MLflow 모델은 다양한 다운스트림 도구(예: Apache Spark에 대한 일괄 처리 유추 또는 REST API를 통한 실시간 서비스)에서 사용할 수 있는 기계 학습 모델을 패키징하기 위한 표준 형식입니다. 이 형식은 다양한 모델의 서비스 및 유추 플랫폼에서 이해할 수 있는 다양한 버전(Python 함수, Pytorch, sklearn 등)으로 모델을 저장할 수 있는 규칙을 정의합니다.
스트리밍 모델을 기록하고 점수를 매기는 방법을 알아보려면 스트리밍 모델을 저장하고 로드하는 방법을 참조하세요.
MLflow 3 은 메트릭 및 매개 변수와 같은 자체 메타데이터를 사용하여 새로운 전용 LoggedModel 개체를 도입하여 MLflow 모델에 상당한 향상된 기능을 제공합니다. 자세한 내용은 MLflow 로깅된 모델을 사용하여 모델 추적 및 비교를 참조하세요.
모델을 기록하고 로드
모델을 기록할 때 MLflow는 자동으로 requirements.txt 로그 및 conda.yaml 파일을 기록합니다. 이러한 파일을 사용하여 모델 개발 환경을 다시 만들고 사용하거나 virtualenv 또는 conda(권장) 를 사용하여 종속성을 다시 설치할 수 있습니다.
중요
Anaconda Inc.는 anaconda.org 채널에 대한 서비스 약관을 업데이트했습니다. 새로운 서비스 약관에 따라 Anaconda의 패키징 및 배포에 의존하는 경우 상업용 라이선스가 필요할 수 있습니다. 자세한 내용은 Anaconda Commercial Edition FAQ를 참조하세요. Anaconda 채널의 사용은 해당 서비스 약관에 따라 관리됩니다.
v1.18 이전에 기록된 MLflow 모델(Databricks Runtime 8.3 ML 이하)은 기본적으로 conda defaults 채널(https://repo.anaconda.com/pkgs/)을 종속성으로 로깅했습니다. 이 라이선스 변경으로 인해 Databricks는 MLflow v1.18 이상을 사용하여 기록된 모델에 대한 채널 defaults 사용을 중지했습니다. 로깅된 기본 채널은 이제 conda-forge(으)로, 관리되는 커뮤니티 https://conda-forge.org/를 가리킵니다.
모델에 대한 conda 환경에서 defaults 채널을 제외하지 않고 MLflow v1.18 이전 모델을 로깅한 경우 해당 모델은 의도하지 않았을 수 있는 defaults 채널에 대한 종속성을 가질 수 있습니다.
모델에 이 종속성이 있는지 여부를 수동으로 확인하려면 기록된 모델로 패키지된 channel 파일의 conda.yaml 값을 검사할 수 있습니다. 예를 들어 채널 종속성이 있는 conda.yaml 모델의 defaults 모양은 다음과 같습니다.
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks는 Anaconda와의 관계에서 Anaconda 리포지토리를 사용하여 모델과 상호 작용하는 것이 허용되는지 여부를 확인할 수 없으므로 Databricks는 고객이 변경하도록 강요하지 않습니다. Databricks 사용을 통한 Anaconda.com 리포지토리 사용이 Anaconda의 조건에 따라 허용되는 경우 어떠한 조치도 취할 필요가 없습니다.
모델 환경에서 사용되는 채널을 변경하려면 모델을 모델 레지스트리에 새 conda.yaml항목으로 다시 등록할 수 있습니다.
conda_env의 log_model() 매개 변수에 채널을 지정하여 이 작업을 수행할 수 있습니다.
log_model() API에 대한 자세한 내용은 작업 중인 모델 버전에 대한 MLflow 설명서(예: scikit-learn용 log_model)를 참조하세요.
conda.yaml 파일에 대한 자세한 내용은 MLflow 설명서를 참조하세요.
API 명령
MLflow 추적 서버에 모델을 기록하려면 mlflow.<model-type>.log_model(model, ...)을 사용합니다.
유추 또는 추가 개발을 위해 이전에 기록된 모델을 로드하려면 mlflow.<model-type>.load_model(modelpath)사용합니다. 여기서 modelpath 다음 중 하나입니다.
