Azure AI 검색의 성능 분석
이 문서에서는 Azure AI 검색에서 쿼리 및 인덱싱 성능을 분석하기 위한 도구, 동작 및 접근 방식을 설명합니다.
기준 수치 개발
대규모 구현에서는 Azure AI 검색 서비스를 프로덕션에 적용하기 전에 성능 벤치마킹 테스트를 수행하는 것이 중요합니다. 예상되는 검색 쿼리 로드와 예상 데이터 수집 워크로드를 모두 테스트해야 합니다(가능한 경우 두 워크로드를 동시에 실행). 벤치마크 수치를 통해 적절한 검색 계층, 서비스 구성 및 예상 쿼리 대기 시간을 확인할 수 있습니다.
벤치마크를 개발하려면 azure-search-performance-testing(GitHub) 도구를 사용하는 것이 좋습니다.
분산 서비스 아키텍처의 영향을 분리하려면 하나의 복제본과 하나의 파티션에 대해 서비스 구성을 테스트해 보세요.
참고 항목
스토리지 최적화 계층(L1 및 L2)의 경우 표준 계층보다 낮은 쿼리 처리량과 더 많은 대기 시간이 소요됩니다.
리소스 로깅 사용
관리자가 처분할 때 가장 중요한 진단 도구는 리소스 로깅입니다. 리소스 로깅은 검색 서비스에 대한 운영 데이터 및 메트릭의 컬렉션입니다. 리소스 로깅은 Azure Monitor를 통해 사용하도록 설정됩니다. Azure Monitor 사용 및 데이터 저장에 대한 비용이 들지만 서비스에 사용하도록 설정하면 성능 문제를 조사하는 데 도움이 될 수 있습니다.
다음 이미지는 쿼리 요청 및 응답의 이벤트 체인을 보여 줍니다. 대기 시간은 네트워크 전송 중, 앱 서비스 계층의 콘텐츠 처리 또는 검색 서비스에서 발생할 수 있습니다. 리소스 로깅의 주요 이점은 검색 서비스 관점에서 활동이 기록된다는 것입니다. 즉, 로그를 통해 성능 문제가 쿼리 또는 인덱싱 문제로 인한 것인지 아니면 다른 실패 지점으로 인한 것인지 확인할 수 있습니다.

리소스 로깅은 기록된 정보를 저장하기 위한 옵션을 제공합니다. 데이터에 대해 고급 Kusto 쿼리를 실행하여 사용량 및 성능에 대한 많은 질문에 답할 수 있도록 Log Analytics를 사용하는 것이 좋습니다.
검색 서비스 포털 페이지에서 진단 설정을 통해 로깅을 사용하도록 설정한 다음 로그를 선택하여 Log Analytics에 대해 Kusto 쿼리를 실행할 수 있습니다. 로그 쿼리를 사용하여 분석할 수 있는 Log Analytics 작업 영역으로 리소스 로그를 보내는 방법을 알아보려면 Azure 리소스에서 리소스 로그 수집 및 분석을 참조하세요.
제한 동작
제한은 검색 서비스가 용량에 있을 때 발생합니다. 쿼리 또는 인덱싱 중에 제한이 발생할 수 있습니다. 클라이언트 측에서 API 호출은 제한된 경우 503 HTTP 응답을 생성합니다. 인덱싱 중에 하나 이상의 항목이 인덱싱에 실패했음을 나타내는 207 HTTP 응답을 수신할 가능성도 있습니다. 이 오류는 검색 서비스가 용량에 가까워지고 있음을 나타냅니다.
경험을 바탕으로 제한의 양과 패턴을 수량화하는 것이 가장 좋습니다. 예를 들어 500,000개 중 하나의 검색 쿼리가 제한되는 것은 조사할 가치가 없을 수도 있습니다. 그러나 일정 기간 동안 많은 비율의 쿼리가 제한되면 큰 문제가 될 수 있습니다. 일정 기간 동안 제한을 관찰하여 제한이 발생할 가능성이 더 높은 시간 프레임을 식별하고 이를 통해 적절한 해결 방법을 결정할 수 있습니다.
대부분의 경우 제한 문제에 대한 간단한 해결 방법은 검색 서비스에 더 많은 리소스를 throw하는 것입니다(일반적으로 쿼리 기반 제한의 경우 복제본 또는 인덱싱 기반 제한의 경우 파티션). 그러나 복제본 또는 파티션을 늘리면 비용이 추가되므로 제한이 발생하는 이유를 파악하는 것이 중요합니다. 제한을 일으키는 조건을 조사하는 방법은 다음의 몇 개 섹션에서 설명합니다.
