수억 개의 파일로 구성된 페타바이트 크기 데이터를 Amazon S3에서 Azure Data Lake Storage Gen2으로 마이그레이션하는 템플릿을 사용하세요.
참고
AWS S3에서 Azure로 볼륨이 작은 데이터를 복사하려는 경우(예: 10TB 미만) Azure Data Factory 데이터 복사 도구를 사용하는 것이 더 효율적이고 사용하기 쉽습니다. 이 문서에서 설명하는 템플릿은 필수 사양 이상의 기능을 제공합니다.
솔루션 템플릿 정보
데이터 파티션은 특히 10TB 이상의 데이터를 마이그레이션할 때 권장됩니다. 데이터를 분할하려면 ‘접두사’ 설정을 활용하여 Amazon S3의 폴더와 파일을 이름으로 필터링합니다. 그러면 각 ADF 복사 작업에서 한 번에 하나의 파티션을 복사할 수 있습니다. 더 나은 처리량을 위해 여러 ADF 복사 작업을 동시에 실행할 수 있습니다.
데이터 마이그레이션에는 일반적으로 일회성 기록 데이터 마이그레이션과 AWS S3에서 Azure로의 변경 내용이 정기적으로 동기화되어야 합니다. 아래에는 두 가지 템플릿이 있습니다. 여기서 한 템플릿은 일회성 기록 데이터 마이그레이션을 처리하고 다른 템플릿은 AWS S3에서 Azure로 변경 내용을 동기화하는 과정을 다룹니다.
Amazon S3에서 Azure Data Lake Storage Gen2로 기록 데이터를 마이그레이션하기 위한 템플릿
이 템플릿(템플릿 이름: AWS S3에서 Azure Data Lake Storage Gen2로 기록 데이터 마이그레이션)은 Azure SQL Database의 외부 컨트롤 테이블에 파티션 목록을 작성했다고 가정합니다. 따라서 Lookup 작업을 사용하여 외부 제어 테이블에서 파티션 목록을 검색하고, 각 파티션을 반복하며, ADF 복사 작업에서 한 번에 하나의 파티션을 복사하도록 합니다. 복사 작업이 완료되면, 저장 프로시저 작업을 사용하여 컨트롤 테이블의 각 파티션 복사 상태를 업데이트합니다.
해당 템플릿은 다음 다섯 가지 작업으로 구성됩니다.
Lookup은 외부 컨트롤 테이블에서 Azure Data Lake Storage Gen2로 복사되지 않은 파티션을 검색합니다. 테이블 이름은 s3_partition_control_table이고 테이블에서 데이터를 로드하는 쿼리는 ‘SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0’입니다.
ForEach는 Lookup 작업에서 파티션 목록을 가져오고 각 파티션을 TriggerCopy 작업으로 반복합니다. 여러 ADF 복사 작업을 동시에 실행하도록 batchCount를 설정할 수 있습니다. 해당 템플릿에는 설정 2가 있습니다.
ExecutePipeline은 CopyFolderPartitionFromS3 파이프라인을 실행합니다. 각 복사 작업에서 파티션을 복사하도록 다른 파이프라인을 만들면 실패한 복사 작업을 다시 실행하여 AWS S3에서 특정 파티션을 충전하기에 용이합니다. 다른 파티션을 로드하는 다른 모든 복사 작업에는 영향을 주지 않습니다.
Copy는 AWS S3의 각 파티션을 Azure Data Lake Storage Gen2로 복사합니다.
SqlServerStoredProcedure는 컨트롤 테이블의 각 파티션 복사 상태를 업데이트합니다.
해당 템플릿은 다음 두 개의 매개 변수를 포함합니다.
AWS_S3_bucketName은 데이터를 마이그레이션할 AWS S3의 버킷 이름입니다. AWS S3에서 여러 버킷의 데이터를 마이그레이션하려는 경우 외부 제어 테이블에 열을 하나 더 추가하여 각 파티션에 대한 버킷 이름을 저장하고, 그에 따라 해당 열에서 데이터를 검색할 수 있도록 파이프라인을 업데이트할 수 있습니다.
Azure_Storage_fileSystem은 데이터를 마이그레이션할 대상 Azure Data Lake Storage Gen2의 fileSystem 이름입니다.
템플릿이 Amazon S3에서 Azure Data Lake Storage Gen2로 변경된 파일만 복사하게 하려면,
해당 템플릿(템플릿 이름: AWS S3에서 Azure Data Lake Storage Gen2로 델타 데이터 복사)은 각 파일의 LastModifiedTime을 사용하여 AWS S3에서 Azure로 새로운 파일 또는 업데이트된 파일만 복사합니다. 파일이나 폴더가 AWS S3에서 파일 또는 폴더 이름의 일부로 Timeslice 정보를 사용하여 이미 분할된 경우(예:/yyyy/mm/dd/file.csv), 자습서로 이동하여 새 파일을 증분 로드하는 보다 효과적인 방법을 알아볼 수 있습니다.
해당 템플릿은 Azure SQL Database의 외부 컨트롤 테이블에 파티션 목록을 작성했다고 가정합니다. 따라서 Lookup 작업을 사용하여 외부 제어 테이블에서 파티션 목록을 검색하고, 각 파티션을 반복하며, ADF 복사 작업에서 한 번에 하나의 파티션을 복사하도록 합니다. 각 복사 작업이 AWS S3에서 파일 복사를 시작하면, LastModifiedTime 속성에 의존하여 새 파일 또는 업데이트된 파일만 식별하고 복사합니다. 복사 작업이 완료되면, 저장 프로시저 작업을 사용하여 컨트롤 테이블의 각 파티션 복사 상태를 업데이트합니다.
해당 템플릿은 다음 일곱 가지 작업을 포함합니다.
Lookup은 외부 제어 테이블에서 파티션을 검색합니다. 테이블 이름은 s3_partition_delta_control_table이고 테이블에서 데이터를 로드하는 쿼리는 ‘select distinct PartitionPrefix from s3_partition_delta_control_table’입니다.