- 모델 경로(예:
models:/{model_id})(MLflow 3 만 해당) - 실행 상대 경로(예:
runs:/{run_id}/{model-path}) - Unity 카탈로그 볼륨 경로(예:
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - 로 시작하는 MLflow 관리 아티팩트 스토리지 경로
dbfs:/databricks/mlflow-tracking/ -
등록된 모델 경로입니다(예:
models:/{model_name}/{model_stage}).
MLflow 모델을 로드하는 옵션의 전체 목록은 MLflow 설명서
Python MLflow 모델의 경우 추가 옵션은 모델을 일반적인 Python 함수로 로드하는 데 mlflow.pyfunc.load_model()을 사용하는 것입니다.
다음 코드 조각을 사용하여 모델을 로드하고 데이터 요소를 채점할 수 있습니다.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
또는 모델을 Apache Spark UDF로 내보내서 일괄 처리 작업 또는 실시간 Spark 스트리밍 작업으로 Spark 클러스터에서 채점하는 데 사용할 수 있습니다.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
로그 모델 종속성
모델을 정확하게 로드하려면 모델 종속성이 올바른 버전으로 Notebook 환경에 로드되었는지 확인해야 합니다. Databricks Runtime 10.5 ML 이상에서 MLflow는 현재 환경과 모델의 종속성 간에 불일치가 감지되면 경고합니다.
모델 종속성 복원을 간소화하는 추가 기능은 Databricks Runtime 11.0 ML 이상에 포함되어 있습니다. Databricks Runtime 11.0 ML 이상에서는 pyfunc 버전 모델의 경우 mlflow.pyfunc.get_model_dependencies를 호출하여 모델 종속성을 검색하고 다운로드할 수 있습니다. 이 함수는 %pip install <file-path>를 사용하여 설치할 수 있는 종속성 파일의 경로를 반환합니다. 모델을 PySpark UDF로 로드하는 경우 env_manager="virtualenv" 호출에서 mlflow.pyfunc.spark_udf를 지정합니다. 이렇게 하면 PySpark UDF의 컨텍스트에서 모델 종속성이 복원되며 외부 환경에는 영향을 주지 않습니다.
MLflow 버전 1.25.0 이상을 수동으로 설치하여 Databricks Runtime 10.5 이하에서 이 기능을 사용할 수도 있습니다.
%pip install "mlflow>=1.25.0"
모델 종속성(Python 및 비 Python) 및 아티팩트를 기록하는 방법에 대한 자세한 내용은 로그 모델 종속성을 참조하세요.
모델 서비스 제공에 대한 모델 종속성 및 사용자 지정 아티팩트를 기록하는 방법을 알아봅니다.
MLflow UI에서 자동으로 생성된 코드 조각
Azure Databricks Notebook에서 모델을 기록하면 Azure Databricks는 모델을 로드하고 실행하는 데 복사하고 사용할 수 있는 코드 조각을 자동으로 생성합니다. 이러한 코드 조각을 보려면 다음을 수행합니다.
- 모델을 생성한 실행에 대한 실행 화면으로 이동합니다. (실행 화면을 표시하는 방법은 노트북 실험 보기를 참조하십시오.)
- Artifacts 섹션으로 스크롤합니다.
- 기록된 모델의 이름을 클릭합니다. 기록된 모델을 로드하고 Spark 또는 pandas 데이터 프레임에서 예측을 하는 데 사용할 수 있는 코드가 표시되는 패널이 오른쪽에 열립니다.
