Azure Data Factory를 사용하여 Azure Files에서 또는 Azure Files로부터 데이터 복사
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 문서에서는 Azure Files에서 또는 Azure Files로 데이터를 복사하는 방법을 설명합니다. Azure Data Factory에 대해 자세히 알아보려면 소개 문서를 참조하세요.
지원되는 기능
이 Azure Files 커넥터는 다음 기능에 대해 지원됩니다.
| 지원되는 기능 | IR | 관리형 프라이빗 엔드포인트 |
|---|---|---|
| 복사 작업(원본/싱크) | ① ② | ✓ 스토리지 계정 V1 제외 |
| 조회 작업 | ① ② | ✓ 스토리지 계정 V1 제외 |
| GetMetadata 작업 | ① ② | ✓ 스토리지 계정 V1 제외 |
| 삭제 작업 | ① ② | ✓ 스토리지 계정 V1 제외 |
① Azure 통합 런타임 ② 자체 호스팅 통합 런타임
Azure Files에서 지원되는 싱크 데이터 저장소로 데이터를 복사하거나 지원되는 원본 데이터 저장소에서 Azure Files로 데이터를 복사할 수 있습니다. 복사 작업에서 원본 및 싱크로 지원되는 데이터 저장소의 목록은 지원되는 데이터 저장소 및 형식을 참조하세요.
특히 이 Azure Files 커넥터는 다음을 지원합니다.
- 계정 키 또는 서비스 SAS(공유 액세스 서명) 인증을 사용하여 파일을 복사합니다.
- 파일을 있는 그대로 복사하거나 지원되는 파일 형식 및 압축 코덱을 사용하여 파일을 붙여넣거나 생성합니다.
시작하기
파이프라인에 복사 작업을 수행하려면 다음 도구 또는 SDK 중 하나를 사용하면 됩니다.
UI를 사용하여 Azure Files에 연결된 서비스 만들기
다음 단계를 사용하여 Azure Portal UI에서 Azure Files에 연결된 서비스를 만듭니다.
Azure Data Factory 또는 Synapse 작업 영역에서 관리 탭으로 이동하여 연결된 서비스를 선택하고 새로 만들기를 클릭합니다.
파일을 검색하고 레이블이 Azure File Storage인 Azure Files 커넥터를 선택합니다.
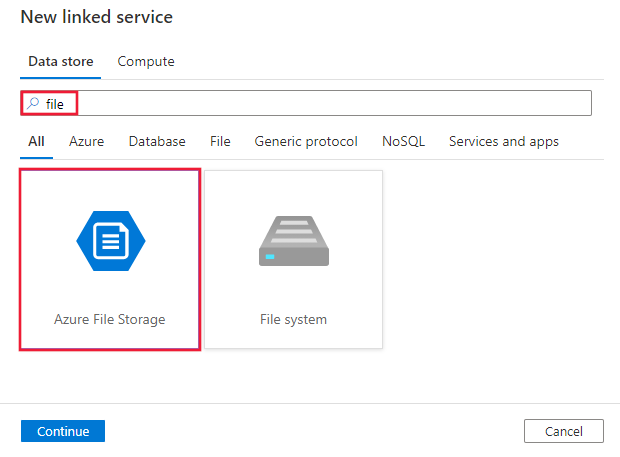
서비스 세부 정보를 구성하고, 연결을 테스트하고, 새로운 연결된 서비스를 만듭니다.
