Azure Machine Learning에서 일괄 처리 엔드포인트를 사용하는 경우 대량의 입력 데이터에 대해 긴 일괄 처리 작업을 수행할 수 있습니다. 데이터는 여러 지역 등 여러 장소에 위치할 수 있습니다. 특정 유형의 일괄 처리 엔드포인트는 리터럴 매개 변수를 입력으로 받을 수도 있습니다.
이 문서에서는 일괄 처리 엔드포인트에 대한 매개 변수 입력을 지정하고 배포 작업을 만드는 방법을 설명합니다. 이 프로세스는 데이터 자산, 데이터 저장소, 스토리지 계정 및 로컬 파일과 같은 다양한 원본의 데이터 작업을 지원합니다.
필수 구성 요소
일괄 처리 엔드포인트 및 배포. 이러한 리소스를 만들려면 Azure Machine Learning에서 일괄 처리 배포로 MLflow 모델 배포를 참조하세요.
일괄 처리 엔드포인트 배포를 실행할 수 있는 권한. AzureML 데이터 과학자, 기여자 및 소유자 역할을 사용하여 배포를 실행할 수 있습니다. 사용자 지정 역할 정의에 필요한 특정 권한을 검토하려면 일괄 처리 엔드포인트에 대한 권한 부여를 참조하세요.
엔드포인트를 호출하는 자격 증명입니다. 자세한 내용은 인증 설정을 참조하세요.
엔드포인트가 배포된 컴퓨팅 클러스터에서 입력 데이터에 대한 읽기 권한입니다.
팁
특정 상황에서는 자격 증명이 없는 데이터 저장소 또는 외부 Azure Storage 계정을 데이터 입력으로 사용해야 합니다. 이러한 시나리오에서는 컴퓨팅 클러스터의 관리 ID가 스토리지 계정을 탑재하는 데 사용되므로 데이터 액세스를 위해 컴퓨팅 클러스터를 구성해야 합니다. 작업(호출자)의 ID가 기본 데이터를 읽는 데 사용되므로 세분화된 액세스 제어가 여전히 있습니다.
인증 설정
엔드포인트를 호출하려면 유효한 Microsoft Entra 토큰이 필요합니다. 엔드포인트를 호출하면 Azure Machine Learning은 토큰과 연결된 ID 아래에 일괄 처리 배포 작업을 만듭니다.
- Azure Machine Learning CLI(v2) 또는 Python용 Azure Machine Learning SDK(v2)를 사용하여 엔드포인트를 호출하는 경우 Microsoft Entra 토큰을 수동으로 가져올 필요가 없습니다. 로그인하는 동안 시스템은 사용자 ID를 인증합니다. 또한 토큰을 검색하고 전달합니다.
- REST API를 사용하여 엔드포인트를 호출하는 경우 토큰을 수동으로 가져와야 합니다.
다음 절차에 설명된 대로 호출에 고유한 자격 증명을 사용할 수 있습니다.
Azure CLI를 사용하여 대화형 또는 디바이스 코드 인증으로 로그인합니다.
az login
다양한 유형의 자격 증명에 대한 자세한 내용은 다양한 유형의 자격 증명을 사용하여 작업을 실행하는 방법을 참조하세요.
기본 작업 만들기
일괄 처리 엔드포인트에서 작업을 만들려면 엔드포인트를 호출합니다. 호출은 Azure Machine Learning CLI, Python용 Azure Machine Learning SDK 또는 REST API 호출을 사용하여 수행할 수 있습니다.
다음 예제에서는 처리를 위해 단일 입력 데이터 폴더를 수신하는 일괄 처리 엔드포인트에 대한 호출 기본 사항을 보여 줍니다. 다양한 입력 및 출력을 포함하는 예제는 입력 및 출력 이해를 참조하세요.
일괄 처리 엔드포인트에서 invoke 작업을 사용합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
특정 배포 호출
일괄 처리 엔드포인트는 동일한 엔드포인트에서 여러 배포를 호스트할 수 있습니다. 사용자가 달리 지정하지 않는 한 기본 엔드포인트가 사용됩니다. 다음 절차를 사용하여 사용하는 배포를 변경할 수 있습니다.
인수 --deployment-name 또는 -d를 사용하여 배포 이름을 지정합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
작업 속성 구성
호출 시 일부 작업 속성을 구성할 수 있습니다.
참고
현재 파이프라인 구성 요소 배포를 사용하여 일괄 처리 엔드포인트에서만 작업 속성을 구성할 수 있습니다.
실험 이름 구성
실험 이름을 구성하려면 다음 절차를 따르세요.