ForEach는 Lookup 작업에서 파티션 목록을 가져오고 각 파티션을 TriggerDeltaCopy 작업으로 반복합니다. 여러 ADF 복사 작업을 동시에 실행하도록 batchCount를 설정할 수 있습니다. 해당 템플릿에는 설정 2가 있습니다.
ExecutePipeline은 DeltaCopyFolderPartitionFromS3 파이프라인을 실행합니다. 각 복사 작업에서 파티션을 복사하도록 다른 파이프라인을 만들면 실패한 복사 작업을 다시 실행하여 AWS S3에서 특정 파티션을 충전하기에 용이합니다. 다른 파티션을 로드하는 다른 모든 복사 작업에는 영향을 주지 않습니다.
Lookup은 LastModifiedTime을 통해 새 파일 또는 업데이트된 파일을 식별할 수 있도록 외부 컨트롤 테이블에서 마지막 복사 작업 실행 시간을 검색합니다. 테이블 이름은 s3_partition_delta_control_table이고 테이블에서 데이터를 로드하는 쿼리는 “select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = ‘@{pipeline().parameters.prefixStr}’ and SuccessOrFailure = 1”입니다.
Copy는 AWS S3의 각 파티션에 대한 새 파일 또는 변경된 파일을 Azure Data Lake Storage Gen2로 복사합니다. modifiedDatetimeStart 속성은 마지막 복사 작업의 실행 시간으로 설정됩니다. modifiedDatetimeEnd 속성은 현재 복사 작업의 실행 시간으로 설정됩니다. 시간은 UTC 표준 시간대를 적용합니다.