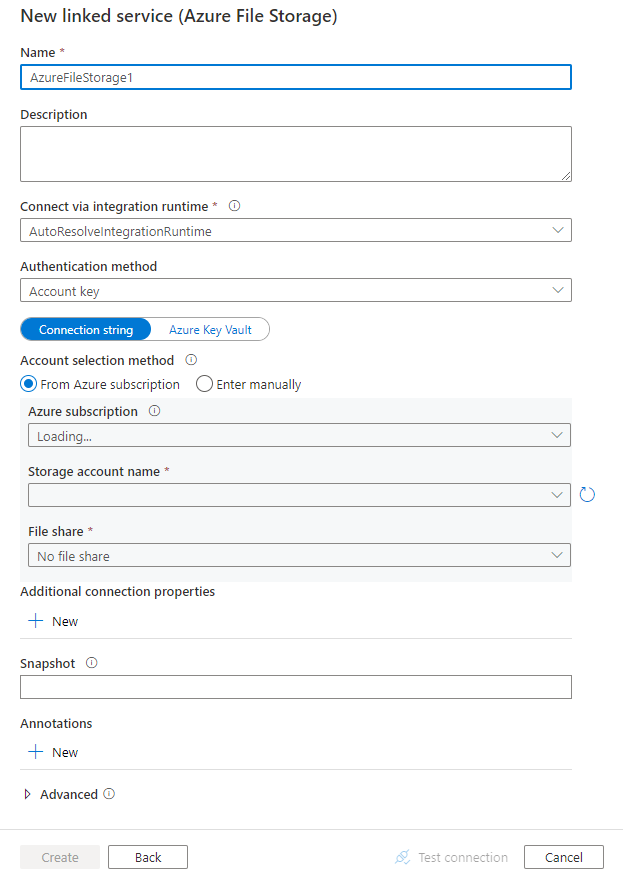
커넥터 구성 세부 정보
다음 섹션에서는 Azure Files와 관련된 엔터티를 정의하는 데 사용되는 속성에 대해 자세히 설명합니다.
연결된 서비스 속성
이 Azure Files 커넥터는 다음 인증 유형을 지원합니다. 자세한 내용은 해당 섹션을 참조하세요.
참고 항목
ADF 작성 UI에서 "기본 인증"으로 표시된 레거시 모델과 함께 Azure Files에 연결된 서비스를 사용하는 경우에는 있는 그대로 지원되지만 앞으로는 새 모델을 사용하는 것이 좋습니다. 레거시 모델은 SMB(서버 메시지 블록)를 통해 스토리지에서 데이터를 전송하고 새 모델은 처리량이 더 우수한 스토리지 SDK를 사용합니다. 업그레이드하려면 연결된 서비스를 편집하여 인증 방법을 "계정 키" 또는 "SAS URI"로 전환할 수 있습니다. 데이터 세트 또는 복사 작업에 변경이 필요하지 않습니다.
계정 키 인증
Data Factory는 Azure Files 계정 키 인증에 대해 다음 속성을 지원합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 AzureFileStorage로 설정되어야 합니다. | 예 |
| connectionString | Azure Files에 연결하는 데 필요한 정보를 지정합니다. Azure Key Vault에 계정 키를 넣고, 연결 문자열에서 accountKey 구성을 끌어올 수도 있습니다. 자세한 내용은 다음 샘플 및 Azure Key Vault에 자격 증명 저장 문서를 참조하세요. |
예 |
| fileShare | 파일 공유를 지정합니다. | 예 |
| snapshot (스냅샷) | 스냅샷에서 복사하려면 파일 공유 스냅샷의 날짜를 지정합니다. | 아니요 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. Azure Integration Runtime 또는 자체 호스팅 Integration Runtime을 사용할 수 있습니다(데이터 저장소가 프라이빗 네트워크에 있는 경우). 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
예제:
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net;",
"fileShare": "<file share name>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
예: Azure Key Vault에 계정 키 저장
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"fileShare": "<file share name>",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
공유 액세스 서명 인증
공유 액세스 서명은 스토리지 계정의 리소스에 대한 위임된 권한을 제공합니다. 공유 액세스 서명을 사용하여 스토리지 계정의 개체에 대해 지정된 시간 동안 제한된 권한을 클라이언트에 부여할 수 있습니다. 공유 액세스 서명에 대한 자세한 내용은 공유 액세스 서명: 공유 액세스 서명 모델 이해를 참조하세요.