실험 이름을 지정하려면 인수 --experiment-name을 사용합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
입력 및 출력 이해
일괄 처리 엔드포인트는 소비자가 일괄 처리 작업을 만드는 데 사용할 수 있는 지속형 API를 제공합니다. 동일한 인터페이스를 사용하여 배포에 필요한 입력과 출력을 지정할 수 있습니다. 입력을 사용하여 엔드포인트가 작업을 수행하는 데 필요한 정보를 전달합니다.
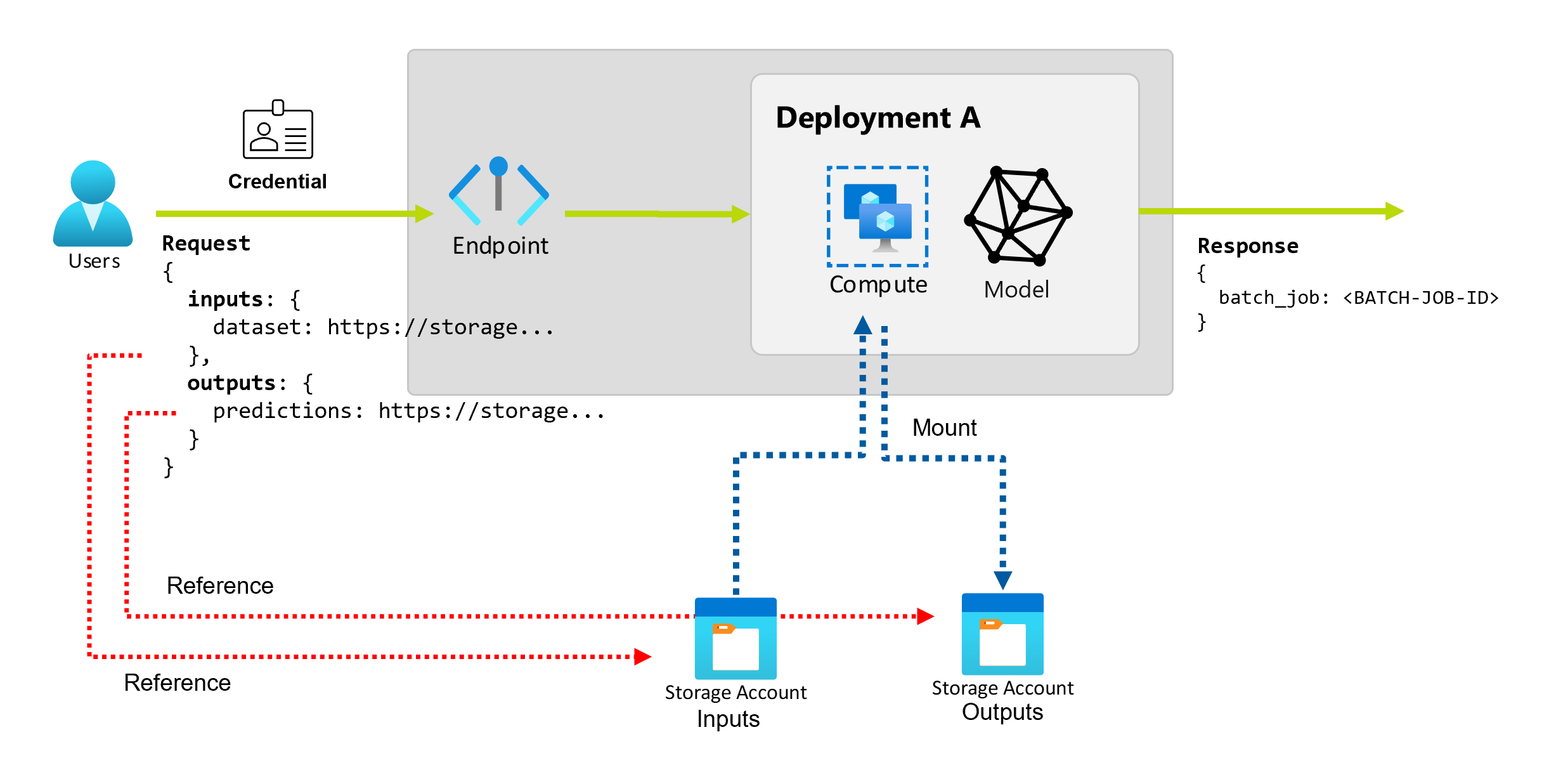
Batch 엔드포인트는 다음 두 가지 유형의 입력을 지원합니다.
