자습서: Azure Data Factory를 사용하여 HDInsight에서 주문형 Apache Hadoop 클러스터 만들기
이 자습서에서는 Azure Data Factory를 사용하여 Azure HDInsight에서 주문형 Apache Hadoop 클러스터를 만드는 방법을 알아봅니다. 그런 후 Azure Data Factory에서 데이터 파이프라인을 사용하여 Hive 작업을 실행하고 클러스터를 삭제합니다. 이 자습서를 마치면 클러스터 생성, 작업 실행 및 클러스터 일정에 따라 삭제가 수행되는 operationalize 빅 데이터 작업을 실행하는 방법을 알아봅니다.
이 자습서에서 다루는 작업은 다음과 같습니다.
- Azure Storage 계정 만들기
- Azure Data Factory 작업 이해
- Azure Portal을 사용하여 데이터 팩터리 만들기
- 연결된 서비스 생성
- 파이프라인을 만듭니다.
- 파이프라인 트리거
- 파이프라인 모니터링
- 출력 확인
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
PowerShell Az 모듈이 설치되었습니다.
Microsoft Entra 서비스 주체입니다. 서비스 주체를 만든 후에는 연결된 문서의 지침을 사용하여 애플리케이션 ID 및 인증 키를 검색해야 합니다. 이 자습서의 뒷부분에서 이러한 값이 필요합니다. 또한 서비스 주체가 클러스터를 만든 구독 또는 리소스 그룹의 참가자 역할의 구성원인지 확인합니다. 필요한 값을 검색하고 적절한 역할을 할당하는 방법에 대한 지침은 Microsoft Entra 서비스 주체 만들기를 참조하세요.
예비 Azure 개체 만들기
이 섹션에서는 주문형으로 만드는 HDInsight 클러스터에 사용될 다양한 개체를 만듭니다. 생성된 스토리지 계정에는 클러스터에서 실행되는 샘플 Apache Hive 작업을 시뮬레이션하는 데 사용하는 샘플 HiveQL 스크립트(partitionweblogs.hql)가 포함됩니다.
이 섹션에서는 Azure PowerShell 스크립트를 사용하여 스토리지 계정을 만들고 스토리지 계정 내의 필수 파일에 추가로 복사합니다. 이 섹션에 있는 Azure PowerShell 샘플 스크립트는 다음 작업을 수행합니다.
- Azure에 로그인합니다.
- Azure 리소스 그룹을 만듭니다.
- Azure Storage 계정을 만듭니다.
- 스토리지 계정에 Blob 컨테이너를 만듭니다.
- 샘플 HiveQL 스크립트(partitionweblogs.hql)를 Blob 컨테이너에 복사합니다. 샘플 스크립트를 이미 다른 공용 Blob 컨테이너에서 사용할 수 있습니다. 아래의 PowerShell 스크립트는 만든 Azure Storage 계정에 이러한 파일의 복사본을 만듭니다.
스토리지 계정 만들기 및 파일 복사
Important
스크립트로 생성될 Azure 리소스 그룹 및 Azure Storage 계정 이름을 지정합니다. 스크립트에 출력된 리소스 그룹 이름, 스토리지 계정 이름 및 스토리지 계정 키를 적어 둡니다. 다음 섹션에서 필요합니다.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
스토리지 계정 확인
- Azure Portal에 로그인합니다.
- 왼쪽에서 모든 서비스>일반>리소스 그룹으로 이동합니다.
- PowerShell 스크립트에서 만든 리소스 그룹 이름을 선택합니다. 나열된 리소스 그룹이 너무 많은 경우 필터를 사용합니다.
- 개요 보기에서 리소스 그룹을 다른 프로젝트와 공유하지 않는 한, 하나의 리소스가 나열됩니다. 그 리소스는 이전에 지정한 이름의 스토리지 계정입니다. 스토리지 계정 이름을 선택합니다.
- 컨테이너 타일을 선택합니다.
- adfgetstarted 컨테이너를 선택합니다.
hivescripts라는 폴더가 표시됩니다. - 이 폴더를 열고 예제 스크립트 파일 partitionweblogs.hql이 포함되어 있는지 확인합니다.
Azure Data Factory 작업 이해
Azure Data Factory는 데이터의 이동 및 변환을 조율하고 자동화합니다. Azure Data Factory는 입력 데이터 조각을 처리하고 처리가 완료되면 클러스터를 삭제하기 위해 HDInsight Hadoop 클러스터를 적시에 만들 수 있습니다.
Azure Data Factory에서 데이터 팩터리에는 하나 이상의 데이터 파이프라인이 포함될 수 있습니다. 데이터 파이프라인은 하나 이상의 활동을 포함합니다. 활동에는 다음 두 가지 유형이 있습니다.
- 데이터 이동 활동. 데이터 이동 활동을 사용하여 원본 데이터 저장소에서 대상 데이터 저장소로 데이터를 이동합니다.
- 데이터 변환 활동 데이터 변환 활동을 사용하여 데이터를 변환/처리합니다. HDInsight Hive 작업은 Data Factory에서 지원하는 데이터 변환 활동 중 하나입니다. 이 자습서에서는 Hive 변환 작업을 사용합니다.
이 문서에서는 주문형 HDInsight Hadoop 클러스터를 만들도록 Hive 작업을 구성합니다. 데이터를 처리하기 위해 작업을 실행하면 과정은 다음과 같습니다.
조각을 처리하기 위해 HDInsight Hadoop 클러스터가 자동으로 적시에 생성됩니다.
입력 데이터는 클러스터에서 HiveQL 스크립트를 실행하여 처리됩니다. 이 자습서에서 hive 작업과 관련된 HiveQL 스크립트는 다음 작업을 수행합니다.
