적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
이 문서에서는 HDFS(Hadoop 분산 파일 시스템) 서버에서 데이터를 복사하는 방법에 대해 설명합니다. 자세한 내용은 Azure Data Factory 및 Synapse Analytics 대한 소개 문서를 참조하세요.
지원되는 기능
이 HDFS 커넥터는 다음 기능에 대해 지원됩니다.
| 지원되는 기능 | 적외선 |
|---|---|
| Copy activity(source/-) | ① ② |
| 조회 작업 | ① ② |
| 삭제 작업 | ① ② |
(1) Azure 통합 런타임(2) 자체 호스팅 통합 런타임
특히 이 HDFS 커넥터는 다음을 지원합니다.
- Windows(Kerberos) 또는 Anonymous 인증을 사용하여 파일을 복사합니다.
- webhdfs 프로토콜 또는 기본 제공 DistCp 지원을 사용하여 파일을 복사합니다.
- 파일을 있는 그대로 복사하거나 지원되는 파일 형식 및 압축 코덱을 사용하여 파일을 구문 분석 또는 생성합니다.
필수 조건
데이터 저장소가 온-프레미스 네트워크, Azure 가상 네트워크 또는 Amazon Virtual Private Cloud 내에 있는 경우 자체 호스팅 통합 런타임 구성하여 연결해야 합니다.
데이터 저장소가 관리되는 클라우드 데이터 서비스인 경우 Azure Integration Runtime 사용할 수 있습니다. 액세스가 방화벽 규칙에서 승인된 IP로 제한되는 경우 허용 목록에 Azure Integration Runtime IP 추가할 수 있습니다.
Azure Data Factory 관리형 가상 네트워크 통합 런타임 기능을 사용하여 자체 호스팅 통합 런타임을 설치하고 구성하지 않고도 온-프레미스 네트워크에 액세스할 수 있습니다.
Data Factory에서 지원하는 네트워크 보안 메커니즘 및 옵션에 대한 자세한 내용은 데이터 액세스 전략을 참조하세요.
참고
Integration Runtime에서 Hadoop 클러스터의 모든 [이름 노드 서버]:[이름 노드 포트] 및 [데이터 노드 서버]:[데이터 노드 포트]에 액세스할 수 있는지 확인합니다. 기본 [이름 노드 포트]는 50070이며 기본 [데이터 노드 포트]는 50075입니다.
시작하기
파이프라인을 사용하여 복사 작업을 수행하려면 다음 도구 또는 SDK 중 하나를 사용할 수 있습니다.
UI를 사용하여 HDFS에 연결된 서비스 만들기
다음 단계를 사용하여 Azure 포털 UI에서 HDFS에 연결된 서비스를 만듭니다.
Azure Data Factory 또는 Synapse 작업 영역에서 관리 탭으로 이동하고 연결된 서비스를 선택한 다음 새로 만들기를 클릭합니다.
HDFS를 검색하고 HDFS 커넥터를 선택합니다.
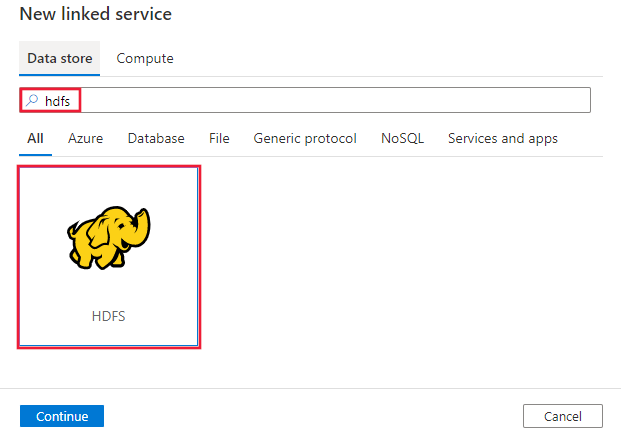
서비스 세부 정보를 구성하고, 연결을 테스트하고, 새로운 연결된 서비스를 만듭니다.
