Azure Data Factory를 사용하여 온-프레미스 Hadoop 클러스터에서 Azure Storage로 데이터를 마이그레이션합니다.
적용 대상: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Azure Data Factory는 온-프레미스 HDFS에서 Azure Blob 스토리지 또는 Azure Data Lake Storage Gen2으로 대규모로 데이터를 마이그레이션하는 데 강력하고 비용 효율적인 고성능 메커니즘을 제공합니다.
Data Factory는 온-프레미스 HDFS에서 Azure로 데이터를 마이그레이션하기 위한 두 가지 기본 접근 방식을 제공합니다. 시나리오에 따라 접근 방식을 선택할 수 있습니다.
- Data Factory DistCp 모드(권장): Data Factory에서 DistCp(분산 복사)를 사용하여 파일을 있는 그대로 Azure Blob 스토리지(단계적 복사) 또는 Azure Data Lake Store Gen2에 복사할 수 있습니다. DistCp와 통합된 Data Factory를 사용하여 기존의 강력한 클러스터를 활용하면 최상의 복사 처리량을 달성할 수 있습니다. 또한 Data Factory에서 유연한 스케줄링 및 통합 모니터링 경험의 이점을 얻을 수 있습니다. Data Factory 구성에 따라 복사 작업은 DistCp 명령을 자동으로 구성하고 데이터를 Hadoop 클러스터에 제출한 다음, 복사 상태를 모니터링합니다. 온-프레미스 Hadoop 클러스터에서 Azure로 데이터를 마이그레이션하려는 경우 Data Factory DistCp 모드를 권장합니다.
- Data Factory 네이티브 통합 런타임 모드: DistCp는 모든 시나리오에서 옵션이 아닙니다. 예를 들어 Azure Virtual Networks 환경에서 DistCp 도구는 Azure Storage 가상 네트워크 엔드포인트와의 Azure ExpressRoute 개인 피어링을 지원하지 않습니다. 또한 경우에 따라 기존 Hadoop 클러스터를 데이터 마이그레이션 엔진으로 사용하지 않기 때문에 기존 ETL 작업의 성능에 영향을 줄 수 있는 클러스터에 과도한 부하를 주지 않습니다. 대신, 온-프레미스 HDFS에서 Azure로 데이터를 복사하는 엔진으로 Data Factory 통합 런타임의 기본 기능을 사용할 수 있습니다.
이 문서에서는 두 가지 접근 방법에 대한 다음 정보를 제공합니다.
- 성능
- 복사 복원력
- 네트워크 보안
- 개괄적인 솔루션 아키텍처
- 구현 모범 사례
성능
Data Factory DistCp 모드에서는 DistCp 도구를 독립적으로 사용하는 경우와 처리량이 동일합니다. Data Factory DistCp 모드는 기존 Hadoop 클러스터의 용량을 극대화합니다. 대규모 클러스터 간 또는 클러스터 내 복사에 DistCp를 사용할 수 있습니다.
DistCp는 MapReduce를 사용하여 배포, 오류 처리 및 복구, 보고에 영향을 줍니다. 작업 매핑을 위한 입력으로 파일 및 디렉터리 목록을 확장합니다. 각 작업은 원본 목록에 지정된 파일 파티션을 복사합니다. DistCp와 통합된 Data Factory를 사용하여 네트워크 대역폭, 스토리지 IOPS 및 대역폭을 완전히 활용하는 파이프라인을 구축하여 환경에 대한 데이터 이동 처리량을 극대화할 수 있습니다.
Data Factory 네이티브 통합 런타임 모드에서는 서로 다른 수준에서 병렬 처리를 수행할 수도 있습니다. 병렬 처리를 사용하여 네트워크 대역폭, 스토리지 IOPS 및 대역폭을 완전히 활용하여 데이터 이동 처리량을 극대화할 수 있습니다.
- 단일 복사 작업은 확장 가능한 컴퓨팅 리소스를 활용할 수 있습니다. 자체 호스팅 통합 런타임을 사용하면 수동으로 머신을 스케일 업하거나 여러 머신으로 스케일 아웃할 수 있습니다(최대 4개 노드). 단일 복사 작업은 모든 노드에서 파일 세트를 분할합니다.
- 단일 복사 작업은 여러 스레드를 사용하여 데이터 저장소에서 읽고 씁니다.
