적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
이 문서에서는 Azure Data Factory 복사 작업 성능 문제를 해결하는 방법을 간략하게 설명합니다.
복사 활동을 실행한 후 복사 활동 모니터링 보기에서 실행 결과 및 성능 통계를 수집할 수 있습니다. 다음 이미지는 예제를 보여줍니다.
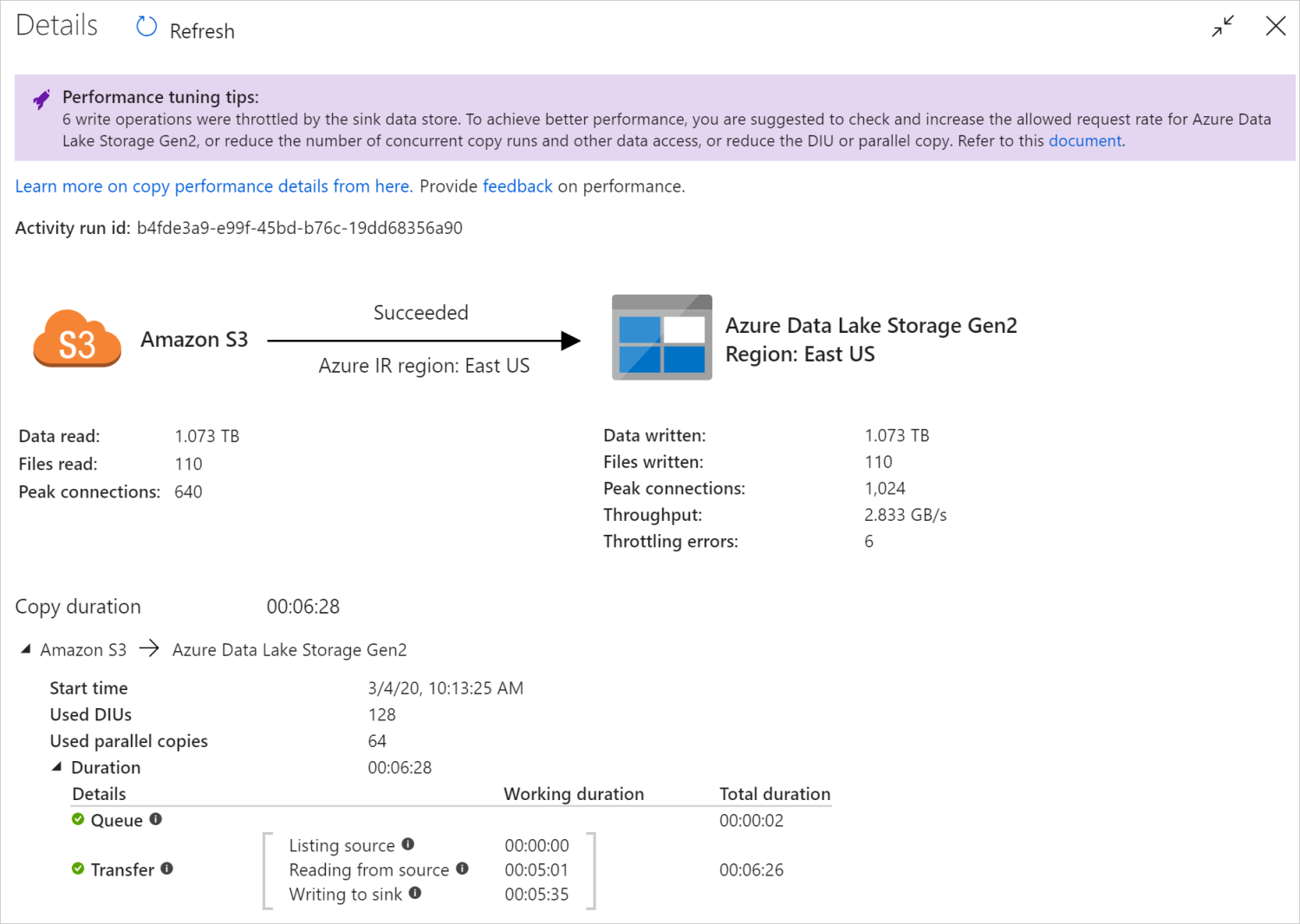
성능 튜닝 팁
일부 시나리오에서는 복사 작업을 실행할 때 이전 이미지와 같이 맨 위에 "성능 튜닝 팁" 이 표시됩니다. 이 팁은 복사 처리량을 높이는 방법에 대한 제안과 함께 이 특정 복사 실행에 대해 서비스가 식별한 병목 상태를 알려줍니다. 권장 사항을 변경한 후 복사를 다시 실행합니다.