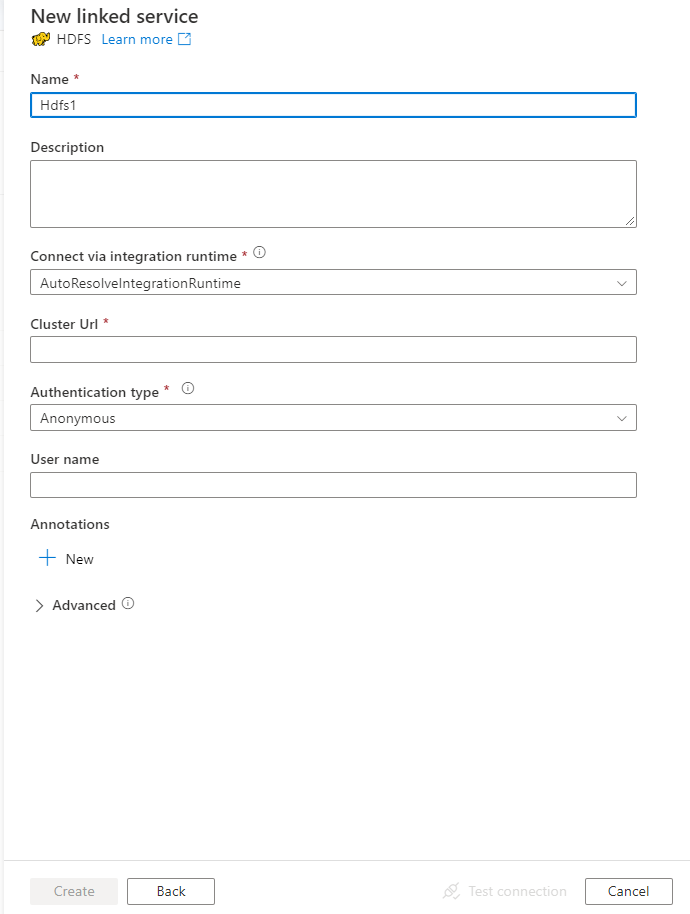
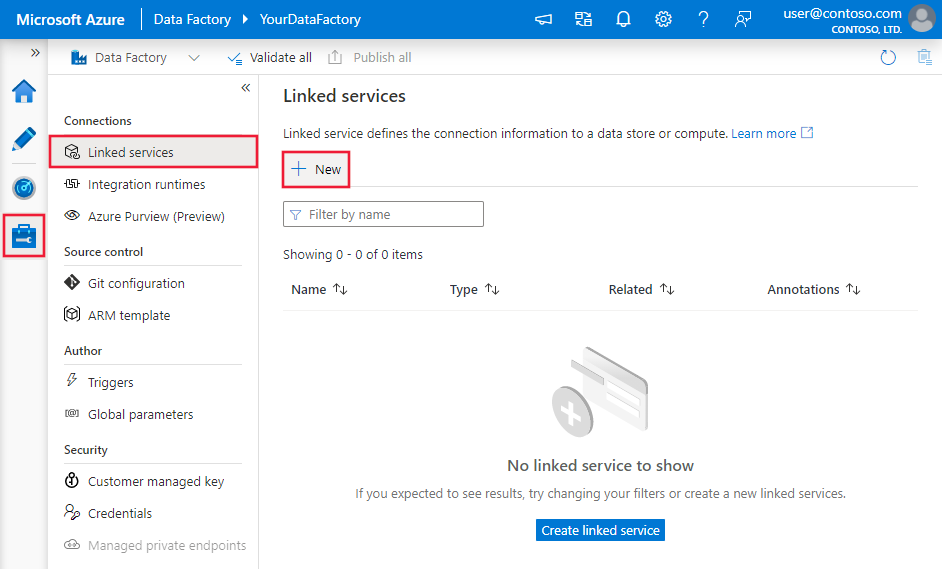
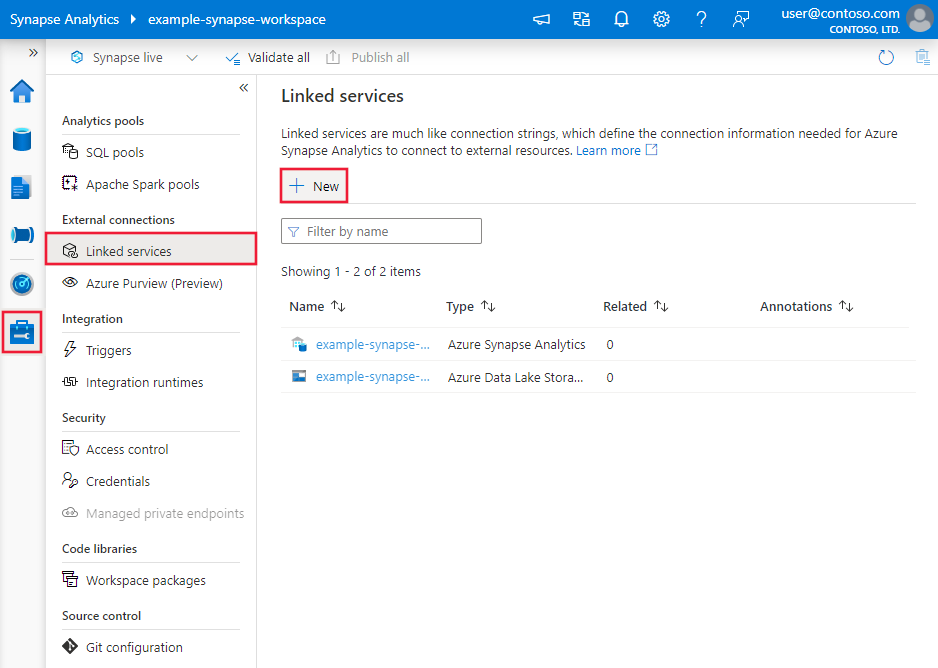
커넥터 구성 세부 정보
다음 섹션에서는 HDFS에 한정된 Data Factory 엔터티를 정의하는 데 사용되는 속성에 대해 자세히 설명합니다.