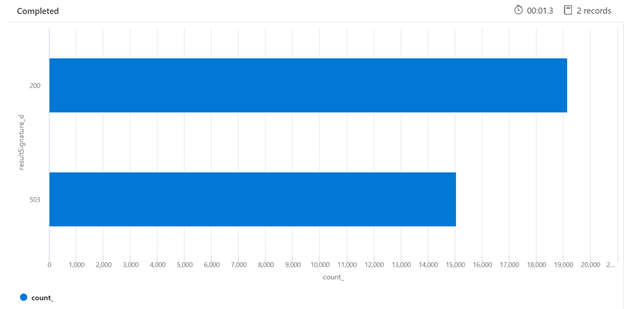
다음은 부하 상태에 있는 검색 서비스의 HTTP 응답 분석을 식별할 수 있는 Kusto 쿼리의 예입니다. 7일 동안, 렌더링된 막대형 차트에서는 응답 성공 수(200개)에 비해 상대적으로 높은 비율의 검색 쿼리가 제한되었음을 알 수 있습니다.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
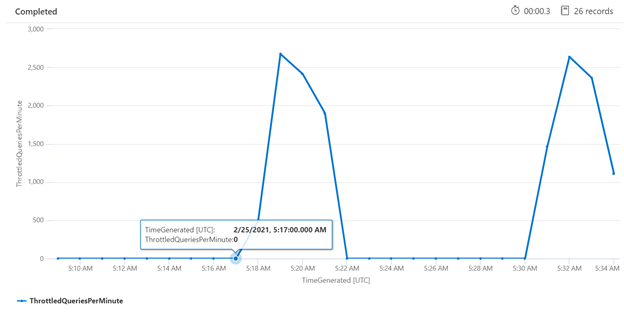
특정 기간에 대한 제한을 검사하면 제한이 더 자주 발생할 수 있는 시간을 식별할 수 있습니다. 아래 예에서 시계열 차트는 지정된 시간 프레임 동안 발생한 제한된 쿼리 수를 표시하는 데 사용됩니다. 이 경우 성능 벤치마킹을 사용하여 시간과 상관 관계가 있는 제한된 쿼리가 수행되었습니다.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
개별 쿼리 측정
경우에 따라 개별 쿼리를 테스트하여 성능을 확인하는 것이 유용할 수 있습니다. 이를 위해서는 검색 서비스가 작업을 완료하는 데 걸리는 시간과 클라이언트에서 왕복 요청을 수행하는 데 걸리는 시간을 확인할 수 있어야 합니다. 진단 로그를 사용하여 개별 작업을 조회할 수 있지만 REST 클라이언트에서 이 모든 작업을 수행하는 것이 더 쉬울 수 있습니다.
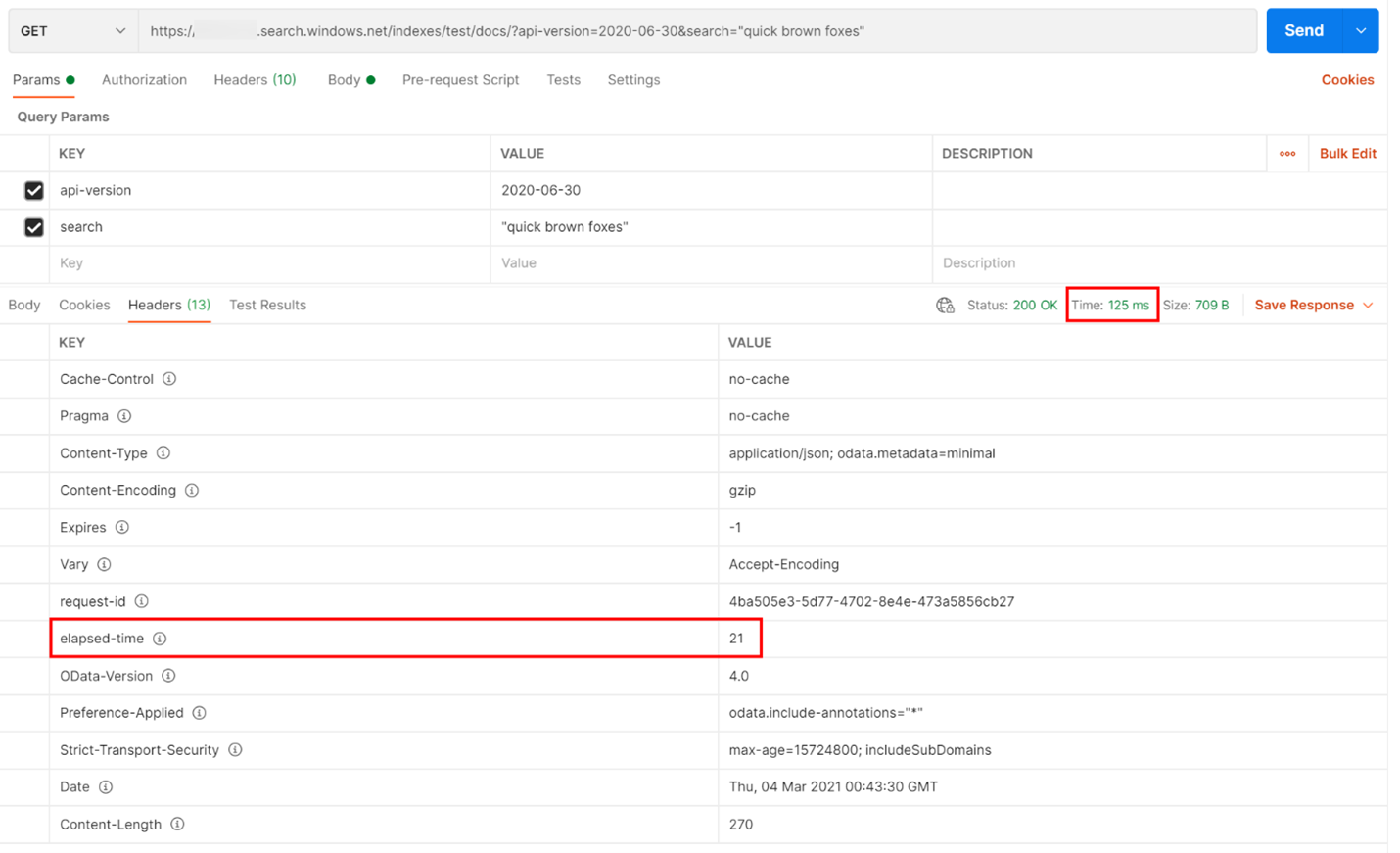
아래 예에서는 REST 기반 검색 쿼리가 실행되었습니다. Azure AI 검색은 모든 응답에 쿼리를 완료하는 데 걸리는 시간(밀리초)을 포함하며 이 시간은 헤더 탭에 "경과 시간"으로 표시됩니다. 응답 위쪽에 있는 상태 옆에서 왕복 시간을 확인할 수 있습니다. 