서비스는 공유 액세스 서명 인증을 사용하기 위해 다음 속성을 지원합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 AzureFileStorage로 설정되어야 합니다. | 예 |
| sasUri | 리소스에 대한 공유 액세스 서명 URI를 지정합니다. 이 필드를 SecureString으로 표시하여 안전하게 저장합니다. SAS 토큰을 Azure Key Vault에 넣어 자동 회전을 사용하고 토큰 부분을 제거할 수도 있습니다. 자세한 내용은 다음 샘플 및 Azure Key Vault에 자격 증명 저장을 참조하세요. |
예 |
| fileShare | 파일 공유를 지정합니다. | 예 |
| snapshot (스냅샷) | 스냅샷에서 복사하려면 파일 공유 스냅샷의 날짜를 지정합니다. | 아니요 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. Azure Integration Runtime 또는 자체 호스팅 Integration Runtime을 사용할 수 있습니다(데이터 저장소가 프라이빗 네트워크에 있는 경우). 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
예제:
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the resource e.g. https://<accountname>.file.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
},
"fileShare": "<file share name>",
"snapshot": "<snapshot version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
예: Azure Key Vault에 SAS 토큰 저장
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.file.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
},
"fileShare": "<file share name>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
시스템이 할당한 관리 ID 인증
데이터 팩터리 또는 Synapse 파이프라인은 다른 Azure 서비스에 대한 인증을 위해 해당 리소스를 나타내는 Azure 리소스용 시스템 할당 관리 ID와 연결될 수 있습니다. Azure Files 인증에 시스템에서 할당한 이 관리 ID를 사용할 수 있습니다. Azure 리소스에 대한 관리 ID에 대한 자세한 내용은 Azure 리소스에 대한 관리 ID란?을 참조하세요.
시스템이 할당한 관리 ID 인증을 사용하려면 다음 단계를 수행합니다.
팩터리 또는 Synapse 작업 영역과 함께 생성된 시스템 할당 관리 ID 개체 ID 값을 복사하여 시스템 할당 관리 ID 정보를 검색합니다.
Azure Files에서 관리 ID 권한을 부여합니다. 역할에 대한 자세한 내용은 이 문서를 참조하세요.
- 원본의 경우 액세스 제어(IAM)에서 최소한 스토리지 파일 데이터 권한이 있는 읽기 권한자 역할을 부여합니다.
- 싱크의 경우 액세스 제어(IAM)에서 최소한 스토리지 파일 데이터 권한 있는 기여자 역할을 부여합니다.
Azure Files 연결된 서비스에서는 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 AzureFileStorage로 설정되어야 합니다. | 예 |
| serviceEndpoint | https://<accountName>.file.core.windows.net/ 패턴을 사용하여 Azure Files 서비스 엔드포인트를 지정합니다. |
예 |
| fileShare | 파일 공유를 지정합니다. | 예 |
| snapshot (스냅샷) | 스냅샷에서 복사하려면 파일 공유 스냅샷의 날짜를 지정합니다. | 아니요 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. Azure Integration Runtime을 사용할 수 있습니다. 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
참고 항목
시스템이 할당한 관리 ID 인증은 Azure 통합 런타임에서만 지원됩니다.
예제:
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.file.core.windows.net/",
"fileShare": "<file share name>",
"snapshot": "<snapshot version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
사용자가 할당한 관리 ID 인증
데이터 팩터리는 하나 이상의 사용자가 할당한 관리 ID로 할당할 수 있습니다. Azure Files 인증에 사용자가 할당한 관리 ID를 사용하면 Azure Files에 액세스하고 데이터를 복사할 수 있습니다. Azure 리소스에 대한 관리 ID에 대한 자세한 내용은 Azure 리소스에 대한 관리 ID란?을 참조하세요.
사용자가 할당한 관리 ID 인증을 사용하려면 다음 단계를 수행합니다.
사용자가 할당한 관리 ID를 하나 이상 만들고 Azure Files에서 권한을 부여합니다. 역할에 대한 자세한 내용은 이 문서를 참조하세요.
- 원본의 경우 액세스 제어(IAM)에서 최소한 스토리지 파일 데이터 권한이 있는 읽기 권한자 역할을 부여합니다.
- 싱크의 경우 액세스 제어(IAM)에서 최소한 스토리지 파일 데이터 권한 있는 기여자 역할을 부여합니다.
하나 이상의 사용자가 할당한 관리 ID를 데이터 팩터리에 할당하고 각 사용자가 할당한 관리 ID에 대한 자격 증명을 만듭니다.