- 기존 테이블(hivesampletable)을 사용하여 다른 테이블(HiveSampleOut)을 만듭니다.
- HiveSampleOut 테이블을 원본 hivesampletable의 특정 열로만 채웁니다.
처리가 완료된 후 HDInsight Hadoop 클러스터가 삭제되고 클러스터는 구성된 시간(timeToLive 설정) 동안 유휴 상태입니다 이 timeToLive 유휴 시간에 처리를 위해 다음 데이터 조각이 제공되면 조각을 처리하는 데 동일한 클러스터가 사용됩니다.
데이터 팩터리 만들기
Azure Portal에 로그인합니다.
왼쪽 메뉴에서
+ Create a resource>Analytics>Data Factory로 이동합니다.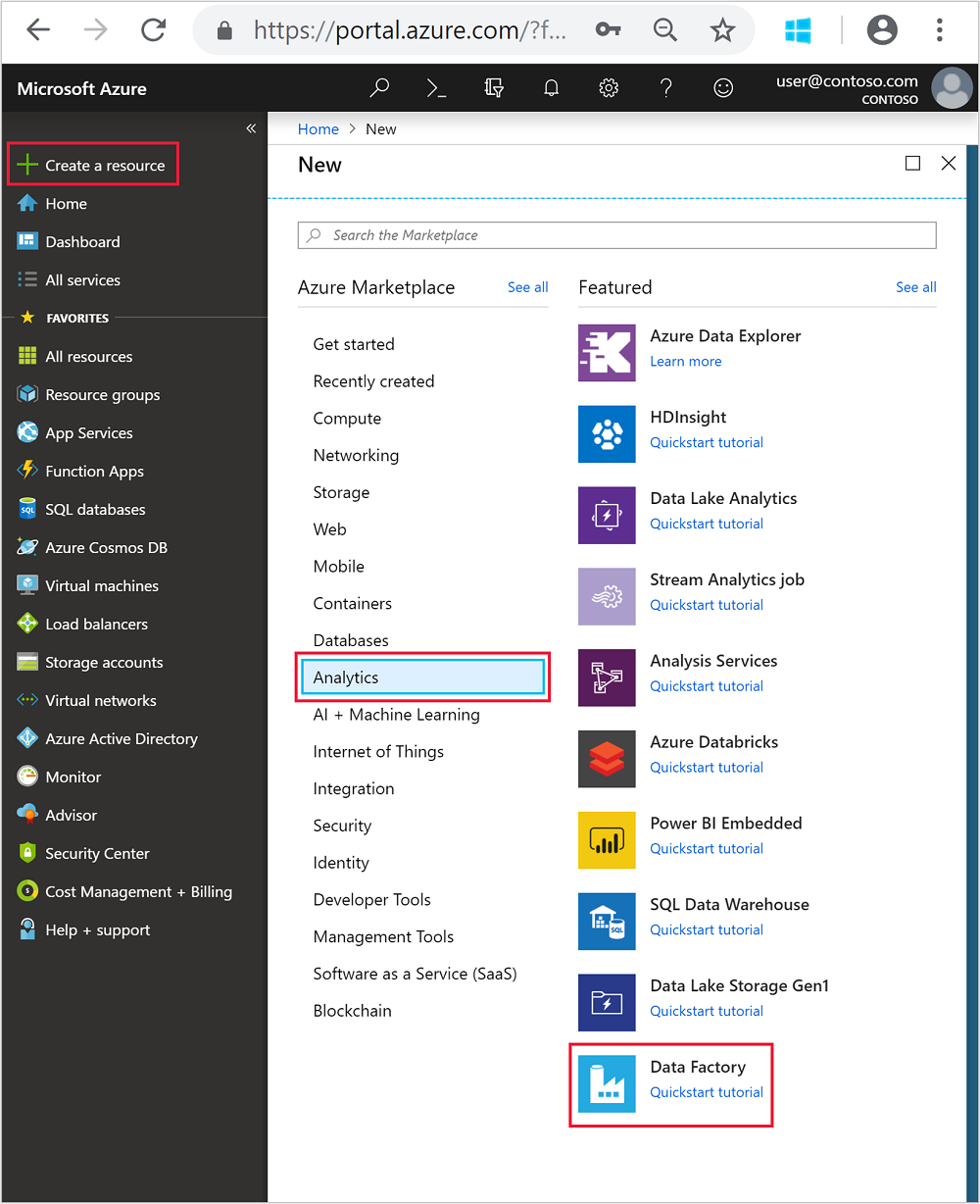
새 데이터 팩터리 타일에 대해 다음 값을 입력하거나 선택합니다.
속성 값 속성 데이터 팩터리의 이름 을 입력합니다. 이 이름은 전역적으로 고유해야 합니다. 버전 V2로 둡니다. 구독 Azure 구독을 선택합니다. Resource group PowerShell 스크립트를 사용하여 만든 리소스 그룹을 선택합니다. 위치 이 위치는 이전에 리소스 그룹을 만드는 동안 지정한 위치로 자동으로 설정됩니다. 이 자습서에서 위치는 미국 동부로 설정됩니다. GIT 사용 이 상자의 선택을 취소합니다. 
만들기를 실행합니다. 데이터 팩터리를 만드는 데는 2 ~ 4분 정도 걸릴 수 있습니다.