SqlServerStoredProcedure는 각 파티션의 복사 상태를 업데이트하고 성공 시 컨트롤 테이블에 실행 시간을 복사합니다. SuccessOrFailure의 열은 1로 설정합니다.
SqlServerStoredProcedure는 각 파티션의 복사 상태를 업데이트하고 실패 시 컨트롤 테이블에 실행 시간을 복사합니다. SuccessOrFailure의 열은 0으로 설정합니다.
해당 템플릿은 다음 두 개의 매개 변수를 포함합니다.
AWS_S3_bucketName은 데이터를 마이그레이션할 AWS S3의 버킷 이름입니다. AWS S3에서 여러 버킷의 데이터를 마이그레이션하려는 경우 외부 제어 테이블에 열을 하나 더 추가하여 각 파티션에 대한 버킷 이름을 저장하고, 그에 따라 해당 열에서 데이터를 검색할 수 있도록 파이프라인을 업데이트할 수 있습니다.
Azure_Storage_fileSystem은 데이터를 마이그레이션할 대상 Azure Data Lake Storage Gen2의 fileSystem 이름입니다.
두 솔루션 템플릿을 사용하는 방법
Amazon S3에서 Azure Data Lake Storage Gen2로 기록 데이터를 마이그레이션하기 위한 템플릿
Azure SQL Database의 컨트롤 테이블을 만들어서 AWS S3의 파티션 목록을 저장합니다.
참고
테이블 이름은 s3_partition_control_table입니다.
컨트롤 테이블의 스키마는 PartitionPrefix와 SuccessOrFailure입니다. 여기서 PartitionPrefix는 이름으로 Amazon S3의 폴더와 파일을 필터링하는 S3의 접두사 설정이며, SuccessOrFailure는 각 파티션의 복사 상태입니다. 0은 파티션이 Azure로 복사되지 않았음을 의미하고, 1은 성공적으로 복사되었음을 의미합니다.