Azure Files 연결된 서비스에서는 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 AzureFileStorage로 설정되어야 합니다. | 예 |
| serviceEndpoint | https://<accountName>.file.core.windows.net/ 패턴을 사용하여 Azure Files 서비스 엔드포인트를 지정합니다. |
예 |
| credentials | 사용자가 할당한 관리 ID를 자격 증명 개체로 지정합니다. | 예 |
| fileShare | 파일 공유를 지정합니다. | 예 |
| snapshot (스냅샷) | 스냅샷에서 복사하려면 파일 공유 스냅샷의 날짜를 지정합니다. | 아니요 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. Azure Integration Runtime 또는 자체 호스팅 Integration Runtime을 사용할 수 있습니다(데이터 저장소가 프라이빗 네트워크에 있는 경우). 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
예제:
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.file.core.windows.net/",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"fileShare": "<file share name>",
"snapshot": "<snapshot version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
레거시 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 AzureFileStorage로 설정되어야 합니다. | 예 |
| host | Azure Files 엔드포인트를 다음으로 지정합니다. -UI 사용: \\<storage name>.file.core.windows.net\<file service name> 지정- JSON 사용: "host": "\\\\<storage name>.file.core.windows.net\\<file service name>" |
예 |
| userId | Azure Files에 다음으로 액세스할 사용자를 지정합니다. -UI 사용: AZURE\<storage name> 지정- JSON 사용: "userid": "AZURE\\<storage name>" |
예 |
| password | 스토리지 액세스 키를 지정합니다. 이 필드를 SecureString으로 표시하여 Data Factory에 안전하게 저장하거나 Azure Key Vault에 저장되는 비밀을 참조합니다. | 예 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. Azure Integration Runtime 또는 자체 호스팅 Integration Runtime을 사용할 수 있습니다(데이터 저장소가 프라이빗 네트워크에 있는 경우). 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 원본에는 아니요이고 싱크에는 예입니다 |
예제:
{
"name": "AzureFileStorageLinkedService",
"properties": {
"type": "AzureFileStorage",
"typeProperties": {
"host": "\\\\<storage name>.file.core.windows.net\\<file service name>",
"userid": "AZURE\\<storage name>",
"password": {
"type": "SecureString",
"value": "<storage access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요.
Azure Data Factory는 다음과 같은 파일 형식을 지원합니다. 형식 기반 설정에 대한 각 문서를 참조하세요.
형식 기반 데이터 세트의 location 설정에서 Azure Files에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 location 아래의 type 속성은 AzureFileStorageLocation으로 설정되어야 합니다. |
예 |
| folderPath | 폴더에 대한 경로입니다. 와일드카드를 사용하여 폴더를 필터링하려면 이 설정을 건너뛰고 작업 원본 설정에서 지정합니다. | 아니요 |
| fileName | 지정된 folderPath 아래의 파일 이름입니다. 와일드카드를 사용하여 파일을 필터링하려면 이 설정을 건너뛰고 작업 원본 설정에서 지정합니다. | 아니요 |
예제:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure File Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureFileStorageLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
복사 작업 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 Azure Files 원본 및 싱크에서 지원하는 속성 목록을 제공합니다.
원본 파일 형태의 Azure Files
Azure Data Factory는 다음과 같은 파일 형식을 지원합니다. 형식 기반 설정에 대한 각 문서를 참조하세요.