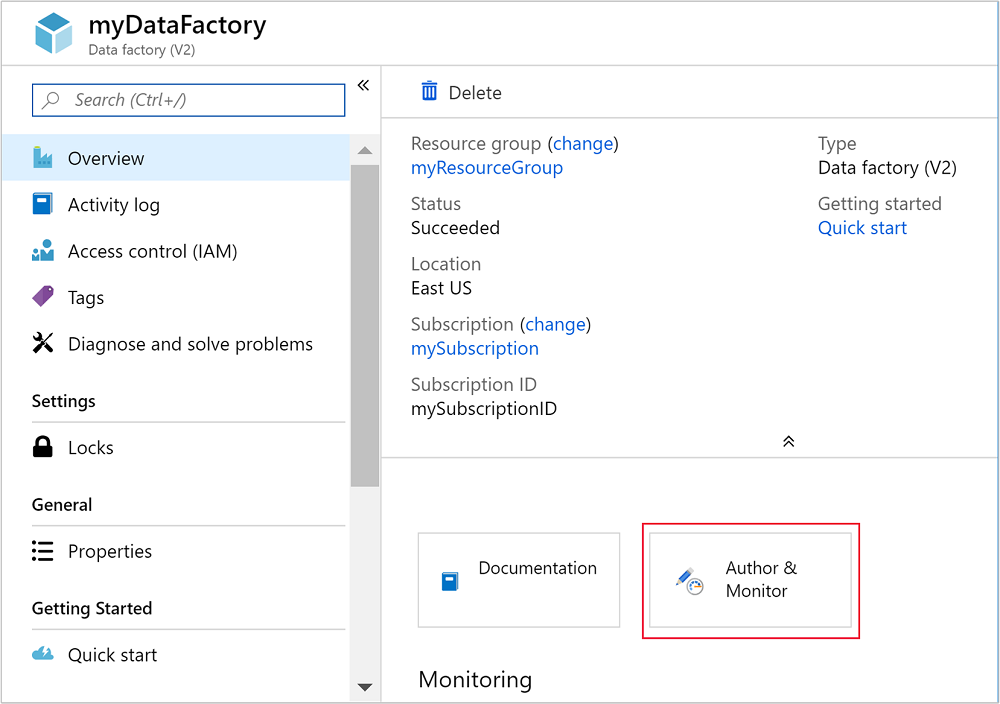
데이터 팩터리가 만들어지면 리소스로 이동 단추가 포함된 배포 성공 알림을 받게 됩니다. 리소스로 이동을 선택하여 Data Factory 기본 보기를 엽니다.
작성 및 모니터링을 선택하여 Azure Data Factory 작성 및 모니터링 포털을 시작합니다.
연결된 서비스 생성
이 섹션에서는 데이터 팩터리 내에서 연결된 2개의 서비스를 작성합니다.
- Azure Storage 계정을 데이터 팩터리에 연결하는 Azure Storage 연결된 서비스. 이 스토리지는 주문형 HDInsight 클러스터에서 사용됩니다. 또한 클러스터에서 실행되는 Hive 스크립트를 포함합니다.
- 주문형 HDInsight 연결된 서비스. Azure Data Factory는 HDInsight 클러스터를 자동으로 만들고 Hive 스크립트를 실행합니다. 그런 다음 클러스터가 미리 구성된 시간 동안 유휴 상태를 유지하면 HDInsight 클러스터를 삭제합니다.
Azure Storage 연결된 서비스 만들기
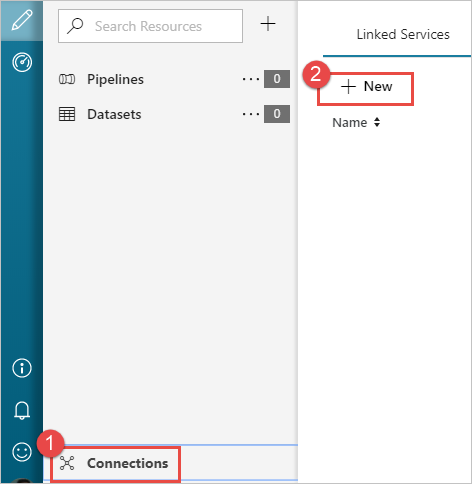
시작하기 페이지의 왼쪽 창에서 작성자 아이콘을 선택합니다.

창의 왼쪽 아래 모서리에서 연결을 선택하고 + 새로 만들기를 선택합니다.
새 연결된 서비스 대화 상자에서 Azure Blob Storage를 선택한 다음 계속을 선택합니다.
