Azure Machine Learning(v1)을 사용하여 모델을 튜닝하는 하이퍼 매개 변수
적용 대상: Azure CLI ml 확장 v1
Azure CLI ml 확장 v1
중요
이 문서의 Azure CLI 명령에는 azure-cli-ml 또는 v1, Azure Machine Learning용 확장이 필요합니다. v1 확장에 대한 지원은 2025년 9월 30일에 종료됩니다. v1 확장은 이 날짜까지 설치하고 사용할 수 있습니다.
2025년 9월 30일 이전에 ml 또는 v2 확장으로 전환하는 것이 좋습니다. v2 확장에 대한 자세한 내용은 Azure ML CLI 확장 및 Python SDK v2를 참조하세요.
Azure Machine Learning(v1) HyperDrive 패키지를 사용하여 효율적으로 하이퍼 매개 변수 튜닝을 자동화합니다. Azure Machine Learning SDK를 사용하여 하이퍼 매개 변수 튜닝에 필요한 단계를 완료하는 방법을 알아봅니다.
- 매개 변수 검색 공간 정의
- 최적화할 기본 메트릭 지정
- 낮은 성능 실행에 조기 종료 정책 지정
- 정책 만들기 및 할당
- 정의된 구성을 사용하여 실험 시작
- 교육 실행 시각화
- 모델에 최상의 구성 선택
하이퍼 매개 변수 튜닝이란?
하이퍼 매개 변수는 모델 학습 프로세스를 제어할 수 있게 하는 조정 가능한 매개 변수입니다. 예를 들어 신경망을 사용하여 숨겨진 레이어 수와 각 레이어의 노드 수를 결정합니다. 모델 성능은 하이퍼 매개 변수에 따라 크게 달라집니다.
하이퍼 매개 변수 최적화라고도 하는 하이퍼 매개 변수 튜닝은 최상의 성능을 발휘하는 하이퍼 매개 변수 구성을 찾는 프로세스입니다. 프로세스는 일반적으로 계산 비용이 많이 들고 수동입니다.
Azure Machine Learning을 사용하면 하이퍼 매개 변수 튜닝을 자동화하고 병렬로 실험을 실행하여 하이퍼 매개 변수를 효율적으로 최적화할 수 있습니다.
검색 공간 정의
하이퍼 매개 변수마다 정의된 값의 범위를 탐색하여 하이퍼 매개 변수를 튜닝합니다.
하이퍼 매개 변수는 불연속 또는 연속일 수 있으며 매개 변수 식에서 설명하는 값의 분포를 가집니다.
개별 하이퍼 매개 변수
개별 하이퍼 매개 변수는 불연속 값 중 choice로 지정됩니다. choice는 다음이 될 수 있습니다.
- 하나 이상의 쉼표로 구분된 값
range개체- 임의의
list개체
{
"batch_size": choice(16, 32, 64, 128)
"number_of_hidden_layers": choice(range(1,5))
}
이 사례에서 batch_size는 [16, 32, 64, 128] 값 중 하나를, number_of_hidden_layers는 [1, 2, 3, 4] 값 중 하나를 사용합니다.
배포를 사용하여 다음과 같은 고급 불연속 하이퍼 매개 변수도 지정할 수 있습니다.
quniform(low, high, q)- 라운드와 같은 값 반환(uniform(low, high) / q) * qqloguniform(low, high, q)- 라운드와 같은 값 반환(exp(uniform(low, high)) / q) * qqnormal(mu, sigma, q)- 라운드와 같은 값 반환(normal(mu, sigma) / q) * qqlognormal(mu, sigma, q)- 라운드와 같은 값 반환(exp(normal(mu, sigma)) / q) * q
연속 하이퍼 매개 변수
연속 하이퍼 매개 변수는 연속 값의 범위에 대한 배포로 지정됩니다.
uniform(low, high)- low와 high 간에 균일하게 배포되는 값 반환loguniform(low, high)- 반환 값의 로그가 균일하게 배포되도록 exp(uniform(low, high))에 따라 그려진 값 반환normal(mu, sigma)- 평균 mu 및 표준 편차 sigma를 사용하여 일반적으로 배포되는 실제 값 반환lognormal(mu, sigma)- 반환 값의 로그가 균일하게 배포되도록 exp(normal(mu, sigma))에 따라 그려진 값 반환
매개 변수 공간 정의의 예제는 다음과 같습니다.
{
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1)
}
이 코드는 learning_rate 및 keep_probability라는 두 개의 매개 변수를 사용하여 검색 공간을 정의합니다. learning_rate는 평균 값 10과 표준 편차 3이 있는 정규 분포를 갖게 됩니다. keep_probability는 최솟값 0.05 및 최댓값 0.1이 있는 균일한 분포를 갖게 됩니다.
하이퍼 매개 변수 공간 샘플링
하이퍼 매개 변수 공간을 통해 사용하도록 매개 변수 샘플링 방법을 지정합니다. Azure Machine Learning에서는 다음 방법을 지원합니다.