연결된 서비스 속성
HDFS 연결된 서비스에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 종류 | type 속성은 Hdfs로 설정해야 합니다. | 예 |
| URL | HDFS에 대한 URL | 예 |
| 인증 유형 | 허용되는 값은 Anonymous 또는 Windows입니다. 온-프레미스 환경을 설정하려면 HDFS 커넥터에 Kerberos 인증 사용 섹션을 참조하세요. |
예 |
| userName | Windows authentication 사용자 이름입니다. Kerberos 인증의 경우 <사용자 이름>@<domain>.com을 지정합니다. | 예 (윈도우 인증) |
| 비밀번호 | Windows authentication 암호입니다. 이 필드를 SecureString으로 표시하여 안전하게 저장하거나 Azure 키 자격 증명 모음에 저장된 비밀을 유추합니다. | 예(Windows 인증의 경우) |
| connectVia | 데이터 저장소에 연결하는 데 사용할 통합 런타임입니다. 자세한 내용은 사전 요구 사항 섹션을 참조하세요. integration runtime 지정되지 않은 경우 서비스는 기본 Azure Integration Runtime 사용합니다. | 아니요 |
예제: 익명 인증 사용
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
예시: Windows 인증 사용
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트를 참조하세요.
Azure Data Factory 다음 파일 형식을 지원합니다. 형식 기반 설정에 대한 각 문서를 참조하세요.
형식 기반 데이터 세트의 location 설정에서 HDFS에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 종류 | 데이터 세트의 아래 location 속성은 HdfsLocation으로 설정되어야 합니다. |
예 |
| 폴더 경로 | 파일 경로입니다. 와일드카드를 사용하여 폴더를 필터링하려면 이 설정을 건너뛰고 작업 원본 설정에서 경로를 지정합니다. | 아니요 |
| 파일 이름 | 지정된 folderPath 아래의 파일 이름입니다. 와일드카드를 사용하여 파일을 필터링하려면 이 설정을 건너뛰고 작업 원본 설정에서 파일 이름을 지정합니다. | 아니요 |
예제:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Copy activity 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 및 작업을 참조하세요. 이 섹션에서는 HDFS 원본에서 지원하는 속성의 목록을 제공합니다.
원본으로 HDFS
Azure Data Factory 다음 파일 형식을 지원합니다. 형식 기반 설정에 대한 각 문서를 참조하세요.