입력 및 출력의 수와 형식은 일괄 처리 배포 형식에 따라 다릅니다. 모델 배포에는 항상 1개의 데이터 입력이 필요하고 1개의 데이터 출력이 생성됩니다. 모델 배포에서는 리터럴 입력이 지원되지 않습니다. 반면, 파이프라인 구성 요소 배포는 엔드포인트를 구축하기 위한 보다 일반적인 구조를 제공합니다. 파이프라인 구성 요소 배포에서 원하는 수의 데이터 입력, 리터럴 입력 및 출력을 지정할 수 있습니다.
다음 표에는 일괄 처리 배포에 대한 입력 및 출력이 요약되어 있습니다.
| 배포 유형 | 입력 수 | 지원되는 입력 유형 | 출력 수 | 지원되는 출력 형식 |
|---|---|---|---|---|
| 모델 배포 | 1 | 데이터 입력 | 1 | 데이터 출력 |
| 파이프라인 구성 요소 배포 | 0-N | 데이터 입력 및 리터럴 입력 | 0-N | 데이터 출력 |
팁
입력과 출력은 항상 이름이 지정됩니다. 각 이름은 호출 중에 데이터를 식별하고 값을 전달하기 위한 키 역할을 합니다. 모델 배포에는 항상 하나의 입력 및 출력이 필요하므로 모델 배포에서 호출하는 동안 이름이 무시됩니다. 사용 사례를 가장 잘 설명하는 이름(예: sales_estimation)을 할당할 수 있습니다.
데이터 입력 살펴보기
데이터 입력은 데이터가 배치된 위치를 가리키는 입력을 나타냅니다. 일괄 처리 엔드포인트는 일반적으로 많은 양의 데이터를 소비하므로 호출 요청의 일부로 입력 데이터를 전달할 수 없습니다. 대신 데이터를 찾기 위해 일괄 처리 엔드포인트가 이동해야 하는 위치를 지정합니다. 입력 데이터는 성능 향상을 위해 대상 컴퓨팅 인스턴스에 탑재되고 스트리밍됩니다.
일괄 처리 엔드포인트는 다음 유형의 스토리지에 있는 파일을 읽을 수 있습니다.
- 폴더(
uri_folder) 및 파일(uri_file) 형식을 포함한 Azure Machine Learning 데이터 자산입니다. - Azure Blob Storage, Azure Data Lake Storage Gen1 및 Azure Data Lake Storage Gen2를 포함한 Azure Machine Learning 데이터 저장소.
- Blob Storage, Data Lake Storage Gen1 및 Data Lake Storage Gen2를 포함한 Azure Storage 계정입니다.
- Azure Machine Learning CLI 또는 Python용 Azure Machine Learning SDK를 사용하여 엔드포인트를 호출하는 경우 로컬 데이터 폴더 및 파일입니다. 그러나 로컬 데이터는 Azure Machine Learning 작업 영역의 기본 데이터 저장소에 업로드됩니다.
중요합니다
사용 중단 알림: FileDataset(V1)의 형식의 데이터 자산은 더 이상 사용되지 않으며 나중에 사용 중지될 예정입니다. 이 기능을 사용하는 기존 일괄 처리 엔드포인트는 계속 작동합니다. 하지만 다음을 사용하여 만든 일괄 처리 엔드포인트에서는 V1 데이터 세트가 지원되지 않습니다.
- 일반적으로 사용할 수 있는 Azure Machine Learning CLI v2 버전(2.4.0 이상).
- 일반 공급되는 REST API 버전(2022-05-01 이상).
리터럴 입력 살펴보기
리터럴 입력은 문자열, 숫자, 부울 값과 같이 호출 시 표현되고 해결될 수 있는 입력을 나타냅니다. 일반적으로 리터럴 입력을 사용하여 파이프라인 구성 요소 배포의 일부로 매개 변수를 엔드포인트에 전달합니다. 일괄 처리 엔드포인트는 다음 리터럴 형식을 지원합니다.
stringbooleanfloatinteger
리터럴 입력은 파이프라인 구성 요소 배포에서만 지원됩니다. 리터럴 엔드포인트를 지정하는 방법을 보려면 리터럴 입력을 사용하여 작업 만들기를 참조하세요.
데이터 출력 살펴보기
데이터 출력은 일괄 작업의 결과가 배치되는 위치를 나타냅니다. 각 출력에는 식별 가능한 이름이 있으며 Azure Machine Learning은 명명된 각 출력에 고유한 경로를 자동으로 할당합니다. 필요한 경우 다른 경로를 지정할 수 있습니다.