- 무작위 샘플링
- 그리드 샘플링
- Bayesian 샘플링
무작위 샘플링
무작위 샘플링은 불연속 및 연속 하이퍼 매개 변수를 지원합니다. 낮은 성능 실행의 조기 종료를 지원합니다. 일부 사용자는 무작위 샘플링을 사용하여 초기 검색을 수행한 다음, 검색 공간을 상세 검색하여 결과를 향상시킵니다.
무작위 샘플링에서 하이퍼 매개 변수 값은 정의된 검색 공간에서 임의로 선택됩니다.
from azureml.train.hyperdrive import RandomParameterSampling
from azureml.train.hyperdrive import normal, uniform, choice
param_sampling = RandomParameterSampling( {
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
그리드 샘플링
그리드 샘플링은 불연속 하이퍼 매개 변수를 지원합니다. 검색 공간을 철저히 검색하도록 예산을 편성할 수 있는 경우에는 그리드 샘플링을 사용합니다. 낮은 성능 실행의 조기 종료를 지원합니다.
그리드 샘플링은 가능한 모든 값에 간단한 그리드 검색을 수행합니다. choice 하이퍼 매개 변수에서만 그리드 샘플링을 사용할 수 있습니다. 예를 들어 다음 공간에는 샘플이 6개 있습니다.
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
param_sampling = GridParameterSampling( {
"num_hidden_layers": choice(1, 2, 3),
"batch_size": choice(16, 32)
}
)
Bayesian 샘플링
Bayesian 샘플링은 Bayesian 최적화 알고리즘을 기반으로 합니다. 이전 샘플에서 수행한 방식을 기반으로 샘플을 선택하여 새 샘플이 기본 메트릭을 향상시킵니다.
하이퍼 매개 변수 공간을 탐색하는 데 예산이 충분한 경우에는 Bayesian 샘플링을 사용하는 것이 좋습니다. 최상의 결과를 얻으려면 최대 실행 수가 튜닝 중인 하이퍼 매개 변수 수의 20배 이상인 것이 좋습니다.
동시 실행 수는 튜닝 프로세스의 효율성에 영향을 줍니다. 병렬 처리 수준이 작으면 이전에 완료된 실행의 이점을 활용하는 실행 수가 증가하므로 동시 실행 수가 적으면 더욱 우수한 샘플링 수렴이 가능합니다.
Bayesian 샘플링은 검색 공간을 통해 choice, uniform 및 quniform 배포만 지원합니다.
from azureml.train.hyperdrive import BayesianParameterSampling
from azureml.train.hyperdrive import uniform, choice
param_sampling = BayesianParameterSampling( {
"learning_rate": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
기본 메트릭 지정
하이퍼 매개 변수 튜닝을 최적화할 기본 메트릭을 지정합니다. 각 교육 실행은 기본 메트릭에 대해 평가됩니다. 조기 종료 정책은 기본 메트릭을 사용하여 낮은 성능 실행을 식별합니다.
기본 메트릭에 다음 특성을 지정합니다.
primary_metric_name: 기본 메트릭 이름은 학습 스크립트에서 로그한 메트릭의 이름과 정확하게 일치해야 합니다.primary_metric_goal:PrimaryMetricGoal.MAXIMIZE또는PrimaryMetricGoal.MINIMIZE일 수 있으며 실행을 평가할 때 기본 메트릭을 최대화 또는 최소화할지 여부를 결정합니다.
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
이 샘플에서는 "정확도"를 극대화합니다.
하이퍼 매개 변수 튜닝에 대한 메트릭 기록
모델의 학습 스크립트는 HyperDrive가 하이퍼 매개 변수 튜닝을 위해 액세스할 수 있도록 모델 학습 중에 기본 메트릭을 로그해야 합니다.
다음 샘플 코드 조각을 사용하여 학습 스크립트에 기본 메트릭을 로그합니다.
from azureml.core.run import Run
run_logger = Run.get_context()
run_logger.log("accuracy", float(val_accuracy))
학습 스크립트는 val_accuracy를 계산하고 기본 메트릭 "정확도"로 로그합니다. 메트릭이 로그될 때마다 하이퍼 매개 변수 튜닝 서비스에 의해 수신됩니다. 사용자는 보고 빈도를 결정해야 합니다.
모델 학습 실행의 로깅 값에 대한 자세한 내용은 Azure Machine Learning 학습 실행에서 로깅 사용을 참조하세요.
초기 종료 정책 지정
초기 종료 정책을 사용하여 자동으로 성능이 불량한 실행을 종료합니다. 초기 종료는 계산 효율성을 향상시킵니다.
정책이 적용되는 시기를 제어하는 매개 변수를 다음과 같이 구성할 수 있습니다.
evaluation_interval: 정책 적용 빈도입니다. 학습 스크립트에서 기본 메트릭을 기록할 때마다 한 번의 간격으로 계산됩니다. 따라서 1의evaluation_interval은 학습 스크립트에서 기본 메트릭을 보고할 때마다 정책을 적용합니다. 2의evaluation_interval은 다른 모든 시간에 정책을 적용합니다. 지정하지 않으면evaluation_interval은 기본적으로 1로 설정됩니다.delay_evaluation: 지정된 간격 동안 첫 번째 정책 평가를 지연합니다. 이 매개 변수는 모든 구성이 최소 간격 동안 실행되도록 허용하여 학습 실행의 이른 종료를 방지하는 선택적 매개 변수입니다. 지정된 경우 정책은 delay_evaluation보다 크거나 같은 evaluation_interval의 모든 배수마다 적용됩니다.