형식 기반 복사 원본의 storeSettings 설정에서 HDFS에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 종류 |
아래에 있는 storeSettings 속성은 HdfsReadSettings로 설정되어야 합니다. |
예 |
| 복사할 파일 찾기 | ||
| 옵션 1: 정적 경로 |
데이터 세트에 지정된 폴더나 파일 경로에서 복사합니다. 폴더의 모든 파일을 복사하려면 wildcardFileName을 *로 지정합니다. |
|
| 옵션 2: 와일드카드 - 와일드카드 폴더 경로 |
원본 폴더를 필터링할 와일드카드 문자가 포함된 폴더 경로입니다. 허용되는 와일드카드는 *(문자 0자 이상 일치) 및 ?(문자 0자 또는 1자 일치)입니다. 실제 폴더 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^를 사용하여 이스케이프합니다. 더 많은 예를 보려면 폴더 및 파일 필터 예를 참조하세요. |
아니요 |
| 옵션 2: 와일드카드 - 와일드카드파일이름 |
원본 파일을 필터링하기 위해 지정된 folderPath/wildcardFolderPath 아래의 와일드카드 문자가 포함된 파일 이름입니다. 허용되는 와일드카드는 *(0개 이상의 문자 일치) 및 ?(0~1개의 문자 일치)입니다. 실제 파일 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^을 사용하여 이스케이프합니다. 더 많은 예를 보려면 폴더 및 파일 필터 예를 참조하세요. |
예 |
| 옵션 3: 파일 목록 - 파일목록경로 (fileListPath) |
지정된 파일 집합을 복사하도록 나타냅니다. 복사할 파일 목록이 포함된 텍스트 파일을 가리킵니다(데이터 세트에 구성된 경로에 대한 상대 경로를 사용하여 한 줄에 하나의 파일). 이 옵션을 사용하는 경우 데이터 세트에서 파일 이름을 지정하지 마세요. 더 많은 예를 보려면 파일 목록 예를 참조하세요. |
아니요 |
| 추가 설정 | ||
| 재귀 | 하위 폴더 또는 지정된 폴더에서만 데이터를 재귀적으로 읽을지 여부를 나타냅니다.
recursive를 true로 설정하고 싱크가 파일 기반 저장소인 경우 빈 폴더 또는 하위 폴더가 싱크에 복사되거나 만들어지지 않습니다. 허용되는 값은 true(기본값) 및 false입니다. fileListPath를 구성하는 경우에는 이 속성이 적용되지 않습니다. |
아니요 |
| 완료 후 파일 삭제 | 대상 저장소로 성공적으로 이동한 후 원본 저장소에서 이진 파일을 삭제할지를 나타냅니다. 파일 삭제는 파일 단위로 이루어지므로 복사 작업에 실패하면 일부 파일은 대상에 복사되고 원본에서 삭제된 반면, 다른 파일은 원본 저장소에 계속 남아 있는 것을 확인할 수 있습니다. 이 속성은 이진 파일 복사 시나리오에서만 유효합니다. 기본값은 false입니다. |
아니요 |
| 수정된날짜시간시작 | 파일은 Last Modified 특성을 기준으로 필터링됩니다. 파일의 마지막 수정 시간이 modifiedDatetimeStart보다 이후이거나 같고 modifiedDatetimeEnd보다 이전이면 파일이 선택됩니다. 시간은 UTC 표준 시간대에 2018-12-01T05:00:00Z 형식으로 적용됩니다. 속성은 NULL일 수 있습니다. 이 경우 파일 특성 필터가 데이터 세트에 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다.
modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다.fileListPath를 구성하는 경우에는 이 속성이 적용되지 않습니다. |
아니요 |
| modifiedDatetimeEnd | 위와 동일합니다. | |
| 활성화파티션탐색 | 분할된 파일의 경우, 파일 경로에서 파티션을 구문 분석할지 여부를 지정하고 이를 추가 원본 열로 추가하십시오. 허용되는 값은 false(기본값) 및 true입니다. |
아니요 |
| 파티션루트경로 | 파티션 검색을 사용하는 경우 분할된 폴더를 데이터 열로 읽도록 절대 루트 경로를 지정합니다. 지정되지 않은 경우 기본적으로 다음과 같이 지정됩니다. - 데이터 세트의 파일 경로 또는 원본의 파일 목록을 사용하는 경우 파티션 루트 경로는 데이터 세트에 구성된 경로입니다. - 와일드카드 폴더 필터를 사용하는 경우 파티션 루트 경로는 첫 번째 와일드카드 앞의 하위 경로입니다. 예를 들어 데이터 세트의 경로를 “root/folder/year=2020/month=08/day=27”로 구성한다고 가정합니다. - 파티션 루트 경로를 “root/folder/year=2020”으로 지정하는 경우 복사 작업은 파일 내의 열 외에도 각각 값이 “08” 및 “27”인 두 개의 열( month 및 day)을 생성합니다.- 파티션 루트 경로가 지정되지 않은 경우 추가 열이 생성되지 않습니다. |
아니요 |
| 최대 동시 연결 수 (maxConcurrentConnections) | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
| DistCp 설정 | ||
| distcpSettings | HDFS DistCp를 사용할 때 사용할 속성 그룹입니다. | 아니요 |
| 리소스 관리자의 엔드포인트 | YARN(Yet Another Resource Negotiator) 엔드포인트 | 예(DistCp를 사용하는 경우) |
| tempScriptPath | 임시 DistCp 명령 스크립트를 저장하는 데 사용되는 폴더 경로입니다. 스크립트 파일이 생성되고 복사 작업을 완료한 후에 제거됩니다. | 예(DistCp를 사용하는 경우) |
| distcpOptions | DistCp 명령에 제공된 추가 옵션입니다. | 아니요 |
예제:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
폴더 및 파일 필터 예제
이 섹션에서는 와일드카드 필터를 사용했을 때의 폴더 경로 및 파일 이름의 결과 동작에 대해 설명합니다.
