Service Fabric 상태 모니터링 소개
다양하고 유연하며 확장 가능한 상태 평가 및 보고 기능을 제공하는 상태 모델이 Azure 서비스 패브릭에 도입되었습니다. 이 모델에서는 클러스터의 상태와 클러스터에서 실행되는 서비스의 상태를 거의 실시간으로 모니터링할 수 있습니다. 간편하게 상태 정보를 얻을 수 있고 잠재적인 문제로 인한 대규모 중단 사태가 발생하기 전에 해당 문제를 해결할 수 있습니다. 일반적인 모델에서는 서비스가 로컬 보기를 기반으로 한 보고서를 보내고 정보는 전체 클러스터 수준 보기를 제공하도록 집계됩니다.
Service Fabric 구성 요소는 이 풍부한 상태 모델을 사용하여 현재 상태를 보고합니다. 동일한 메커니즘을 사용하여 애플리케이션의 상태를 보고할 수도 있습니다. 사용자 지정 조건을 캡처하는 고품질의 상태 보고에 투자하면 실행 중인 애플리케이션에 대한 문제를 훨씬 더 쉽게 감지하고 수정할 수 있습니다.
Service Fabric 상태 모델 및 사용 방법을 설명하는 교육 비디오는 이 페이지를 확인하세요.
참고 항목
이전에는 모니터링되는 업그레이드에 대한 요구를 해결하기 위해 상태 하위 시스템을 시작했습니다. Service Fabric은 모니터링되는 애플리케이션 및 클러스터 업그레이드를 제공하여 가동 중지 시간 없는 최대 가용성을 보장하고 사용자 개입을 최소화하거나 필요 없도록 합니다. 이 목표를 달성하기 위해 업그레이드에서는 구성된 업그레이드 정책을 기초로 상태를 확인합니다. 상태가 바람직한 임계값에 부합하는 경우에만 업그레이드를 진행할 수 있습니다. 그렇지 않으면 관리자가 문제를 해결할 수 있도록 업그레이드가 자동으로 롤백되거나 일시 중지됩니다. 애플리케이션 업그레이드에 대한 자세한 내용은 이 문서를 참조하세요.
Health 스토어
Health 스토어는 클러스터의 엔터티에 대한 상태 관련 정보를 쉽게 검색하고 평가하기 위해 보관합니다. 또한 높은 가용성과 확장성을 제공할 수 있도록 서비스 패브릭 지속형 상태 저장 서비스로 구현됩니다. Health 스토어는 fabric:/System 애플리케이션의 일부로, 클러스터가 가동되어 실행될 때 사용할 수 있습니다.
상태 엔터티 및 계층 구조
상태 엔터티는 여러 엔터티 간의 상호 작용 및 종속성을 캡처하는 논리적 계층 구조로 구성됩니다. 상태 저장소는 Service Fabric 구성 요소로부터 수신한 보고서를 기준으로 상태 엔터티와 계층 구조를 자동으로 빌드합니다.
상태 엔터티는 서비스 패브릭 엔터티를 미러링합니다. (예: 상태 애플리케이션 엔터티가 클러스터에 배포된 애플리케이션 인스턴스와 일치하는 반면, 상태 노드 엔터티는 Service Fabric 클러스터 노드와 일치하는지 등.) 상태 계층 구조는 시스템 엔터티의 상호 작용을 캡처하며 고급 상태 평가를 위한 기준입니다. 서비스 패브릭 기술 개요에서 주요 서비스 패브릭 개념에 대해 알아볼 수 있습니다. 애플리케이션에 대한 자세한 내용은 Service Fabric 애플리케이션 모델을 참조하세요.
상태 엔터티 및 계층 구조를 사용하면 클러스터와 애플리케이션에 대한 효과적인 보고, 디버깅 및 모니터링이 가능합니다. 상태 모델은 클러스터에서 많이 이동되는 항목의 상태를 정확하게 세분화 하여 표현할 수 있습니다.