중요합니다
일괄 처리 엔드포인트는 Blob Storage 데이터 저장소에서 출력 작성만 지원합니다. Data Lake Storage Gen2와 같이 계층적 네임스페이스를 사용하도록 설정된 스토리지 계정에 작성해야 하는 경우 서비스가 완전히 호환되기에 스토리지 서비스를 Blob Storage 데이터 저장소로 등록할 수 있습니다. 이러한 방식으로 일괄 처리 엔드포인트의 출력을 Data Lake Storage Gen2에 쓸 수 있습니다.
데이터 입력을 사용하여 작업 만들기
다음 예제에서는 작업을 만들고 데이터 자산, 데이터 저장소 및 Azure Storage 계정에서 데이터 입력을 가져오는 동안 작업을 만드는 방법을 보여 줍니다.
데이터 자산의 입력 데이터 사용
Azure Machine Learning 데이터 자산(이전의 데이터 세트)은 작업에 대한 입력으로 지원됩니다. 다음 단계에 따라 Azure Machine Learning에서 등록된 데이터 자산에 저장된 입력 데이터를 사용하는 일괄 처리 엔드포인트 작업을 실행합니다.
경고
MLTable(형식 테이블)의 데이터 자산은 현재 모델 배포에 지원되지 않습니다. MLTable은 파이프라인 구성 요소 배포에 대해 지원됩니다.
데이터 자산을 만듭니다. 이 예제에서는 여러 CSV 파일이 포함된 폴더로 구성됩니다. 일괄 처리 엔드포인트를 사용하여 파일을 병렬로 처리합니다. 데이터가 데이터 자산으로 이미 등록되어 있는 경우 이 단계를 건너뛰어도 됩니다.
heart-data.yml YAML 파일에 데이터 자산 정의를 만듭니다.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: data데이터 자산을 만듭니다.
az ml data create -f heart-data.yml
입력을 설정합니다.
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)데이터 자산 ID의 형식은 다음과 같습니다.
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>엔드포인트를 실행합니다.
--set인수를 사용하여 입력을 지정합니다. 먼저 데이터 자산 이름의 하이픈을 밑줄 문자로 바꿉니다. 키는 영숫자 문자와 밑줄 문자만 포함할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_ID모델 배포를 제공하는 엔드포인트의 경우 모델 배포에는 항상 하나의 데이터 입력만 필요하기 때문에
--input인수를 사용하여 데이터 입력을 지정할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_ID인수
--set은(는) 여러 입력을 지정할 때 긴 명령을 생성하는 경향이 있습니다. 이러한 경우 파일에 입력을 나열한 다음 엔드포인트를 호출할 때 파일을 참조할 수 있습니다. 예를 들어 다음 줄을 포함하는 inputs.yml YAML라는 이름의 파일을 만들 수 있습니다.inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1그런 다음
--file인수를 사용하여 입력을 지정하는 다음 명령을 실행할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
데이터 저장소의 입력 데이터 사용
일괄 배포 작업은 Azure Machine Learning 등록 데이터 저장소에 있는 데이터를 직접 참조할 수 있습니다. 이 예제에서는 먼저 Azure Machine Learning 작업 영역의 데이터 저장소에 일부 데이터를 업로드합니다. 그런 다음 해당 데이터에 대한 일괄 처리 배포를 실행합니다.
이 예제에서는 기본 데이터 저장소를 사용하지만 다른 데이터 저장소를 사용할 수도 있습니다. 모든 Azure Machine Learning 작업 영역에서 기본 Blob 데이터 저장소의 이름은 workspaceblobstore입니다. 다음 단계에서 다른 데이터 저장소를 사용하려면 workspaceblobstore을(를) 기본 설정 데이터 저장소의 이름으로 바꿉니다.
데이터 저장소에 샘플 데이터를 업로드합니다. 샘플 데이터는 azureml-examples 리포지토리에서에서 사용할 수 있습니다. 해당 리포지토리의 sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data 폴더에서 데이터를 찾을 수 있습니다.
- Azure Machine Learning 스튜디오에서 기본 Blob 데이터 저장소에 대한 데이터 자산 페이지를 연 다음 해당 Blob 컨테이너의 이름을 검색합니다.
- Azure Storage Explorer나 AzCopy와 같은 도구를 사용하여 샘플 데이터를 해당 컨테이너 내의 heart-disease-uci-unlabeled라는 폴더에 업로드합니다.
입력 정보를 설정합니다.
INPUT_PATH변수에 파일 경로를 배치합니다.DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"어떻게
paths폴더가 입력 경로의 일부인지 확인합니다. 이 형식은 다음 값이 경로임을 나타냅니다.엔드포인트를 실행합니다.