| 폴더 경로 | 파일 이름 | 재귀 | 원본 폴더 구조 및 필터 결과(굵게 표시된 파일이 검색됨) |
|---|---|---|---|
Folder* |
(비어 있음, 기본값 사용) | 거짓 | 폴더A File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(비어 있음, 기본값 사용) | true | 폴더A File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
거짓 | 폴더A File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | 폴더A File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
파일 목록 예
이 섹션에서는 Copy activity 원본에서 파일 목록 경로를 사용하여 발생하는 동작에 대해 설명합니다. 원본 폴더 구조가 다음과 같고 굵게 표시된 파일을 복사하려는 것으로 가정합니다.
| 샘플 원본 구조 | FileListToCopy.txt의 콘텐츠 | 구성 |
|---|---|---|
| 루트 폴더A File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 메타데이터 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
데이터 세트: - 폴더 경로: root/FolderA복사 작업 원본에서는 다음이 해당됩니다. - 파일 목록 경로: root/Metadata/FileListToCopy.txt 파일 목록 경로는 복사하려는 파일 목록이 포함된 동일한 데이터 저장소의 텍스트 파일을 가리키며, 데이터 세트에 구성된 경로의 상대 경로를 사용하여 한 줄에 하나의 파일을 가리킵니다. |
DistCp를 사용하여 HDFS에서 데이터 복사
DistCp는 Hadoop 클러스터에 분산된 복사를 수행하는 Hadoop 네이티브 명령줄 도구입니다. DistCp에서 명령을 실행하면 먼저 복사할 모든 파일을 나열하고 Hadoop 클러스터에서 여러 맵 작업을 만들며 각 맵 작업은 원본에서 싱크로 이진 복사를 수행합니다.
Copy activity DistCp를 사용하여 파일을 Azure Blob Storage(staged copy 포함) 또는 Azure 데이터 레이크 저장소에 복사할 수 있도록 지원합니다. 이 경우 DistCp는 자체 호스팅 통합 런타임에서 실행되는 대신 클러스터의 기능을 활용할 수 있습니다. DistCp를 사용하면 클러스터가 매우 강력한 경우에 특히 더 나은 복사 처리량을 제공합니다. 구성에 따라 Copy activity 자동으로 DistCp 명령을 생성하고 Hadoop 클러스터에 제출하며 복사 상태를 모니터링합니다.
필수 조건
DistCp를 사용하여 HDFS에서 Azure Blob Storage(준비된 복사본 포함) 또는 Azure 데이터 레이크 저장소로 파일을 복사하려면 Hadoop 클러스터가 다음 요구 사항을 충족하는지 확인합니다.
MapReduce 및 YARN 서비스가 활성화됩니다.
YARN 버전은 2.5 이상입니다.
HDFS 서버는 대상 데이터 저장소와 통합됩니다. Azure Blob Storage 또는 ADLS Gen1(Azure Data Lake Store):
- Azure Blob FileSystem은 Hadoop 2.7 이후 기본적으로 지원됩니다. Hadoop 환경 구성에서 JAR 경로를 지정해야 합니다.
- Azure Data Lake Store FileSystem은 Hadoop 3.0.0-alpha1부터 패키지됩니다. Hadoop 클러스터 버전이 해당 버전보다 이전인 경우 Azure Data Lake Store 관련 JAR 패키지(azure-datalake-store.jar)를 here 클러스터로 수동으로 가져오고 Hadoop 환경 구성에서 JAR 파일 경로를 지정해야 합니다.
HDFS에서 임시 폴더를 준비합니다. 이 임시 폴더는 KB 수준 공간을 차지할 수 있도록 DistCp 셸 스크립트를 저장하는 데 사용됩니다.
HDFS 연결된 서비스에 제공된 사용자 계정에 다음 권한이 있는지 확인합니다.
- YARN에서 애플리케이션을 제출합니다.
- 임시 폴더 아래에 하위 폴더를 만들고 파일을 읽고 씁니다.