참고로, 현재 성능 튜닝 팁은 다음과 같은 경우에 대한 제안을 제공합니다.
| 범주 | 성능 튜닝 팁 |
|---|---|
| 데이터 저장소 특정 | Azure Synapse Analytics로 데이터 로드: PolyBase 또는 COPY 문을 사용하지 않는 경우 사용하는 것이 좋습니다. |
| Azure SQL Database 데이터 복사: DTU 사용률이 높은 경우 더 높은 계층으로 업그레이드하는 것이 좋습니다. | |
| Azure Cosmos DB 데이터 복사: RU 사용률이 높은 경우 더 큰 RU로 업그레이드하는 것이 좋습니다. | |
| SAP 테이블에서 데이터 복사: 대량의 데이터를 복사할 때 SAP 커넥터의 파티션 옵션을 사용하여 병렬 로드를 사용하도록 설정하고 최대 파티션 수를 늘리는 것이 좋습니다. | |
| Amazon Redshift에서 데이터 수집: 사용되지 않는 경우 UNLOAD를 사용하는 것이 좋습니다. | |
| 데이터 저장소 제어 | 복사하는 동안 많은 읽기/쓰기 작업이 데이터 저장소에 의해 제한되는 경우 데이터 저장소에 대해 허용되는 요청 속도를 확인하고 늘리거나 동시 워크로드를 줄이는 것이 좋습니다. |
| 통합 런타임 | 자체 호스팅 Integration Runtime(IR)을 사용하며 복사 작업이 IR에서 실행 가능한 리소스가 확보될 때까지 큐에서 오랫동안 대기하고 있다면, IR을 스케일 아웃 또는 스케일 업하는 방법을 고려해 보세요. |
| 최적이 아닌 지역에 있는 Azure Integration Runtime 사용하여 읽기/쓰기가 느린 경우 다른 지역에서 IR을 사용하도록 구성하는 것이 좋습니다. | |
| 내결함성 | 호환되지 않는 행을 건너뛰는 내결함성 구성으로 인해 성능이 저하되면, 원본 데이터와 싱크 데이터의 호환성을 먼저 확인하는 것이 좋습니다. |
| 준비된 복사 | 준비된 복사본이 구성되어 있더라도 원본 동기화 쌍에 실질적인 도움이 되지 않는다면 삭제하는 것이 바람직합니다. |
| 이력서 | 복사 활동이 마지막 실패 지점에서 재개되었지만 원래 실행 후 DIU 설정을 변경하는 경우에는 새 DIU 설정이 적용되지 않습니다. |
복사 활동 실행 세부 정보 이해
복사 활동 모니터링 보기의 맨 아래에 있는 실행 세부 정보 및 기간은 복사 활동이 진행되는 주요 단계를 설명합니다(이 문서 시작 부분의 예 참조). 이 단계는 특히 복사 성능 문제를 해결하는 데 유용합니다. 복사 작업 중 병목 상태는 가장 오랜 시간이 걸리는 작업입니다. 각 단계의 정의에 대한 다음 표를 참조하십시오. 이러한 정보를 통해 Azure IR에서의 복사 작업 문제 해결 및 자체 호스팅 IR에서의 복사 작업 문제 해결 방법을 알아봅니다.