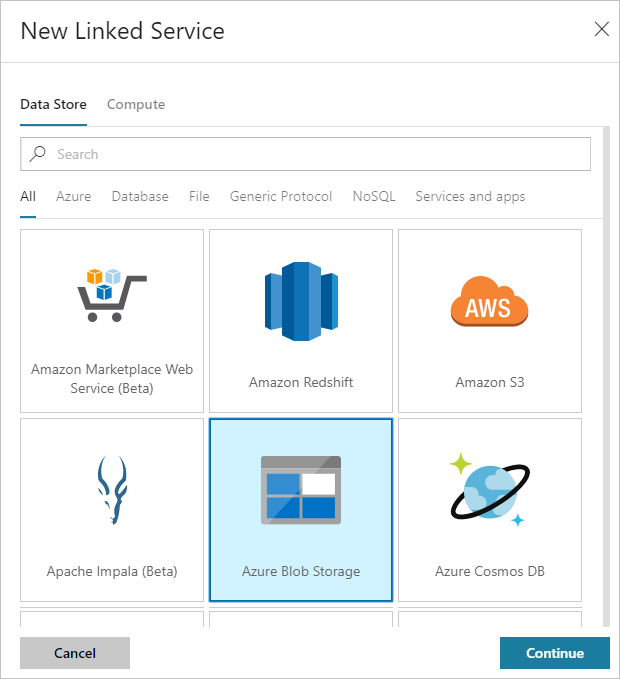
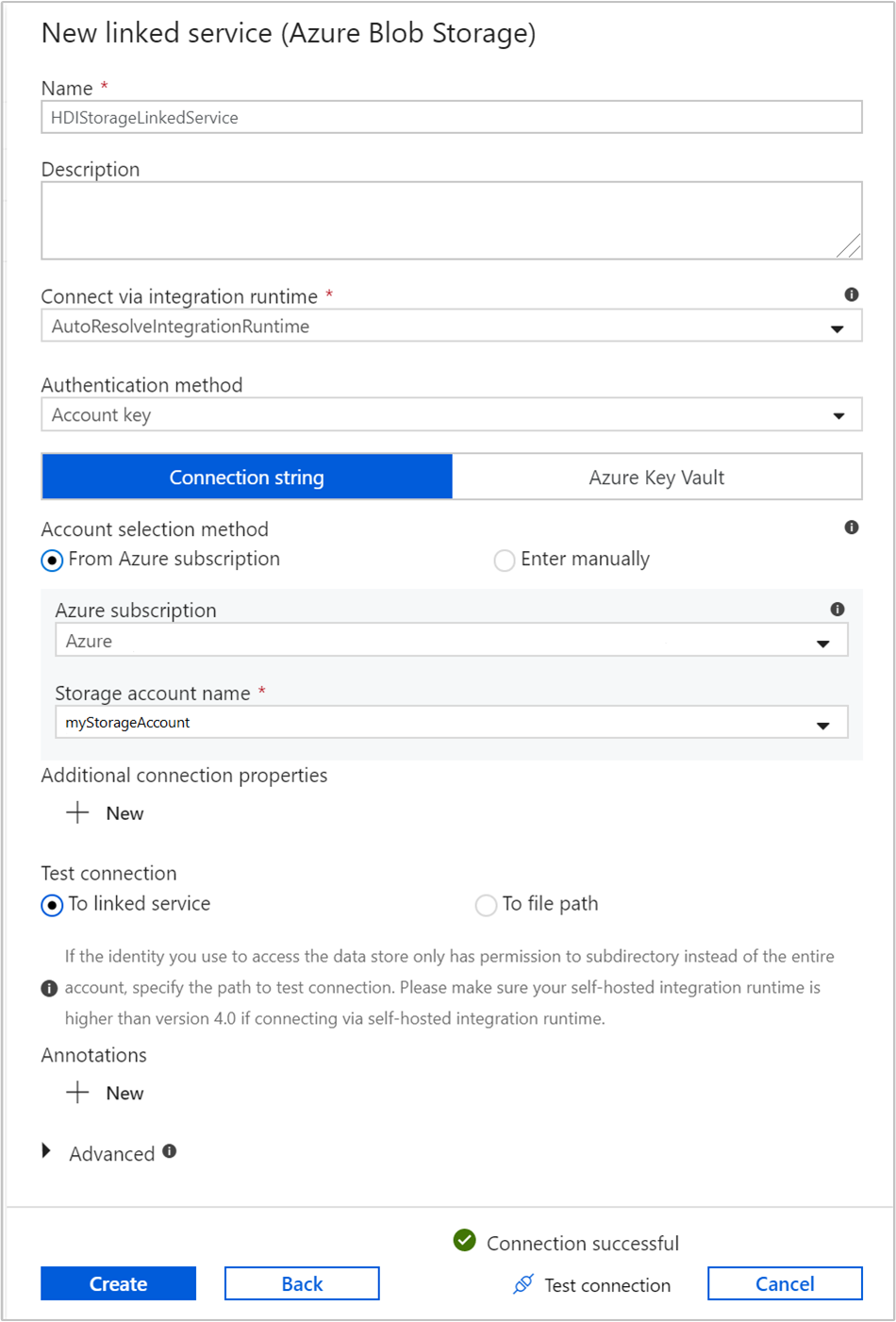
Storage 연결된 서비스에 대해 다음 값을 제공합니다.
속성 값 속성 HDIStorageLinkedService를 입력합니다.Azure 구독 드롭다운 목록에서 구독을 선택합니다. 스토리지 계정 이름 PowerShell 스크립트의 일부로 만든 Azure Storage 계정을 선택합니다. 연결 테스트를 선택하고, 성공하면 만들기를 선택합니다.
주문형 HDInsight 연결된 서비스 만들기
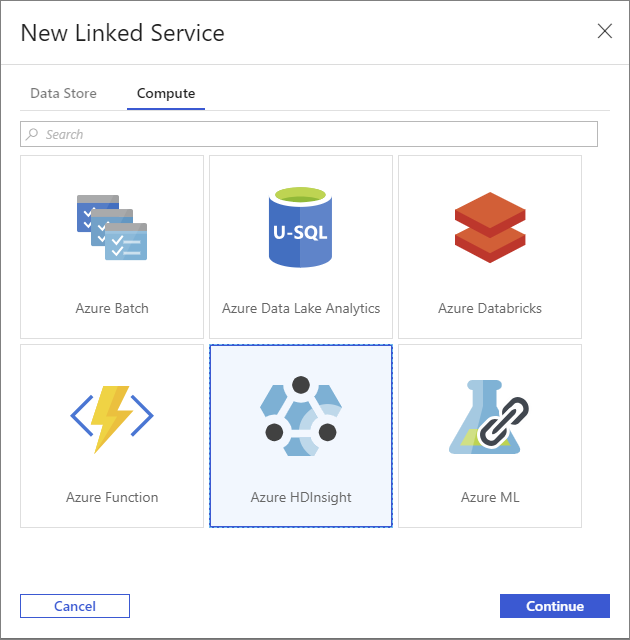
+ 새로 만들기 단추를 다시 선택하여 또 하나의 연결된 서비스를 만듭니다.
새 연결된 서비스 창에서 컴퓨팅 탭을 선택합니다.