구성
DistCp 관련 구성 및 예제를 참조하려면 원본으로 HDFS 섹션으로 이동하십시오.
HDFS 커넥터에 Kerberos 인증 사용
HDFS 커넥터에 Kerberos 인증을 사용하도록 온-프레미스 환경을 설정하는 옵션은 두 가지가 있습니다. 사용자의 상황에 적합한 옵션을 선택할 수 있습니다.
두 옵션 모두에서 Hadoop 클러스터에 대해 webhdfs를 켜야 합니다.
webhdfs의 HTTP 주체 및 keytab를 생성합니다.
중요한
HTTP Kerberos 주체는 Kerberos HTTP SPNEGO 사양에 의해 "HTTP/"로 시작해야 합니다. 여기에서 자세히 알아보세요.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS 구성 옵션:
hdfs-site.xml에 다음 세 가지 속성을 추가합니다.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
옵션 1: Kerberos 영역에 자체 호스팅된 통합 런타임 컴퓨터 연결
요구 사항
- 자체 호스팅 통합 런타임 컴퓨터는 Kerberos 영역에 가입해야 하며 Windows 도메인에 가입할 수 없습니다.
구성 방법
KDC 서버:
주체를 생성하고 암호를 지정합니다.
중요한
사용자 이름에는 호스트 이름을 포함하면 안 됩니다.
Kadmin> addprinc <username>@<REALM.COM>
자체 호스팅 통합 런타임 컴퓨터에서:
Ksetup 유틸리티를 실행하여 KDC(Kerberos 키 배포 센터) 서버 및 영역을 구성합니다.
Kerberos 영역이 Windows 도메인과 다르기 때문에 머신을 작업 그룹의 구성원으로 구성해야 합니다. 다음 명령을 실행하여 Kerberos 영역을 설정하고 KDC 서버를 추가하여 이 구성을 달성할 수 있습니다. REALM.COM을 귀하의 실질적인 도메인 이름으로 바꾸세요.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>이러한 명령을 실행한 후 컴퓨터를 다시 시작합니다.
Ksetup명령으로 구성을 확인합니다. 출력은 다음과 같아야 합니다.C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
데이터 팩토리 또는 Synapse 작업 공간에서:
- Windows 인증과 Kerberos 보안 주체 이름 및 암호를 사용하여 HDFS 데이터 원본에 연결하도록 HDFS 커넥터를 구성합니다. 구성 세부 정보에서 HDFS 연결된 서비스 속성을 확인합니다.
옵션 2: Windows 도메인과 Kerberos 영역 간의 상호 신뢰 사용
요구 사항
- 자체 호스팅 통합 런타임 컴퓨터는 Windows 도메인에 가입해야 합니다.
- 도메인 컨트롤러의 설정을 업데이트할 수 있는 권한이 필요합니다.
구성 방법
참고
다음 자습서에서 REALM.COM과 AD.COM을 고유한 영역 이름과 도메인 컨트롤러로 바꾸십시오.
KDC 서버:
KDC가 다음 구성 템플릿을 참조하여 Windows 도메인을 신뢰하도록 krb5.conf 파일에서 KDC 구성을 편집합니다. 기본적으로 이 구성은 /etc/krb5.conf에 있습니다.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }파일을 구성한 후 KDC 서비스를 다시 시작합니다.
다음 명령을 사용하여 KDC 서버의 krbtgt/REALM.COM@AD.COM라는 보안 주체를 준비합니다.
Kadmin> addprinc krbtgt/REALM.COM@AD.COMhadoop.security.auth_to_local HDFS 서비스 구성 파일에
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//를 추가합니다.
도메인 컨트롤러에서:
다음
Ksetup명령을 실행하여 영역 항목을 추가합니다.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMWindows 도메인에서 Kerberos 영역으로 신뢰 관계를 설정합니다. [password]는 보안 주체인 krbtgt/REALM.COM@AD.COM의 암호입니다.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Kerberos에서 사용되는 암호화 알고리즘을 선택합니다.
a.
Server Manager Group Policy Management Domain 그룹 정책 개체 디폴트 또는 활성 도메인 정책 을 선택하고,편집 을 선택합니다.b.
그룹 정책 관리 편집기 창에서컴퓨터 구성 정책 Windows 설정 보안 설정 로컬 정책 보안 설정 을 선택하고,네트워크 보안: Kerberos에 허용되는 암호화 유형 구성 을 설정합니다.c. KDC 서버에 연결할 때 사용할 암호화 알고리즘을 선택합니다. 모든 옵션을 선택할 수 있습니다.