- Data Factory 제어 흐름은 동시에 여러 복사 작업을 시작할 수 있습니다. 예를 들어 For Each 루프를 사용할 수 있습니다.
자세한 내용은 복사 작업 성능 가이드를 참조하세요.
복원력
Data Factory DistCp 모드에서는 여러 수준의 복원력에 대해 서로 다른 DistCp 명령줄 매개 변수(예: -i, 실패 무시 또는 -update, 소스 파일과 대상 파일 크기가 다를 때 데이터 쓰기)를 사용할 수 있습니다.
Data Factory 네이티브 통합 런타임 모드의 단일 복사 작업 실행에서 Data Factory에는 재시도 메커니즘이 내장되어 있습니다. 데이터 저장소 또는 기본 네트워크에서 특정 수준의 일시적 장애를 처리할 수 있습니다.
온-프레미스 HDFS에서 Blob 스토리지로, 온-프레미스 HDFS에서 Data Lake Store Gen2로 이진 복사를 수행할 때 Data Factory는 자동으로 검사점을 대규모로 확장합니다. 복사 작업 실행이 실패하거나 시간이 초과되면 후속 재시도에서(재시도 횟수가 >1인지 확인) 처음부터 시작하지 않고 마지막 실패 지점부터 복사가 재개됩니다.
네트워크 보안
기본적으로 Data Factory는 HTTPS 프로토콜을 통한 암호화된 연결을 사용하여 온-프레미스 HDFS에서 Blob 스토리지 또는 Azure Data Lake Storage Gen2로 데이터를 전송합니다. HTTPS는 전송 중인 데이터의 암호화를 제공하고, 도청 및 메시지 가로채기(man-in-the-middle) 공격을 방지합니다.
또는 공용 인터넷을 통해 데이터를 전송하지 않으려는 경우에는 보안을 강화하기 위해 ExpressRoute를 통한 개인 피어링 링크를 통해 데이터를 전송할 수 있습니다.
솔루션 아키텍처
이 이미지는 공용 인터넷을 통한 데이터 마이그레이션을 보여줍니다.
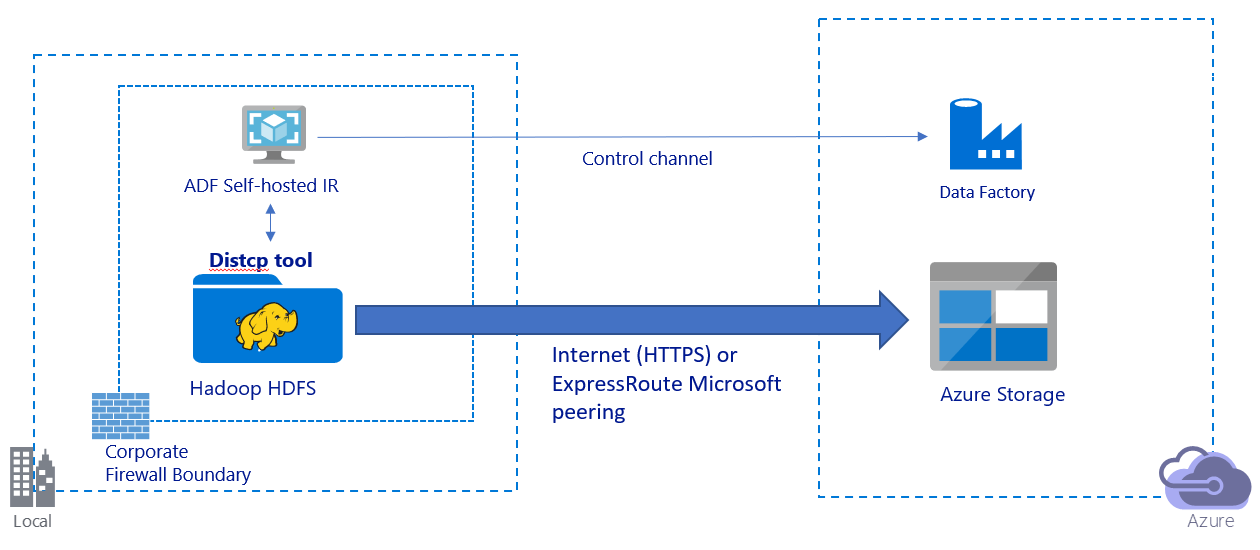
- 이 아키텍처에서 데이터는 공용 인터넷을 통해 HTTPS를 사용하여 안전하게 전송됩니다.