이 경우 418밀리초(ms)입니다. 결과 섹션에서 "헤더" 탭을 선택했습니다. 아래 이미지에서 빨간색 상자로 강조 표시된 이 두 값을 사용하면 검색 서비스가 검색 쿼리를 완료하는 데 21ms가 걸렸고 전체 클라이언트 왕복 요청에 125ms가 걸렸습니다. 이 두 수치를 빼면 검색 쿼리를 검색 서비스로 전송하고 검색 결과를 다시 클라이언트로 전송하는 데 104ms의 추가 시간이 소요되었음을 확인할 수 있습니다.
이 기술은 쿼리 성능에 영향을 주는 다른 요인으로부터 네트워크 대기 시간을 격리하는 데 도움이 됩니다.
쿼리 속도
검색 서비스가 요청을 제한하는 한 가지 잠재적인 이유는 볼륨이 QPS(초당 쿼리 수) 또는 QPM(분당 쿼리 수)으로 캡처되는 쿼리 수가 너무 많기 때문입니다. 검색 서비스에서 수신하는 QPS가 많을수록 일반적으로 이러한 쿼리에 응답하는 데 더 많은 시간이 걸리고 더 이상 따라잡을 수 없게 되면 제한 503 HTTP 응답이 다시 전송됩니다.
다음 Kusto 쿼리는 쿼리의 평균 기간(밀리초)(AvgDurationMS) 및 각 쿼리에서 반환된 평균 문서 수(AvgDocCountReturned)와 함께 QPM으로 측정된 쿼리 볼륨을 보여 줍니다.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart

팁
이 차트 뒤의 데이터를 표시하려면 | render timechart 줄을 제거한 다음 쿼리를 다시 실행합니다.
쿼리의 인덱싱 효과
성능을 볼 때 고려해야 할 중요한 요소는 인덱싱이 검색 쿼리와 동일한 리소스를 사용한다는 것입니다. 많은 양의 콘텐츠를 인덱싱하는 경우 서비스가 두 워크로드를 모두 수용하려고 시도함에 따라 대기 시간이 증가할 것을 예상할 수 있습니다.