Azure Machine Learning은 다음 초기 종료 정책을 지원합니다.
산적 정책
산적 정책은 slack 요소/slack 양 및 평가 간격을 기반으로 합니다. 산적은 기본 메트릭이 가장 성공한 실행의 지정된 slack 요소/slack 양 내에 있지 않으면 실행을 종료합니다.
참고
Bayesian 샘플링은 초기 종료를 지원하지 않습니다. Bayesian 샘플링을 사용할 경우 early_termination_policy = None을 설정합니다.
다음 구성 매개 변수를 지정합니다.
slack_factor또는slack_amount: 성능이 훌륭한 학습 실행에 대해 허용된 slack입니다.slack_factor는 비율로 허용되는 slack을 지정합니다.slack_amount는 비율 대신에 절대 양으로 허용되는 slack을 지정합니다.예를 들어 간격 10에 적용되는 산적 정책을 사용하는 것이 좋습니다. 간격 10에서 최상의 성능 실행이 기본 메트릭 극대화를 목표로 기본 메트릭이 0.8임을 보고했다고 가정합니다. 정책에서
slack_factor를 0.2로 지정하면 간격 10에서 최상의 메트릭이 0.66(0.8/(1+slack_factor)) 미만인 모든 학습 실행이 종료됩니다.evaluation_interval: (선택 사항) 정책 적용 빈도입니다.delay_evaluation: (선택 사항) 지정된 간격 동안 첫 번째 정책 평가를 지연합니다.
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5)
이 예제에서는 평가 간격 5에서 시작하여 메트릭이 보고될 때 모든 간격에서 초기 종료 정책이 적용됩니다. 최상의 메트릭이 성능이 훌륭한 실행의 (1/(1+0.1) 또는 91%보다 작은 모든 실행이 종료됩니다.
중앙값 중지 정책
중앙값 중지는 실행에서 보고하는 기본 메트릭의 실행 평균을 기반으로 하는 초기 종료 정책입니다. 이 정책은 모든 학습 실행에서 실행 평균을 계산하고 기본 메트릭 값이 평균의 중앙값보다 낮은 실행을 중지합니다.
이 정책은 다음 구성 매개 변수를 사용합니다.
evaluation_interval: 정책 적용에 대한 빈도입니다(선택적 매개 변수).delay_evaluation: 지정된 간격 동안 첫 번째 정책 평가를 지연합니다(선택적 매개 변수).
from azureml.train.hyperdrive import MedianStoppingPolicy
early_termination_policy = MedianStoppingPolicy(evaluation_interval=1, delay_evaluation=5)
이 예제에서는 평가 간격 5에서 시작하여 모든 간격에서 초기 종료 정책이 적용됩니다. 최상의 기본 메트릭이 모든 학습 실행의 간격 1:5에서 실행 평균의 중앙값보다 낮으면 실행은 간격 5에서 중지됩니다.
잘림 선택 영역 정책
잘림 선택 영역은 각 평가 간격에서 성능이 가장 낮은 실행의 백분율을 취소합니다. 기본 메트릭을 사용하여 실행을 비교합니다.
이 정책은 다음 구성 매개 변수를 사용합니다.
truncation_percentage: 각 평가 간격에서 종료할 성능이 가장 낮은 실행의 백분율입니다. 1~99 사이의 정수 값입니다.evaluation_interval: (선택 사항) 정책 적용 빈도입니다.delay_evaluation: (선택 사항) 지정된 간격 동안 첫 번째 정책 평가를 지연합니다.exclude_finished_jobs: 정책을 적용할 때 완료된 작업을 제외할지 여부를 지정합니다.
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
이 예제에서는 평가 간격 5에서 시작하여 모든 간격에서 초기 종료 정책이 적용됩니다. 간격 5에서의 성능이 간격 5에서의 모든 실행 중 가장 낮은 20%인 경우 실행은 간격 5에서 종료되고 정책을 적용할 때 완료된 작업은 제외됩니다.
종료 정책 없음(기본값)
지정된 정책이 없으면 하이퍼 매개 변수 튜닝 서비스는 모든 학습이 완료될 때까지 실행되도록 합니다.
policy=None
초기 종료 정책 선택
- 가능성이 높은 작업을 종료하지 않고 비용 절약을 제공하는 보수적인 정책을 원하는 경우
evaluation_interval1 및delay_evaluation5의 중앙값 중지 정책을 사용하는 것이 좋습니다. 이는 일반적인 설정이며, 기본 메트릭에서 손실 없이 약 25%-35% 절감을 제공할 수 있습니다(계산 데이터에 따라). - 더욱 적극적으로 절약하려면 허용 가능한 slack이 더 작은 산적 정책이나 잘림 비율이 더 큰 잘림 선택 정책을 사용합니다.
정책 만들기 및 할당
최대 학습 실행 수를 지정하여 리소스 예산을 제어합니다.
max_total_runs: 최대 학습 실행 수입니다. 1~1000 사이의 정수여야 합니다.max_duration_minutes: (선택 사항) 하이퍼 매개 변수 튜닝 실험의 최대 기간(분)입니다. 이 기간이 취소된 후에 실행됩니다.