형식 기반 복사 원본의 storeSettings 설정에서 Azure Files에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | storeSettings 아래의 type 속성은 AzureFileStorageReadSettings로 설정해야 합니다. |
예 |
| 복사할 파일 찾기: | ||
| 옵션 1: 정적 경로 |
데이터 세트에 지정된 폴더/파일 경로에서 복사합니다. 폴더의 모든 파일을 복사하려면 wildcardFileName을 *로 지정합니다. |
|
| 옵션 2: 파일 접두사 - 접두사 |
원본 파일을 필터링하기 위해 데이터 세트에 구성된 지정된 파일 공유 아래의 파일 이름에 대한 접두사입니다. 이름이 fileshare_in_linked_service/this_prefix로 시작하는 파일이 선택되었습니다. 와일드카드 필터보다 더 나은 성능을 제공하는 Azure Files에 대한 서비스측 필터를 사용합니다. 이 기능은 기존 링크 서비스 모델을 사용하는 경우 지원되지 않습니다. |
아니요 |
| 옵션 3: 와일드카드 - wildcardFolderPath |
원본 폴더를 필터링할 와일드카드 문자가 포함된 폴더 경로입니다. 허용되는 와일드카드는 *(0개 이상의 문자 일치) 및 ?(0-1개의 문자 일치)입니다. 실제 폴더 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^을 사용하여 이스케이프합니다. 더 많은 예는 폴더 및 파일 필터 예제를 참조하세요. |
아니요 |
| 옵션 3: 와일드카드 - wildcardFileName |
원본 파일을 필터링하기 위해 지정된 folderPath/wildcardFolderPath 아래의 와일드카드 문자가 포함된 파일 이름입니다. 허용되는 와일드카드는 *(0개 이상의 문자 일치) 및 ?(0-1개의 문자 일치)입니다. 실제 파일 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^을 사용하여 이스케이프합니다. 더 많은 예는 폴더 및 파일 필터 예제를 참조하세요. |
예 |
| 옵션 4: 파일 목록 - fileListPath |
지정된 파일 집합을 복사하도록 지정합니다. 복사할 파일 목록이 포함된 텍스트 파일을 가리키며, 데이터 세트에 구성된 경로에 대한 상대 경로를 사용하여 한 줄에 하나의 파일을 가리킵니다. 이 옵션을 사용하는 경우 데이터 세트에서 파일 이름을 지정하지 마세요. 파일 목록 예에서 더 많은 예를 참조하세요. |
아니요 |
| 추가 설정: | ||
| 재귀 | 하위 폴더 또는 지정된 폴더에서만 데이터를 재귀적으로 읽을지 여부를 나타냅니다. recursive를 true로 설정하고 싱크가 파일 기반 저장소인 경우 빈 폴더 또는 하위 폴더가 싱크에 복사되거나 만들어지지 않습니다. 허용되는 값은 true(기본값) 및 false입니다. fileListPath를 구성하는 경우에는 이 속성이 적용되지 않습니다. |
아니요 |
| deleteFilesAfterCompletion | 대상 저장소로 이동한 후에 원본 저장소에서 이진 파일을 삭제할지를 나타냅니다. 파일 삭제는 파일 단위로 이루어지므로 복사 작업에 실패하면 일부 파일은 대상에 복사되고 원본에서 삭제된 반면, 다른 파일은 원본 저장소에 계속 남아 있는 것을 확인할 수 있습니다. 이 속성은 이진 파일 복사 시나리오에서만 유효합니다. 기본값은 false입니다. |
아니요 |
| modifiedDatetimeStart | 마지막으로 수정한 특성에 따라 파일을 필터링합니다. 마지막 수정 시간이 modifiedDatetimeStart 이상 modifiedDatetimeEnd 미만인 경우 파일이 선택됩니다. 시간은 UTC 표준 시간대에 "2018-12-01T05:00:00Z" 형식으로 적용됩니다. 이 속성은 NULL일 수 있습니다. 즉, 데이터 세트에 파일 특성 필터가 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다. modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다.fileListPath를 구성하는 경우에는 이 속성이 적용되지 않습니다. |
아니요 |
| modifiedDatetimeEnd | 위와 동일합니다. | 아니요 |
| enablePartitionDiscovery | 분할된 파일의 경우 파일 경로에서 파티션을 구문 분석할지를 지정하고 추가 원본 열로 추가합니다. 허용되는 값은 false(기본값) 및 true입니다. |
아니요 |
| partitionRootPath | 파티션 검색을 사용하는 경우 분할된 폴더를 데이터 열로 읽도록 절대 루트 경로를 지정합니다. 지정되지 않은 경우 기본적으로 다음과 같이 지정됩니다. - 데이터 세트의 파일 경로 또는 원본의 파일 목록을 사용하는 경우 파티션 루트 경로는 데이터 세트에 구성된 경로입니다. - 와일드카드 폴더 필터를 사용하는 경우 파티션 루트 경로는 첫 번째 와일드카드 앞의 하위 경로입니다. 예를 들어 데이터 세트의 경로를 “root/folder/year=2020/month=08/day=27”로 구성한다고 가정합니다. - 파티션 루트 경로를 “root/folder/year=2020”으로 지정하는 경우 복사 작업은 파일 내의 열 외에도 각각 값이 “08” 및 “27”인 두 개의 열( month 및 day)을 생성합니다.- 파티션 루트 경로가 지정되지 않은 경우 추가 열이 생성되지 않습니다. |
아니요 |
| maxConcurrentConnections | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
예제:
"activities":[
{
"name": "CopyFromAzureFileStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureFileStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
싱크로서의 Azure Files
Azure Data Factory는 다음과 같은 파일 형식을 지원합니다. 형식 기반 설정에 대한 각 문서를 참조하세요.