컨트롤 테이블에 정의된 파티션은 5개이고 각 파티션 복사의 기본 상태는 0입니다.
동일한 Azure SQL Database에 컨트롤 테이블에 대한 저장 프로시저를 만듭니다.
참고
저장 프로시저의 이름은 sp_update_partition_success입니다. ADF 파이프라인에서 SqlServerStoredProcedure 작업으로 호출합니다.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255)
AS
BEGIN
UPDATE s3_partition_control_table
SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix
END
GO
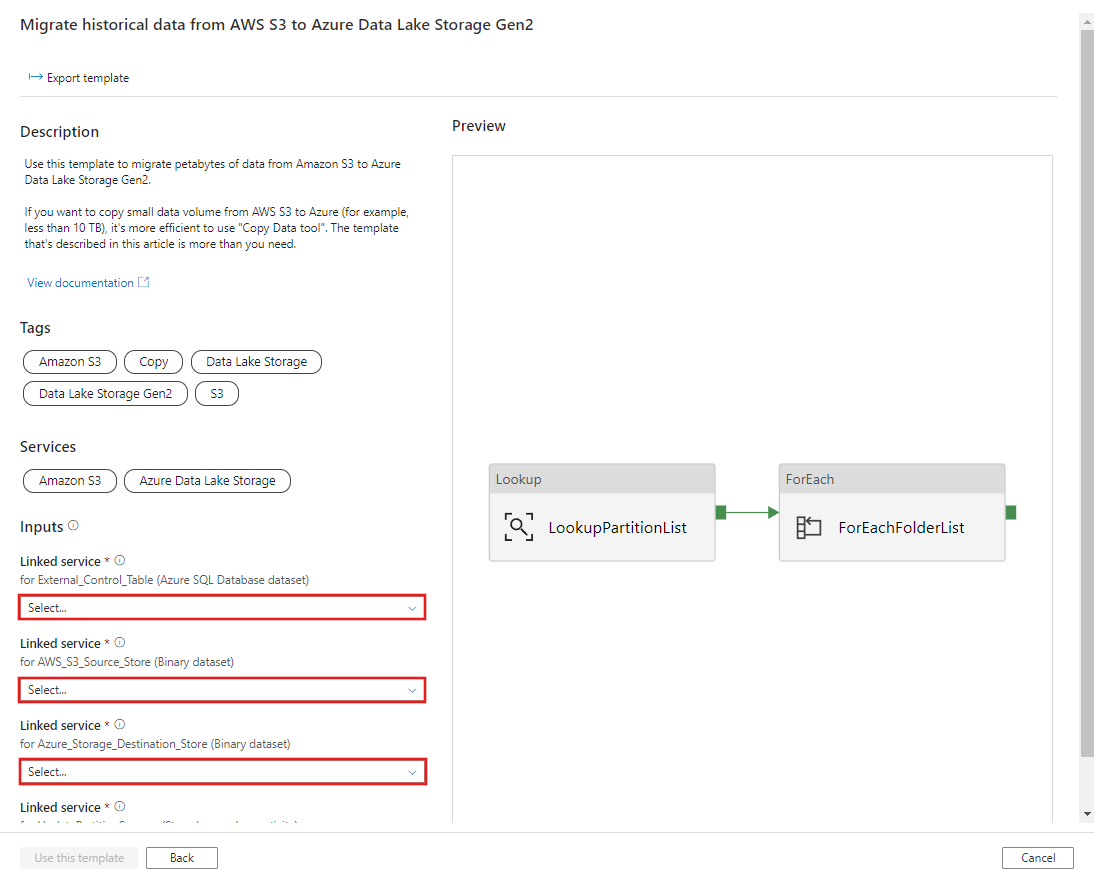
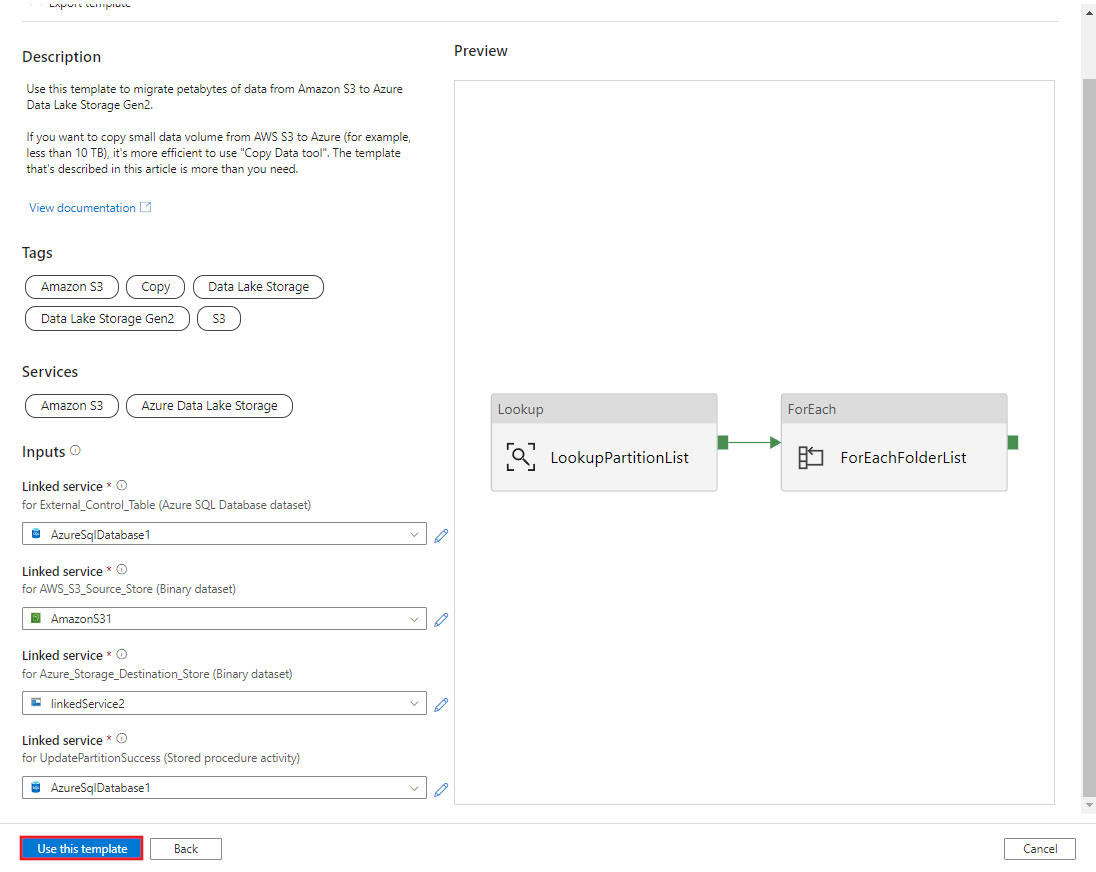
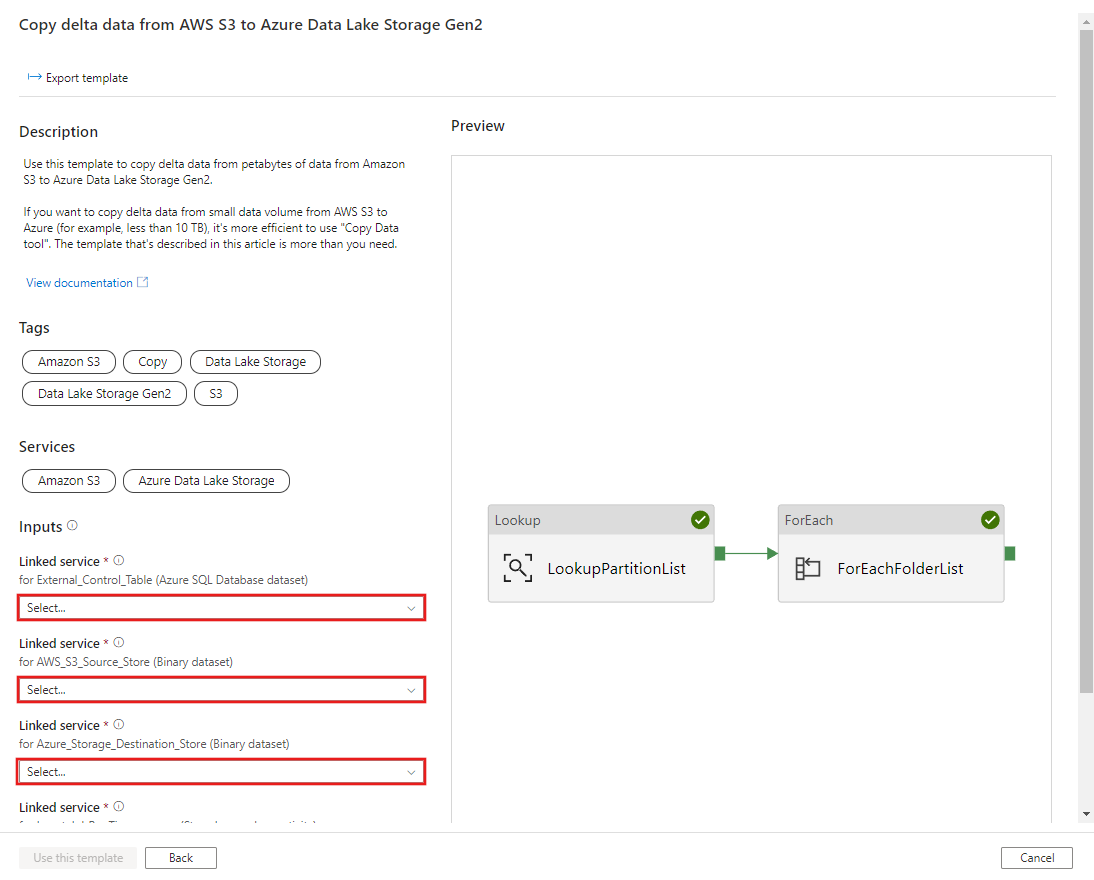
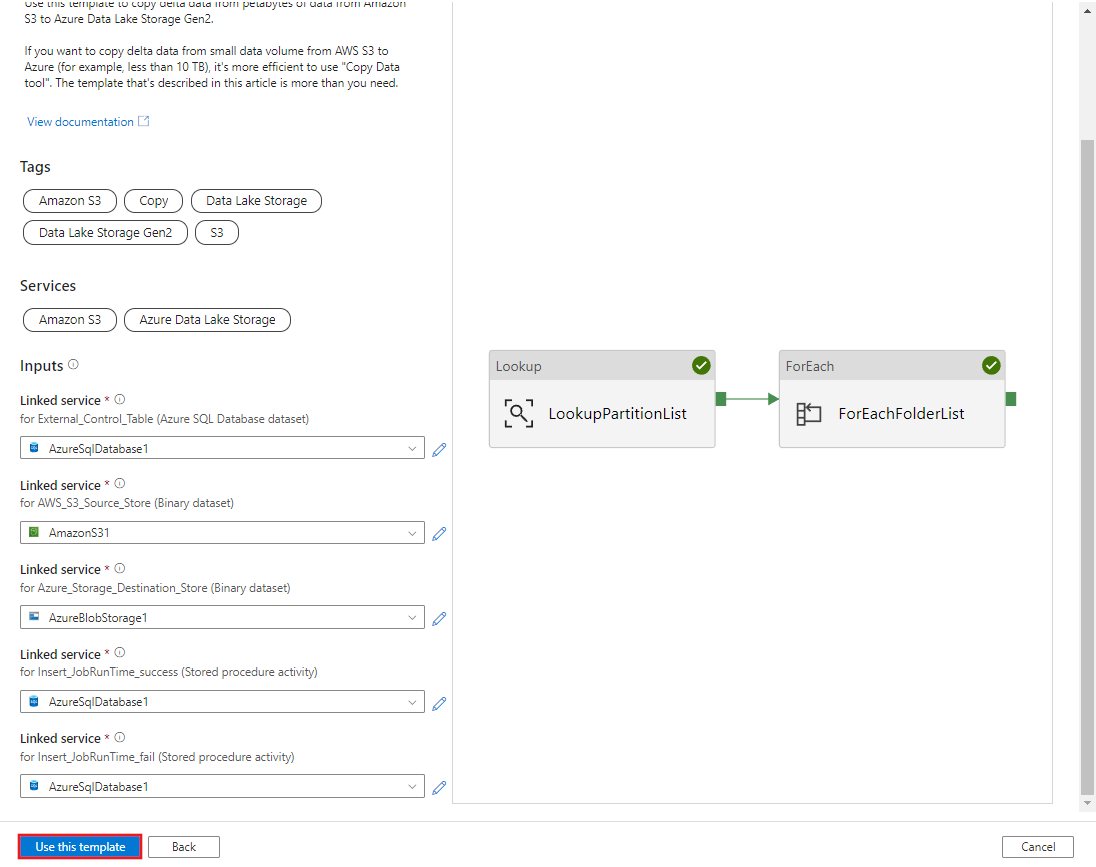
AWS S3에서 Azure Data Lake Storage Gen2로 기록 데이터 마이그레이션하기 템플릿으로 이동합니다. S3 AWS를 데이터 원본 스토어로, Azure Data Lake Storage Gen2를 대상 스토어로, 외부 컨트롤 테이블에 대한 연결을 입력합니다. 외부 컨트롤 테이블 및 저장 프로시저는 동일한 연결에 대한 참조입니다.