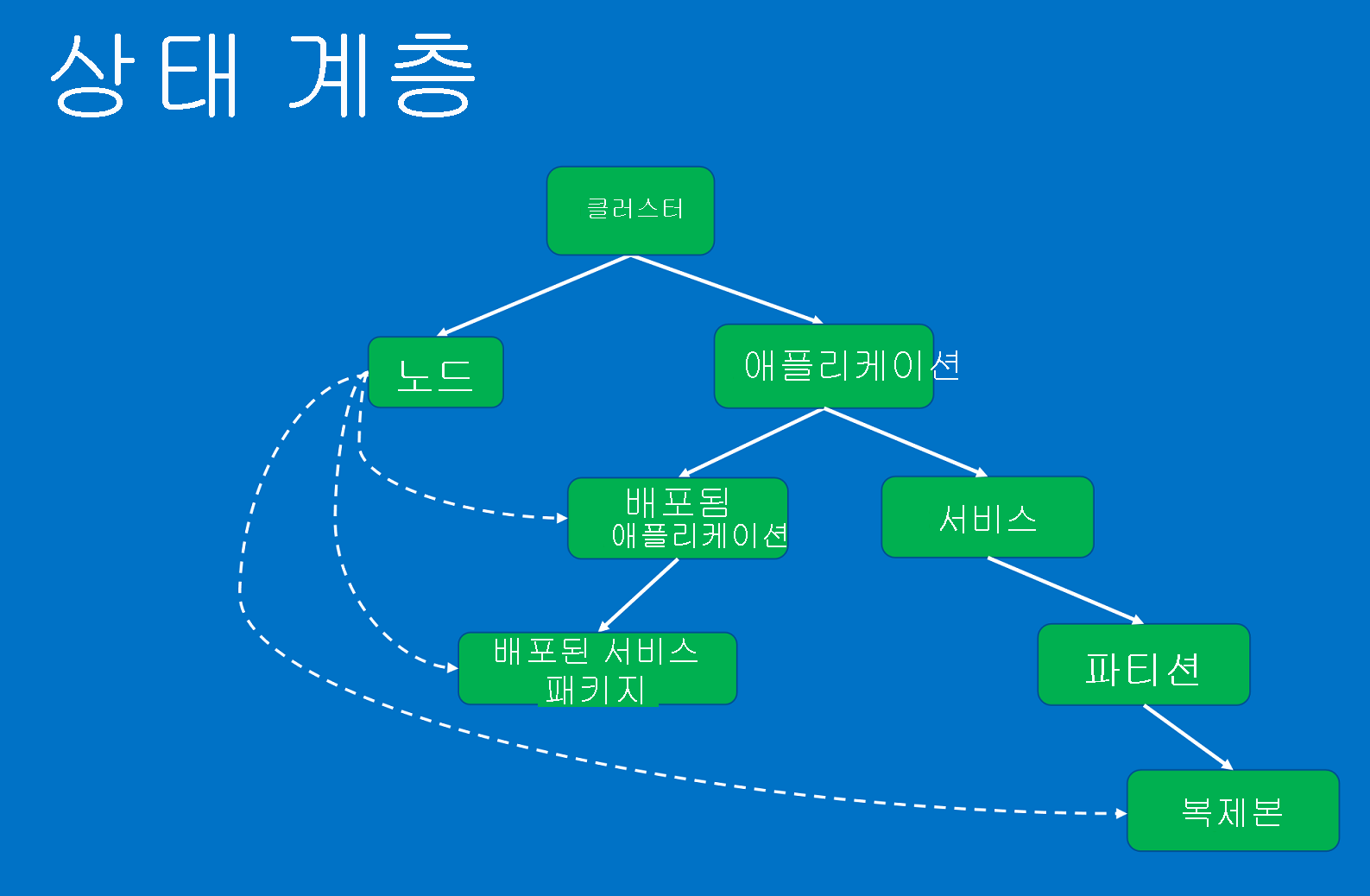 부모-자식 관계에 따른 계층 구조로 구성된 상태 엔터티
부모-자식 관계에 따른 계층 구조로 구성된 상태 엔터티
상태 엔터티는 다음과 같습니다.
- 클러스터. 서비스 패브릭 클러스터의 상태를 나타냅니다. 클러스터 상태 보고서에서는 전체 클러스터에 영향을 주는 상태를 설명합니다. 이러한 조건은 클러스터의 여러 엔터티나 클러스터 자체에 영향을 미칩니다. 조건에 따라 보고자는 하나 이상의 비정상 상태인 자식으로 문제 범위를 축소할 수 없습니다. 예를 들면 네트워크 분할 또는 통신 문제로 인한 클러스터의 스플릿 브레인이 포함됩니다.
