적용 대상:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 Azure SQL Managed Instance와 함께 사용할 모범 사례 및 권장 사항과 함께 장애 조치(failover) 그룹 기능에 대한 개요를 제공합니다. 장애 조치(failover) 그룹 기능을 사용하면 SQL 관리형 인스턴스의 모든 사용자 데이터베이스를 다른 Azure 지역으로 복제 및 장애 조치(failover)할 수 있습니다.
시작하려면 Azure SQL Managed Instance에 대한 장애 조치(failover) 그룹 구성을 검토합니다.
개요
장애 조치(failover) 그룹 기능을 사용하면 한 SQL 관리형 인스턴스에서 다른 Azure 지역의 다른 SQL 관리형 인스턴스로 사용자 데이터베이스의 복제 및 장애 조치(failover)를 관리할 수 있습니다. 장애 조치(failover) 그룹은 지역 복제된 데이터베이스의 배포 및 관리를 대규모로 간소화하도록 설계되었습니다.
자세한 내용은 Azure SQL Managed Instance 고가용성을 참조하세요. 지오-페일오버 RPO 및 RTO에 대한 내용은 비즈니스 연속성 개요를 참조하세요.
엔드포인트 리디렉션
장애 조치 그룹은 지리적 장애 조치 중에 변경되지 않는 읽기-쓰기 및 읽기 전용 수신기 엔드포인트를 제공합니다. 연결이 자동으로 현재 기본 서버로 라우팅되기 때문에 지리적 장애 조치 후에 애플리케이션에 대한 연결 문자열을 변경할 필요가 없습니다. 지역 장애 조치(failover)는 그룹의 모든 보조 데이터베이스를 주 역할을 담당하게 전환합니다. 지역 장애 조치(failover)가 완료되면 엔드포인트를 새 지역으로 리디렉션하도록 DNS 레코드가 자동으로 업데이트됩니다.
읽기 전용 워크로드 부하 분산
주 데이터베이스에 대한 트래픽을 줄이기 위해 장애 조치(failover) 그룹의 보조 데이터베이스를 사용하여 읽기 전용 워크로드를 오프로드할 수도 있습니다. 읽기 전용 수신기를 사용하여 읽기 전용 트래픽을 읽기 가능한 보조 데이터베이스로 보냅니다.
애플리케이션 복구
완전한 비즈니스 연속성을 달성하기 위해 지역 데이터베이스 중복성을 추가하는 것은 솔루션의 일부일 뿐입니다. 치명적인 오류 후 애플리케이션(서비스) 엔드투엔드 복구에는 서비스 및 모든 종속성 서비스를 구성하는 모든 구성 요소의 복구가 필요합니다. 이러한 구성 요소의 예에는 클라이언트 소프트웨어(예: 사용자 지정 JavaScript를 사용한 브라우저), 웹 프런트 엔드, 스토리지 및 DNS가 포함됩니다. 모든 구성 요소는 동일한 오류에 탄력적이며 애플리케이션의 RTO(복구 시간 목표) 내에서 사용할 수 있는 것이 중요합니다. 따라서 모든 종속 서비스를 확인하고 그들이 제공하는 보장 사항과 기능을 이해해야 합니다. 그런 다음 당신이 의존하는 서비스의 장애 조치 중에도 서비스가 기능을 발휘하도록 적절한 단계를 수행해야 합니다.
장애 조치 정책
장애 조치 그룹은 두 개의 장애 조치 정책을 지원합니다.
-
고객 관리(권장) - 고객이 장애 조치(failover) 그룹의 하나 이상의 데이터베이스에 영향을 미치는 예기치 않은 중단을 발견하면 그룹의 장애 조치(failover)를 수행할 수 있습니다. PowerShell, Azure CLI 또는 Rest API와 같은 명령줄 도구를 사용하는 경우 고객 관리 장애 조치(failover) 정책 값은
manual입니다. -
Microsoft 관리 - 주 지역에 영향을 주는 광범위한 중단이 발생하는 경우 Microsoft는 장애 조치(failover) 정책을 Microsoft 관리로 구성한 영향을 받은 모든 장애 조치(failover) 그룹의 장애 조치(failover)를 시작합니다. Microsoft에서 관리하는 장애 조치는 개별 장애 조치 그룹이나 지역 내 일부 장애 조치 그룹에 대해 시작되지 않습니다. PowerShell, Azure CLI 또는 Rest API와 같은 명령줄 도구를 사용하는 경우, Microsoft 관리 장애 조치(failover) 정책 값은
automatic입니다.
각 장애 조치(failover) 정책에는 다음 테이블에서 요약한 대로 장애 조치(failover) 범위 및 데이터 손실에 대한 고유한 사용 사례 집합과 해당 기대 사항이 있습니다.