- 공용 네트워크 환경에서 Data Factory DistCp 모드를 사용하는 것이 좋습니다. 기존의 강력한 클러스터를 활용하면 최상의 복사 처리량을 달성할 수 있습니다. 또한 Data Factory에서 유연한 스케줄링 및 통합 모니터링 경험의 이점을 얻을 수 있습니다.
- 이 아키텍처의 경우 DistCp 명령을 Hadoop 클러스터에 제출하고 복사 상태를 모니터링하려면 회사 방화벽 뒤의 Windows 머신에 Data Factory 자체 호스팅 통합 런타임을 설치해야 합니다. 머신은 데이터를 이동하는 엔진이 아니기 때문에(제어만을 목적으로 함) 머신의 용량은 데이터 이동 처리량에 영향을 주지 않습니다.
- DistCp 명령의 기존 매개 변수가 지원됩니다.
이 이미지는 프라이빗 링크를 통해 데이터를 마이그레이션하는 것을 보여줍니다.
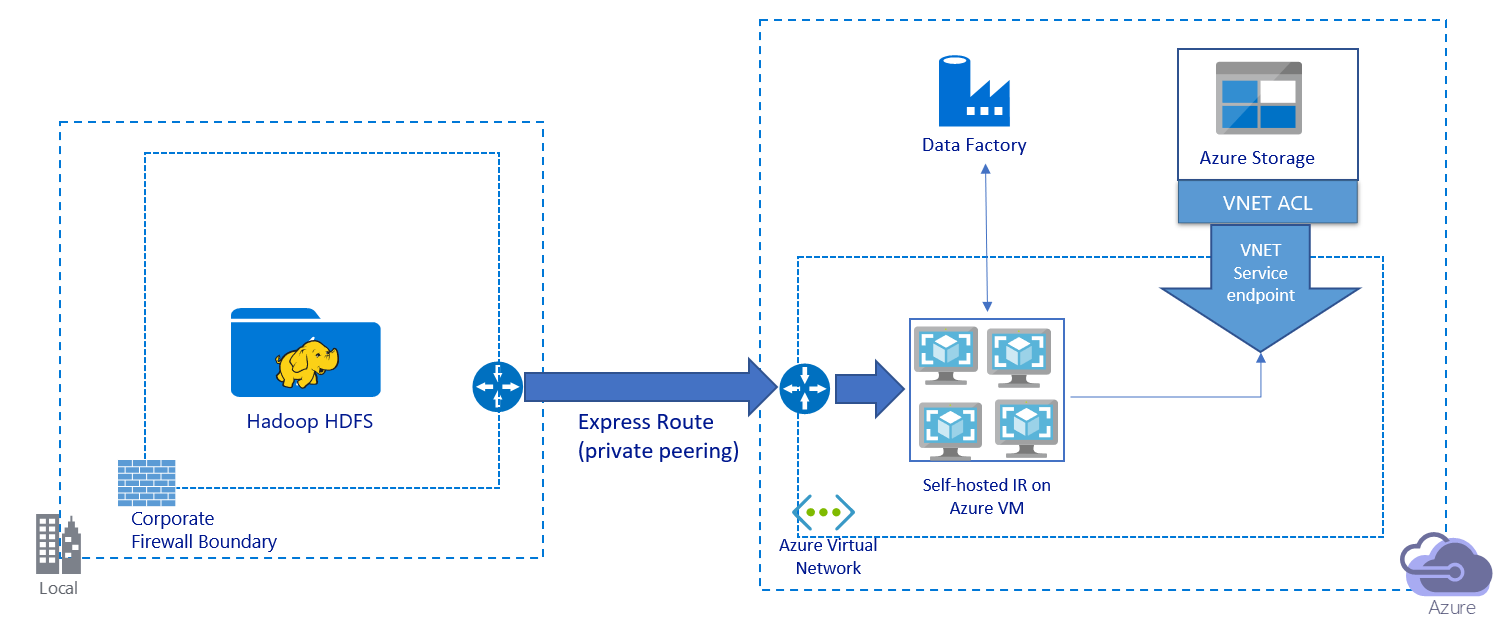
- 이 아키텍처에서 데이터는 Azure ExpressRoute를 통한 개인 피어링 링크를 통해 마이그레이션됩니다. 데이터는 공용 인터넷을 통과하지 않습니다.