- 노드. 서비스 패브릭 노드의 상태를 나타냅니다. 노드 상태 보고서에서는 노드 기능에 영향을 주는 상태를 설명합니다. 일반적으로 노드에서 실행되는 배포된 모든 엔터티에 영향을 줍니다. 예를 들면 노드에 디스크 공간(또는 메모리, 연결 등 기타 컴퓨터 전반적인 속성)이 부족하거나 노드가 다운되는 경우가 포함됩니다. 노드 엔터티는 노드 이름(문자열)으로 식별됩니다.
- 응용 프로그램. 클러스터에서 실행 중인 애플리케이션 인스턴스의 상태를 나타냅니다. 애플리케이션 상태 보고서에서는 전체 애플리케이션 상태에 영향을 주는 상태를 설명합니다. 이 상태는 개별 자식(서비스 또는 배포된 애플리케이션)으로 좁힐 수 없습니다. 예를 들면 애플리케이션에서 서로 다른 서비스 간의 엔드투엔드 상호 작용이 포함됩니다. 애플리케이션 엔터티는 애플리케이션 이름(URI)으로 식별됩니다.
- 서비스. 클러스터에서 실행되는 서비스의 상태를 나타냅니다. 서비스 상태 보고서에서는 전체 서비스 상태에 영향을 주는 상태를 설명합니다. 보고자는 비정상 파티션 또는 복제본으로 문제 범위를 축소할 수 없습니다. 예를 들면 모든 파티션에 대해 문제를 일으키는 서비스 구성(포트 또는 외부 파일 공유 등)이 포함됩니다. 서비스 엔터티는 서비스 이름(URI)으로 식별됩니다.
- 파티션. 서비스 파티션의 상태를 나타냅니다. 파티션 상태 보고서에서는 전체 복제본 세트에 영향을 주는 상태를 설명합니다. 예를 들면 복제본의 수가 목표 개수 아래이거나 파티션이 쿼럼 손실 상태인 경우가 포함됩니다. 파티션 엔터티는 파티션 ID(GUID)로 식별됩니다.
- 복제본. 상태 저장 서비스 복제본 또는 상태 비저장 서비스 인스턴스의 상태를 나타냅니다. 복제본은 Watchdog 및 시스템 구성 요소가 애플리케이션에 대해 보고할 수 있는 최소 단위입니다. 상태 저장 서비스의 경우 보조 복제본에 작업을 복제할 수 없는 주 복제본과 느린 복제를 예로 들 수 있습니다. 또한 상태 비저장 인스턴스는 리소스 부족 또는 연결 문제가 있는 경우에 보고할 수 있습니다. 복제본 엔터티는 파티션 ID(GUID) 및 복제본 또는 인스턴스 ID(long)로 식별됩니다.
- DeployedApplication. 노드에서 실행되는 애플리케이션의 상태를 나타냅니다. 배포된 애플리케이션 상태 보고서에서는 동일한 노드에 배포된 서비스 패키지로 좁힐 수 없는 노드의 애플리케이션별 상태를 설명합니다. 예를 들면 애플리케이션 패키지를 해당 노드에 다운로드할 수 없는 경우 또는 해당 노드에서 애플리케이션 보안 주체를 설정하는 데 문제가 있는 경우가 포함됩니다. 애플리케이션 이름(URI) 및 노드 이름(문자열)으로 배포된 애플케이션이 식별됩니다.
- DeployedServicePackage. 클러스터의 노드에서 실행 중인 서비스 패키지의 상태를 나타냅니다. 동일한 애플리케이션에 대해 동일한 노드의 다른 서비스 패키지에 영향을 주지 않는 서비스 패키지별 상태를 설명합니다. 예를 들면 서비스 패키지의 코드 패키지를 시작할 수 없거나 구성 패키지를 읽을 수 없는 경우가 포함됩니다. 배포된 서비스 패키지는 애플리케이션 이름(URI), 노드 이름(문자열), 서비스 매니페스트 이름(문자열) 및 서비스 패키지 활성화 ID(문자열)로 식별됩니다.
상태 모델의 세분성을 통해 문제를 쉽게 감지하여 수정할 수 있습니다. 예를 들어, 서비스가 응답하지 않는 경우 애플리케이션 인스턴스가 비정상이라고 보고될 수 있습니다. 하지만 문제가 해당 애플리케이션 내의 모든 서비스에 영향을 주지는 않을 수도 있으므로 그 수준에서 보고하는 것은 이상적이지 않습니다. 많은 정보가 해당 파티션을 가리키는 경우 보고서는 비정상 서비스에 적용되거나, 특정 자식 파티션에 적용되어야 합니다. 데이터가 계층 구조를 통해 자동으로 표면화되며 비정상 파티션을 서비스 및 애플리케이션 수준에서 볼 수 있습니다. 이러한 집계는 문제의 근본 원인을 빠르고 정확하게 찾아내서 해결하는 데 도움이 됩니다.