Azure HDInsight와 계속을 차례로 선택합니다.
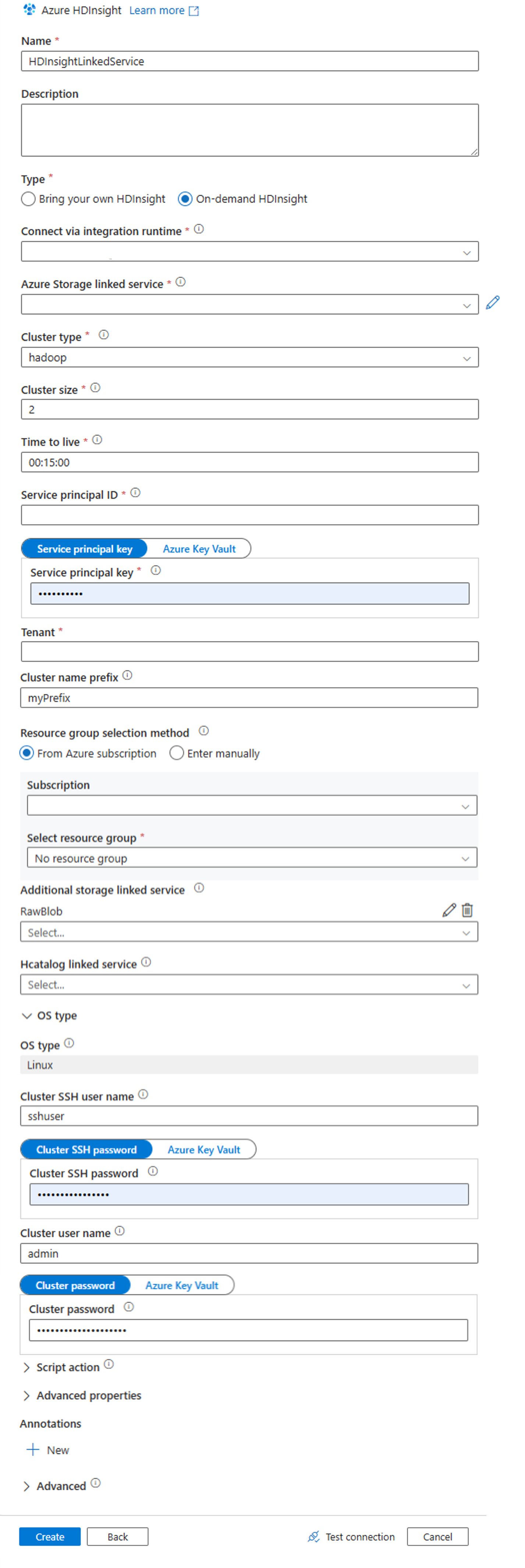
새 연결된 서비스 창에서 다음 값을 입력하고 나머지는 기본값으로 둡니다.
속성 값 속성 HDInsightLinkedService를 입력합니다.Type 주문형 HDInsight를 선택합니다. Azure Storage 연결된 서비스 HDIStorageLinkedService를 선택합니다.클러스터 유형 hadoop을 선택합니다. TTL(Time to Live) HDInsight 클러스터를 자동으로 삭제하기 전에 사용할 수 있는 기간을 지정합니다. 서비스 주체 ID 필수 구성의 일부로 만든 Microsoft Entra 서비스 주체의 애플리케이션 ID를 제공합니다. 서비스 주체 키 Microsoft Entra 서비스 주체에 대한 인증 키를 제공합니다. 클러스터 이름 접두사 데이터 팩터리에 의해 만들어진 모든 클러스터 유형에 접두사로 추가될 값을 제공합니다. 구독 드롭다운 목록에서 구독을 선택합니다. 리소스 그룹 선택 이전에 사용했던 PowerShell 스크립트의 일부로 만든 리소스 그룹을 선택합니다. OS 유형/클러스터 SSH 사용자 이름 SSH 사용자 이름(일반적으로 sshuser)을 입력합니다.OS 유형/클러스터 SSH 암호 SSH 사용자에 대한 암호를 제공합니다. OS 유형/클러스터 사용자 이름 클러스터 사용자 이름(일반적으로 admin)을 입력합니다.OS 유형/클러스터 암호 클러스터 사용자의 암호를 제공합니다. 다음으로 만들기를 선택합니다.
파이프라인을 만듭니다.
+(더하기) 단추를 선택한 다음 파이프라인을 선택합니다.
활동 도구 상자에서 HDInsight를 펼치고, Hive 활동을 파이프라인 디자이너 화면으로 끌어 옵니다. 일반 탭에서 활동의 이름을 제공합니다.