| 단계 | 설명 |
|---|---|
| 큐 | 복사 활동이 실제로 통합 런타임에서 시작될 때까지 경과된 시간입니다. |
| 사전 복사 스크립트 | IR에서 복사 작업이 시작되는 시점부터 목표 데이터 저장소에서 사전 복사 스크립트 실행을 완료하는 복사 작업까지 소요된 시간입니다. 데이터베이스 싱크를 위한 복제 전 스크립트를 구성할 때 적용합니다. 예를 들어, 새 데이터를 복사하기 전에 데이터 정리를 수행할 때 적용합니다. |
| 이전 | 이전 단계의 끝과 소스에서 싱크로 모든 데이터를 전송하는 IR 사이에 경과된 시간입니다. 전송 내 하위 단계가 병렬로 실행되며, 예를 들어 파일 형식의 구문 분석/생성과 같은 일부 작업은 현재 표시되지 않습니다. - 첫 번째 바이트까지의 시간: 이전 단계의 끝과 IR이 원본 데이터 저장소에서 첫 번째 바이트를 받는 시간 사이에 경과된 시간입니다. 파일 기반이 아닌 소스에 적용됩니다. - 원본 나열: 소스 파일 또는 데이터 파티션을 열거하는 데 소요된 시간입니다. 후자는 Oracle/SAP HANA/Teradata/Netezza/등과 같은 데이터베이스에서 데이터를 복사하는 경우와 같이 데이터베이스 원본에 대한 파티션 옵션을 구성할 때 적용됩니다. - 원본에서 읽기: 원본 데이터 저장소에서 데이터를 검색하는 데 소요된 시간입니다. - 싱크에 쓰기: 싱크 데이터 저장소에 데이터를 쓰는 데 소요된 시간입니다. 현재 Azure AI Search, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud를 비롯한 일부 커넥터에는 이 메트릭이 없습니다.. |
Azure IR에서 복사 작업 문제 해결
성능 튜닝 단계를 따라 시나리오에 대한 성능 테스트를 계획하고 수행합니다.
복사 작업 성능이 기대에 미치지 못하는 경우, Azure Integration Runtime에서 실행되는 단일 복사 작업에 대한 문제를 해결하려면 복사 모니터링 화면에서 퍼포먼스 튜닝 팁이 표시될 때 제안을 적용하고 다시 시도해 보세요. 그렇지 않으면 복사 활동 실행 세부 정보를 이해하고, 어느 단계의 기간이 가장 긴지 확인한 다음 아래 지침을 적용하여 복사 성능을 향상시키세요.
"사전 복사 스크립트"는 긴 기간을 경험했습니다. 즉, 싱크 데이터베이스에서 실행되는 사전 검사 스크립트를 완료하는 데 시간이 오래 걸립니다. 지정된 사전 검사 스크립트 논리를 조정하여 성능을 향상시킵니다. 스크립트 개선에 도움이 필요한 경우 데이터베이스 팀에 문의하십시오.
"전송 - 첫 번째 바이트까지의 시간"은 긴 작업 기간을 경험했습니다. 원본 쿼리는 데이터를 반환하는 데 시간이 오래 걸립니다. 즉, 원본이 다른 작업으로 사용 중이거나 쿼리가 최적이 아니거나 데이터를 검색하는 데 시간이 오래 걸리는 방식으로 저장되기 때문에 쿼리가 원본에서 처리하는 데 시간이 오래 걸릴 수 있습니다. 다른 쿼리가 해당 원본에서 동시에 실행되고 있는지 또는 데이터를 더 빨리 검색할 수 있도록 쿼리를 업데이트할 수 있는지 고려합니다. 데이터 원본을 관리하는 팀이 있는 경우 해당 팀에 문의하여 쿼리를 수정하거나 원본 성능을 확인합니다.
‘전송 - 원본 나열’에 긴 작업 시간 발생: 즉 소스 파일 또는 원본 데이터베이스 데이터 파티션을 열거하는 속도가 느리다는 것을 의미합니다.