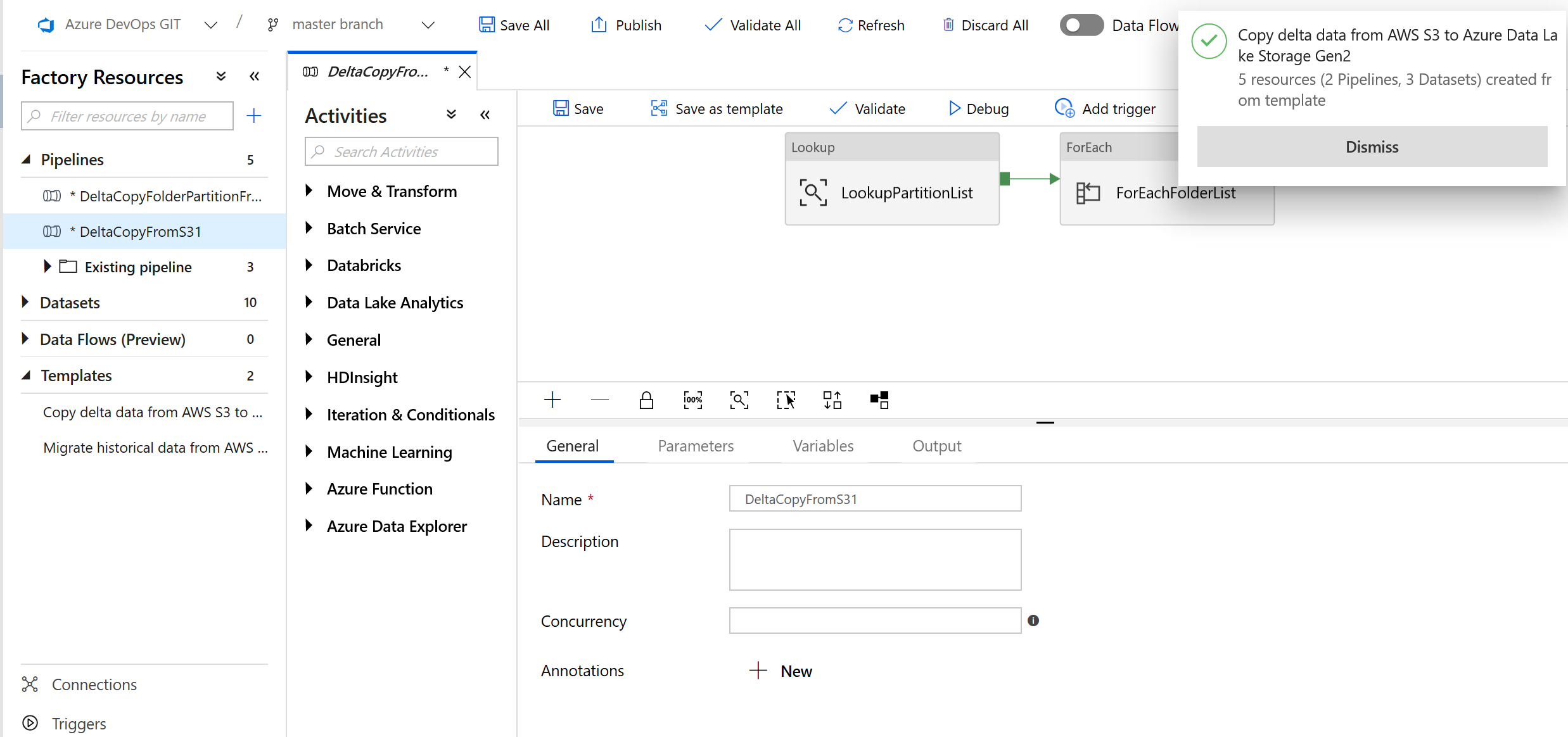
이 템플릿 사용을 선택합니다.
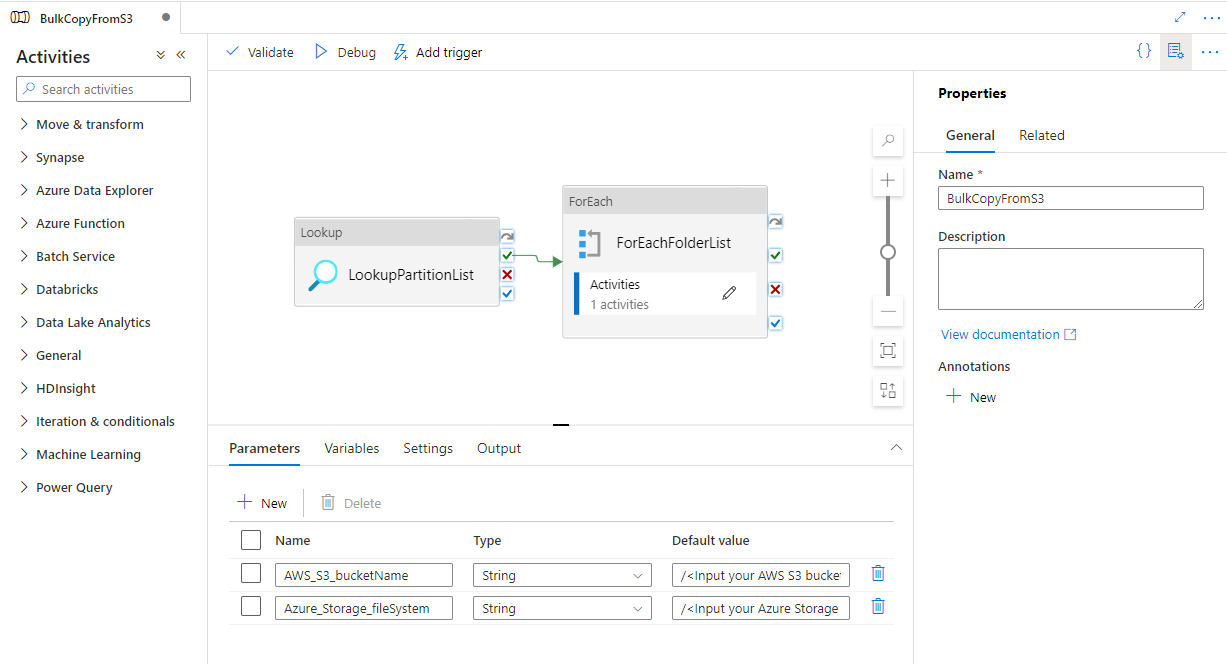
다음 예제와 같이 2개의 파이프라인과 3개의 데이터 세트가 만들어진 것을 볼 수 있습니다.