상태 계층 구조는 부모-자식 관계로 이루어집니다. 클러스터는 노드 및 애플리케이션으로 구성됩니다. 애플리케이션에는 서비스 및 배포된 애플리케이션이 포함됩니다. 배포된 애플리케이션에는 배포된 서비스 패키지가 포함됩니다. 서비스에는 파티션이 있고 각 파티션에는 하나 이상의 복제본이 있습니다. 노드 및 배포된 엔터티 간에는 특수한 관계가 있습니다. 기관 시스템 구성 요소(장애 조치(Failover) 관리자 서비스)에서 비정상 노드로 보고되면 배포된 애플리케이션, 서비스 패키지 및 배포된 복제본에 영향을 줍니다.
상태 계층 구조는 최신 상태 보고서에 기반한 시스템의 최신 상태를 나타내며, 이 정보는 거의 실시간 정보입니다. 내부 및 외부 Watchdog는 동일한 엔터티에 대해 애플리케이션별 논리 또는 사용자 지정 모니터링 상태에 따라 보고할 수 있습니다. 사용자 보고서는 시스템 보고서와 함께 존재합니다.
대규모 클라우드 서비스를 설계할 때 상태를 보고하고 이에 대응하는 방식에 대해 투자하도록 계획합니다. 이러한 선투자를 하면 서비스를 더 쉽게 디버그/모니터링/운영할 수 있습니다.
성능 상태
서비스 패브릭은 3가지 성능 상태(정상, 경고 및 오류)를 사용하여 엔터티가 정상인지 여부를 설명합니다. Health 스토어로 전송되는 모든 보고서에 이러한 상태 중 하나를 지정해야 합니다. 상태 평가 결과는 이러한 상태 중 하나입니다.
사용 가능한 성능 상태 는 다음과 같습니다.
- 확인. 엔터티가 정상입니다. 엔터티 또는 자식(해당하는 경우)에 대해 보고된 알려진 문제가 없습니다.
- 경고. 엔터티에 몇 가지 문제가 있지만 여전히 제대로 작동합니다. 예를 들어, 지연이 있으나 아직 기능상의 문제는 없습니다. 일부 경우 외부 개입 없이도 경고 상태가 자체 해결되기도 합니다. 이러한 경우 상태 보고서는 알림을 전달하고 상황에 대한 정보를 제공합니다. 또한 사용자 개입이 없으면 심각한 문제를 초래하는 경고 상태도 있을 수 있습니다.
- 오류. 엔터티가 비정상입니다. 엔터티가 제대로 작동하지 않으므로 해당 엔터티의 상태를 해결하는 조치를 취해야 합니다.
- ‘알 수 없음’. 엔터티가 Health 스토어에 존재하지 않습니다. 이 결과는 여러 구성 요소에서 결과를 병합하는 분산 쿼리에서 얻을 수 있습니다. 예를 들어, 노드 목록 가져오기 쿼리는FailoverManager, ClusterManager 및 HealthManager로, 애플리케이션 목록 가져오기 쿼리는 ClusterManager 및 HealthManager로 갑니다. 이들 쿼리는 여러 시스템 구성 요소의 결과를 병합합니다. 다른 시스템 구성 요소에서 상태 저장소에 없는 엔터티를 반환할 경우 병합된 결과에 알 수 없는 상태가 있습니다. 상태 보고서가 아직 처리되지 않았거나 엔터티가 삭제 후 정리되지 않아 엔터티가 저장소에 없습니다.
상태 정책
Health 스토어는 상태 정책을 적용하여 보고서와 해당 자식에 따라 엔터티가 정상인지 결정합니다.
참고 항목
상태 정책은 클러스터 매니페스트(클러스터 및 노드 상태 평가용) 또는 애플리케이션 매니페스트(애플리케이션 및 해당 자식 평가용)에서 지정할 수 있습니다. 또한 해당 평가에만 사용되는 사용자 지정 상태 평가 정책에서 상태 평가 요청을 전달할 수도 있습니다.
기본적으로 서비스 패브릭은 부모-자식 계층 구조 관계에 대한 엄격한 규칙(모든 것이 정상이어야 함)을 적용합니다. 자식 중 하나에 비정상 이벤트가 하나만 있어도 부모가 비정상으로 간주됩니다.