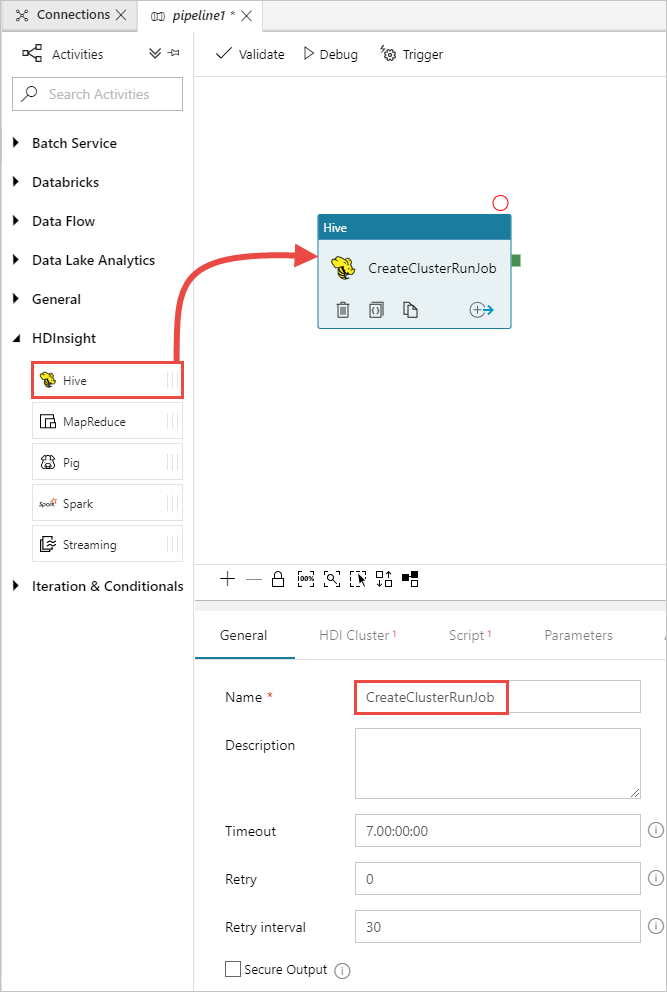
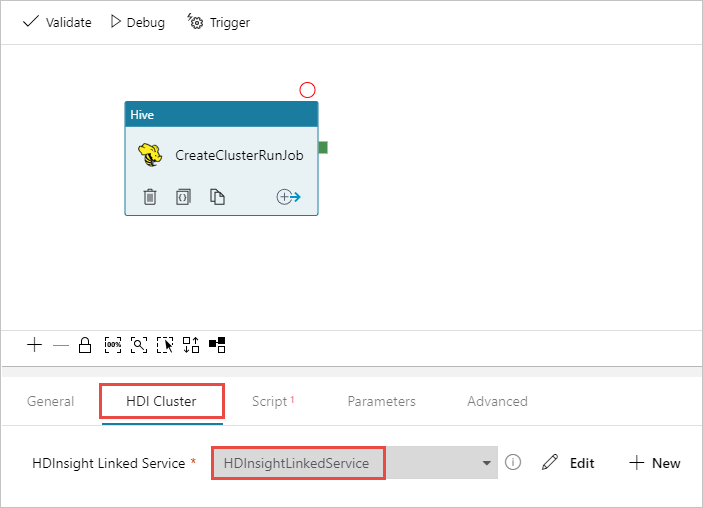
Hive 활동을 선택했는지 확인하고 HDI 클러스터 탭을 선택합니다. 그리고 HDInsight 연결 서비스 드롭다운 목록에서 HDInsight에 대해 이전에 만든 연결된 서비스인 HDInsightLinkedService를 선택합니다.
스크립트 탭을 선택하고 다음 단계를 완료합니다.
스크립트 연결된 서비스에 대해 드롭다운 목록에서 HDIStorageLinkedService를 선택합니다. 이 값은 이전에 만든 스토리지 연결된 서비스입니다.
파일 경로로 스토리지 찾아보기를 선택하고 샘플 Hive 스크립트를 사용할 수 있는 위치로 이동합니다. 이전에 PowerShell 스크립트를 실행한 경우 이 위치는
adfgetstarted/hivescripts/partitionweblogs.hql입니다.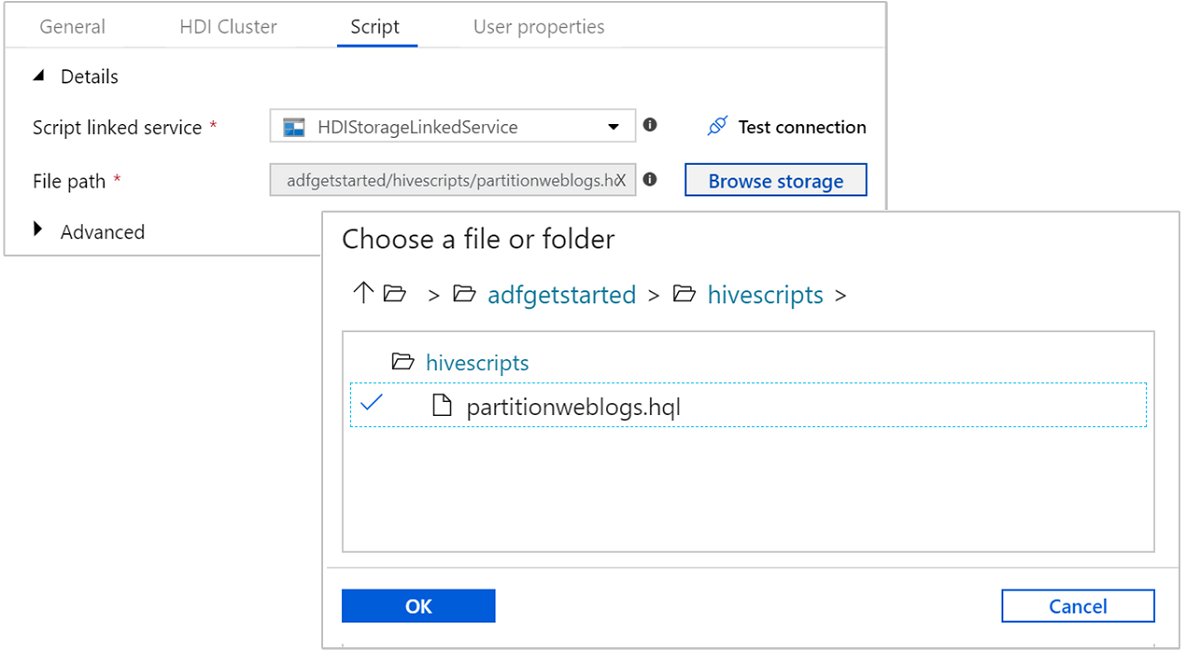
고급>매개 변수에서
Auto-fill from script를 선택합니다. 이 옵션은 런타임에 값을 필요로 하는 Hive 스크립트의 매개 변수를 찾습니다.값 텍스트 상자에서