- DistCp 도구는 Azure Storage 가상 네트워크 엔드포인트를 사용하는 ExpressRoute 개인 피어링을 지원하지 않습니다. 통합 런타임을 통해 Data Factory의 기본 기능을 사용하여 데이터를 마이그레이션하는 것이 좋습니다.
- 이 아키텍처의 경우 Azure 가상 네트워크의 Windows VM에 Data Factory 자체 호스팅 통합 런타임을 설치해야 합니다. VM을 수동으로 스케일 업하거나 여러 VM으로 스케일 아웃하여 네트워크 및 스토리지 IOPS 또는 대역폭을 최대한 활용할 수 있습니다.
- 각 Azure VM(Data Factory 자체 호스팅 통합 런타임이 설치됨)에 대해 시작하는 권장 구성은 32 vCPU 및 128GB 메모리의 Standard_D32s_v3입니다. 데이터 마이그레이션 중에 VM의 CPU 및 메모리 사용량을 모니터링하여 성능 향상을 위해 VM을 스케일 업해야 하는지 아니면 비용을 줄이기 위해 VM을 스케일 다운해야 하는지 확인할 수 있습니다.
- 단일 자체 호스팅 통합 런타임과 최대 4개의 VM 노드를 연결하여 스케일 아웃할 수도 있습니다. 자체 호스팅된 통합 런타임에 대해 실행되는 단일 복사 작업은 파일 세트를 자동으로 분할하고 모든 VM 노드를 사용하여 파일을 병렬로 복사합니다. 고가용성을 위해 데이터 마이그레이션 중에 단일 실패 지점 시나리오를 방지하기 위해 두 개의 VM 노드로 시작하는 것이 좋습니다.
- 이 아키텍처를 사용하면 초기 스냅샷 데이터 마이그레이션 및 델타 데이터 마이그레이션을 사용할 수 있습니다.
구현 모범 사례
데이터 마이그레이션을 구현할 때 이러한 모범 사례를 따르는 것이 좋습니다.
인증 및 자격 증명 관리
- HDFS에 인증하려면 Windows (Kerberos) 또는 익명을 사용할 수 있습니다.
- Azure Blob 스토리지에 연결하기 위해 여러 인증 유형이 지원됩니다. Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다. Microsoft Entra ID의 자동 관리 Data Factory ID를 기반으로 빌드된 관리 ID를 사용하면 연결된 서비스 정의에 자격 증명을 제공하지 않고도 파이프라인을 구성할 수 있습니다. 또는 서비스 주체, 공유 액세스 서명 또는 스토리지 계정 키를 사용하여 Blob 스토리지에 인증할 수 있습니다.
- Data Lake Storage Gen2에 연결하기 위해 여러 인증 유형도 지원됩니다. Azure 리소스에 대한 관리 ID를 사용하는 것이 좋지만 서비스 주체 또는 스토리지 계정 키를 사용할 수도 있습니다.
- Azure 리소스에 대해 관리 ID를 사용하지 않는 경우 Data Factory 연결된 서비스를 수정하지 않고 보다 쉽게 키를 중앙에서 관리하고 순환하기 위해 Azure Key Vault에 자격 증명을 저장하는 것이 좋습니다. 이는 또한 CI/CD의 모범 사례입니다.
초기 스냅샷 데이터 마이그레이션
Data Factory DistCp 모드에서는 하나의 복사 작업을 작성하여 DistCp 명령을 제출하고 다른 매개 변수를 사용하여 초기 데이터 마이그레이션 동작을 제어할 수 있습니다.
Data Factory 네이티브 통합 런타임 모드에서는 특히 10TB 넘는 데이터를 마이그레이션하는 경우 데이터 파티션을 권장합니다. 데이터를 분할하려면 HDFS의 폴더 이름을 사용합니다. 그런 다음, 각 Data Factory 복사 작업은 한 번에 하나의 폴더 파티션을 복사할 수 있습니다. 더 나은 처리량을 위해 여러 Data Factory 복사 작업을 동시에 실행할 수 있습니다.
네트워크 또는 데이터 저장소의 일시적 문제로 인해 복사 작업이 실패하는 경우 실패한 복사 작업을 다시 실행하여 HDFS에서 특정 파티션을 다시 로드할 수 있습니다. 다른 파티션을 로드하는 다른 복사 작업은 영향을 받지 않습니다.
델타 데이터 마이그레이션
Data Factory DistCp 모드에서 DistCp 명령줄 매개 변수 -update를 사용하여 델타 데이터 마이그레이션을 위해 소스 파일과 대상 파일의 크기가 다를 때 데이터를 쓸 수 있습니다.
Data Factory 네이티브 통합 모드에서 HDFS에서 새 파일 또는 변경된 파일을 식별하는 가장 효과적인 방법은 시간 분할 명명 규칙을 사용하는 것입니다. HDFS의 데이터가 파일 또는 폴더 이름(예: /yyyy/mm/dd/file.csv)의 시간 조각 정보를 사용하여 시간 분할된 경우 파이프라인은 증분 복사할 파일 및 폴더를 쉽게 식별할 수 있습니다.
또는 HDFS의 데이터가 시간 분할되지 않은 경우 Data Factory는 LastModifiedDate 값을 사용하여 새 파일 또는 변경된 파일을 식별할 수 있습니다. Data Factory는 HDFS의 모든 파일을 스캔하고 설정된 값보다 큰 최종 수정된 타임스탬프가 있는 새 파일 및 업데이트된 파일만 복사합니다.
HDFS에 많은 파일이 있는 경우 초기 파일 검색은 필터 조건과 일치하는 파일 수에 관계없이 시간이 오래 걸릴 수 있습니다. 이 시나리오에서는 먼저 초기 스냅샷 마이그레이션에 사용한 것과 동일한 파티션을 사용하여 데이터를 분할하는 것이 좋습니다. 그런 다음, 파일 검색을 병렬로 수행할 수 있습니다.
가격 견적
HDFS에서 Azure Blob 스토리지로 데이터를 마이그레이션하는 경우 다음 파이프라인을 고려하세요.
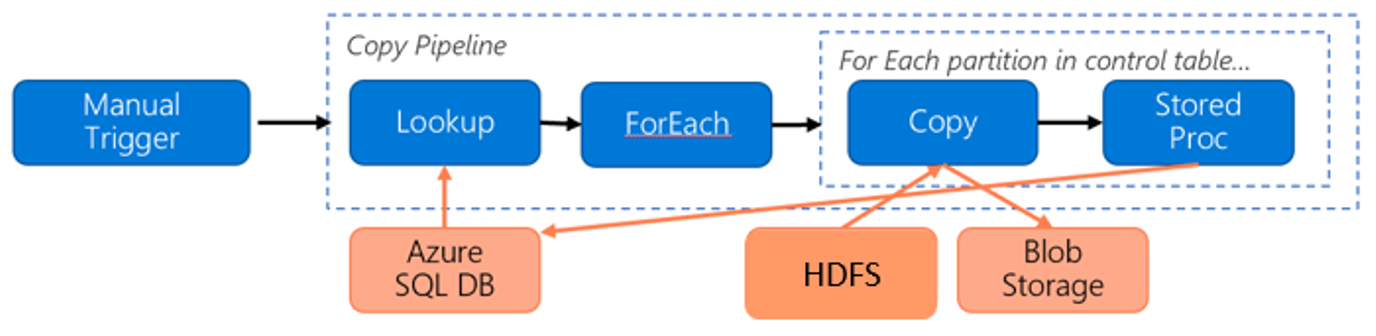
다음 정보를 가정하겠습니다.
- 총 데이터 볼륨은 1PB입니다.
- Data Factory 네이티브 통합 런타임 모드를 사용하여 데이터를 마이그레이션합니다.
- 1PB는 1,000개의 파티션으로 나뉘고 각 복사 작업은 하나의 파티션을 이동합니다.
- 각 복사 작업은 네 대의 머신과 연결되어 500MBps의 처리량을 달성하는 단일 자체 호스팅 통합 런타임으로 구성됩니다.
- ForEach 동시성은 4로 설정되고 집계 처리량은 2GBps입니다.
- 마이그레이션을 완료하는 데 총 146시간이 소요됩니다.
다음은 가정에 따라 예상되는 가격입니다.