| 장애 조치 정책 | 장애 조치(failover) 범위 | 사용 사례 | 잠재적 데이터 손실 |
|---|---|---|---|
| 고객 관리형 (권장) |
장애 조치 그룹 | 장애 조치(failover) 그룹에 있는 하나 이상의 데이터베이스가 중단의 영향을 받아 사용할 수 없게 됩니다. 장애 조치(failover)를 선택할 수 있습니다. | 예 |
| Microsoft에서 관리 | 지역의 모든 장애 조치 그룹 | 지역에서 광범위한 중단으로 인해 데이터베이스를 사용할 수 없게 되며 Microsoft Azure SQL 서비스 팀은 강제 장애 조치(failover)를 트리거하기로 결정합니다. 애플리케이션은 1시간 이상의 RTO(가동 중지 시간)를 허용하고 재해 복구 책임을 Microsoft에 위임하려는 경우에만 이 옵션을 사용합니다. Microsoft 관리 장애 조치(failover)는 극단적인 상황에서만 실행될 수 있습니다. 고객이 직접 관리하는 장애 조치(failover) 정책을 강력히 권장합니다. |
예 |
고객 관리형
드문 경우지만 기본 제공 가용성 또는 고가용성 만으로는 중단을 완화할 수 없으며, 데이터베이스를 사용하는 애플리케이션의 SLA(서비스 수준 계약)에서 허용되지 않는 기간 동안 장애 조치(failover) 그룹의 데이터베이스를 사용할 수 없는 경우가 있습니다. 일부 데이터베이스에만 영향을 미치는 지역화된 문제로 인해 데이터베이스를 사용할 수 없거나 데이터 센터, 가용성 영역 또는 지역 수준에 존재할 수 있습니다. 이러한 경우에서 비즈니스 연속성을 복원하기 위해 강제 장애 조치(failover)를 시작할 수 있습니다.
장애 조치(failover) 정책을 고객 관리형으로 설정하는 것이 좋습니다. 장애 조치(failover)를 시작하고 비즈니스 연속성을 복원할 시기를 제어할 수 있기 때문입니다. 장애 조치(failover) 그룹에 있는 하나 이상의 데이터베이스에 영향을 주는 예기치 않은 가동 중단이 발견되면 장애 조치(failover)를 시작할 수 있습니다.
Microsoft에서 관리
Microsoft 관리 장애 조치(failover) 정책을 통해 재해 복구 책임이 Azure SQL 서비스로 위임됩니다. Azure SQL 서비스가 강제 장애 조치(failover)를 시작하려면 다음 조건을 충족해야 합니다.
- 자연 재해 이벤트, 구성 변경, 소프트웨어 버그 또는 하드웨어 구성 요소 오류 및 해당 지역의 많은 데이터베이스로 인한 지역 수준 중단이 영향을 받습니다.
- 유예 기간이 만료되었습니다. 가동 중단 규모와 완화 정도를 확인하려면 사람이 작업해야 하므로 유예 기간을 1시간 미만으로 설정할 수 없습니다.
이러한 조건이 충족되면 Azure SQL 서비스는 장애 조치(failover) 정책이 Microsoft 관리로 설정된 지역의 모든 장애 조치(failover) 그룹에 대해 강제 장애 조치(failover)를 시작합니다.
중요한
고객 관리 장애 조치(failover) 정책을 사용하여 재해 복구 계획을 테스트하고 구현합니다. 극단적인 상황에서만 Microsoft에서 실행할 수 있는 Microsoft 관리 장애 조치(failover)에 의존하지 마세요. Microsoft 관리 장애 조치(failover) 정책이 Microsoft 관리형으로 설정된 지역의 모든 장애 조치(failover) 그룹에 대해 Microsoft 관리 장애 조치(failover)가 시작됩니다. 개별 장애 조치(failover) 그룹에 대해 시작할 수 없습니다. 장애 조치(failover) 그룹을 선택적으로 장애 조치(failover)해야 하는 경우 고객 관리 장애 조치(failover) 정책을 사용합니다.
"다음 경우에만 장애 조치(failover) 정책을 Microsoft에서 관리하는 것으로 설정합니다:"
- 재해 복구 책임을 Azure SQL 서비스에 위임하려고 합니다.
- 애플리케이션에서 데이터베이스를 1시간 이상 사용할 수 없는 상황을 허용합니다.
- 강제 장애 조치(failover)의 실제 시간이 크게 달라질 수 있으므로 유예 기간이 만료된 후 일정 시간 동안 강제 장애 조치(failover)를 트리거할 수 있습니다.
- 장애 조치 그룹에 포함된 모든 데이터베이스는 영역 중복 구성이나 가용성 상태와 관계없이 장애 조치가 가능합니다. 영역 중복을 위해 구성된 데이터베이스는 영역 오류에 대해 독립적이며 가동 중단의 영향을 받지 않을 수 있지만, Microsoft 관리 장애 조치 정책을 통해 장애 조치 그룹에 속한 경우에도 장애 조치를 수행합니다.
- 애플리케이션에서 사용하는 다른 Azure 서비스 또는 구성 요소에 대한 애플리케이션의 종속성을 고려하지 않고 장애 조치(failover) 그룹의 데이터베이스를 강제 장애 조치(failover)할 수 있으며, 이로 인해 애플리케이션의 성능이 저하되거나 사용 불가능하게 될 수 있습니다.
- 강제 장애 조치(failover)의 정확한 시간을 제어할 수 없고 보조 데이터베이스의 동기화 상태를 무시하므로 알 수 없는 양의 데이터 손실이 발생할 수 있습니다.
- 장애 조치(failover) 그룹의 주 복제본과 보조 복제본은 동일한 서비스 계층, 컴퓨팅 계층 및 컴퓨팅 크기를 갖습니다.
Microsoft에서 장애 조치를 트리거하면 Azure SQL 장애 조치 그룹 작업 이름 항목이 Azure Monitor 활동 로그에 추가됩니다. 이 항목은 리소스 아래에 장애 조치(failover) 그룹 이름을 포함하고 이벤트 시작 위치에서는 Microsoft에서 장애 조치(failover)를 시작했음을 나타내기 위해 단일 하이픈(-)이 표시됩니다. 이 정보는 Azure Portal에서 새 주 서버 또는 인스턴스의 활동 로그 페이지에서도 찾을 수 있습니다.