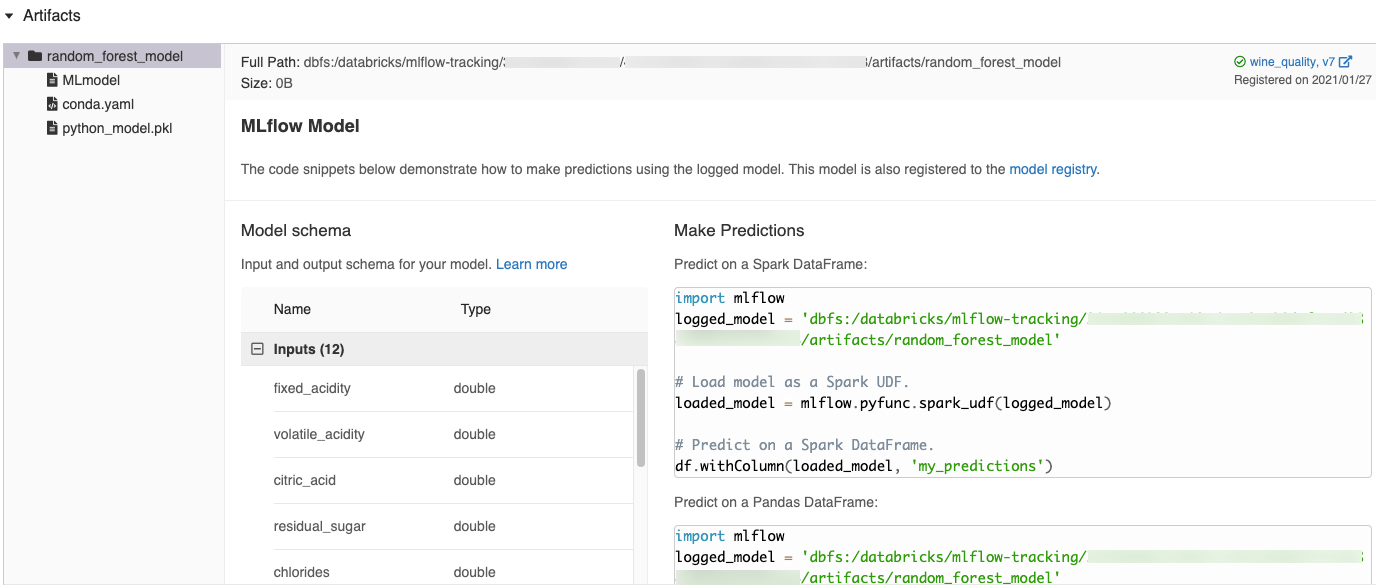
예제
기록 모델 예제는 기계 학습 모델의 학습 실행 추적 예제를 참조하세요.
모델 레지스트리에 모델 등록
MLflow 모델의 전체 수명 주기를 관리하는 UI 및 API 집합을 제공하는 중앙 집중식 모델 저장소인 MLflow 모델 레지스트리에 모델을 등록할 수 있습니다. 모델 레지스트리를 사용하여 Databricks Unity 카탈로그에서 모델을 관리하는 방법에 대한 지침은 Unity 카탈로그모델 수명 주기 관리를 참조하세요. 작업 영역 모델 레지스트리를 사용하려면 작업 영역 모델 레지스트리(레거시)를 사용하여 모델 수명 주기 관리를 참조하세요.
MLflow 3을 사용하여 만든 모델이 Unity 카탈로그 모델 레지스트리에 등록되면 모든 실험 및 작업 영역에서 하나의 중앙 위치에서 매개 변수 및 메트릭과 같은 데이터를 볼 수 있습니다. 자세한 내용은 MLflow 3의 모델 레지스트리 개선 사항을 참조하세요.
API를 사용하여 모델을 등록하려면 다음 명령을 사용합니다.
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Unity 카탈로그 볼륨에 모델 저장
모델을 로컬에 저장하려면 mlflow.<model-type>.save_model(model, modelpath)을 사용합니다.
modelpath는 Unity 카탈로그 볼륨의 경로여야 합니다. 예를 들어 Unity 카탈로그 볼륨 위치 dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models 사용하여 프로젝트 작업을 저장하는 경우 모델 경로 /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models사용해야 합니다.
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
MLlib 모델의 경우 ML 파이프라인을 사용합니다.
모델 아티팩트 다운로드
다양한 API를 사용하여 등록된 모델에 대해 기록된 모델 아티팩트(예: 모델 파일, 플롯 및 메트릭)를 다운로드할 수 있습니다.
Python API 예제:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Java API 예제:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI 명령 예제:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
온라인 서비스 제공을 위한 모델 배포
메모
모델을 배포하기 전에 모델이 제공될 수 있는지 확인하는 것이 좋습니다. 배포 전에 mlflow.models.predict 사용하여 모델의 유효성을 검사하는방법에 대한 MLflow 설명서를 참조하세요.
Mosaic AI 모델 서비스 사용하여 Unity 카탈로그 모델 레지스트리에 등록된 기계 학습 모델을 REST 엔드포인트로 호스트합니다. 이러한 엔드포인트는 모델 버전의 가용성에 따라 자동으로 업데이트됩니다.