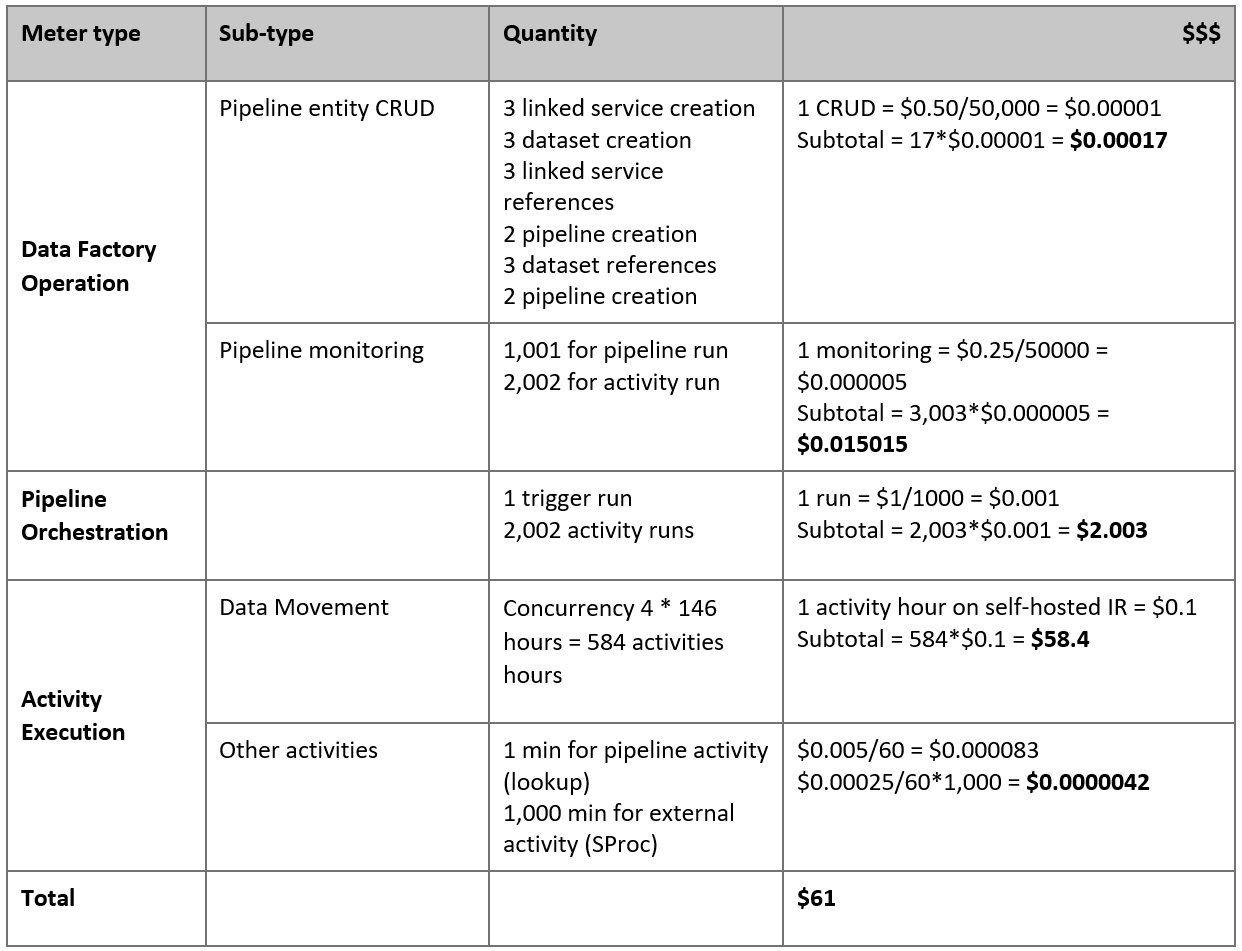
참고 항목
가상의 가격 책정 예제입니다. 실제 가격은 사용자 환경의 실제 처리량에 따라 달라집니다. 자체 호스팅된 통합 런타임이 설치된 Azure Windows VM의 가격은 포함되지 않습니다.
추가 참조
- HDFS 커넥터
- Azure Blob 스토리지 커넥터
- Azure Data Lake Storage Gen2 커넥터
- 복사 작업 성능 조정 가이드
- 자체 호스팅 통합 런타임 만들기 및 구성
- 자체 호스팅 통합 런타임 고가용성 및 확장성
- 데이터 이동 보안 고려 사항
- Azure Key Vault에 자격 증명 저장.
- 시간 분할 파일 이름에 따라 증분 방식으로 파일 복사
- LastModifiedDate에 따라 새 파일 및 변경된 파일 복사
- Data Factory 가격 책정 페이지