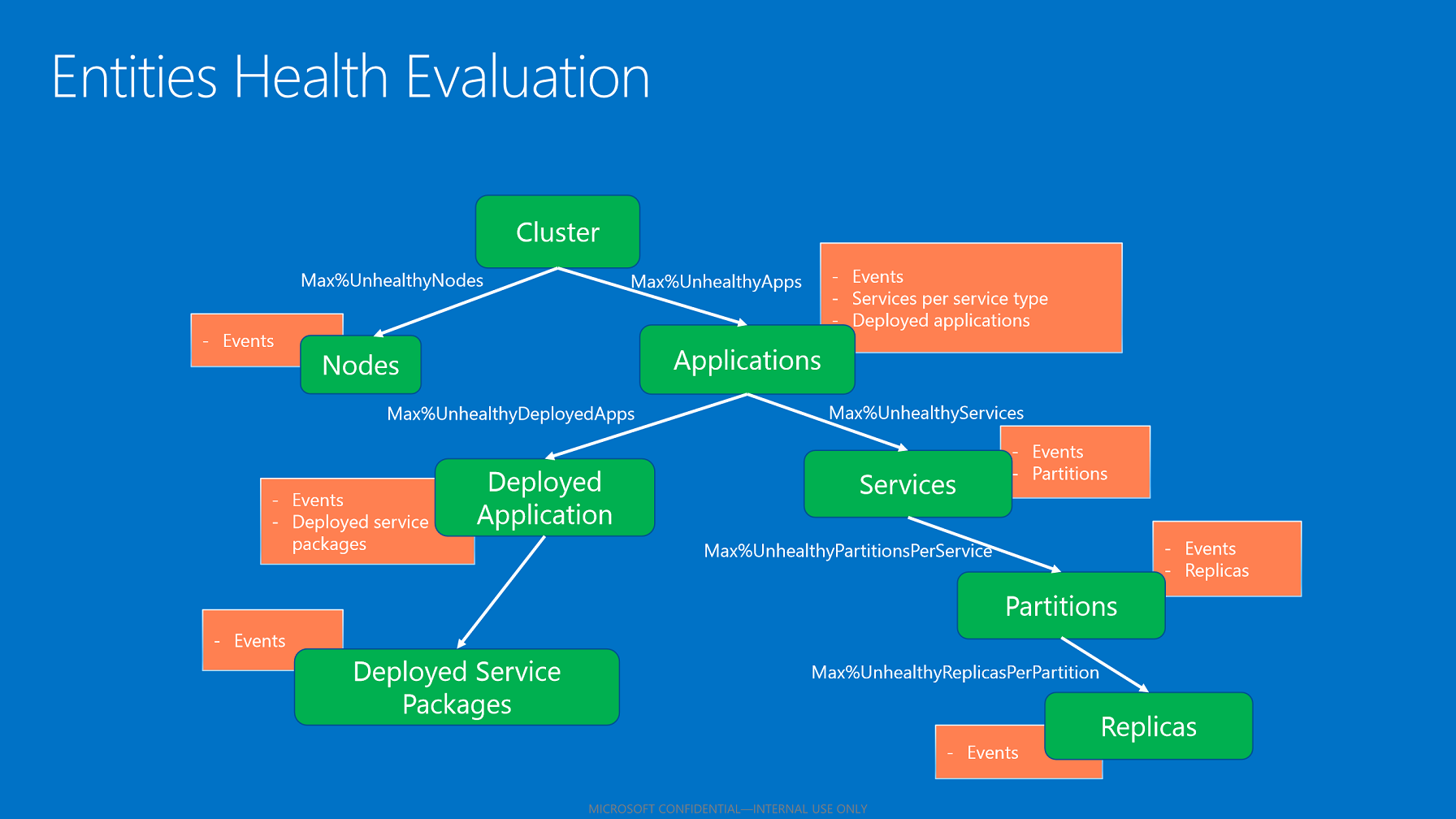
클러스터 상태 정책
클러스터 상태 정책 은 클러스터 성능 상태 및 노드 성능 상태를 평가하는 데 사용됩니다. 이 정책은 클러스터 매니페스트에서 정의할 수 있습니다. 없는 경우는 기본 정책(0 허용 실패)이 사용됩니다.
클러스터 상태 정책은 다음과 같습니다.