참고
max_total_runs 및 max_duration_minutes가 모두 지정된 경우 이러한 두 임계값 중 첫 번째 임계값에 도달하면 하이퍼 매개 변수 조정 실험은 종료됩니다.
또한 하이퍼 매개 변수 조정 검색 중 동시에 실행할 학습 실행의 최대 수를 지정합니다.
max_concurrent_runs: (선택 사항) 동시에 실행할 수 있는 최대 실행 수입니다. 지정하지 않으면 모든 실행이 병렬로 시작됩니다. 지정한 경우 1~100 사이의 정수여야 합니다.
참고
동시 실행 수는 지정된 컴퓨팅 대상에서 사용할 수 있는 리소스에서 제어됩니다. 원하는 동시성에 사용할 수 있는 리소스가 컴퓨팅 대상에 있는지 확인합니다.
max_total_runs=20,
max_concurrent_runs=4
이 코드는 한 번에 구성 4개를 실행하여 실행을 최대 20개까지 사용하도록 하이퍼 매개 변수 튜닝 실험을 구성합니다.
하이퍼 매개 변수 튜닝 실험 구성
하이퍼 매개 변수 튜닝 실험을 구성하려면 다음을 제공합니다.
- 정의된 하이퍼 매개 변수 검색 공간
- 초기 종료 정책 지정
- 기본 메트릭
- 리소스 할당 설정
- ScriptRunConfig
script_run_config
ScriptRunConfig는 샘플링된 하이퍼 매개 변수로 실행되는 학습 스크립트입니다. 작업당 리소스(단일 또는 다중 노드)와 사용할 컴퓨팅 대상을 정의합니다.
참고
script_run_config에서 사용되는 컴퓨팅 대상에는 동시성 수준을 만족할 수 있는 충분한 리소스가 있어야 합니다. ScriptRunConfig에 대한 자세한 내용은 학습 실행 구성을 참조하세요.
하이퍼 매개 변수 조정 실험 구성
from azureml.train.hyperdrive import HyperDriveConfig
from azureml.train.hyperdrive import RandomParameterSampling, BanditPolicy, uniform, PrimaryMetricGoal
param_sampling = RandomParameterSampling( {
'learning_rate': uniform(0.0005, 0.005),
'momentum': uniform(0.9, 0.99)
}
)
early_termination_policy = BanditPolicy(slack_factor=0.15, evaluation_interval=1, delay_evaluation=10)
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
HyperDriveConfig는 ScriptRunConfig script_run_config에 전달된 매개 변수를 설정합니다. script_run_config는 차례대로 매개 변수를 학습 스크립트로 전달합니다. 위 코드 조각은 샘플 Notebook 학습, 하이퍼 매개 변수 튜닝 및 PyTorch를 사용하여 배포에서 가져온 것입니다. 이 샘플에서는 learning_rate 및 momentum 매개 변수가 튜닝됩니다. 실행 초기 중지는 slack_factor를 벗어난 기본 메트릭 실행을 중지하는 BanditPolicy에 의해 결정됩니다(BanditPolicy 클래스 참조 확인).
샘플에서 다음 코드는 튜닝되는 값이 학습 스크립트의 fine_tune_model 함수에 수신, 구문 분석 및 전달되는 방식을 보여줍니다.
# from pytorch_train.py
def main():
print("Torch version:", torch.__version__)
# get command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--num_epochs', type=int, default=25,
help='number of epochs to train')
parser.add_argument('--output_dir', type=str, help='output directory')
parser.add_argument('--learning_rate', type=float,
default=0.001, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
args = parser.parse_args()
data_dir = download_data()
print("data directory is: " + data_dir)
model = fine_tune_model(args.num_epochs, data_dir,
args.learning_rate, args.momentum)
os.makedirs(args.output_dir, exist_ok=True)
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
중요
모든 하이퍼 매개 변수 실행은 모델 및 모든 데이터 로더 다시 빌드를 포함하여 학습을 처음부터 다시 시작합니다. Azure Machine Learning 파이프라인이나 수동 프로세스를 사용하여 학습을 실행하기 전에 가능한 한 많은 데이터 준비를 수행하면 이 비용을 최소화할 수 있습니다.
하이퍼 매개 변수 튜닝 실험 제출
하이퍼 매개 변수 튜닝 구성을 정의하면 다음과 같이 실험을 제출합니다.
from azureml.core.experiment import Experiment
experiment = Experiment(workspace, experiment_name)
hyperdrive_run = experiment.submit(hd_config)
웜 시작 하이퍼 매개 변수 튜닝(선택 사항)
모델에 가장 적합한 하이퍼 매개 변수 값 찾기는 반복 프로세스일 수 있습니다. 이전 실행 5개의 지식을 다시 사용하여 하이퍼 매개 변수 튜닝을 가속화할 수 있습니다.
웜 시작은 샘플링 방법에 따라 다르게 처리됩니다.
- Bayesian 샘플링: 이전 실행의 평가판은 새 샘플을 선택하고 기본 메트릭을 향상시키기 위해 이전 지식으로 사용됩니다.
