL(Cascade Lake)을 사용하는 데이터베이스용 하드웨어 생성이 Gen7로 표시되고, Intel® Xeon® Platinum 8370C(Ice Lake) 또는 AMD® EPYC® 7763v(밀라노)를 사용하는 데이터베이스용 하드웨어 생성이 Gen8로 표시됩니다. 지정된 컴퓨팅 크기 및 하드웨어 구성의 경우 리소스 제한은 CPU 유형(Intel Broadwell, Skylake, Ice Lake, Cascade Lake 또는 AMD Milan)에 관계없이 동일합니다.
** Fsv2 시리즈 하드웨어는 2026년 10월 1일에 사용 중지됩니다.
자세한 내용은 단일 데이터베이스 및 탄력적 풀의 리소스 한도를 참조하세요.
하이퍼스케일 데이터베이스 컴퓨팅 리소스 및 사양은 하이퍼스케일 컴퓨팅 리소스를 참조하세요.
표준 시리즈(Gen5)
Gen5(표준 시리즈) 하드웨어는 균형 잡힌 컴퓨팅 및 메모리 리소스를 제공하며 대부분의 데이터베이스 워크로드에 적합합니다.
표준 시리즈(Gen5) 하드웨어는 전 세계 모든 공용 지역에서 사용할 수 있습니다.
하이퍼스케일 프리미엄 시리즈
프리미엄 시리즈 하드웨어 옵션은 Intel 및 AMD의 최신 CPU 및 메모리 기술을 사용합니다. 프리미엄 시리즈는 표준 시리즈 하드웨어에 비해 컴퓨팅 성능을 향상시킵니다.
- 프리미엄 시리즈 옵션은 표준 시리즈에 비해 더 빠른 CPU 성능과 더 많은 수의 최대 vCore를 제공합니다.
- 프리미엄 시리즈 메모리 최적화 옵션은 표준 계열을 기준으로 두 배의 메모리 양을 제공합니다.
표준 시리즈, 프리미엄 시리즈 및 최적화된 프리미엄 시리즈 메모리는 하이퍼스케일 탄력적 풀에 사용할 수 있습니다.
자세한 내용은 하이퍼스케일 프리미엄 시리즈 블로그 공지 사항을 참조하세요.
사용 가능한 지역의 경우 하이퍼스케일 프리미엄 시리즈 가용성을 참조하세요.
DC 시리즈
- DC 시리즈 하드웨어는 Intel SGX(Software Guard Extensions) 기술이 있는 Intel 프로세서를 사용합니다.
- DC 시리즈는 VBS(가상화 기반 보안) Enclave에 비해 하드웨어 Enclave의 더 강력한 보안 보호가 필요한 보안 Enclave 워크로드를 사용하는 Always Encrypted 에 필요합니다.
- DC 시리즈는 보안 enclave를 사용하여 Always Encrypted에서 제공하는 중요한 데이터를 처리하고 기밀 쿼리 처리 기능을 요구하는 워크로드용으로 설계되었습니다.
- DC 시리즈 하드웨어는 균형 잡힌 컴퓨팅 및 메모리 리소스를 제공합니다.
DC 시리즈는 프로비전된 컴퓨팅에 대해서만 지원되며(서버리스가 지원되지 않음) 영역 중복성을 지원하지 않습니다. DC 시리즈를 사용할 수 있는 지역의 경우 DC 시리즈 가용성을 참조하세요.
DC 시리즈에서 지원하는 Azure 제품 유형
DC 시리즈 하드웨어에서 데이터베이스 또는 탄력적 풀을 만들려면 구독은 종량제 또는 EA(기업계약)You-Go 를 포함한 유료 제품 유형이어야 합니다. DC 시리즈에서 지원하는 Azure 제품 유형의 전체 목록은 지출 한도 없이 현재 제품을 참조하세요.
하드웨어 구성 선택
만들 때 SQL Database에서 데이터베이스 또는 탄력적 풀에 대한 하드웨어 구성을 선택할 수 있습니다. 기존 데이터베이스 또는 탄력적 풀의 하드웨어 구성을 변경할 수도 있습니다.
SQL Database 또는 풀을 만들 때 하드웨어 구성을 선택하려면
자세한 내용은 SQL Database 만들기를 참조하세요.
기본 사항 탭의 컴퓨팅 + 스토리지 섹션에서 데이터베이스 구성 링크를 선택한 다음, 구성 변경 링크를 선택합니다.

원하는 하드웨어 구성을 선택합니다.

기존 SQL Database 또는 풀의 하드웨어 구성을 변경하려면
데이터베이스의 경우 개요 페이지에서 가격 책정 계층 링크를 선택합니다.

풀의 경우 개요 페이지에서 구성을 선택합니다.
단계에 따라 구성을 변경하고 이전 단계에서 설명한 대로 하드웨어 구성을 선택합니다.
하드웨어 가용성
현재 세대 하드웨어 가용성에 대한 자세한 내용은 Azure SQL Database에 대한 지역별 기능 가용성을 참조하세요.
이전 세대 하드웨어
Fsv2 시리즈
Azure SQL Database용 Fsv2 시리즈 하드웨어는 2026년 10월 1일에 사용 중지됩니다. 서비스 중단을 최소화하고 가격 성능을 유지하려면 하이퍼스케일 프리미엄 시리즈 또는 Gen5(표준 시리즈) 하드웨어로 전환합니다. 자세한 내용은 사용 중지 알림: Azure SQL Database FSV2 시리즈 제품을 참조하세요. 대부분의 데이터베이스 및 워크로드의 경우 하이퍼스케일 프리미엄 시리즈 또는 Gen5(표준 시리즈) 하드웨어는 Fsv2보다 유사하거나 더 나은 가격 성능을 제공합니다. 확인하려면 특정 데이터베이스 및 워크로드에서 유효성을 검사하세요.
- Fsv2는 다른 하드웨어보다 메모리 및
tempdbvCore당 메모리를 적게 제공하므로 이러한 제한에 민감한 워크로드는 표준 시리즈(Gen5)에서 더 나은 성능을 발휘할 수 있습니다. - Fsv2 시리즈는 범용 계층에서만 지원됩니다.
Gen4
Gen4 하드웨어가 사용 중지되었으며 프로비전, 업 스케일링 또는 다운스컬링에는 사용할 수 없습니다. 더 넓은 범위의 vCore 및 스토리지 확장성, 가속화된 네트워킹, 최고의 IO 성능, 최소 지연 시간을 위해 데이터베이스를 지원되는 하드웨어 세대로 마이그레이션합니다. 단일 데이터베이스에 대한 하드웨어 옵션 및탄력적 풀에 대한 하드웨어 옵션을 검토합니다. 자세한 내용은 Azure SQL 데이터베이스의 Gen4 하드웨어에 대한 지원 종료를 참조하세요.