쿼리 속도가 느려지면 인덱싱 작업의 시간을 확인하여 쿼리 성능 저하와 일치하는지 확인합니다. 예를 들어 인덱서가 검색 쿼리의 성능 저하와 관련된 일별 또는 시간별 작업을 실행하고 있을 수 있습니다.
이 섹션에서는 검색 및 인덱싱 속도를 시각화하는 데 도움이 되는 일련의 쿼리를 제공합니다. 이러한 예에서는 시간 범위가 쿼리에서 설정됩니다. Azure Portal에서 쿼리를 실행할 때 쿼리에서 설정을 지정해야 합니다.
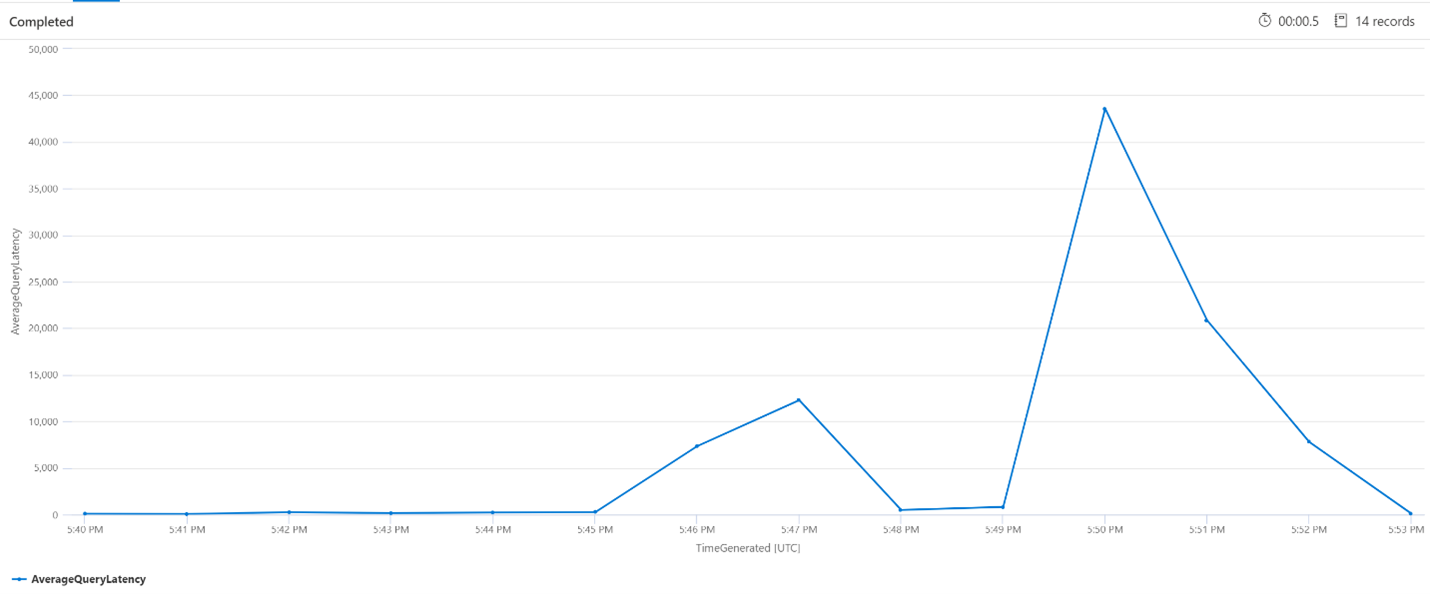
평균 쿼리 대기 시간
아래 쿼리에서는 검색 쿼리의 평균 대기 시간을 표시하기 위해 1분 간격 크기를 사용합니다. 차트에서 평균 대기 시간이 5:45pm까지 낮았고 5:53pm까지 지속되었음을 알 수 있습니다.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
QPM(분당 평균 쿼리 수)
다음 쿼리를 통해 분당 평균 쿼리 수를 확인하여 대기 시간에 영향을 줄 수 있는 검색 요청이 급증하지 않았는지 확인할 수 있습니다. 차트에서 약간의 변동이 있지만 요청 수의 급증을 나타내는 부분은 없습니다.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart

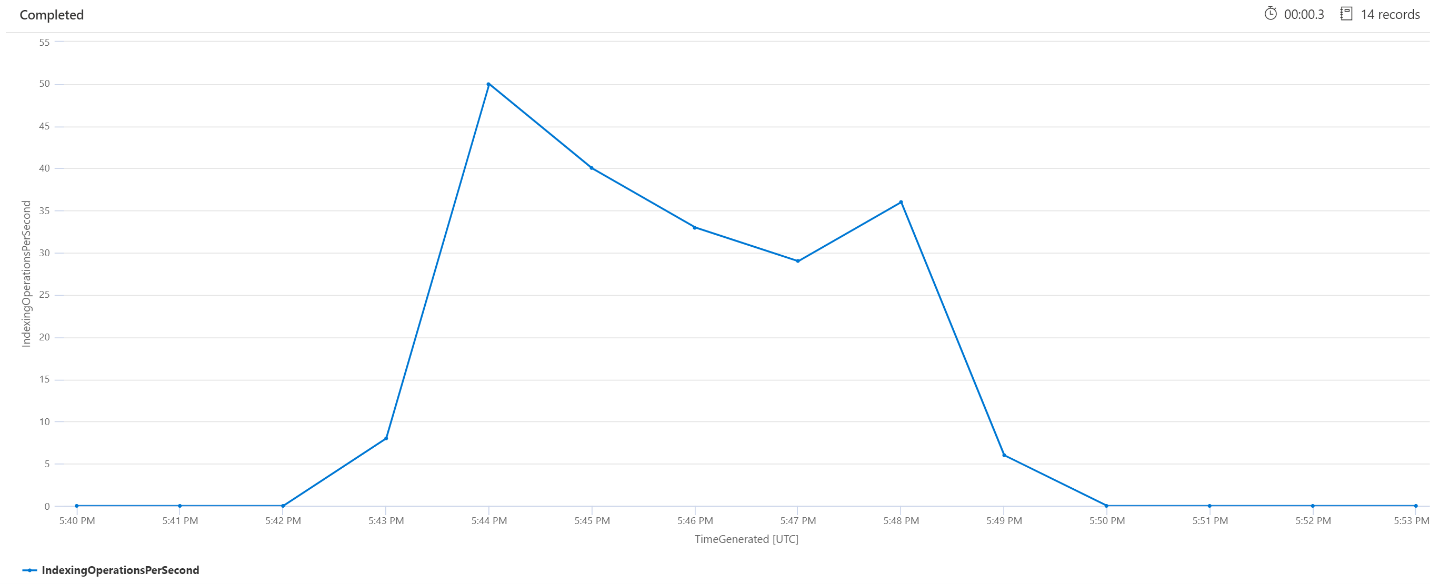
OPM(분당 인덱싱 작업)