- 무작위 샘플링 또는 그리드 샘플링: 초기 종료는 이전 실행의 지식을 사용하여 성능이 낮은 실행을 확인합니다.
웜 시작을 사용할 부모 실행 목록을 지정합니다.
from azureml.train.hyperdrive import HyperDriveRun
warmstart_parent_1 = HyperDriveRun(experiment, "warmstart_parent_run_ID_1")
warmstart_parent_2 = HyperDriveRun(experiment, "warmstart_parent_run_ID_2")
warmstart_parents_to_resume_from = [warmstart_parent_1, warmstart_parent_2]
하이퍼 매개 변수 튜닝 실험이 취소되면 마지막 검사점에서 학습 실행을 계속할 수 있습니다. 그러나 학습 스크립트는 검사점 논리를 처리해야 합니다.
학습 실행은 동일한 하이퍼 매개 변수 구성과 탑재된 출력 폴더를 사용해야 합니다. 학습 스크립트는 학습 실행을 계속할 검사점이나 모델 파일이 포함된 resume-from 인수를 수락해야 합니다. 다음 조각을 사용하여 개별 학습 실행을 계속할 수 있습니다.
from azureml.core.run import Run
resume_child_run_1 = Run(experiment, "resume_child_run_ID_1")
resume_child_run_2 = Run(experiment, "resume_child_run_ID_2")
child_runs_to_resume = [resume_child_run_1, resume_child_run_2]
이전 실험의 웜 시작을 사용하도록 하이퍼 매개 변수 튜닝 실험을 구성하거나 구성에서 선택적 매개 변수 resume_from 및 resume_child_runs를 사용하여 개별 학습 실행을 계속할 수 있습니다.
from azureml.train.hyperdrive import HyperDriveConfig
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
resume_from=warmstart_parents_to_resume_from,
resume_child_runs=child_runs_to_resume,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
하이퍼 매개 변수 튜닝 실행 시각화
Azure Machine Learning 스튜디오에서 하이퍼 매개 변수 튜닝 실행을 시각화하거나 Notebook 위젯을 사용할 수 있습니다.
스튜디오
Azure Machine Learning 스튜디오에서 모든 하이퍼 매개 변수 튜닝 실행을 시각화할 수 있습니다. 포털에서 실험을 보는 방법에 대한 자세한 내용은 스튜디오에서 실행 레코드 보기를 참조하세요.
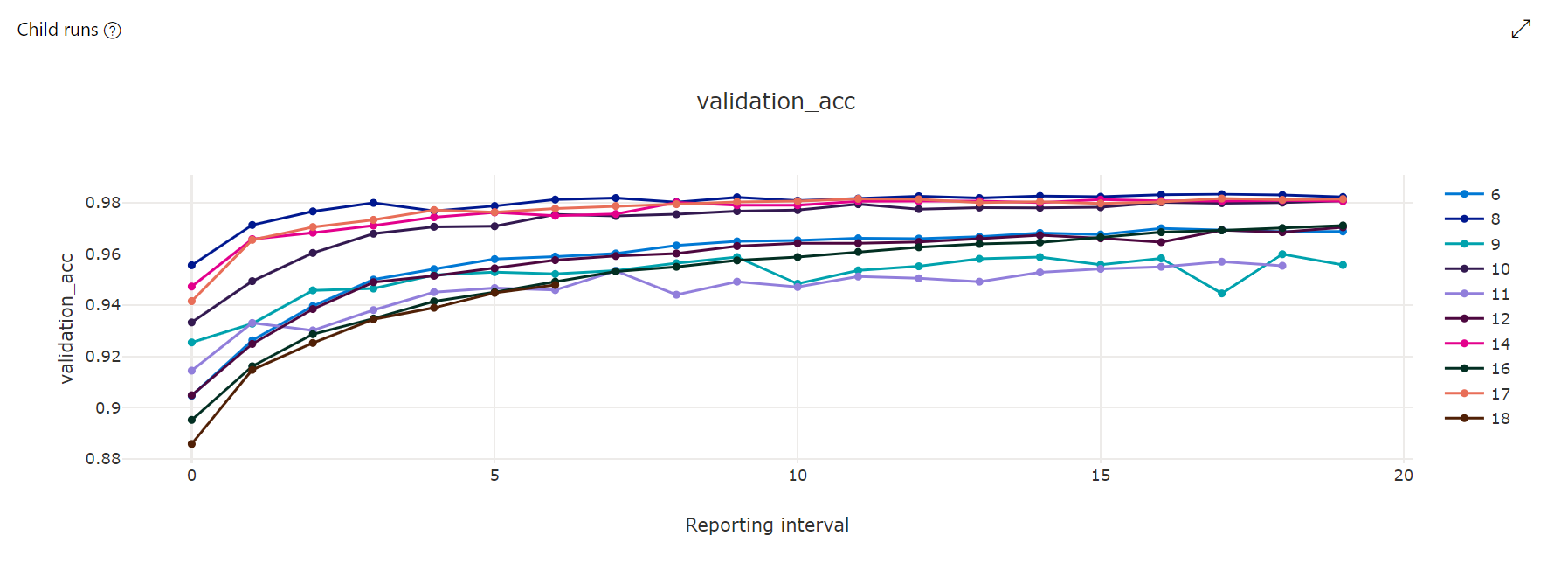
메트릭 차트: 이 시각화는 하이퍼 매개 변수 튜닝 기간 동안 각 HyperDrive 자식 실행에 로그된 메트릭을 추적합니다. 각 줄은 자식 실행을 나타내고 각 지점은 런타임 반복 시 기본 메트릭 값을 측정합니다.