d.
Ksetup명령을 사용하여 특정 영역에서 사용할 암호화 알고리즘을 지정합니다.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Windows 도메인에서 Kerberos 보안 주체를 사용할 수 있도록 도메인 계정과 Kerberos 보안 주체 간의 매핑을 만듭니다.
a. 관리 도구>Active Directory Users and Computers를 선택합니다.
b. 보기>고급 기능을 선택하여 고급 기능을 구성합니다.
c. 고급 기능 창에서 매핑을 만들 계정을 마우스 오른쪽 단추로 클릭하고 이름 매핑 창에서 Kerberos 이름 탭을 선택합니다.
d. 영역에서 보안 주체를 추가합니다.
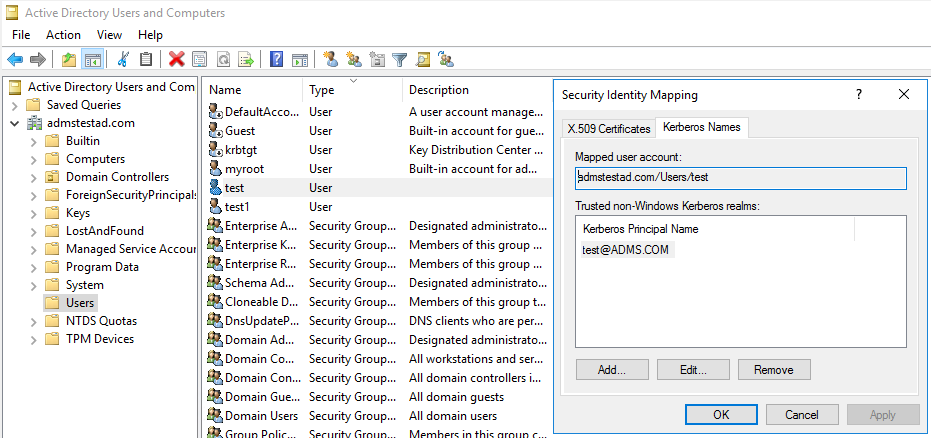
자체 호스팅 통합 런타임 컴퓨터에서:
다음
Ksetup명령을 실행하여 영역 항목을 추가합니다.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
데이터 팩토리 또는 Synapse 작업 공간에서:
- HDFS 데이터 원본에 연결하기 위해 도메인 계정 또는 Kerberos 보안 주체와 함께 Windows 인증을 사용하여 HDFS 커넥터를 구성합니다. 구성 세부 정보에서 HDFS 연결된 서비스 속성 섹션을 참조하세요.
조회 작업 속성
조회 작업 속성에 대한 자세한 내용은 조회 작업을 참조하세요.
활동 속성 삭제
삭제 작업 속성에 대한 자세한 내용은 삭제 작업을 참조하세요.
레거시 모델
참고
다음 모델은 이전 버전과의 호환성을 위해 그대로 계속 지원됩니다. 작성 UI가 새 모델을 생성하도록 전환되었으므로 앞에서 설명한 새 모델을 사용하는 것이 좋습니다.
레거시 데이터 세트 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| 종류 | 데이터 세트의 type 속성을 FileShare로 설정해야 합니다. | 예 |
| 폴더 경로 | 파일 경로입니다. 와일드카드 필터가 지원됩니다. 허용되는 와일드카드는 *(0개 이상의 문자 일치) 및 ?(0~1개의 문자 일치)입니다. 실제 파일 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^을 사용하여 이스케이프합니다. 예: rootfolder/subfolder/(더 많은 예제는 폴더 및 파일 필터 예제 참조) |
예 |
| 파일 이름 | 지정된 "folderPath" 아래의 파일에 대한 이름 또는 와일드카드 필터입니다. 이 속성의 값을 지정하지 않으면 데이터 세트는 폴더에 있는 모든 파일을 가리킵니다. 필터에 허용되는 와일드카드는 *(문자 0자 이상 일치) 및 ?(문자 0자 또는 1자 일치)입니다.- 예 1: "fileName": "*.csv"- 예 2: "fileName": "???20180427.txt"실제 폴더 이름에 와일드카드 또는 이 이스케이프 문자가 있는 경우 ^를 사용하여 이스케이프합니다. |
아니요 |
| 수정된날짜시간시작 | 파일은 Last Modified 특성을 기준으로 필터링됩니다. 파일의 마지막 수정 시간이 modifiedDatetimeStart보다 이후이거나 같고 modifiedDatetimeEnd보다 이전이면 파일이 선택됩니다. 시간은 UTC 표준 시간대에 2018-12-01T05:00:00Z 형식으로 적용됩니다. 많은 수의 파일에 파일 필터를 적용하려는 경우 이 설정을 사용하면 데이터 이동의 전반적인 성능에 영향을 줄 수 있음에 유의합니다. 속성은 NULL일 수 있습니다. 이 경우 파일 특성 필터가 데이터 세트에 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다.
modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다. |
아니요 |
| modifiedDatetimeEnd | 파일은 Last Modified 특성을 기준으로 필터링됩니다. 파일의 마지막 수정 시간이 modifiedDatetimeStart보다 이후이거나 같고 modifiedDatetimeEnd보다 이전이면 파일이 선택됩니다. 시간은 UTC 표준 시간대에 2018-12-01T05:00:00Z 형식으로 적용됩니다. 많은 수의 파일에 파일 필터를 적용하려는 경우 이 설정을 사용하면 데이터 이동의 전반적인 성능에 영향을 줄 수 있음에 유의합니다. 속성은 NULL일 수 있습니다. 이 경우 파일 특성 필터가 데이터 세트에 적용되지 않습니다. modifiedDatetimeStart에 datetime 값이 있지만 modifiedDatetimeEnd가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 크거나 같은 파일이 선택됩니다.
modifiedDatetimeEnd에 datetime 값이 있지만 modifiedDatetimeStart가 NULL이면, 마지막으로 수정된 특성이 datetime 값보다 작은 파일이 선택됩니다. |
아니요 |
| 형식 | 파일 기반 저장소(이진 복사본) 간에 파일을 있는 그대로 복사하려는 경우 입력 및 출력 데이터 세트 정의 둘 다에서 format 섹션을 건너뜁니다. 특정 형식으로 파일을 구문 분석하려는 경우 TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat과 같은 파일 형식 유형이 지원됩니다. 이 값 중 하나로 서식에서 type 속성을 설정합니다. 자세한 내용은 텍스트 형식, JSON 형식, Avro 형식, ORC 형식 및 Parquet 형식 섹션을 참조하세요. |
아니요(이진 복사 시나리오에만 해당) |
| 압축 | 데이터에 대한 압축 유형 및 수준을 지정합니다. 자세한 내용은 지원되는 파일 형식 및 압축 코덱을 참조하세요. 지원되는 형식은 Gzip, Deflate, Bzip2 및 ZipDeflate입니다. 지원되는 수준은 최적 및 가장 빠름입니다. |
아니요 |
팁
폴더 아래에서 모든 파일을 복사하려면 folderPath만을 지정합니다.
지정된 이름의 단일 파일을 복사하려면 폴더 부분으로 folderPath 및 파일 이름으로 fileName을 지정합니다.
폴더 아래에서 파일의 하위 집합을 복사하려면 폴더 부분으로 folderPath 및 와일드카드 필터로 fileName을 지정합니다.
예제:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
레거시 복사 작업 원본 모델
| 속성 | 설명 | 필수 |
|---|---|---|
| 종류 | Copy activity 원본의 type 속성을 HdfsSource로 설정해야 합니다. | 예 |
| 재귀 | 하위 폴더 또는 지정된 폴더에서만 데이터를 재귀적으로 읽을지 여부를 나타냅니다. recursive를 true로 설정하고 싱크가 파일 기반 저장소인 경우 빈 폴더 또는 하위 폴더가 싱크에 복사되거나 만들어지지 않습니다. 허용되는 값은 true(기본값) 및 false입니다. |
아니요 |
| distcpSettings | HDFS DistCp를 사용하는 경우의 속성 그룹입니다. | 아니요 |
| 리소스 관리자의 엔드포인트 | YARN 리소스 관리자의 접속점 | 예(DistCp를 사용하는 경우) |
| tempScriptPath | 임시 DistCp 명령 스크립트를 저장하는 데 사용되는 폴더 경로입니다. 스크립트 파일이 생성되고 복사 작업을 완료한 후에 제거됩니다. | 예(DistCp를 사용하는 경우) |
| distcpOptions | DistCp 명령에 제공된 추가 옵션입니다. | 아니요 |
| 최대 동시 연결 수 (maxConcurrentConnections) | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아니요 |
예제: DistCp를 사용하는 Copy 활동의 HDFS 소스
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
관련 콘텐츠
Copy activity 원본 및 싱크로 지원되는 데이터 저장소 목록은 지원되는 데이터 저장소 참조하세요.