파일 기반 소스에서 데이터를 복사할 때 폴더 경로 또는 파일 이름( 또는
wildcardFolderPath)에wildcardFileName를 사용하거나 파일의 마지막 수정 시간 필터(modifiedDatetimeStart또는modifiedDatetimeEnd)를 사용하는 경우 해당 필터는 지정된 폴더 아래의 모든 파일을 클라이언트 쪽으로 복사 활동을 나열하게 한 다음 필터를 적용합니다. 이러한 파일 열거는 특히 작은 파일 집합만 필터 규칙을 충족하는 경우 병목 상태가 될 수 있습니다.날짜/시간 분할 파일 경로 또는 이름에 따라 파일을 복사할 수 있는지 여부를 확인합니다. 이러한 방식은 원본 나열 쪽에 부담을 주지 않습니다.
데이터 저장소의 기본 필터, 특히 Amazon S3, Azure Blob Storage, Azure Files의 "prefix"와 ADLS Gen1의 "listAfter/listBefore"를 대신 사용할 수 있는지 확인합니다. 이러한 필터는 데이터 저장소 서버 쪽 필터이며 성능이 향상됩니다.
큰 데이터 집합 하나를 작은 데이터 집합 여러 개로 분할하고 이러한 복사 작업이 데이터의 각 부분을 동시에 실행하는 것을 고려하세요. Lookup/GetMetadata + ForEach + Copy를 사용하여 이 작업을 수행할 수 있습니다. 일반적인 예는 여러 컨테이너에서 파일 복사 또는 Amazon S3에서 ADLS Gen2로 데이터 마이그레이션 솔루션 템플릿을 참조하세요.
서비스에서 원본 제한 오류가 보고되었는지, 아니면 데이터 저장소의 사용률이 높아졌는지 확인하세요. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
원본 데이터 저장소 지역과 동일하거나 가까운 지역에서 Azure IR을 사용합니다.
‘전송 - 원본에서 읽기’에 긴 작업 시간 발생:
적용되는 경우 커넥터별 데이터 로드 모범 사례를 채택합니다. 예를 들어 Amazon Redshift에서 데이터를 복사할 때 Redshift UNLOAD를 사용하도록 구성합니다.
서비스가 소스에서 속도 제한 오류를 보고하는지 또는 데이터 저장소의 사용률이 높은지 확인합니다. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
복사 소스 및 싱크 패턴을 확인합니다.
복사 패턴이 4개 이상의 DIU(데이터 통합 단위)를 지원하는 경우 자세한 내용은 이 섹션을 참조하세요. 일반적으로 더 나은 성능을 얻기 위해 DIU를 늘릴 수 있습니다.
그렇지 않으면 큰 데이터 집합 하나를 작은 데이터 집합 여러 개로 분할하고 이러한 복사 작업이 데이터의 각 부분을 동시에 실행하는 것을 고려하세요. Lookup/GetMetadata + ForEach + Copy를 사용하여 이 작업을 수행할 수 있습니다. 일반적인 예는 여러 컨테이너에서 파일 복사, Amazon S3에서 ADLS Gen2로 데이터 마이그레이션 또는 컨트롤 테이블을 사용하여 대량 복사 솔루션 템플릿을 참조하세요.
원본 데이터 저장소 지역과 동일하거나 가까운 지역에서 Azure IR을 사용합니다.
“전송 - 싱크에 쓰기” 작업이 오래 걸림
적용되는 경우 커넥터별 데이터 로드 모범 사례를 채택합니다. 예를 들어 데이터를 Azure Synapse Analytics 복사하는 경우 PolyBase 또는 COPY 문을 사용합니다.
서비스에서 제한 오류가 발생하고 있는지, 아니면 데이터 저장소의 사용률이 높은 상태인지 확인해야 합니다. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
복사 소스 및 싱크 패턴을 확인합니다.
복사 패턴이 4개 이상의 DIU(데이터 통합 단위)를 지원하는 경우 자세한 내용은 이 섹션을 참조하세요. 일반적으로 더 나은 성능을 얻기 위해 DIU를 늘릴 수 있습니다.
그렇지 않으면 병렬 복사본을 점진적으로 튜닝합니다. 병렬 복사본이 너무 많으면 성능이 저하될 수도 있습니다.
싱크 데이터 저장소 지역과 동일하거나 가까운 지역에서 Azure IR을 사용합니다.
자체 호스팅 IR에서 복사 작업 문제 해결
성능 튜닝 단계를 따라 시나리오에 대한 성능 테스트를 계획하고 수행합니다.