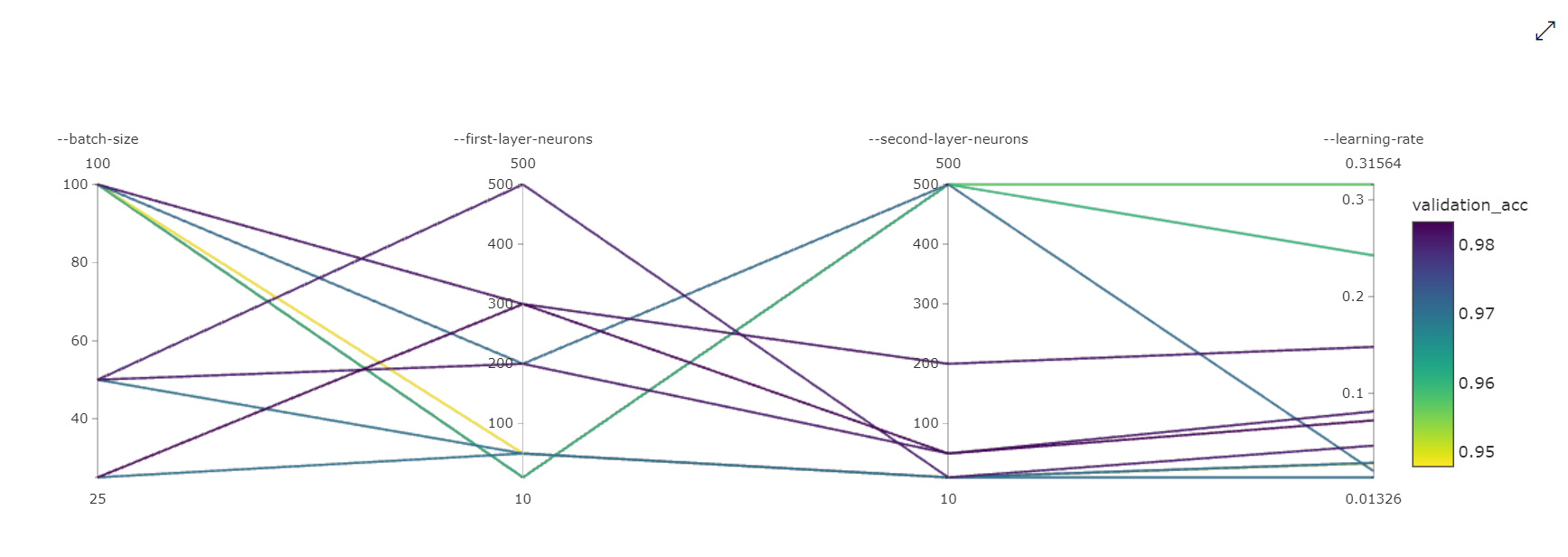
병렬 좌표 차트: 이 시각화에서는 기본 메트릭 성능과 개별 하이퍼 매개변수 값 간의 상관 관계를 보여줍니다. 차트는 축을 이동(클릭하여 축 레이블에 따라 끌기)하고 단일 축에서 값을 강조 표시하는(클릭하여 단일 축을 따라 세로 방향으로 끌어 원하는 값 범위 강조 표시) 대화형 차트입니다. 병렬 좌표 차트의 가장 오른쪽에는 해당 실행 인스턴스에 설정된 하이퍼 매개 변수에 해당하는 가장 적합한 메트릭 값을 그리는 축이 포함됩니다. 이 축은 차트 그라데이션 범례를 보다 읽기 쉬운 방식으로 데이터에 투영하기 위해 제공됩니다.