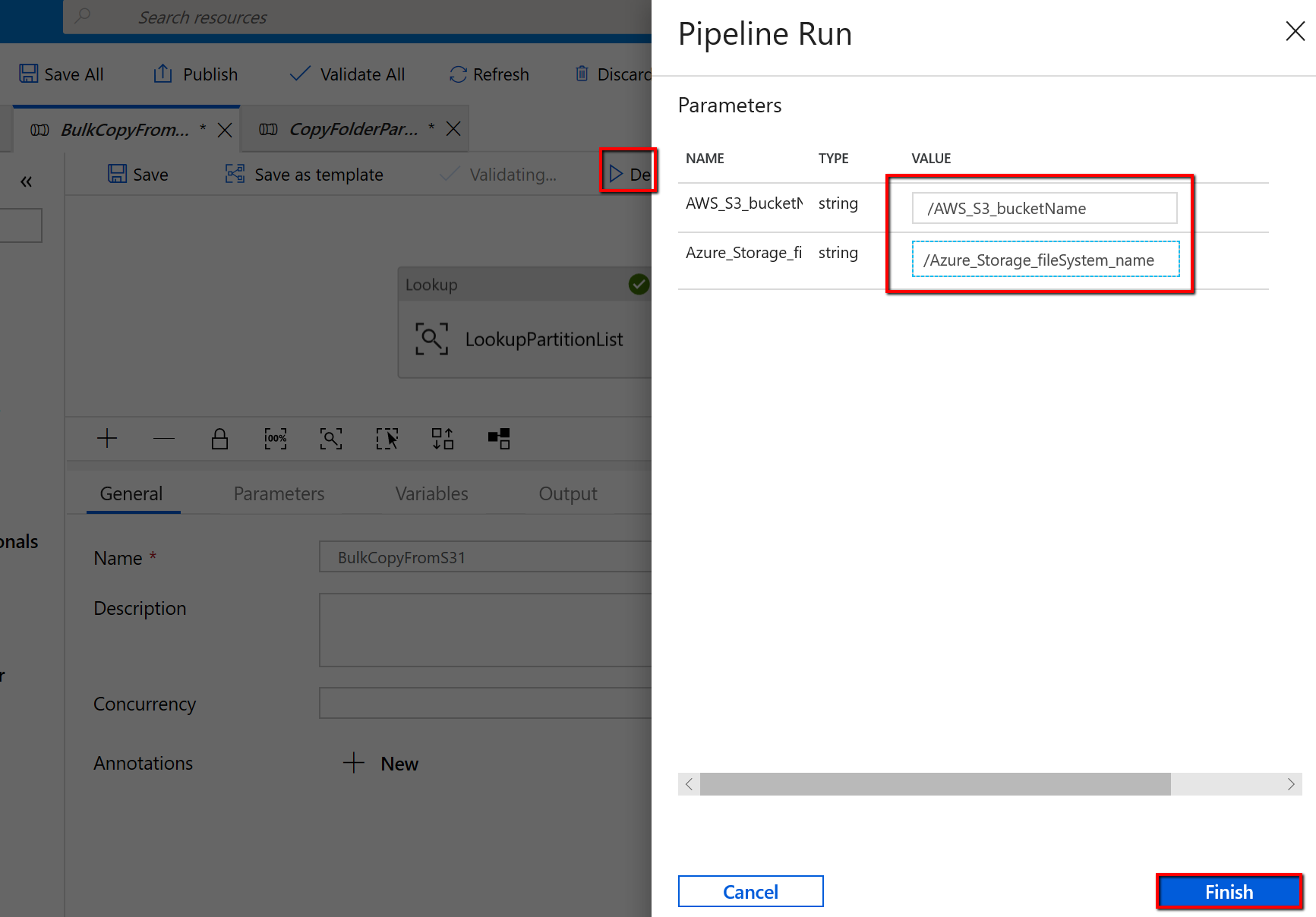
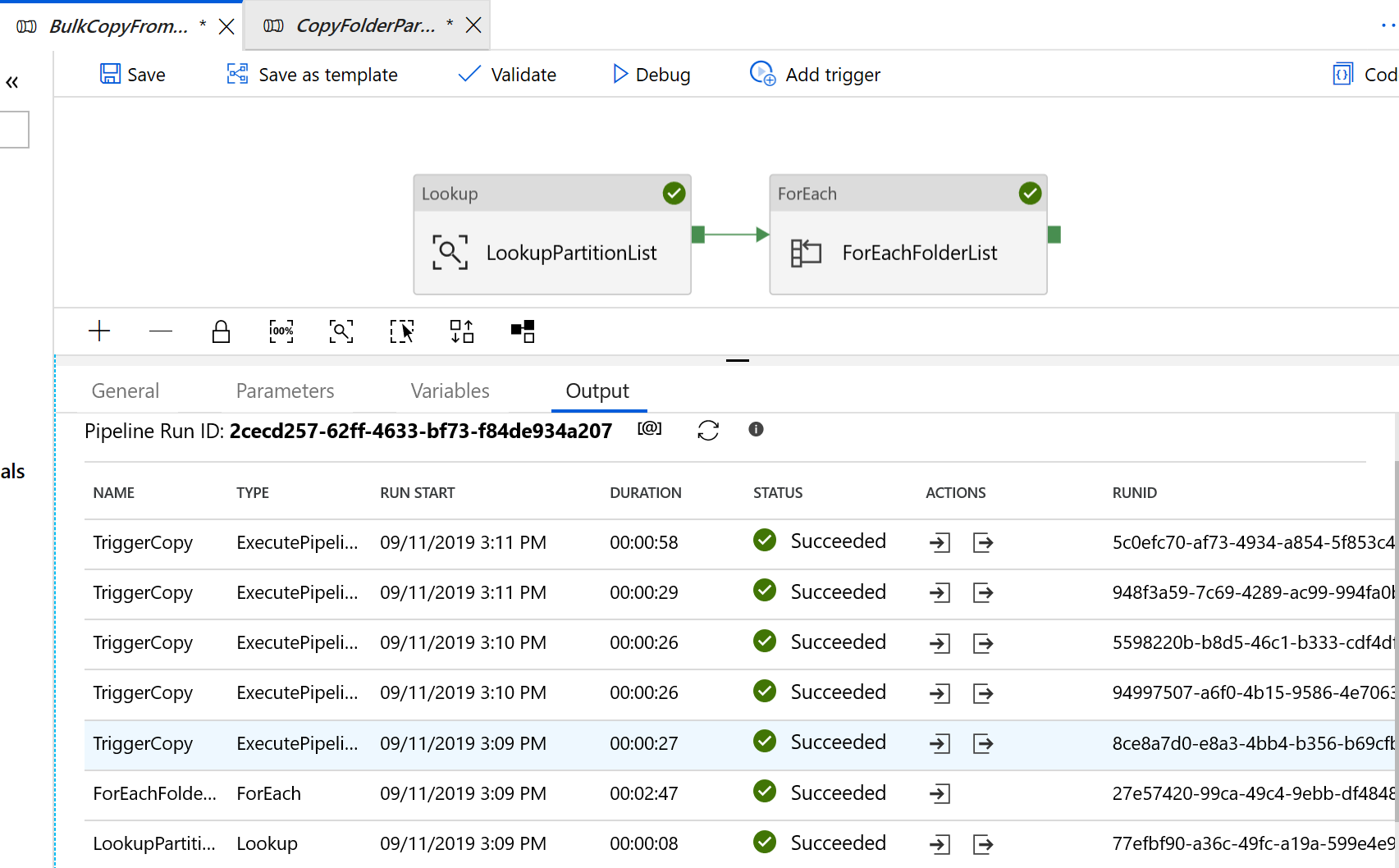
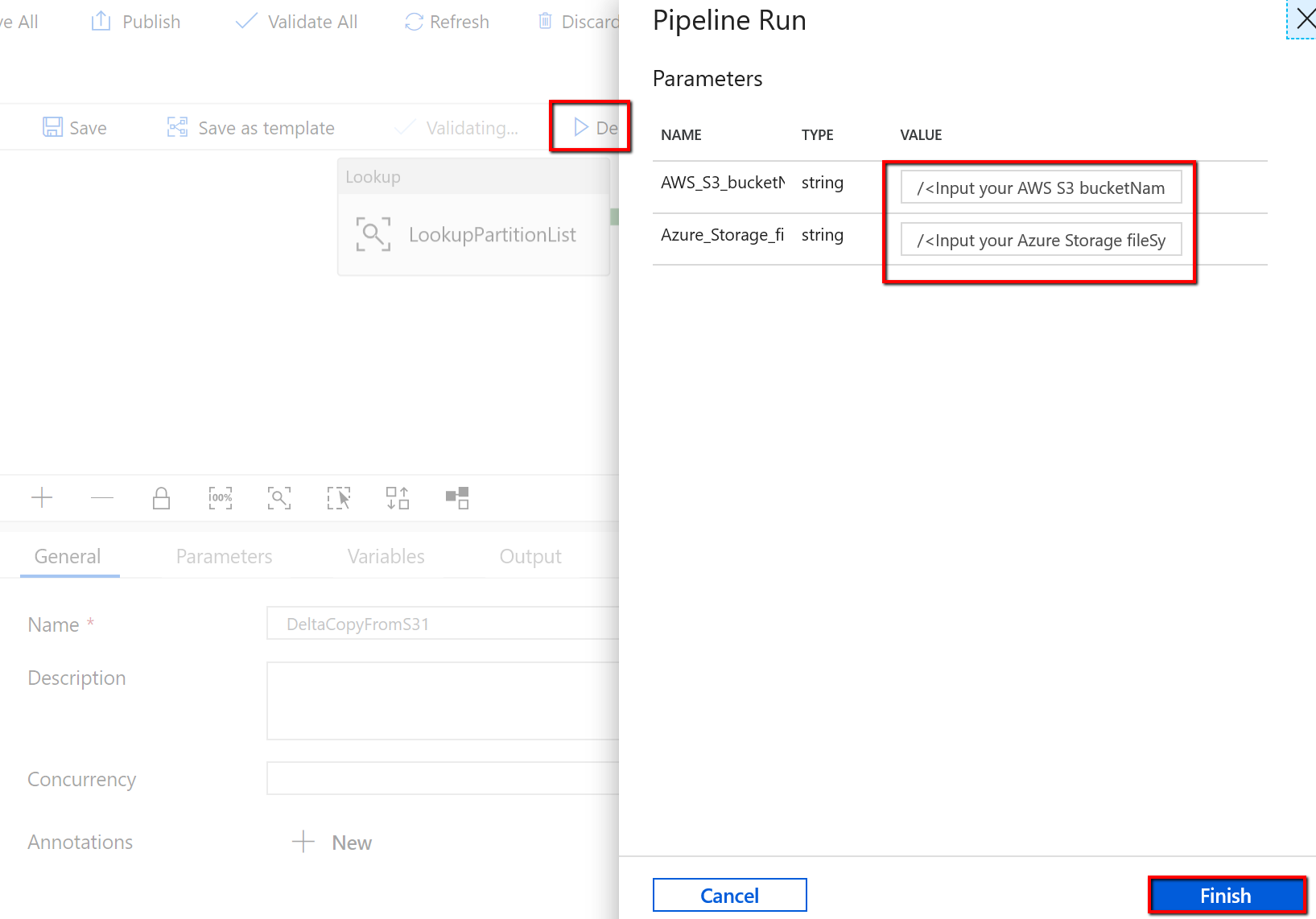
‘BulkCopyFromS3’ 파이프라인으로 이동하여 디버그를 선택한 다음 매개 변수를 입력합니다. 마침을 선택합니다.
결과는 다음 예제와 유사합니다.
템플릿이 Amazon S3에서 Azure Data Lake Storage Gen2로 변경된 파일만 복사하게 하려면,
Azure SQL Database의 컨트롤 테이블을 만들어서 AWS S3의 파티션 목록을 저장합니다.
참고
테이블 이름은 s3_partition_delta_control_table입니다.
컨트롤 테이블의 스키마는 PartitionPrefix, JobRunTime, SuccessOrFailure입니다. 여기서 PartitionPrefix는 이름으로 Amazon S3의 폴더와 파일을 필터링하는 S3의 접두사 설정이며, JobRunTime은 복사 작업을 실행할 때의 Datetime 값이고, SuccessOrFailure는 각 파티션 복사의 상태입니다. 0은 파티션이 Azure로 복사되지 않았음을 의미하고, 1은 성공적으로 복사되었음을 의미합니다.
컨트롤 테이블에는 5개의 파티션이 정의되어 있습니다. JobRunTime의 기본값은 일회성 기록 데이터의 마이그레이션을 시작하는 시간일 수 있습니다. ADF 복사 작업은 해당 시간 이후 마지막으로 수정된 AWS S3의 파일을 복사합니다. 각 파티션 복사의 기본 상태는 1입니다.