복사 성능이 기대에 미치지 못하는 경우 Azure Integration Runtime 실행되는 단일 복사 작업의 문제를 해결하려면 복사 모니터링 보기에 사용 튜닝 팁이 표시되는 경우 제안을 적용하고 다시 시도합니다. 그렇지 않으면 복사 활동 실행 세부 정보를 이해하고, 어느 단계의 기간이 가장 긴지 확인한 다음 아래 지침을 적용하여 복사 성능을 향상시키세요.
‘큐’에 긴 시간 발생: 다시 말해, 자체 호스팅 IR에서 실행 가능한 리소스가 확보될 때까지 복사 작업이 대기열에서 장시간 지연될 수 있음을 의미합니다. IR 용량과 사용량을 확인하고 워크로드에 따라 스케일 업 또는 스케일 아웃합니다.
‘전송 - 첫 번째 바이트까지의 시간’에 긴 작업 시간 발생: 즉, 원본 쿼리가 데이터를 반환하는 데 시간이 오래 걸린다는 것을 의미합니다. 쿼리 또는 서버를 확인하고 최적화합니다. 추가 도움이 필요하면 데이터 저장소 팀에 문의하세요.
‘전송 - 원본 나열’에 긴 작업 시간 발생: 즉 소스 파일 또는 원본 데이터베이스 데이터 파티션을 열거하는 속도가 느리다는 것을 의미합니다.
자체 호스팅 IR 시스템이 원본 데이터 저장소에 연결하는 대기 시간이 짧은지 확인합니다. 원본이 Azure에 있는 경우 이 도구를 사용하여 자체 호스팅된 IR 머신에서 Azure 지역으로의 대기 시간을 확인할 수 있습니다. 대기 시간이 짧을수록 좋습니다.
파일 기반 소스에서 데이터를 복사할 때 폴더 경로 또는 파일 이름( 또는
wildcardFolderPath)에wildcardFileName를 사용하거나 파일의 마지막 수정 시간 필터(modifiedDatetimeStart또는modifiedDatetimeEnd)를 사용하는 경우 해당 필터는 지정된 폴더 아래의 모든 파일을 클라이언트 쪽으로 복사 활동을 나열하게 한 다음 필터를 적용합니다. 이러한 파일 열거는 특히 작은 파일 집합만 필터 규칙을 충족하는 경우 병목 상태가 될 수 있습니다.날짜/시간 분할 파일 경로 또는 이름에 따라 파일을 복사할 수 있는지 여부를 확인합니다. 이러한 방식은 원본 나열 쪽에 부담을 주지 않습니다.
데이터 저장소의 기본 필터, 특히 Amazon S3, Azure Blob Storage, Azure Files의 "prefix"와 ADLS Gen1의 "listAfter/listBefore"를 대신 사용할 수 있는지 확인합니다. 이러한 필터는 데이터 저장소 서버 쪽 필터이며 성능이 향상됩니다.
큰 데이터 집합 하나를 작은 데이터 집합 여러 개로 분할하고 이러한 복사 작업이 데이터의 각 부분을 동시에 실행하는 것을 고려하세요. Lookup/GetMetadata + ForEach + Copy를 사용하여 이 작업을 수행할 수 있습니다. 일반적인 예는 여러 컨테이너에서 파일 복사 또는 Amazon S3에서 ADLS Gen2로 데이터 마이그레이션 솔루션 템플릿을 참조하세요.
서비스에서 원본 제한 오류가 보고되었는지, 아니면 데이터 저장소의 사용률이 높아졌는지 확인하세요. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
‘전송 - 원본에서 읽기’에 긴 작업 시간 발생:
자체 호스팅 IR 시스템이 원본 데이터 저장소에 연결하는 대기 시간이 짧은지 확인합니다. Azure에 데이터 원본이 있는 경우, 이 도구를 사용하여 자가 호스팅된 IR 머신에서 Azure 지역으로의 대기 시간을 확인할 수 있습니다. 대기 시간이 짧을수록 좋습니다.
자체 호스팅 IR 시스템에 데이터를 효율적으로 읽고 전송할 수 있는 충분한 인바운드 대역폭이 있는지 확인합니다. 원본 데이터 저장소가 Azure 있는 경우 이 도구를 사용하여 다운로드 속도를 확인할 수 있습니다.
Azure Portal -> 데이터 팩터리 또는 Synapse 작업 영역 -> 개요 페이지에서 자체 호스팅 IR의 CPU 및 메모리 사용량 추세를 확인합니다. CPU 사용량이 많거나 사용 가능한 메모리가 부족한 경우 IR 스케일 업/아웃을 고려하세요.
해당하는 경우 커넥터별 데이터 로드 모범 사례를 채택합니다. 예시:
Oracle, Netezza에서 데이터를 복사하는 경우 Teradata, SAP HANA, SAP 테이블 및 SAP Open Hub)) 데이터 파티션 옵션을 사용하여 데이터를 병렬로 복사할 수 있습니다.
HDFS에서 데이터를 복사하는 경우 DistCp를 사용하도록 구성합니다.
Amazon Redshift에서 데이터를 복사할 때 Redshift UNLOAD를 사용하도록 구성합니다.
서비스가 소스에서 속도 제한 오류를 보고하는지 또는 데이터 저장소의 사용률이 높은지 확인합니다. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
복사 소스 및 싱크 패턴을 확인합니다.
파티션 옵션 사용 데이터 저장소에서 데이터를 복사하는 경우 병렬 복사본을 점진적으로 조정하는 것이 좋습니다. 병렬 복사본이 너무 많으면 성능이 저하될 수도 있습니다.
그렇지 않으면 큰 데이터 집합 하나를 작은 데이터 집합 여러 개로 분할하고 이러한 복사 작업이 데이터의 각 부분을 동시에 실행하는 것을 고려하세요. Lookup/GetMetadata + ForEach + Copy를 사용하여 이 작업을 수행할 수 있습니다. 일반적인 예는 여러 컨테이너에서 파일 복사, Amazon S3에서 ADLS Gen2로 데이터 마이그레이션 또는 컨트롤 테이블을 사용하여 대량 복사 솔루션 템플릿을 참조하세요.
“전송 - 싱크에 쓰기” 작업이 오래 걸림
적용되는 경우 커넥터별 데이터 로드 모범 사례를 채택합니다. 예를 들어 데이터를 Azure Synapse Analytics 복사하는 경우 PolyBase 또는 COPY 문을 사용합니다.
자체 호스팅 IR 시스템이 싱크 데이터 저장소에 연결하는 대기 시간이 짧은지 확인합니다. Azure에 싱크가 있는 경우, 이 도구를 사용하여 자체 호스팅된 IR 머신에서 Azure 지역까지의 대기 시간을 확인할 수 있으며, 이 값이 적을수록 좋습니다.
자체 호스팅 IR 시스템에 데이터를 효율적으로 전송하고 쓸 수 있는 충분한 아웃바운드 대역폭이 있는지 확인합니다. 싱크 데이터 저장소가 Azure 있는 경우 이 도구를 사용하여 업로드 속도를 확인할 수 있습니다.
Azure Portal -> 데이터 팩터리 또는 Synapse 작업 영역 -> 개요 페이지에서 자체 호스팅 IR의 CPU 및 메모리 사용량 추세를 확인합니다. CPU 사용량이 많거나 사용 가능한 메모리가 부족한 경우 IR 스케일 업/아웃을 고려하세요.
서비스에서 제한 오류가 발생하고 있는지, 아니면 데이터 저장소의 사용률이 높은 상태인지 확인해야 합니다. 그렇다면 데이터 저장소의 워크로드를 줄이거나 데이터 저장소 관리자에게 문의하여 제한 한도 또는 사용 가능한 리소스를 늘리십시오.
병렬 복사본을 점진적으로 조정하는 것이 좋습니다. 병렬 복사본이 너무 많으면 성능이 저하될 수도 있습니다.
커넥터 및 IR 성능
이 섹션에서는 특정 커넥터 형식 또는 통합 런타임에 대한 몇 가지 성능 문제 해결 가이드를 살펴봅니다.