ConsiderWarningAsError. 상태를 평가하는 동안 경고 상태 보고를 오류로 처리할지 여부를 지정합니다. 기본값: false입니다.
MaxPercentUnhealthyApplications. 클러스터에서 오류로 처리하기 전에 비정상 상태를 유지할 수 있는 애플리케이션의 최대 허용 비율을 지정합니다.
MaxPercentUnhealthyNodes. 클러스터에서 오류로 처리하기 전에 비정상 상태를 유지할 수 있는 노드의 최대 허용 비율을 지정합니다. 대형 클러스터에는 항상 복구를 위해 다운되거나 중단되는 노드가 있으므로 이 비율은 이를 허용할 수 있도록 구성되어야 합니다.
ApplicationTypeHealthPolicyMap. 클러스터 상태를 평가하는 동안 애플리케이션 유형 상태 정책 맵을 사용하여 특수 애플리케이션 유형을 설명할 수 있습니다. 기본적으로 모든 애플리케이션은 풀에 배치되고 MaxPercentUnhealthyApplications를 사용하여 평가됩니다. 일부 애플리케이션 유형을 다르게 처리해야 하는 경우, 전역 풀에서 꺼낼 수 있습니다. 대신, 맵 내의 해당 애플리케이션 유형 이름과 연결된 백분율에 대해 평가됩니다. 예를 들어 클러스터에는 다양한 유형의 애플리케이션 수천 개와 특수 애플리케이션 유형의 제어 애플리케이션 인스턴스가 약간 있습니다. 제어 애플리케이션은 절대 오류가 발생하면 안 됩니다. 일부 실패를 허용하도록 전체 MaxPercentUnhealthyApplications를 20%로 설정할 수 있지만, 애플리케이션 유형 "ControlApplicationType"의 경우에는 MaxPercentUnhealthyApplications를 0으로 설정해야 합니다. 이러한 방식으로, 여러 애플리케이션 중 일부가 비정상 상태이더라도 전체 비정상 비율보다 낮으면 클러스터가 경고로 평가됩니다. 경고 상태는 클러스터 업그레이드 또는 오류 상태에 의해 트리거되는 기타 모니터링에 영향을 주지 않습니다. 하지만 제어 애플리케이션 중 하나라도 잘못되면 클러스터가 비정상 상태가 되고, 이로 인해 클러스터 업그레이드는 업그레이드 구성에 따라 롤백 또는 차단됩니다. 맵에 정의된 애플리케이션 유형의 경우 모든 애플리케이션 인스턴스를 애플리케이션 전체 풀에서 가져옵니다. 이러한 애플리케이션은 맵의 특정 MaxPercentUnhealthyApplications를 사용하여 총 애플리케이션 수를 기반으로 평가됩니다. 나머지 애플리케이션은 전체 풀에 남아 있으며 MaxPercentUnhealthyApplications를 사용하여 평가됩니다.
다음 예제는 클러스터 매니페스트에서 발췌한 내용입니다. 애플리케이션 유형 맵에 항목을 정의하려면 매개 변수 이름 앞에 "ApplicationTypeMaxPercentUnhealthyApplications-"를 붙이고 그 뒤에 애플리케이션 유형 이름을 붙이면 됩니다.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. 클러스터 상태를 평가하는 동안 노드 유형 상태 정책 맵을 사용하여 특수 노드 유형을 설명할 수 있습니다. 노드 유형은 맵 내의 해당 노드 유형 이름과 연결된 백분율에 대해 평가됩니다. 이 값을 설정해도MaxPercentUnhealthyNodes에 사용되는 노드의 전역 풀에는 영향을 주지 않습니다. 예를 들어 클러스터에는 다양한 유형의 여러 노드가 있고 중요한 작업을 호스트하는 몇 가지 노드 유형이 있습니다. 해당 유형의 노드는 가동 중단되지 않아야 합니다. 모든 노드의 실패를 허용하기 위해 전역MaxPercentUnhealthyNodes를 20%로 지정할 수 있지만 노드 유형SpecialNodeType에 대해서는MaxPercentUnhealthyNodes를 0으로 설정합니다. 이러한 방식으로, 여러 노드 중 일부가 비정상 상태이더라도 전체 비정상 비율보다 낮으면 클러스터는 경고 상태로 평가됩니다. 경고 상태는 클러스터 업그레이드 또는 오류 상태에 의해 트리거되는 기타 모니터링에 영향을 주지 않습니다. 