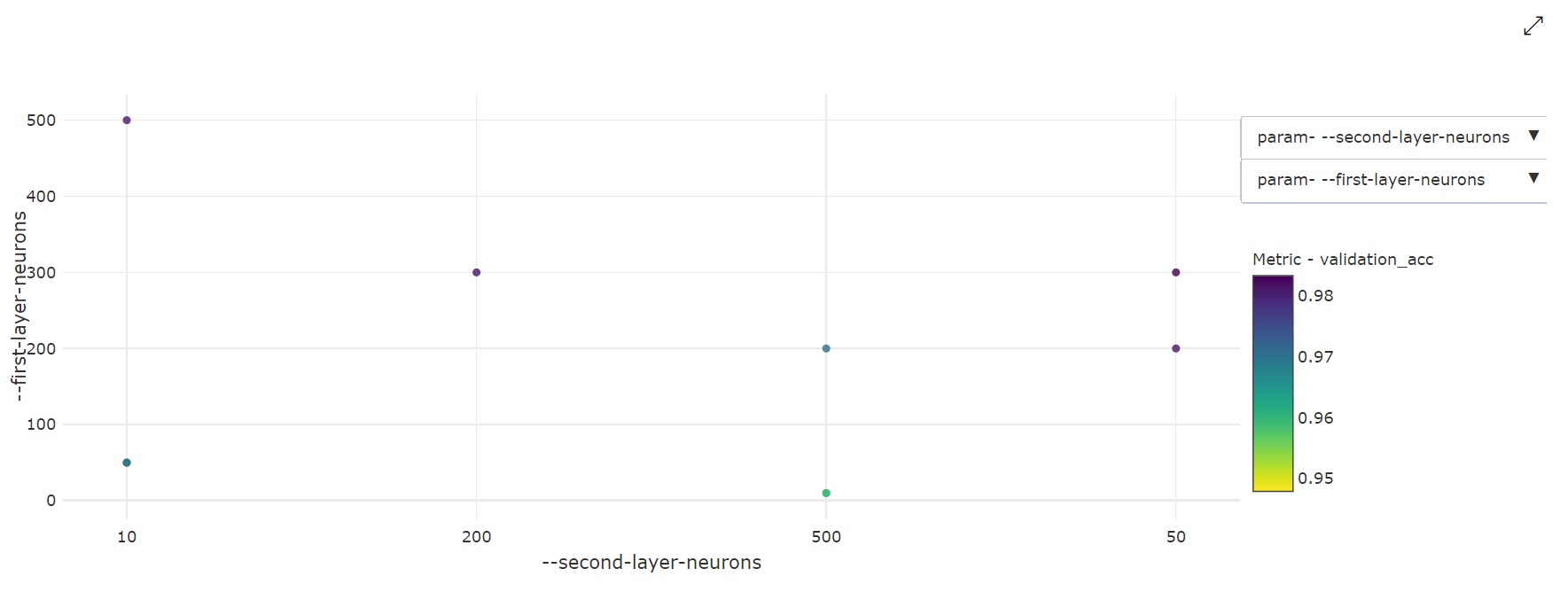
2차원 분산형 차트: 이 시각화에서는 개별 하이퍼 매개 변수 2개와 연결된 기본 메트릭 값 간의 상관 관계를 보여줍니다.
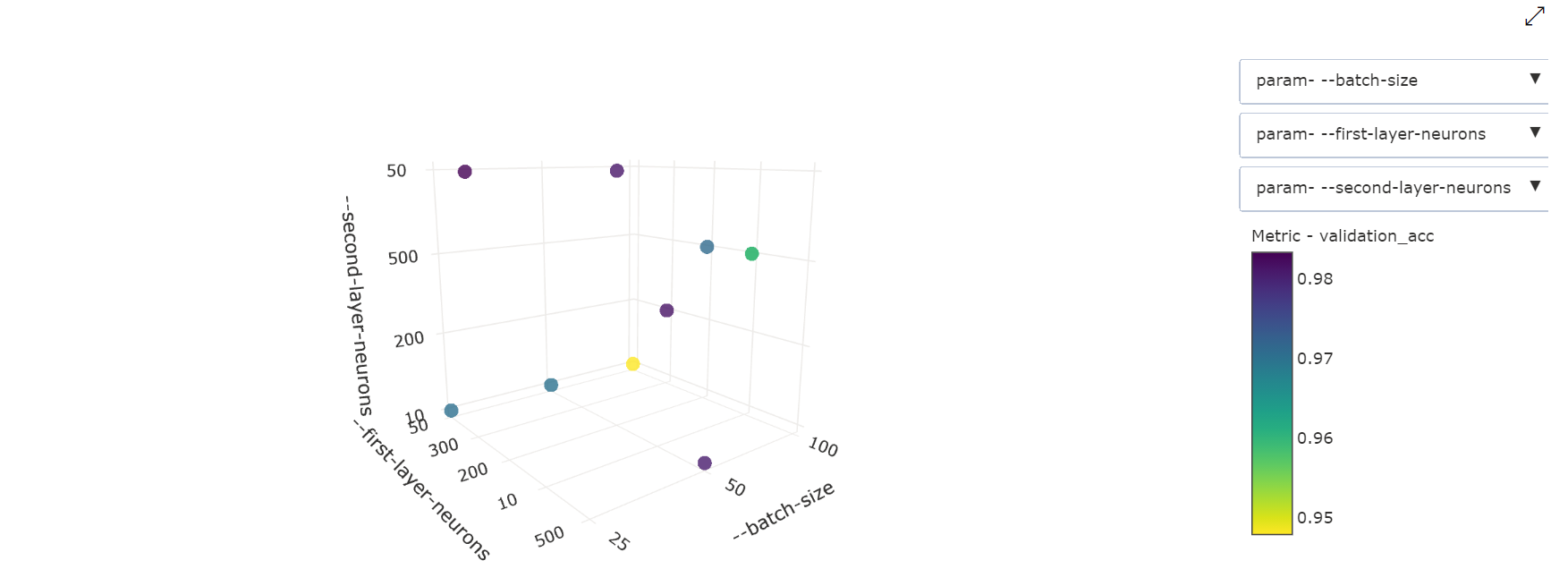
3차원 분산형 차트: 이 시각화는 2D와 동일하지만 기본 메트릭 값과의 상관 관계에 대한 하이퍼 매개 변수 차원 3개를 허용합니다. 3D 공간에서 다른 상관 관계를 보려면 클릭하고 끌어 차트 방향을 바꾸면 됩니다.