활동 실행 시간은 Azure IR과 Azure 가상 네트워크 IR을 사용하여 달라집니다.
활동 실행 시간은 데이터 세트가 서로 다른 Integration Runtime 기반으로 하는 경우에 다릅니다.
증상: 데이터 집합에서 연결된 서비스 드롭다운을 전환하기만 하면 동일한 파이프라인 작업이 수행되지만 런타임은 크게 다릅니다. 데이터 세트가 Managed Virtual Network Integration Runtime을 기반으로 할 때는, 기본 Integration Runtime을 기반으로 할 때보다 평균적으로 시간이 더 오래 걸립니다.
원인: 파이프라인 실행의 세부 정보를 확인하면 느린 파이프라인이 관리형 가상 네트워크 IR에서 실행되는 동안 일반 파이프라인이 Azure IR에서 실행되고 있음을 확인할 수 있습니다. 기본적으로 관리형 가상 네트워크 IR은 서비스 인스턴스당 하나의 컴퓨팅 노드를 예약하지 않기 때문에 Azure IR보다 큐 시간이 더 길어집니다. 각 복사 활동이 시작될 수 있도록 준비하면서, 주로 Azure IR이 아닌 가상 네트워크에 합류하는 단계에서 발생합니다.
데이터를 Azure SQL Database 로드할 때 성능이 저하됩니다.
증상: Azure SQL Database에 데이터를 복사하는 속도가 느립니다.
Cause: 문제의 근본 원인은 주로 Azure SQL Database 측의 병목 현상에 의해 트리거됩니다. 가능한 원인은 다음과 같습니다.
Azure SQL Database 계층은 충분히 높지 않습니다.
Azure SQL Database DTU 사용량은%100에 가깝습니다. 성능을 모니터링하고 Azure SQL Database 계층을 업그레이드하는 것을 고려할 수 있습니다.
인덱스가 제대로 설정되지 않았습니다. 데이터를 로드하기 전에 모든 인덱스를 제거하고 로드가 완료된 후 다시 만듭니다.
WriteBatchSize는 스키마 행 크기에 맞게 충분히 크지 않습니다. 문제에 대한 속성을 확장해 보세요.
대량 삽입 대신 저장 프로시저를 사용 중이므로 성능이 저하될 것으로 예상됩니다.
큰 Excel 파일을 파싱할 때 시간 초과 또는 성능 저하
증상:
Excel 데이터 세트를 만들고 연결/저장소, 미리 보기 데이터, 목록 또는 새로 고침 워크시트에서 스키마를 가져올 때 excel 파일 크기가 큰 경우 시간 제한 오류가 발생할 수 있습니다.
복사 작업을 사용하여 큰 Excel 파일(>= 100MB)에서 다른 데이터 저장소로 데이터를 복사하는 경우 성능 저하 또는 OOM 문제가 발생할 수 있습니다.
원인:
스키마 가져오기, 데이터 미리 보기 및 Excel 데이터 세트의 워크시트 나열과 같은 작업의 경우 제한 시간은 100s이고 정적입니다. 큰 Excel 파일의 경우 이러한 작업은 제한 시간 값 내에서 완료되지 않을 수 있습니다.
복사 작업은 전체 Excel 파일을 메모리로 읽은 다음 지정된 워크시트와 셀을 찾아 데이터를 읽습니다. 이 동작은 기본 SDK 서비스 사용으로 인해 발생합니다.
해결 방법:
스키마 가져오기의 경우 원본 파일의 하위 집합인 더 작은 샘플 파일을 생성하고 ‘연결/저장소에서 스키마 가져오기’ 대신 ‘샘플 파일에서 스키마 가져오기’를 선택할 수 있습니다.
워크시트를 나열하는 경우 워크시트 드롭다운에서 "편집"을 선택하고 대신 시트 이름/인덱스를 입력할 수 있습니다.
큰 excel 파일(>100MB)을 다른 저장소에 복사하려면 스포츠 스트리밍 읽기 및 성능이 더 좋은 Data Flow Excel 원본을 사용할 수 있습니다.