동일한 Azure SQL Database에 컨트롤 테이블에 대한 저장 프로시저를 만듭니다.
참고
저장 프로시저의 이름은 sp_insert_partition_JobRunTime_success입니다. ADF 파이프라인에서 SqlServerStoredProcedure 작업으로 호출합니다.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit
AS
BEGIN
INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure)
VALUES
(@PartPrefix,@JobRunTime,@SuccessOrFailure)
END
GO
AWS S3에서 Azure Data Lake Storage Gen2로 델타 데이터 복사 템플릿으로 이동합니다. S3 AWS를 데이터 원본 스토어로, Azure Data Lake Storage Gen2를 대상 스토어로, 외부 컨트롤 테이블에 대한 연결을 입력합니다. 외부 컨트롤 테이블 및 저장 프로시저는 동일한 연결에 대한 참조입니다.
이 템플릿 사용을 선택합니다.
다음 예제와 같이 2개의 파이프라인과 3개의 데이터 세트가 만들어진 것을 볼 수 있습니다.
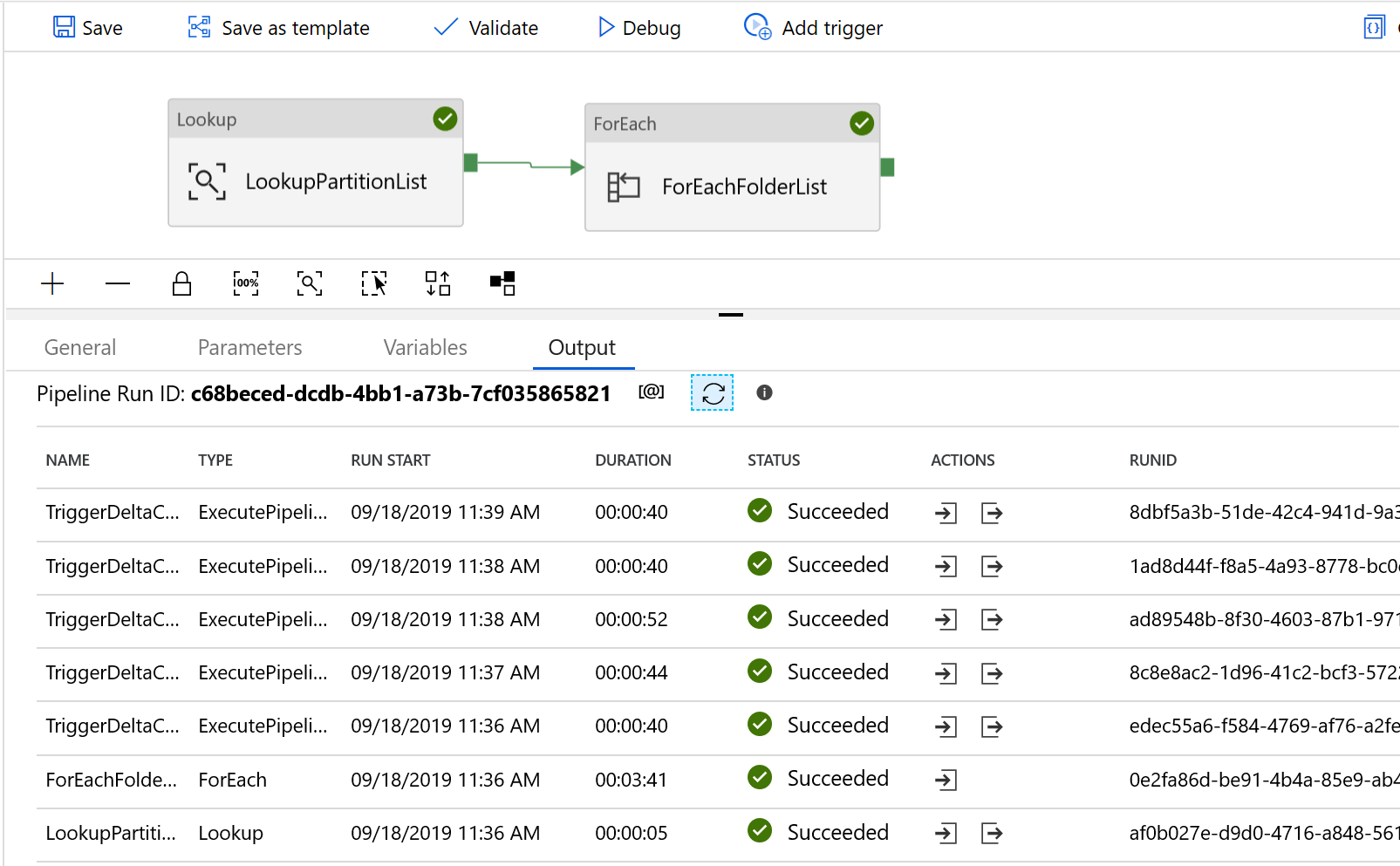
‘DeltaCopyFromS3’ 파이프라인으로 이동하여 디버그를 선택한 다음 매개 변수를 입력합니다. 마침을 선택합니다.
결과는 다음 예제와 유사합니다.
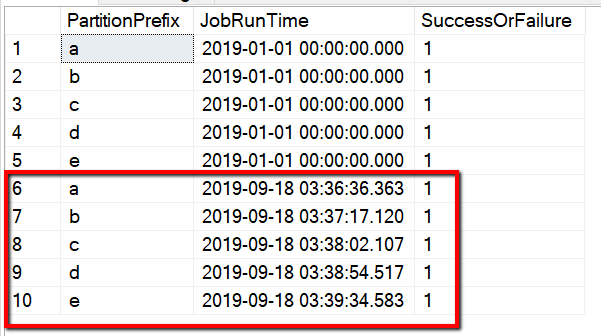
‘Select * from s3_partition_delta_control_table’쿼리를 통해 컨트롤 테이블의 결과를 확인할 수도 있습니다. 다음 예제와 유사한 출력이 표시됩니다.
 Azure Data Factory
Azure Data Factory