형식 기반 복사 싱크의 storeSettings 설정에서 Azure Files에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | storeSettings 아래의 type 속성은 AzureFileStorageWriteSettings로 설정해야 합니다. |
예 |
| copyBehavior | 원본이 파일 기반 데이터 저장소의 파일인 경우 복사 동작을 정의합니다. 허용된 값은 다음과 같습니다. - PreserveHierarchy(기본값): 대상 폴더에서 파일 계층 구조를 유지합니다. 원본 폴더의 원본 파일 상대 경로는 대상 폴더의 대상 파일 상대 경로와 동일합니다. - FlattenHierarchy: 원본 폴더의 모든 파일이 대상 폴더의 첫 번째 수준에 있게 됩니다. 대상 파일은 자동 생성된 이름을 갖습니다. - MergeFiles: 원본 폴더의 모든 파일을 하나의 파일로 병합합니다. 파일 이름이 지정된 경우 병합되는 파일 이름은 지정된 이름입니다. 그렇지 않으면 자동 생성되는 파일 이름이 적용됩니다. |
아니요 |
| maxConcurrentConnections | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
예제:
"activities":[
{
"name": "CopyToAzureFileStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureFileStorageWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
폴더 및 파일 필터 예제
이 섹션에서는 와일드카드 필터가 있는 폴더 경로 및 파일 이름의 결과 동작에 대해 설명합니다.
| folderPath | fileName | 재귀 | 원본 폴더 구조 및 필터 결과(굵게 표시된 파일이 검색됨) |
|---|---|---|---|
Folder* |
(비어 있음, 기본값 사용) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(비어 있음, 기본값 사용) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
파일 목록 예
이 섹션에서는 복사 작업 원본에서 파일 목록 경로를 사용하는 경우의 결과 동작을 설명합니다.
원본 폴더 구조가 다음과 같고 굵게 표시된 파일을 복사하려는 것으로 가정합니다.
| 샘플 원본 구조 | FileListToCopy.txt의 콘텐츠 | 구성 |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 메타데이터 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
데이터 세트: - 폴더 경로: root/FolderA복사 작업 원본: - 파일 목록 경로: root/Metadata/FileListToCopy.txt 파일 목록 경로는 복사하려는 파일 목록이 포함된 동일한 데이터 저장소에 있는 텍스트 파일을 가리키며, 데이터 세트에 구성된 경로의 상대 경로를 사용하여 한 줄에 하나씩 파일을 가리킵니다. |
recursive 및 copyBehavior 예제
이 섹션에서는 다양한 recursive 및 copyBehavior 값 조합에 대한 복사 작업의 결과 동작을 설명합니다.