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/형식으로 기존 폴더를 추가합니다. 경로는 대/소문자를 구분합니다. 이 경로는 스크립트의 출력이 저장되는 위치입니다. 이제 스토리지 계정이 기본적으로 필요한 보안 전송을 사용하도록 설정되어 있으므로wasbs스키마가 필요합니다.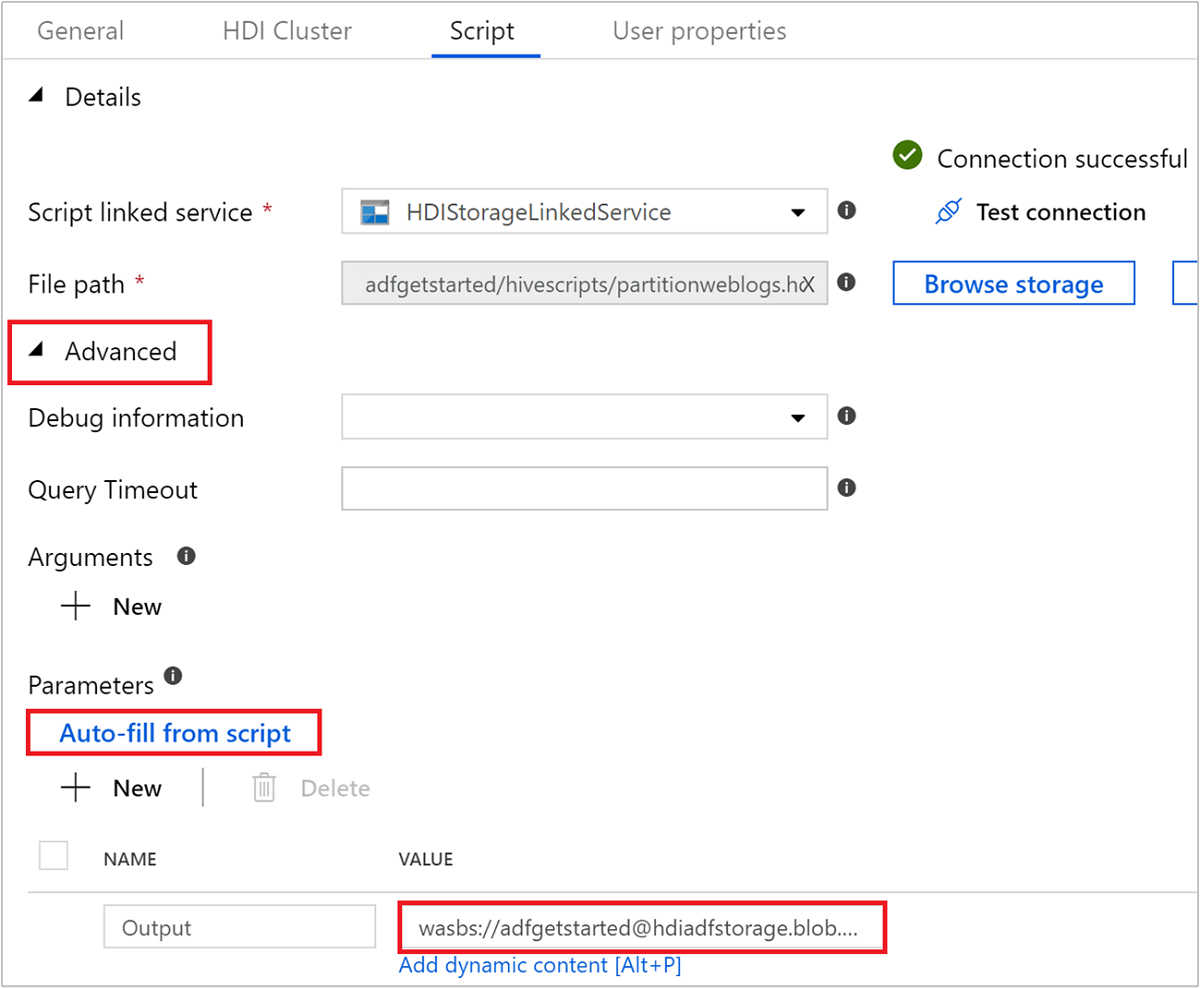
파이프라인에 대한 유효성을 검사하려면 유효성 검사를 선택합니다. >>(오른쪽 화살표) 단추를 선택하여 유효성 검사 창을 닫습니다.
마지막으로 모두 게시를 선택하여 Azure Data Factory에 아티팩트를 게시합니다.
파이프라인 트리거
디자이너 화면의 도구 모음에서 트리거 추가>지금 트리거를 선택합니다.
팝업 사이드바에서 확인을 선택합니다.
파이프라인 모니터링
왼쪽의 모니터 탭으로 전환합니다. 파이프라인 실행 목록에 파이프라인 실행이 표시됩니다. 상태 열에서 실행 상태를 확인합니다.
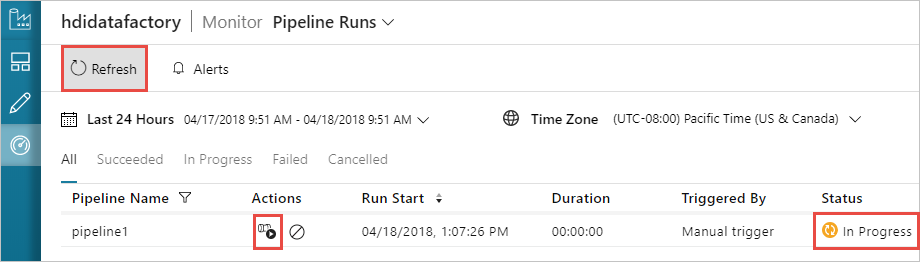
새로 고침을 선택하여 상태를 새로 고칩니다.