여기서는 분당 인덱싱 작업 수를 살펴보겠습니다. 차트에서 많은 양의 데이터가 오후 5시 42분에 시작되어 오후 5시 50분에 끝났음을 알 수 있습니다. 이 인덱싱은 검색 쿼리의 지연이 시작되기 3분 전에 시작되었고 검색 쿼리의 지연이 끝나기 3분 전에 끝났습니다.
이 인사이트를 통해 검색 서비스가 충분히 사용되어 인덱싱이 검색 쿼리 대기 시간에 영향을 미치기까지 약 3분이 걸렸다는 것을 알 수 있습니다. 또한 인덱싱이 완료된 후 검색 서비스가 새로 인덱싱된 콘텐츠의 모든 작업을 완료하여 쿼리 지연이 해소되기까지 3분이 추가로 걸렸음을 확인할 수 있습니다.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
백그라운드 서비스 처리
쿼리 또는 인덱싱 대기 시간이 주기적으로 급증하는 것은 드문 일이 아닙니다. 인덱싱 또는 높은 쿼리 속도에 대한 응답으로 급증이 발생할 수 있지만 병합 작업 중에도 발생할 수 있습니다. 검색 인덱스는 청크 또는 분할된 데이터베이스로 저장됩니다. 시스템은 주기적으로 작게 분할된 데이터베이스를 큰 분할 데이터베이스로 병합하여 서비스 성능을 최적화할 수 있습니다. 이 병합 프로세스는 이전에 인덱스에서 삭제하도록 표시된 문서를 정리하여 저장 공간을 복구합니다.
분할된 데이터베이스 병합은 빠르지만 리소스를 많이 사용하므로 서비스 성능이 저하될 수 있습니다. 짧은 쿼리 대기 시간이 표시되고 이러한 버스트가 인덱싱된 콘텐츠에 대한 최근 변경 내용과 일치하는 경우 지연 시간이 분할된 병합 작업 때문이라고 가정할 수 있습니다.
다음 단계
서비스 성능 분석과 관련된 문서를 검토하세요.