| 재귀 | copyBehavior | 원본 폴더 구조 | 결과 대상 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같이 원본 폴더와 동일한 구조로 만들어집니다. Folder1 File1 File2 Subfolder1 File3 File4 File5. |
| true | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같은 구조로 만들어집니다. Folder1 File1에 대해 자동 생성된 이름 File2에 대해 자동 생성된 이름 File3에 대해 자동 생성된 이름 File4에 대해 자동 생성된 이름 File5에 대해 자동 생성된 이름 |
| true | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같은 구조로 만들어집니다. Folder1 File1, File2, File3, File4 및 File5의 파일 내용이 자동 생성된 파일 이름을 사용하는 파일 하나로 병합됩니다. |
| false | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같은 구조로 만들어집니다. Folder1 File1 File2 File3, File4, File5를 가진 Subfolder1은 선택되지 않습니다. |
| false | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같은 구조로 만들어집니다. Folder1 File1에 대해 자동 생성된 이름 File2에 대해 자동 생성된 이름 File3, File4, File5를 가진 Subfolder1은 선택되지 않습니다. |
| false | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Folder1 대상 폴더가 다음과 같은 구조로 만들어집니다. Folder1 File1과 File2의 내용이 자동 생성된 파일 이름이 있는 하나의 파일로 병합됩니다. File1에 대해 자동 생성된 이름 File3, File4, File5를 가진 Subfolder1은 선택되지 않습니다. |
조회 작업 속성
속성에 대한 자세한 내용을 보려면 조회 작업을 확인하세요.
GetMetadata 작업 속성
속성에 대한 자세한 내용을 보려면 GetMetadata 작업을 확인하세요.
삭제 작업 속성
속성에 대한 자세한 내용을 보려면 삭제 작업을 확인하세요.
레거시 모델
참고 항목
다음 모델은 이전 버전과의 호환성을 위해 그대로 계속 지원됩니다. 앞의 섹션에서 설명한 새 모델을 사용하는 것이 좋습니다. 그러면 작성 UI가 새 모델을 생성하도록 전환됩니다.
레거시 데이터 세트 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 형식 속성을 FileShare로 설정해야 합니다. | 예 |
| folderPath | 파일의 경로입니다. 와일드카드 필터가 지원되며, 허용되는 와일드카드는 *(0개 이상의 문자 일치) 및 ?(0-1개의 문자 일치)입니다. 실제 폴더 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^을 사용하여 이스케이프합니다. 예: rootfolder/subfolder/(더 많은 예제는 폴더 및 파일 필터 예제 참조) |
예 |
| fileName | 지정된 "folderPath" 아래의 파일에 대한 이름 또는 와일드 카드 필터입니다. 이 속성의 값을 지정하지 않으면 데이터 세트는 폴더에 있는 모든 파일을 가리킵니다. 필터에 허용되는 와일드카드는 *(문자 0자 이상 일치) 및 ?(문자 0자 또는 1자 일치)입니다.- 예 1: "fileName": "*.csv"- 예 2: "fileName": "???20180427.txt"^을 사용하여 실제 파일 이름 내에 와일드카드 또는 이 이스케이프 문자가 있는 경우 이스케이프합니다.fileName이 출력 데이터 세트에 대해 지정되지 않고 preserveHierarchy가 작업 싱크에 지정되지 않으면, 복사 작업은 다음과 같은 패턴으로 파일 이름을 자동으로 생성합니다. "Data.[activity run ID GUID].[GUID if FlattenHierarchy].[format if configured].[compression if configured] ", 예: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz"; 쿼리 대신 테이블 이름을 사용하여 테이블 형식 원본에서 복사하면, 이름 패턴이 " [table name].[format].[compression if configured] "입니다(예: "MyTable.csv"). |
아니요 |
| modifiedDatetimeStart | 마지막으로 수정한 특성에 따라 파일을 필터링합니다. 마지막 수정 시간이 modifiedDatetimeStart 이상 modifiedDatetimeEnd 미만인 경우 파일이 선택됩니다. 시간은 UTC 표준 시간대에 "2018-12-01T05:00:00Z" 형식으로 적용됩니다. 많은 양의 파일에서 파일을 필터링하려는 경우 이 설정을 사용하면 데이터 이동의 전반적인 성능에 영향을 줄 수 있습니다. 속성은 NULL일 수 있습니다. 이 경우 파일 특성 필터가 데이터 세트에 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다. modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다. |