그러나 오류 상태에 있는SpecialNodeType유형의 노드 하나만으로도 클러스터가 비정상 상태가 되며 업그레이드 구성에 따라 롤백이 트리거되거나 클러스터 업그레이드가 일시 중지됩니다. 반면에 전역MaxPercentUnhealthyNodes를 0으로 설정하고, 오류 상태인SpecialNodeType유형의 한 노드에서SpecialNodeType최대 백분율 비정상 노드를 100으로 설정해도 이 경우에는 전역 제한이 더 엄격하므로 해당 클러스터가 오류 상태를 유지합니다.다음 예제는 클러스터 매니페스트에서 발췌한 내용입니다. 노드 유형 맵에 항목을 정의하려면 매개 변수 이름 앞에 "NodeTypeMaxPercentUnhealthyNodes-"를 붙이고 그 뒤에 노드 유형 이름을 붙이면 됩니다.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
애플리케이션 상태 정책
애플리케이션 상태 정책은 애플리케이션 및 해당 자식에 대해 이벤트 및 하위 상태 집계의 평가를 수행하는 방법을 설명합니다. 애플리케이션 패키지의 애플리케이션 매니페스트 ApplicationManifest.xml에서 정의할 수 있습니다. 정책을 지정하지 않으면 상태 보고가 있거나 자식이 경고 또는 오류 성능 상태인 경우 서비스 패브릭에서 해당 엔터티를 비정상으로 가정합니다. 구성 가능한 정책은 다음과 같습니다.
- ConsiderWarningAsError. 상태를 평가하는 동안 경고 상태 보고를 오류로 처리할지 여부를 지정합니다. 기본값: false입니다.
- MaxPercentUnhealthyDeployedApplications. 애플리케이션에서 오류로 처리하기 전에 비정상 상태를 유지할 수 있는 배포된 애플리케이션의 최대 허용 비율을 지정합니다. 이 비율은 클러스터에서 애플리케이션이 현재 배포되어 있는 노드 수에 대해 배포된 비정상 애플리케이션의 수를 나누어 계산됩니다. 계산값은 적은 수의 노드에서 오류 하나를 허용할 수 있도록 반올림됩니다. 기본 비율: 0.
- DefaultServiceTypeHealthPolicy. 애플리케이션에서 모든 서비스 유형의 기본 상태 정책을 대체하는 기본 서비스 유형 상태 정책을 지정합니다.
- ServiceTypeHealthPolicyMap. 서비스 유형별 서비스 상태 정책의 맵을 제공합니다. 이러한 정책은 지정된 서비스 유형의 기본 서비스 유형 상태 정책을 대체합니다. 예를 들어 애플리케이션에 상태 비저장 게이트웨이 서비스 유형과 상태 저장 엔진 서비스 유형이 있다면, 평가를 위한 상태 정책을 다르게 구성할 수 있습니다. 서비스 유형별로 정책을 지정할 때 서비스의 상태를 좀더 세분화하여 제어할 수 있습니다.
서비스 유형 상태 정책
서비스 유형 상태 정책 은 서비스 및 서비스의 자식을 평가 및 집계하는 방법을 지정합니다. 정책은 다음과 같습니다.
- MaxPercentUnhealthyPartitionsPerService. 서비스를 비정상으로 처리하기 전에 허용되는 최대 비정상 파티션 비율을 지정합니다. 기본 비율: 0.
- MaxPercentUnhealthyReplicasPerPartition. 파티션을 비정상으로 처리하기 전에 허용되는 최대 비정상 복제본 비율을 지정합니다. 기본 비율: 0.
- MaxPercentUnhealthyServices. 애플리케이션을 비정상으로 처리하기 전에 허용되는 최대 비정상 서비스 비율을 지정합니다. 기본 비율: 0.
다음 예제는 애플리케이션 매니페스트에서 발췌한 내용입니다.
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
상태 평가
사용자 및 자동화된 서비스가 언제든지 엔터티의 상태를 평가할 수 있습니다. 엔터티 상태를 평가하기 위해서는 Health 스토어에서 엔터티에 대한 모든 상태 보고서를 집계하고 모든 자식(해당하는 경우)을 평가합니다. 상태 집계 알고리즘은 상태 보고서를 평가하는 방법과 자식 성능 상태(해당하는 경우)를 집계하는 방법을 지정하는 상태 정책을 사용합니다.