큰 JSON/Excel/XML 파일을 읽는 OOM 문제
Symptoms: 큰 JSON/Excel/XML 파일을 읽을 때 작업 실행 중에 OOM(메모리 부족) 문제가 발생합니다.
원인:
- 대용량 XML 파일의 경우: 대용량 XML 파일을 읽을 때 발생하는 OOM 문제는 의도적으로 설계된 것입니다. 그 이유는 전체 XML 파일이 단일 개체이므로 메모리로 읽어온 다음 스키마를 유추하고 데이터를 검색해야 하기 때문입니다.
- 대용 Excel 파일의 경우: 대용량 Excel 파일을 읽는 OOM 문제는 의도적으로 수행됩니다. 원인은 사용하는 SDK(POI/NPOI)가 Excel 파일 전체를 메모리로 읽어온 뒤 스키마를 유추해 데이터를 가져와야 하기 때문입니다.
- 큰 JSON 파일의 경우: 큰 JSON 파일을 읽을 때 발생하는 OOM 문제는 JSON 파일이 단일 개체일 때 의도적으로 발생합니다.
권장 사항: 문제를 해결하려면 다음 옵션 중 하나를 적용합니다.
- 옵션-1: 강력한 컴퓨터(높은 CPU/메모리)에 온라인 자체 호스팅 통합 런타임을 등록하여 복사 작업을 통해 대용량 파일에서 데이터를 읽습니다.
- 옵션-2: 최적화된 메모리와 큰 크기의 클러스터(예: 48개 코어)를 사용하여 매핑 데이터 흐름 작업을 통해 큰 파일에서 데이터를 읽습니다.
- 옵션-3: 큰 파일을 작은 파일로 분할한 다음 복사 또는 매핑 데이터 흐름 작업을 사용하여 폴더를 읽습니다.
- Option-4: XML/Excel/JSON 폴더를 복사하는 동안 문제가 발생하거나 OOM 문제로 인해 멈췄다면, 파이프라인에서 foreach 활동 및 복사/매핑 데이터 흐름 활동을 사용하여 각 파일 또는 하위 폴더를 처리하세요.
-
옵션-5: 기타:
- XML의 경우 각 파일에 동일한 스키마가 있는 경우 메모리 최적화 클러스터와 함께 Notebook 작업을 사용하여 파일에서 데이터를 읽습니다. 현재 Spark에는 XML을 처리하기 위한 다양한 구현이 있습니다.
- JSON의 경우 아래의 JSON 설정의 매핑 데이터 흐름 원본에서 다양한 문서 형식(예: 단일 문서, 행당 문서 및 문서 배열)을 사용합니다. JSON 파일 콘텐츠가 줄당 문서인 경우 메모리가 거의 소비되지 않습니다.
기타 참조
지원되는 일부 데이터 저장소에 대한 성능 모니터링 및 튜닝 참조는 다음과 같습니다.
- Azure Blob 저장소: Blob 저장소의 확장성 및 성능 목표 및 Blob 저장소에 대한 성능 및 확장성 검사 목록.
- Azure Table Storage: Table Storage의 확장성 및 성능 목표 및 Table Storage의 성능 및 확장성 검사 목록.
- Azure SQL Database: 성능을 모니터링하고 DTU(데이터베이스 트랜잭션 단위) 백분율을 확인할 수 있습니다.
- Azure Synapse Analytics: 해당 기능은 DWU(Data Warehouse 단위)로 측정됩니다. Azure Synapse Analytics 컴퓨팅 성능 관리(개요) 참조하세요.
- Azure Cosmos DB:
Azure Cosmos DB. - SQL Server: 모니터 및 성능 조정.
- 온-프레미스 파일 서버: 파일 서버에 대한 성능 튜닝입니다.
관련 콘텐츠
다른 복사 작업 문서를 참조하세요.
- 복사 작업 개요
- Copy activity 성능 및 확장성 가이드
- Copy activity 성능 최적화 기능
데이터 레이크 또는 데이터 웨어하우스의 데이터를 Azure Amazon S3에서 Azure Storage