Notebook 위젯
Notebook 위젯을 사용하여 학습 실행의 진행률을 시각화할 수 있습니다. 다음 코드 조각은 Jupyter Notebook에서 모든 하이퍼 매개 변수 조정 실행을 시각화합니다.
from azureml.widgets import RunDetails
RunDetails(hyperdrive_run).show()
이 코드는 각 하이퍼 매개 변수 구성의 학습 실행에 대한 세부 정보가 있는 표를 표시합니다.
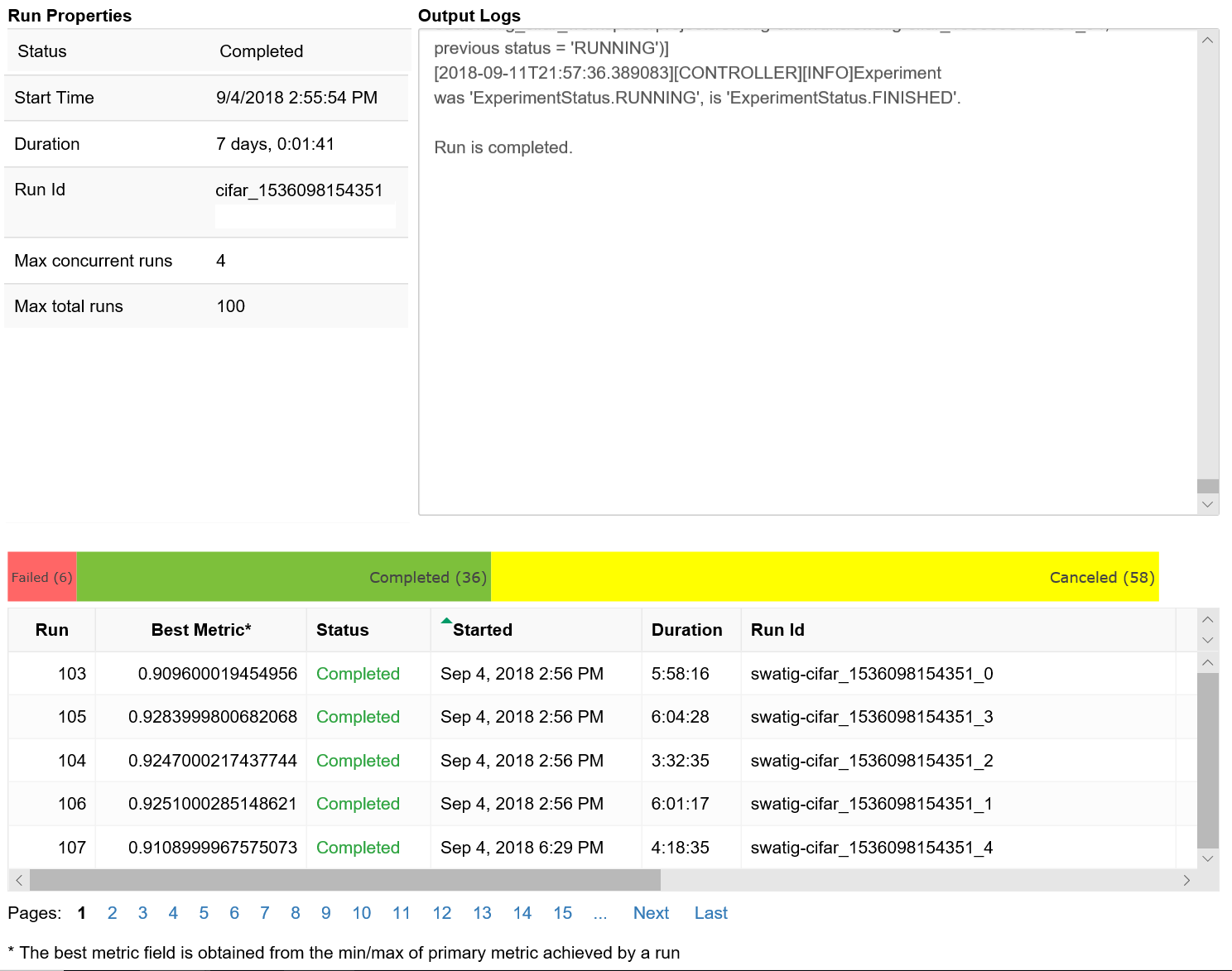
학습 진행률에 따라 각 실행의 성능을 시각화할 수도 있습니다.
최적 모델 찾기
모든 하이퍼 매개 변수 튜닝 실행이 완료되면 성능이 가장 좋은 구성과 하이퍼 매개 변수 값을 식별할 수 있습니다.
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details()['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print('\n Accuracy:', best_run_metrics['accuracy'])
print('\n learning rate:',parameter_values[3])
print('\n keep probability:',parameter_values[5])
print('\n batch size:',parameter_values[7])
샘플 노트북
이 폴더의 train-hyperparameter-* notebooks를 참조하세요.
Jupyter 노트북을 사용하여 이 서비스 검색 문서를 따라 노트북을 실행하는 방법을 알아봅니다.