용어 및 기능
FOG(장애 조치 그룹)
장애 조치(failover) 그룹을 사용하면 주 리전의 중단으로 인해 주 SQL 관리형 인스턴스를 사용할 수 없게 될 경우, SQL 관리형 인스턴스 내의 모든 사용자 데이터베이스가 하나의 단위로 다른 Azure 리전으로 장애 조치(failover)할 수 있습니다. SQL Managed Instance의 장애 조치(failover) 그룹에는 인스턴스 내의 모든 사용자 데이터베이스가 포함되므로 한 인스턴스에 하나의 장애 조치(failover) 그룹만 구성할 수 있습니다.
중요한
장애 조치 그룹의 이름은
.database.windows.net도메인에서 전역적으로 고유해야 합니다.기본
장애 조치(failover) 그룹의 주 데이터베이스를 호스트하는 SQL 관리형 인스턴스입니다.
부차적인
장애 조치(failover) 그룹에서 보조 데이터베이스를 호스트하는 SQL 관리형 인스턴스입니다. 보조는 주 데이터베이스와 동일한 Azure 지역에 있을 수 없습니다.
중요한
메모리 내 OLTP 개체가 데이터베이스에 포함된 경우 메모리 내 OLTP 개체는 항상 메모리에서 상주하기 때문에 주 및 보조 지역 복제본 인스턴스에서 서비스 계층이 일치해야 합니다. 지역 복제 인스턴스의 서비스 계층이 낮아 메모리 부족 문제가 발생할 수 있습니다. 이 경우 보조 복제본에서 데이터베이스를 복구하지 못하여 보조 데이터베이스를 지역 보조 데이터베이스의 메모리 내 OLTP 개체와 함께 사용할 수 없습니다. 결과적으로 장애 조치(failover)가 실패할 수도 있습니다. 이를 방지하려면 지역 보조 인스턴스의 서비스 계층이 주 인스턴스의 서비스 계층과 일치해야 합니다. 서비스 계층 업그레이드는 데이터 크기 작업일 수 있으며 완료하는 데 시간이 걸릴 수 있습니다.
장애 조치(데이터 손실 없음)
장애 조치(failover)는 보조 역할이 주 역할로 전환되기 전에 주 데이터베이스와 보조 데이터베이스 간에 전체 데이터 동기화를 수행합니다. 이렇게 하면 데이터 손실이 발생하지 않습니다. 장애 조치(failover)는 주 서버에 액세스할 수 있는 경우에만 가능합니다. 장애 조치(failover)는 다음과 같은 시나리오에서 사용됩니다.
- 데이터 손실이 허용되지 않을 때 프로덕션에서 DR(재해 복구) 연습 수행
- 워크로드를 다른 지역으로 재배치
- 가동 중단이 완화된 후 워크로드를 주 지역으로 반환(장애 복구(failback))
강제 장애 조치(데이터 손실 가능성)
강제 장애 조치는 주 역할의 최근 변경이 전파되기를 기다리지 않고 즉시 보조 역할을 주 역할로 전환합니다. 이 작업으로 인해 데이터가 손실될 수 있습니다. 강제 장애 조치(failover)는 주 장치에 액세스할 수 없을 때 장애 발생 시 복구 방법으로 활용됩니다. 중단이 완화되면 이전 주 데이터베이스는 자동으로 다시 연결되고 새로운 보조 데이터베이스가 됩니다. 장애 조치(failover)를 실행하여 장애 복구하고, 복제본을 원래 주 역할 및 보조 역할로 되돌릴 수 있습니다.
데이터 손실이 있는 유예 기간
데이터가 비동기 복제를 사용하여 보조 위치에 복제되므로 Microsoft 관리 장애 조치(failover) 정책을 사용하는 그룹의 강제 장애 조치(failover) 시 데이터가 손실될 수 있습니다. 애플리케이션의 데이터 손실 허용 오차를 반영하도록 장애 조치(failover) 정책을 사용자 지정할 수 있습니다.
GracePeriodWithDataLossHours를 구성하면 데이터 손실을 초래할 수 있는 강제 장애 조치(failover)가 시작될 때까지 Azure SQL 서비스가 대기하는 시간을 제어할 수 있습니다.
DNS 영역
새 SQL Managed Instance를 만들 때 자동으로 생성되는 고유 ID입니다. 이 인스턴스의 다중 도메인(SAN) 인증서는 같은 DNS 영역의 인스턴스에 대한 클라이언트 연결을 인증하기 위해 프로비저닝됩니다. 동일한 장애 조치(failover) 그룹의 두 SQL 관리형 인스턴스는 DNS 영역을 공유해야 합니다.
페일오버 그룹 읽기-쓰기 수신기
현재 주 지역을 가리키는 DNS CNAME 레코드입니다. 장애 조치 그룹이 생성될 때 자동으로 생성되며, 장애 조치 후 주 데이터베이스 서버가 변경되면 읽기-쓰기 작업 부하는 주 데이터베이스 서버에 투명하게 다시 연결할 수 있습니다. SQL 관리형 인스턴스에서 장애 조치(failover) 그룹을 만들면 수신기 URL에 대한 DNS CNAME 레코드가 다음과 같이
<fog-name>.<zone_id>.database.windows.net구성됩니다.장애 조치 그룹의 읽기 전용 수신기
현재 보조 서버를 가리키는 DNS CNAME 레코드입니다. 장애 조치(failover) 그룹이 생성될 때 자동으로 생성되며, 장애 조치 후에 보조 데이터베이스가 바뀌면 읽기 전용 SQL 워크로드가 보조 데이터베이스에 자동으로 연결할 수 있습니다. SQL 관리형 인스턴스에서 장애 조치(failover) 그룹을 만들면 수신기 URL에 대한 DNS CNAME 레코드가 다음과 같이
<fog-name>.secondary.<zone_id>.database.windows.net구성됩니다. 기본적으로 읽기 전용 수신기의 장애 조치 전환은 보조 서버가 오프라인일 때 주 서버의 성능에 영향을 주지 않도록 비활성화됩니다. 그러나 보조 서버가 복구될 때까지 읽기 전용 세션이 연결할 수 없음을 의미합니다.
장애 조치(failover) 그룹 아키텍처
장애 조치(failover) 그룹은 주 인스턴스에서 구성되어야 하며 다른 Azure 지역의 보조 인스턴스에 연결해야 합니다. 주 인스턴스의 모든 사용자 데이터베이스는 보조 인스턴스에 복제됩니다. 시스템 데이터베이스 master 및 msdb는 복제되지 않습니다.
다음 다이어그램에서는 SQL 관리형 인스턴스 및 장애 조치(failover) 그룹을 사용하는 지역 중복 클라우드 애플리케이션의 일반적인 구성을 보여 줍니다.
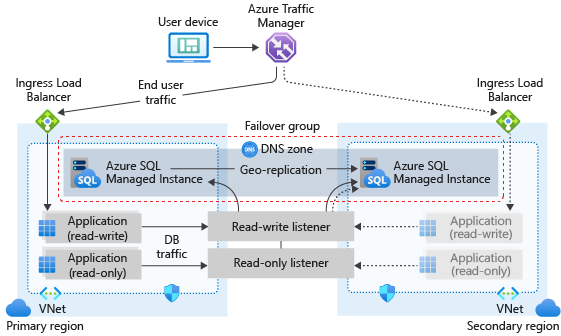
애플리케이션에서 SQL Managed Instance를 데이터 계층으로 사용하는 경우 비즈니스 연속성을 위해 설계할 때 이 문서에 설명된 일반 지침 및 모범 사례를 따릅니다.
지역 보조 인스턴스 만들기
장애 조치(failover) 후 주 SQL Managed Instance에 대한 중단 없는 연결을 보장하려면 주 인스턴스와 보조 인스턴스가 모두 동일한 DNS 영역에 있어야 합니다. 같은 다중 도메인(SAN) 인증서를 사용하여 장애 조치(failover) 그룹의 두 인스턴스 중 하나에 대한 클라이언트 연결을 인증할 수 있습니다. 애플리케이션이 프로덕션 배포에 사용할 준비가 되면 다른 지역에 보조 SQL Managed Instance를 만들고 주 SQL Managed Instance와 DNS 영역을 공유하는지 확인합니다. 인스턴스를 만들 때 선택적 매개 변수를 지정하여 이 작업을 수행할 수 있습니다. PowerShell 또는 REST API를 사용하는 경우 선택적 매개 변수의 이름은 DNSZonePartner입니다. Azure Portal에서 해당하는 선택적 필드의 이름은 기본 Managed Instance입니다.
중요한
서브넷에서 만든 첫 번째 SQL 관리형 인스턴스는 동일한 서브넷의 모든 후속 인스턴스에 대한 DNS 영역을 결정합니다. 즉, 같은 서브넷의 두 인스턴스는 서로 다른 DNS 영역에 속할 수 없습니다.
주 인스턴스와 같은 DNS 영역에서 보조 SQL Managed Instance를 생성하는 방법에 대한 자세한 내용은 Azure SQL Managed Instance에 대한 장애 조치(failover) 그룹 구성을 참조하세요.
쌍을 이루는 지역 사용
성능상의 이유로 두 SQL 관리형 인스턴스를 쌍을 이루는 지역에 배포합니다. 쌍을 이루는 지역의 SQL Managed Instance 장애 조치(failover) 그룹은 페어링되지 않은 지역에 비해 성능이 향상됩니다.
Azure SQL Managed Instance는 보통 Azure 쌍을 이루는 지역이 동시에 배포되지 않는 안전한 배포 사례를 따릅니다. 그러나 먼저 업그레이드되는 지역을 예측할 수 없으므로 배포 순서가 보장되지 않습니다. 경우에 따라 주 인스턴스가 먼저 업그레이드되기도 하고 보조 인스턴스가 먼저 업그레이드되기도 합니다.
Azure SQL Managed Instance가 장애 조치(failover) 그룹의 일부이고 그룹의 인스턴스가 Azure 쌍을 이루는 지역에 없는 경우 주 데이터베이스와 보조 데이터베이스에 대해 다른 유지 관리 기간 일정을 선택합니다. 예를 들어 지역 보조 데이터베이스의 유지 관리 기간은 평일로, 지역 주 데이터베이스의 유지 관리 기간은 주말로 선택합니다.
인스턴스 간 지역 복제 트래픽 흐름 사용 및 최적화
중단 없는 지역 복제 트래픽 흐름에 대해 주 인스턴스와 보조 인스턴스를 호스트하는 가상 네트워크 서브넷 간의 연결을 설정하고 유지 관리해야 합니다. 네트워크 토폴로지 및 정책에 따라 선택할 수 있는 인스턴스 간에 연결을 제공하는 방법에는 여러 가지가 있습니다.
장애 조치 그룹의 두 인스턴스 간에 연결을 설정할 때 글로벌 VNet 피어링(가상 네트워크 피어링)을 사용하면 좋습니다. Microsoft 백본 인프라를 사용하여 피어링된 가상 네트워크 사이에 대기 시간이 짧고 대역폭이 높은 프라이빗 연결을 제공합니다. 피어링된 가상 네트워크 간의 통신에 공용 인터넷, 게이트웨이, 또는 추가 암호화가 필요하지 않습니다.
초기 파종
SQL 관리형 인스턴스 간에 장애 조치(failover) 그룹을 설정하는 경우 데이터 복제가 시작되기 전에 초기 시드 단계가 있습니다. 초기 시드 단계는 가장 길고 비용이 많이 드는 작업입니다. 초기 시드가 완료되면 데이터가 동기화되고 후속 데이터 변경 내용만 복제됩니다. 초기 시드가 완료되는 데 걸리는 시간은 데이터 크기, 복제된 데이터베이스 수, 주 데이터베이스의 워크로드 강도 및 주 인스턴스와 보조 인스턴스를 호스트하는 가상 네트워크 간의 연결 속도에 따라 달라집니다. 이는 주로 연결 설정 방법에 따라 달라집니다. 정상적인 상황에서 권장되는 글로벌 가상 네트워크 피어링을 사용하여 연결이 설정된 경우 시드 속도는 SQL Managed Instance 시간당 최대 360GB입니다. 시드는 사용자 데이터베이스의 일괄 처리에 대해 병렬로 수행되지만 모든 데이터베이스에 대해 동시에 수행되는 것은 아닙니다. 인스턴스에 호스트되는 데이터베이스가 많은 경우 일괄 처리가 여러 번 필요할 수 있습니다.
두 인스턴스 간의 링크 속도가 필요한 속도보다 느리면 시드 시간에 큰 영향을 받을 수 있습니다. 명시된 시드 속도, 데이터베이스 수, 총 데이터 크기 및 연결 속도를 사용하여 데이터 복제가 시작되기 전에 초기 시드 단계가 걸리는 시간을 예측할 수 있습니다. 예를 들어, 단일 100GB 데이터베이스의 경우 링크가 시간당 84GB를 푸시할 수 있고 시드되는 다른 데이터베이스가 없으면 초기 시드 단계에 약 1.2시간이 걸립니다. 링크가 시간당 10GB만 전송할 수 있으면 100GB 데이터베이스를 시드하는 데 약 10시간이 걸립니다. 복제할 데이터베이스가 여러 대 있는 경우 시드가 병렬로 실행됩니다. 느린 링크 속도와 결합하면 초기 시드 단계가 상당히 오래 걸릴 수 있습니다. 특히 모든 데이터베이스의 데이터를 병렬로 시드하는 것이 사용 가능한 링크 대역폭을 초과하는 경우 더 오래 걸릴 수 있습니다.
중요한
초기 시드 단계는 매우 낮은 속도 또는 사용 중인 링크로 며칠이 걸릴 수 있습니다. 이 경우 장애 조치(failover) 그룹을 만드는 데 시간이 초과할 수 있습니다. 장애 조치(failover) 그룹 만들기는 6일 후에 자동으로 취소됩니다.
지역 보조 인스턴스로 지역 장애 조치(failover) 관리
장애 조치(failover) 그룹은 주 SQL 관리형 인스턴스에 있는 모든 데이터베이스의 지역 장애 조치(failover)를 관리합니다. 그룹을 만들면 인스턴스의 각 데이터베이스가 지역 보조 인스턴스에 자동으로 지역 복제됩니다. 장애 조치(failover) 그룹을 사용하여 데이터베이스 일부의 부분 장애 조치(failover)를 시작할 수 없습니다.
중요한
주 SQL 관리형 인스턴스에서 데이터베이스를 삭제하면 지역 보조 SQL 관리형 인스턴스에서도 데이터베이스가 자동으로 삭제됩니다.
읽기-쓰기 수신기(주 MI)를 사용하십시오.
읽기-쓰기 워크로드의 경우 서버 이름으로 <fog-name>.zone_id.database.windows.net을 사용합니다. 연결은 자동으로 주 서버로 전환됩니다. 이 이름은 장애 조치(failover) 후에 변경되지 않습니다. 지역 장애 조치(failover)에는 DNS 레코드 업데이트가 포함되므로 클라이언트 DNS 캐시를 새로 고친 후에만 새 클라이언트 연결이 새 주 복제본으로 라우팅됩니다. 보조 인스턴스는 주 인스턴스와 DNS 영역을 공유하므로 클라이언트 애플리케이션이 같은 서버 쪽 SAN 인증서를 사용하여 다시 연결할 수 있습니다. 기존 클라이언트 연결을 종료한 다음 다시 만들어 새 주 데이터베이스로 라우팅해야 합니다. 읽기-쓰기 수신기 및 읽기 전용 수신기는 SQL 관리형 인스턴스에 대한 퍼블릭 엔드포인트를 통해 연결할 수 없습니다.
읽기 전용 수신기 사용(보조 MI)
데이터 대기 시간을 허용하는 논리적으로 격리된 읽기 전용 워크로드가 있는 경우 지역 보조 데이터베이스에서 이러한 워크로드를 실행할 수 있습니다. 지역 보조 데이터베이스에 직접 연결하려면 서버 이름으로 <fog-name>.secondary.<zone_id>.database.windows.net을 사용합니다.
중요 비즈니스용 계층에서 SQL Managed Instance는 연결 문자열의 매개 변수를 사용하여 읽기 전용 쿼리 워크로드를 오프로드하도록 ApplicationIntent=ReadOnly 사용을 지원합니다. 지역 복제된 보조 데이터베이스를 구성한 경우 이 기능을 사용하여 주 위치 또는 지역 복제된 위치에 있는 읽기 전용 복제본에 연결할 수 있습니다.
- 주 위치의 읽기 전용 복제본에 연결하려면
ApplicationIntent=ReadOnly와<fog-name>.<zone_id>.database.windows.net을 사용합니다. - 보조 위치의 읽기 전용 복제본에 연결하려면
ApplicationIntent=ReadOnly와<fog-name>.secondary.<zone_id>.database.windows.net을 사용합니다.
읽기-쓰기 수신기 및 읽기 전용 수신기는 SQL 관리형 인스턴스에 대한 퍼블릭 엔드포인트를 통해 연결할 수 없습니다.
장애 조치 후 성능이 저하될 가능성
일반적인 Azure 애플리케이션은 여러 Azure 서비스를 사용하며 여러 구성 요소로 구성됩니다. 그룹의 지역 장애 조치(failover)는 Azure SQL 구성 요소의 상태에 따라서만 트리거됩니다. 중단은 주 지역의 다른 Azure 서비스에 영향을 미치지 않을 수 있으며 해당 구성 요소는 해당 지역에서 계속 사용할 수 있습니다. 주 데이터베이스가 보조 지역으로 전환되면 종속된 구성 요소 사이의 대기 시간이 늘어날 수 있습니다. 지역 간 대기 시간이 높아도 애플리케이션 성능에 영향을 주지 않도록 보조 지역에 있는 모든 애플리케이션 구성 요소의 중복성을 확인하고 데이터베이스와 함께 애플리케이션 구성 요소를 장애 조치(failover)합니다.
강제 장애 조치(failover) 후 데이터 손실 가능성
주 지역에서 중단이 발생하는 경우 최근 트랜잭션이 지역 보조에 복제되지 않았을 수 있으며 강제 장애 조치(failover)가 수행될 경우 데이터가 손실될 수 있습니다.
DNS 업데이트
읽기/쓰기 수신기의 DNS 업데이트는 장애 조치(failover)가 시작된 후 즉시 발생합니다. 이 작업으로 인해 데이터가 손실되지 않습니다. 그러나 데이터베이스 역할을 전환하는 프로세스는 정상적인 조건에서 최대 5분이 걸릴 수 있습니다. 완료될 때까지 새로운 주 인스턴스의 일부 데이터베이스는 계속 읽기 전용입니다. PowerShell을 사용하여 장애 조치를 시작하는 경우 주 복제본 역할을 전환하는 작업은 동기식입니다. Azure Portal을 사용하여 시작하는 경우 UI에 완료 상태가 표시됩니다. REST API를 사용하여 시작하는 경우, 표준 Azure Resource Manager의 폴링 메커니즘을 사용하여 완료되었는지 모니터링합니다.
중요한
지역 장애 조치(failover)를 유발한 중단이 완화된 후에는 수동 계획된 장애 조치(failover)를 사용하여 기본 위치를 다시 원래 위치로 다시 이동합니다.
라이선스가 없는 DR 복제본으로 비용 절감
DR(재해 복구)에만 사용할 보조 SQL 관리형 인스턴스를 구성하여 SQL Server 라이선스 비용을 절감할 수 있습니다. 이를 설정하려면 Azure SQL Managed Instance에 대한 라이선스가 필요 없는 대기 복제본(replica) 구성을 참조하세요.
보조 인스턴스가 읽기 워크로드에 사용되지 않는 한, Microsoft는 주 인스턴스와 일치하는 무료 vCore를 제공합니다. 보조 인스턴스에서 사용한 컴퓨팅 및 스토리지에 대한 요금은 계속 청구됩니다. 장애 조치(failover) 그룹은 하나의 복제본만 지원하며 복제본은 읽을 수 있는 복제본이거나 DR 전용 복제본으로 지정되어야 합니다.
시스템 데이터베이스의 개체에 종속된 시나리오 사용
시스템 데이터베이스는 장애 조치(failover) 그룹의 보조 인스턴스에 복제되지 않습니다. 시스템 데이터베이스의 개체에 의존하는 시나리오를 사용하도록 설정하려면 보조 인스턴스에서 동일한 개체를 만들어야 합니다. 주 인스턴스와 동기화된 상태로 유지합니다.
예를 들어 보조 인스턴스에서 동일한 로그인을 사용하려는 경우 동일한 SID로그인을 사용하여 만들어야 합니다.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
자세한 내용은 로그인 및 에이전트 작업의 복제를 참조하세요.
인스턴스 속성 및 보존 정책 인스턴스 동기화
장애 조치(failover) 그룹의 인스턴스는 Azure 리소스와 별도로 유지되며 주 인스턴스의 구성에 대한 변경 내용은 보조 인스턴스에 자동으로 복제되지 않습니다. 주 인스턴스와 보조 인스턴스 모두에서 모든 관련 변경 내용을 수행해야 합니다. 예를 들어 주 인스턴스에서 백업 스토리지 중복성 또는 장기 백업 보존 정책을 변경하는 경우 보조 인스턴스에서도 변경해야 합니다.
인스턴스 스케일링
주 인스턴스와 보조 인스턴스의 구성은 동일해야 합니다. 여기에는 컴퓨팅 크기, 스토리지 크기 및 서비스 계층이 포함됩니다. 장애 조치(failover) 그룹의 구성을 변경해야 하는 경우 각 인스턴스를 그에 따라 동일한 구성으로 확장하여 이 작업을 수행할 수 있습니다. 자세한 내용은 장애 조치(failover) 그룹에서 인스턴스 크기 조정을 검토합니다.
중요한 데이터 손실 방지
광역 네트워크의 높은 대기 시간으로 인해 지역 복제에는 비동기 복제 메커니즘이 사용됩니다. 비동기 복제를 사용하면 주 데이터베이스에서 오류가 발생할 때 데이터가 손실될 가능성이 있습니다. 데이터를 보호하는 방법을 알아보려면 데이터 손실 방지를 검토하세요.
장애 조치 그룹 상태
장애 조치 그룹은 데이터 복제의 현재 상태를 보고합니다.
- 시드: 초기 시드 는 모든 사용자 데이터베이스가 보조 인스턴스에서 초기화될 때까지 장애 조치(failover) 그룹을 만든 후에 발생합니다. 장애 조치(failover) 그룹이 시드 상태에 있는 동안에는 사용자 데이터베이스가 아직 보조 인스턴스에 복사되지 않으므로 장애 조치(failover)를 시작할 수 없습니다.
- 동기화: 장애 조치(failover) 그룹의 일반적인 상태입니다. 이는 주 인스턴스의 데이터 변경 내용이 보조 인스턴스에 비동기적으로 복제되는 중임을 의미합니다. 이 상태는 데이터가 매 순간 완전히 동기화된다는 것을 보장하지 않습니다. 장애 조치(failover) 그룹의 인스턴스 간 복제 프로세스의 비동기 특성으로 인해 기본 데이터의 변경 사항이 보조 데이터베이스에 아직 복제되지 않았을 수 있습니다. 장애 조치 그룹이 동기화 상태일 때 자동 및 수동 장애 조치가 모두 시작될 수 있습니다.
- 장애 조치 진행 중: 이 상태는 자동으로 또는 수동으로 시작된 장애 조치(failover)가 진행 중임을 나타냅니다. 장애 조치(failover) 그룹이 이 상태에 있는 동안에는 장애 조치 그룹에 대한 변경이나 추가 장애 조치를 시작할 수 없습니다.
장애 복구
Microsoft 관리 장애 조치(failover) 정책을 사용하여 장애 조치(failover) 그룹을 구성하면 설정된 유예 기간에 따라 재해 발생 시 지리적 보조 서버로 강제 장애 조치(failover)가 시작됩니다. 이전 기본 위치로의 장애 복구(failback)는 반드시 수동으로 시작해야 합니다.
기능 상호 운용성
백업들
전체 백업은 다음 시나리오에서 수행됩니다.
- 장애 조치(failover) 그룹을 만들 때 초기 시드가 시작되기 전에.
- 장애 조치 후.
전체 백업은 건너뛰거나 연기할 수 없는 데이터 작업의 크기로, 완료하는 데 다소 시간이 걸릴 수 있습니다. 완료하는 데 걸리는 시간은 데이터 크기, 데이터베이스 수 및 주 데이터베이스의 워크로드 강도에 따라 달라집니다. 전체 백업은 초기 데이터 전송을 눈에 띄게 지연시킬 수 있으며, 장애 조치 후 새 인스턴스에서 장애 조치 작업을 지연시키거나 방지할 수 있습니다.
다음을 고려하십시오.
- 장애 조치(failover) 그룹의 보조 인스턴스에서 호스트되는 데이터베이스는 장애 조치(failover) 후 또는 장애 조치(failover) 그룹이 삭제될 때까지 해당 인스턴스가 기본이 될 때까지 백업되지 않습니다.
- 장애 조치(failover) 후 데이터베이스가 주 역할로 변경되거나 장애 조치(failover) 그룹이 삭제된 후 독립 실행형이 되면 특정 시점 복원을 용이하게 하기 위해 전체 데이터베이스 백업이 자동으로 시작됩니다.
- 해당 인스턴스가 장애 조치(failover) 그룹의 보조 복제본인 경우 인스턴스에서 특정 시점으로 데이터베이스를 복원할 수 없습니다. 특정 시점으로 복원하려면 해당 시점 동안 주 인스턴스에서 데이터베이스를 복원해야 합니다.
- 동일한 SQL 관리형 인스턴스 쌍에서 삭제된 장애 조치(failover) 그룹을 다시 만들려면 장애 조치(failover) 그룹을 삭제한 후 모든 사용자 데이터베이스를 의도한 보조 데이터베이스에서 제거해야 합니다. 데이터베이스는 모든 보류 중인 백업 작업이 완료된 후에만 완전히 제거됩니다(데이터 크기 작업)를 수행하지 않은 경우 전체 백업을 포함합니다. 각 데이터베이스에 보류 중인 전체 백업 작업이 진행 중일 수 있으므로 매우 큰 데이터베이스가 있는 장애 조치(failover) 그룹을 삭제한 후 보조 인스턴스를 정리할 시간을 허용합니다.