활동 실행 보기 아이콘을 선택하여 파이프라인와 연결된 활동 실행을 볼 수도 있습니다. 아래 스크린샷에서는 만든 파이프라인에 활동이 하나만 있기 때문에 활동 실행이 하나만 표시됩니다. 이전 보기로 돌아가려면 페이지 위쪽의 파이프라인을 선택합니다.
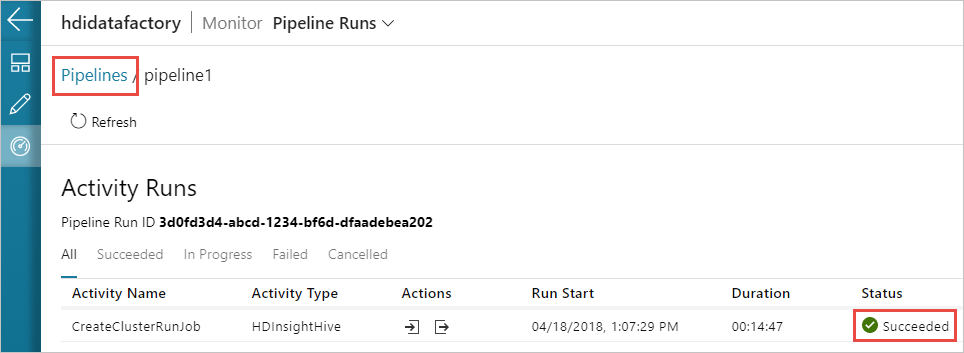
출력 확인
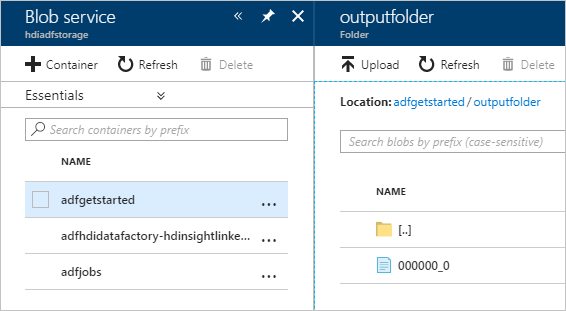
출력을 확인하려면 Azure Portal에서 이 자습서에 사용한 스토리지 계정으로 이동합니다. 다음 폴더 또는 컨테이너가 표시됩니다.
파이프라인의 일부로 실행된 Hive 스크립트의 출력을 포함하는 adfgerstarted/outputfolder가 표시됩니다.
adfhdidatafactory-<linked-service-name>-<timestamp> 컨테이너가 표시됩니다. 이 컨테이너는 파이프라인 실행의 일부로 생성된 HDInsight 클러스터의 기본 스토리지 위치입니다.
Azure Data Factory 작업 로그가 있는 adfjobs 컨테이너가 표시됩니다.
리소스 정리
주문형 HDInsight 클러스터 생성을 사용할 경우에는 HDInsight 클러스터를 명시적으로 삭제할 필요가 없습니다. 클러스터는 파이프라인을 만드는 동안 제공한 구성에 따라 삭제됩니다. 클러스터를 삭제한 후에도 해당 클러스터와 연결된 스토리지 계정이 계속 존재합니다. 이 동작은 데이터 무결성을 유지하기 위해 의도적으로 제공됩니다. 그러나 데이터를 유지하지 않으려면 만든 스토리지 계정을 삭제할 수 있습니다.
또는 이 자습서에 대해 만든 전체 리소스 그룹을 삭제할 수 있습니다. 이 프로세스는 만든 스토리지 계정 및 Azure Data Factory를 삭제합니다.
리소스 그룹 삭제
Azure Portal에 로그인합니다.
왼쪽 창에서 리소스 그룹 을 선택합니다.
PowerShell 스크립트에서 만든 리소스 그룹 이름을 선택합니다. 나열된 리소스 그룹이 너무 많은 경우 필터를 사용합니다. 이렇게 하면 리소스 그룹이 열립니다.
리소스 타일에서 리소스 그룹을 다른 프로젝트와 공유하지 않는 한 기본 스토리지 계정과 데이터 팩터리가 나열됩니다.
리소스 그룹 삭제를 선택합니다. 이렇게 하면 스토리지 계정 및 스토리지 계정에 저장된 데이터도 삭제됩니다.
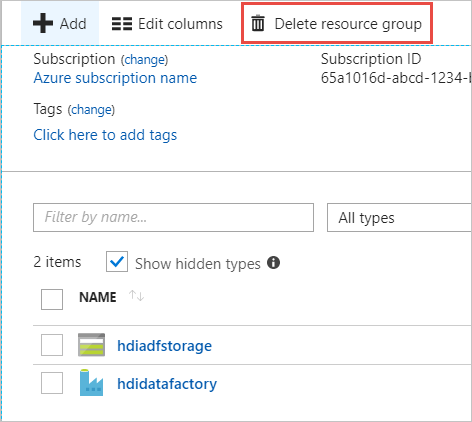
삭제를 확인하려면 리소스 그룹 이름을 입력하고 삭제를 선택합니다.
다음 단계
이 문서에서는 Azure Data Factory를 사용하여 주문형 HDInsight 클러스터를 만들고 Apache Hive 작업을 실행하는 방법을 알아보았습니다. 사용자 지정 구성을 사용하여 HDInsight 클러스터를 만드는 방법을 알아보려면 다음 문서를 계속 진행합니다.