--set인수를 사용하여 입력을 지정합니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATH모델 배포를 제공하는 엔드포인트의 경우 모델 배포에는 항상 하나의 데이터 입력만 필요하기 때문에
--input인수를 사용하여 데이터 입력을 지정할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folder인수
--set은(는) 여러 입력을 지정할 때 긴 명령을 생성하는 경향이 있습니다. 이러한 경우 파일에 입력을 나열한 다음 엔드포인트를 호출할 때 파일을 참조할 수 있습니다. 예를 들어 다음 줄을 포함하는 inputs.yml YAML라는 이름의 파일을 만들 수 있습니다.inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>데이터가 파일에 있는 경우 입력에
uri_file형식을 대신 사용합니다.그런 다음
--file인수를 사용하여 입력을 지정하는 다음 명령을 실행할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Azure Storage 계정의 입력 데이터 사용
Azure Machine Learning 일괄 처리 엔드포인트는 퍼블릭 및 프라이빗 Azure Storage 계정의 클라우드 위치에서 데이터를 읽을 수 있습니다. 다음 단계를 사용하여 스토리지 계정의 데이터로 일괄 처리 엔드포인트 작업을 실행합니다.
스토리지 계정에서 데이터를 읽는 데 필요한 추가 구성에 대한 자세한 내용은 데이터 액세스를 위한 컴퓨팅 클러스터 구성을 참조하세요.
입력을 설정합니다.
INPUT_DATA변수를 설정합니다.INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"데이터가 파일에 있는 경우 다음 형식과 유사한 형식을 사용하여 입력 경로를 정의합니다.
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"엔드포인트를 실행합니다.
--set인수를 사용하여 입력을 지정합니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATA모델 배포를 제공하는 엔드포인트의 경우 모델 배포에는 항상 하나의 데이터 입력만 필요하기 때문에
--input인수를 사용하여 데이터 입력을 지정할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folder--set인수는 여러 입력을 지정할 때 긴 명령을 생성하는 경향이 있습니다. 이러한 경우 파일에 입력을 나열한 다음 엔드포인트를 호출할 때 파일을 참조할 수 있습니다. 예를 들어 다음 줄을 포함하는 inputs.yml YAML라는 이름의 파일을 만들 수 있습니다.inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data그런 다음
--file인수를 사용하여 입력을 지정하는 다음 명령을 실행할 수 있습니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml데이터가 파일에 있는 경우 데이터 입력에 inputs.yml 파일의
uri_file형식을 사용합니다.
리터럴 입력을 사용하여 작업 만들기
파이프라인 구성 요소 배포는 리터럴 입력을 사용할 수 있습니다. 기본 파이프라인을 포함하는 일괄 처리 배포의 예는 일괄 처리 엔드포인트를 사용하여 파이프라인을 배포하는 방법을 참조하세요.
다음 예에서는 append 값을 사용하여 string 형식의 score_mode라는 입력을 지정하는 방법을 보여줍니다.
YAML 파일에 입력을 배치합니다(예: 이름이 inputs.yml인 파일).
inputs:
score_mode:
type: string
default: append
--file 인수를 사용하여 입력을 지정하는 다음 명령을 실행합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
--set 인수를 사용하여 형식 및 기본값을 지정할 수도 있습니다. 그러나 이 접근 방식은 여러 입력을 지정할 때 긴 명령을 생성하는 경향이 있습니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
데이터 출력을 사용하여 작업 만들기
다음 예제에서는 score(이)라는 출력의 위치를 변경하는 방법을 보여 줍니다. 완전성을 높이기 위해 이 예에서는 heart_data(이)라는 입력도 구성합니다.
이 예제에서는 기본 데이터 저장소인 workspaceblobstore를 사용합니다. 그러나 Blob Storage 계정인 한 작업 영역에서 다른 데이터 저장소를 사용할 수 도 있습니다. 다른 데이터 저장소를 사용하려면 다음 단계에서 workspaceblobstore을(를) 기본 설정 데이터 저장소의 이름으로 바꿉니다.
데이터 저장소의 ID를 가져옵니다.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')데이터 저장소 ID의 형식은 다음과 같습니다.
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore데이터 출력을 만듭니다.
inputs-and-outputs.yml이라는 파일에서 입력 및 출력 값을 정의합니다. 출력 경로에서 데이터 저장소 ID를 사용합니다. 완전성을 위해 데이터 입력도 정의합니다.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-path참고
어떻게
paths폴더가 출력 경로의 일부인지 확인합니다. 이 형식은 다음 값이 경로임을 나타냅니다.배포를 실행합니다.
--file인수를 사용하여 입력 및 출력 값을 지정합니다.az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml