이 문서에서는 HDInsight 클러스터에서 실행되는 Apache Spark 작업을 추적하고 디버그하는 방법을 알아봅니다. Apache Hadoop YARN UI, Spark UI 및 Spark 기록 서버를 사용하여 디버그합니다. Spark 클러스터의 머신러닝: MLLib을 사용한 식품 검사 데이터 예측 분석과 함께 제공되는 Notebook을 사용하여 Spark 작업을 시작합니다. 다음 단계를 사용하여 다른 방법(예: spark-submit)을 사용하여 제출한 애플리케이션을 추적합니다.
Azure 구독이 없는 경우, 시작하기 전에 무료 계정을 만드십시오.
필수 조건
HDInsight의 Apache Spark 클러스터. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요.
Notebook, 즉 기계 학습: MLLib를 사용하여 음식 검사 데이터에 대한 예측 분석을 실행하기 시작했어야 합니다. 이 Notebook을 실행하는 방법에 대한 지침은 링크를 따르세요.
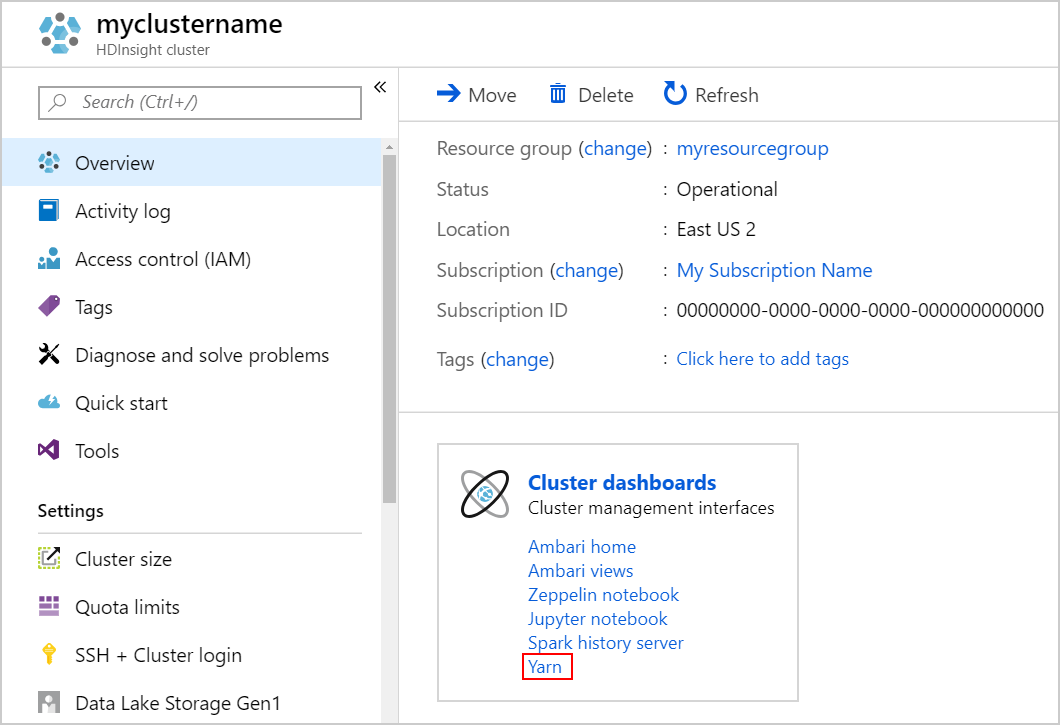
YARN UI에서 애플리케이션 추적
YARN UI를 시작합니다. 클러스터 대시보드에서 Yarn을 선택합니다.
팁 (조언)
또는 Ambari UI에서 YARN UI를 시작할 수도 있습니다. Ambari UI를 시작하려면 클러스터 대시보드에서 Ambari 홈을 선택합니다. Ambari UI에서 YARN>빠른 연결> 활성 Resource Manager >Resource Manager UI로 이동합니다.
Jupyter Notebook을 사용하여 Spark 작업을 시작했기 때문에 애플리케이션에는 remotesparkmagics (Notebook에서 시작된 모든 애플리케이션의 이름)라는 이름이 있습니다. 애플리케이션 이름에 대해 애플리케이션 ID를 선택하여 작업에 대한 자세한 정보를 가져옵니다. 이 작업은 애플리케이션 보기를 시작합니다.
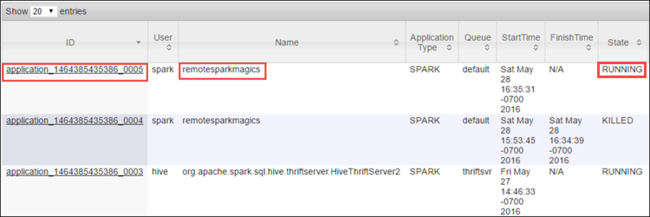
Jupyter Notebook에서 시작되는 이러한 애플리케이션의 경우 Notebook을 종료할 때까지 상태가 항상 실행 중입니다.
애플리케이션 보기에서 더 자세히 드릴다운하여 애플리케이션 및 로그(stdout/stderr)와 연결된 컨테이너를 확인할 수 있습니다. 아래와 같이 추적 URL에 해당하는 연결을 클릭하여 Spark UI를 시작할 수도 있습니다.
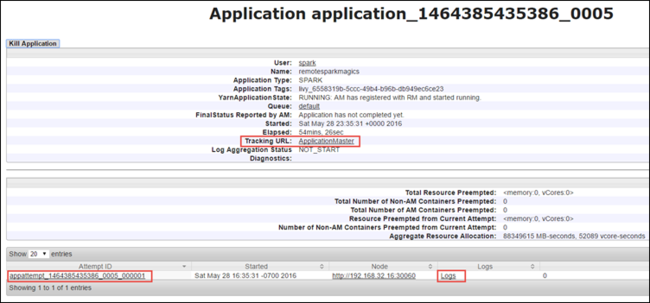
Spark UI에서 애플리케이션 추적
Spark UI에서 이전에 시작한 애플리케이션에서 생성한 Spark 작업으로 드릴다운할 수 있습니다.
Spark UI를 시작하려면 위의 화면 캡처와 같이 애플리케이션 보기에서 추적 URL에 대한 링크를 선택합니다. Jupyter Notebook에서 실행되는 애플리케이션에서 시작되는 모든 Spark 작업을 볼 수 있습니다.
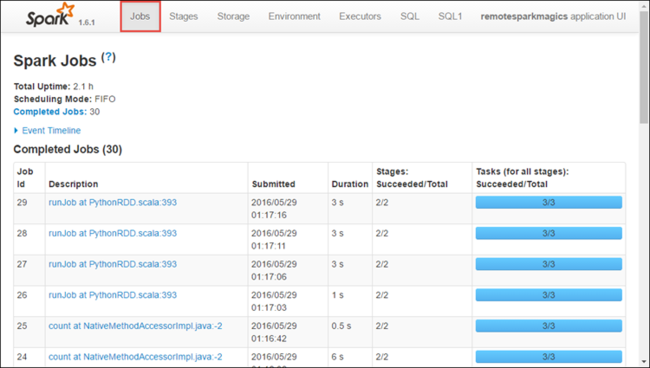
실행기 탭을 선택하여 각 실행기에 대한 처리 및 스토리지 정보를 확인합니다. 스레드 덤프 링크를 선택하여 호출 스택을 검색할 수도 있습니다.
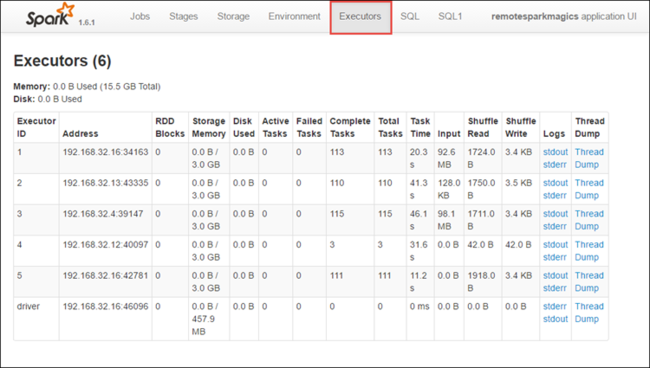
스테이지 탭을 선택하여 애플리케이션과 연결된 스테이지를 확인합니다.
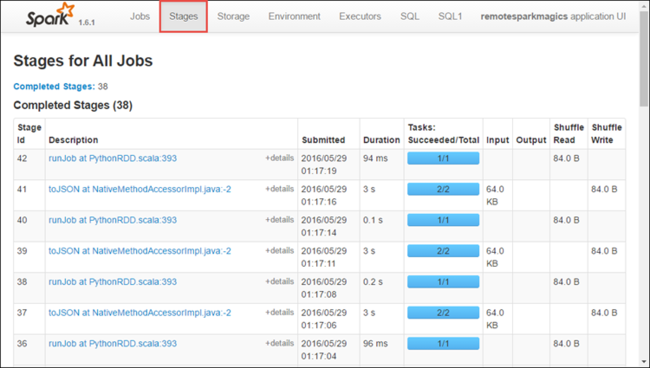
각 단계에는 아래와 같이 실행 통계를 볼 수 있는 여러 작업이 있을 수 있습니다.
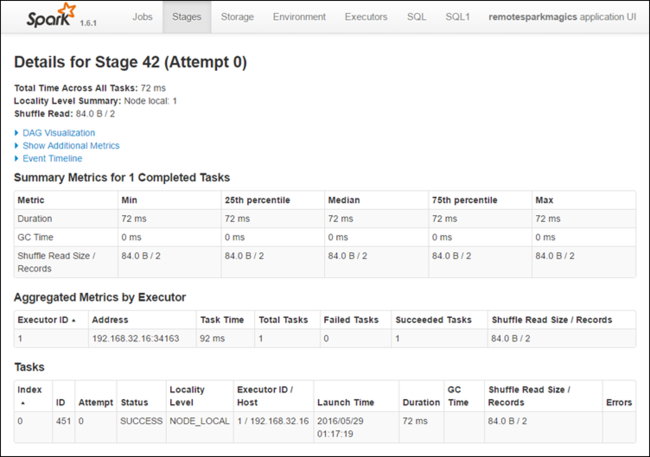
단계 세부 정보 페이지에서 DAG 시각화를 시작할 수 있습니다. 아래와 같이 페이지 맨 위에 있는 DAG 시각화 링크를 확장합니다.
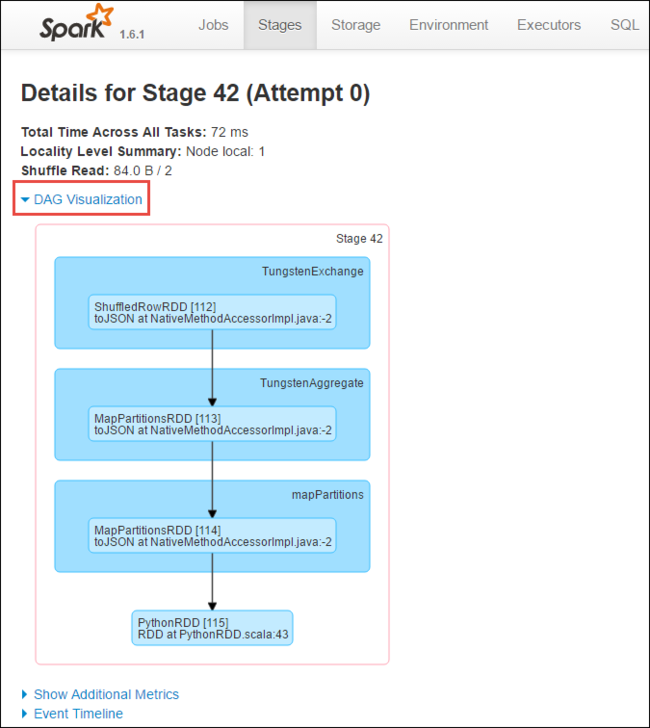
DAG 또는 Direct Aclyic Graph는 애플리케이션의 다양한 단계를 나타냅니다. 그래프의 각 파란색 상자는 애플리케이션에서 호출된 Spark 작업을 나타냅니다.
스테이지 세부 정보 페이지에서 애플리케이션 타임라인 보기를 시작할 수도 있습니다. 아래와 같이 페이지 맨 위에 있는 이벤트 타임라인 링크를 확장합니다.
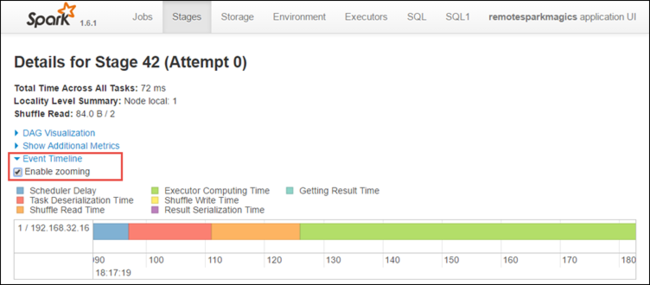
이 이미지는 타임라인의 형태로 Spark 이벤트를 표시합니다. 타임라인 보기는 작업, 작업 내 및 단계 내의 세 가지 수준에서 사용할 수 있습니다. 위의 이미지는 지정된 스테이지의 타임라인 보기를 캡처합니다.
팁 (조언)
확대/축소 사용 확인란을 선택하면 타임라인 보기에서 왼쪽과 오른쪽으로 스크롤할 수 있습니다.
Spark UI의 다른 탭은 Spark 인스턴스에 대한 유용한 정보도 제공합니다.
- 스토리지 탭 - 애플리케이션이 RDD를 만드는 경우 스토리지 탭에서 정보를 찾을 수 있습니다.
- 환경 탭 - 이 탭은 다음과 같은 Spark 인스턴스에 대한 유용한 정보를 제공합니다.
- Scala 버전
- 클러스터와 연결된 이벤트 로그 디렉터리
- 애플리케이션의 실행기 코어 수
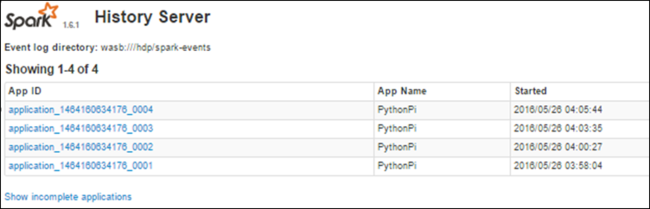
Spark 기록 서버를 사용하여 완료된 작업에 대한 정보 찾기
작업이 완료되면 작업에 대한 정보가 Spark 기록 서버에 유지됩니다.
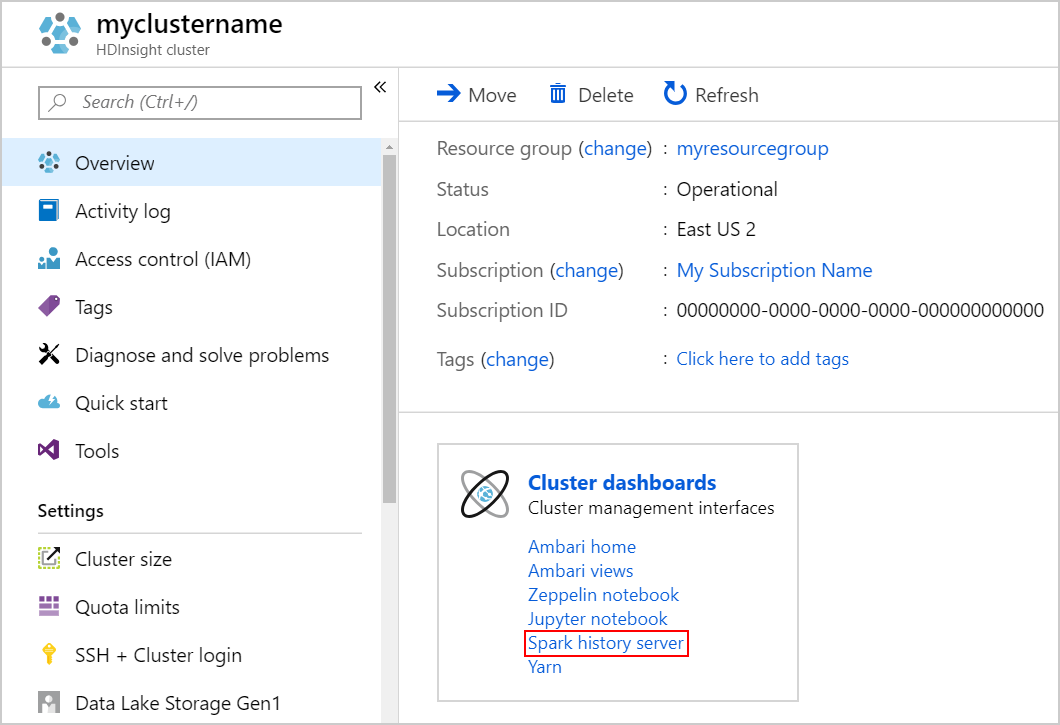
Spark 기록 서버를 시작하려면 개요 페이지에서 클러스터 대시보드에서 Spark 기록 서버를 선택합니다.
팁 (조언)
또는 Ambari UI에서 Spark 기록 서버 UI를 시작할 수도 있습니다. Ambari UI를 시작하려면 개요 블레이드에서 클러스터 대시보드에서 Ambari 홈을 선택합니다. Ambari UI에서 Spark2빠른 링크>Spark2>기록 서버 UI로 이동합니다.
완료된 모든 애플리케이션이 나열됩니다. 자세한 내용을 보려면 애플리케이션 ID를 선택하여 애플리케이션으로 드릴다운합니다.