아니요 |
| modifiedDatetimeEnd | 마지막으로 수정한 특성에 따라 파일을 필터링합니다. 마지막 수정 시간이 modifiedDatetimeStart 이상 modifiedDatetimeEnd 미만인 경우 파일이 선택됩니다. 시간은 UTC 표준 시간대에 "2018-12-01T05:00:00Z" 형식으로 적용됩니다. 많은 양의 파일에서 파일을 필터링하려는 경우 이 설정을 사용하면 데이터 이동의 전반적인 성능에 영향을 줄 수 있습니다. 속성은 NULL일 수 있습니다. 이 경우 파일 특성 필터가 데이터 세트에 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다. modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다. |
아니요 |
| format | 파일 기반 저장소(이진 복사) 간에 파일을 있는 그대로 복사하려는 경우 입력 및 출력 데이터 세트 정의 둘 다에서 형식 섹션을 건너뜁니다. 특정 형식으로 파일을 생성하거나 구문 분석하려는 경우 TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat과 같은 파일 형식 유형이 지원됩니다. 이 값 중 하나로 서식에서 type 속성을 설정합니다. 자세한 내용은 텍스트 형식, Json 형식, Avro 형식, Orc 형식 및 Parquet 형식 섹션을 참조하세요. |
아니요(이진 복사 시나리오에만 해당) |
| 압축 | 데이터에 대한 압축 유형 및 수준을 지정합니다. 자세한 내용은 지원되는 파일 형식 및 압축 코덱을 참조하세요. 지원되는 형식은 GZip, Deflate, BZip2 및 ZipDeflate입니다. 지원되는 수준은 최적 및 가장 빠름입니다. |
아니요 |
팁
폴더 아래에서 모든 파일을 복사하려면 folderPath만을 지정합니다.
지정된 이름의 단일 파일을 복사하려면 폴더 부분으로 folderPath 및 파일 이름으로 fileName을 지정합니다.
폴더 아래에서 파일의 하위 집합을 복사하려면 폴더 부분으로 folderPath 및 와일드카드 필터로 fileName을 지정합니다.
참고 항목
파일 필터에 "fileFilter" 속성을 사용한 경우 그대로 계속 지원되지만, 이후 "fileName"에 추가된 새 필터 기능을 사용하도록 제안합니다.
예제:
{
"name": "AzureFileStorageDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<Azure File Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
레거시 복사 작업 원본 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 형식 속성을 FileSystemSource로 설정해야 합니다. | 예 |
| 재귀 | 하위 폴더에서 또는 지정된 폴더에서만 데이터를 재귀적으로 읽을지 여부를 나타냅니다. recursive가 true로 설정되고 싱크가 파일 기반 저장소인 경우 싱크에서 빈 폴더/하위 폴더가 복사/생성되지 않습니다. 허용되는 값은 true(기본값), false입니다. |
아니요 |
| maxConcurrentConnections | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
예제:
"activities":[
{
"name": "CopyFromAzureFileStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure File Storage input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
레거시 복사 작업 싱크 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 싱크의 type 속성은 FileSystemSink로 설정해야 합니다. | 예 |
| copyBehavior | 원본이 파일 기반 데이터 저장소의 파일인 경우 복사 동작을 정의합니다. 허용된 값은 다음과 같습니다. - PreserveHierarchy(기본값): 대상 폴더에서 파일 계층 구조를 유지합니다. 원본 폴더의 원본 파일 상대 경로는 대상 폴더의 대상 파일 상대 경로와 동일합니다. - FlattenHierarchy: 원본 폴더의 모든 파일은 대상 폴더의 첫 번째 수준에 있게 됩니다. 대상 파일은 자동 생성된 이름을 갖습니다. - MergeFiles: 원본 폴더의 모든 파일을 하나의 파일로 병합합니다. 파일 이름이 지정된 경우 지정된 이름이 병합된 파일 이름이 됩니다. 그렇지 않으면 자동 생성된 파일 이름이 병합된 파일 이름이 됩니다. |
아니요 |
| maxConcurrentConnections | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
예제:
"activities":[
{
"name": "CopyToAzureFileStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure File Storage output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
관련 콘텐츠
복사 작업에서 원본 및 싱크로 지원되는 데이터 저장소 목록은 지원되는 데이터 저장소를 참조하세요.