전체 백업은 건너뛰거나 연기할 수 없고 완료하는 데 다소 시간이 걸릴 수 있는 데이터 작업의 크기입니다. 완료하는 데 걸리는 시간은 데이터 크기, 데이터베이스 수 및 주 데이터베이스의 워크로드 강도에 따라 달라집니다. 전체 백업은 초기 데이터 전송을 눈에 띄게 지연시킬 수 있으며, 장애 조치 직후 새 인스턴스에서 장애 조치 작업을 지연시키거나 실패하게 할 수 있습니다.
로그 재생 서비스
LRS(Log Replay Service)를 사용하여 Azure SQL Managed Instance로 마이그레이션된 데이터베이스는 컷오버 단계가 실행될 때까지 장애 조치(failover) 그룹에 추가할 수 없습니다. LRS를 사용하여 마이그레이션된 데이터베이스는 전환 시점까지 복원 중 상태이며, 복원 중 상태의 데이터베이스는 장애 조치 그룹에 추가할 수 없습니다. 복원 중인 상태의 데이터베이스를 사용하여 장애 조치(failover) 그룹을 만들려고 시도하면 데이터베이스 복원이 완료될 때까지 장애 조치(failover) 그룹 만들기가 지연됩니다.
트랜잭션 복제
장애 조치(failover) 그룹에 있는 인스턴스에서 트랜잭션 복제 사용이 지원됩니다. 그러나 SQL 관리형 인스턴스를 장애 조치(failover) 그룹에 추가하기 전에 복제를 구성하면 장애 조치(failover) 그룹을 만들기 시작하면 복제가 일시 중지됩니다. 복제 모니터의 상태가 Replicated transactions are waiting for the next log backup or for mirroring partner to catch up표시됩니다. 장애 조치(failover) 그룹이 성공적으로 생성되면 복제가 재개됩니다.
게시자 또는 배포자 SQL Managed Instance가 장애 조치(failover) 그룹에 있는 경우, 장애 조치(failover)가 발생한 후 SQL Managed Instance 관리자가 모든 게시를 이전 주 데이터베이스에서 정리하고 새로운 주 데이터베이스에서 다시 구성해야 합니다. 이 시나리오에서 필요한 활동의 단계는 트랜잭션 복제 가이드를 검토하세요.
권한 및 제한 사항
장애 조치 그룹을 구성하기 전에 권한 및 제한 사항 목록을 검토하세요.
프로그래밍 방식으로 장애 조치(failover) 그룹 관리
Azure PowerShell, Azure CLI 및 REST API를 사용하여 프로그래밍 방식으로 장애 조치(failover) 그룹을 관리할 수도 있습니다. 자세한 내용은 장애 조치(failover) 그룹 구성 을 검토하세요.
재해 복구 훈련
DR 훈련을 수행하는 권장 방법은 다음 튜토리얼(테스트 장애 조치(failover))에 따라 수동으로 계획된 장애 조치를 사용하는 것입니다.
강제 장애 조치(failover)를 사용하여 훈련을 수행하는 것은 권장되지 않습니다. 이 작업은 데이터 손실에 대한 가드레일을 제공하지 않기 때문에 권장되지 않습니다. 그럼에도 불구하고 강제 장애 조치(failover)를 시작하기 전에 다음 조건이 충족되도록 하여 데이터 손실 없는 강제 장애 조치(failover)를 수행할 수 있습니다.
- 기본 SQL 관리형 인스턴스에서 워크로드가 중지됩니다.
- 모든 장기 실행 트랜잭션이 완료되었습니다.
- 기본 SQL 관리형 인스턴스에 대한 모든 클라이언트 연결이 끊어졌습니다.
-
장애 조치(failover) 그룹 상태는
Synchronizing주 인스턴스와 보조 인스턴스 모두에 동일하게 적용됩니다.
두 개의 SQL 관리형 인스턴스가 역할을 전환했는지 확인하세요. 또한 필요에 따라 새 기본 SQL 관리형 인스턴스에 대한 연결을 설정하고 읽기/쓰기 작업을 시작하기 전에 장애 조치(failover) 그룹 상태가 '진행 중인 장애 조치(failover ) '에서 '동기화' 로 전환되었습니다.
원래 SQL 관리형 인스턴스 역할에 대한 데이터 손실 없는 장애 복구를 수행하려면 강제 장애 조치(failover) 대신 수동 계획된 장애 조치(failover)를 사용하는 것이 좋습니다.
강제적인 실패 복구가 사용되는 경우:
- 데이터 손실 없이 페일오버를 수행할 때와 동일한 단계를 따릅니다.
- 두 SQL 관리형 인스턴스에서 이전 강제 장애 조치(failover)가 성공하지 못한 경우 강제 장애 복구(failback)가 실패할 것으로 예상됩니다. 강제 장애 복구(failback)를 실행하기 전에, 두 인스턴스 모두에서 장애 조치(failover) 그룹 상태가
Synchronizing인지 확인합니다. - 이전 주 SQL 관리형 인스턴스에서 미해결 자동 백업 작업이 완료될 때까지 기다려야 하므로 초기 강제 장애 조치(failover)가 완료된 직후 강제 장애 복구(failback)가 실행될 경우 더 긴 장애 복구(failback) 실행 시간이 예상됩니다.
- 주 역할에서 보조 역할로 전환되는 인스턴스에 대한 미해결 자동 백업 작업은 이 인스턴스의 데이터베이스 가용성에 영향을 미칠 수 있습니다.
- 장애 조치(failover) 그룹 상태를 사용하여 두 인스턴스가 역할을 성공적으로 변경했으며 클라이언트 연결을 수락할 준비가 되었는지 확인하세요.