상태 보고서 집계
하나의 엔터티에는 서로 다른 속성에 대해 서로 다른 보고자(시스템 구성 요소 또는 Watchdog)에서 보낸 여러 상태 보고서가 있을 수 있습니다. 집계에서는 연결된 상태 정책 특히, 애플리케이션 또는 클러스터 상태 정책의 ConsiderWarningAsError 멤버를 사용합니다. ConsiderWarningAsError는 경고를 평가하는 방법을 지정합니다.
집계된 성능 상태는 해당 엔터티에 대한 최악 의 상태 보고서에 의해 트리거됩니다. 오류 상태 보고서가 하나 이상 있는 경우, 집계된 성능 상태는 오류입니다.
하나 이상의 오류 상태 보고가 있는 상태 엔터티는 오류로 평가됩니다. 만료된 상태 보고서에 대해서도 그 상태와 상관없이 같은 내용이 적용됩니다.
오류 보고서가 없고 하나 이상의 경고가 있는 경우 집계된 성능 상태는 ConsiderWarningAsError 정책 플래그에 따라 경고 또는 오류 중 하나입니다.
경고 보고서가 있고 ConsiderWarningAsError가 false(기본값)로 설정된 상태 보고서 집계.
자식 상태 집계
엔터티의 집계된 성능 상태는 자식 성능 상태(해당하는 경우)를 반영합니다. 자식 성능 상태를 집계하기 위한 알고리즘은 엔터티 유형에 따라 적용 가능한 상태 정책을 사용합니다.
상태 정책에 따른 자식 집계.
Health 스토어에서 모든 자식을 평가한 후 비정상 자식에 대해 구성된 최대 비율에 따라 성능 상태를 집계합니다. 이 비율은 엔터티 및 자식 유형을 기반으로 하는 정책에서 확보합니다.
- 모든 자식이 정상 상태이면 자식 집계 성능 상태도 정상입니다.
- 자식에 정상 및 경고 상태가 모두 있으면 자식 집계 성능 상태는 경고입니다.
- 허용된 최대 비정상 자식 비율에 들어가지 않는 오류 상태의 자식이 있으면 집계된 부모 성능 상태는 오류입니다.
- 오류 상태의 자식이 허용된 최대 비정상 자식 비율 내에 있으면 집계된 부모 성능 상태는 경고입니다.
상태 보고
시스템 구성 요소, 시스템 패브릭 애플리케이션 및 내부/외부 Watchdog에서 Service Fabric 엔터티에 대해 보고할 수 있습니다. 보고자는 모니터링하는 상태를 바탕으로 모니터링되는 엔터티의 상태를 로컬 결정으로 파악합니다. 따라서 전역 상태를 살펴보거나 데이터를 집계할 필요가 없습니다. 바람직한 동작은 간단한 보고자를 갖는 것이지 보낼 정보를 추정하기 위해 많은 것들을 살펴봐야 하는 복잡한 조직체를 갖는 것이 아닙니다.
상태 데이터를 Health 스토어로 보내려면 보고자가 영향 받는 엔터티를 식별하여 상태 보고서를 작성해야 합니다. 보고서를 보내려면 FabricClient.HealthClient.ReportHealth API Partition 또는 CodePackageActivationContext 개체, PowerShell cmdlet 또는 REST에 노출된 상태 보고서 API를 사용합니다.
상태 보고서
클러스터의 각 엔터티에 대한 상태 보고서 에는 다음과 같은 정보가 포함됩니다.
SourceId. 상태 이벤트의 보고자를 고유하게 식별하는 문자열입니다.
엔터티 식별자. 보고서가 적용되는 엔터티를 식별합니다. 다음과 같은 엔터티 유형에 따라 달라집니다.
- 클러스터. 없음.
- 노드. 노드 이름(문자열).
- 응용 프로그램. 애플리케이션 이름(URI). 클러스터에 배포된 애플리케이션 인스턴스의 이름을 나타냅니다.
- 서비스. 서비스 이름(URI). 클러스터에 배포된 서비스 인스턴스의 이름을 나타냅니다.
- 파티션. 파티션 ID(GUID). 파티션 고유 식별자를 나타냅니다.
- 복제본. 상태 저장 서비스 복제본 ID 또는 상태 비저장 서비스 인스턴스 ID(INT64).
- DeployedApplication. 애플리케이션 이름(URI) 및 노드 이름(문자열).
- DeployedServicePackage. 애플리케이션 이름(URI), 노드 이름(문자열) 및 서비스 매니페스트 이름(문자열).
속성. 보고자가 엔터티의 특정 속성에 대한 상태 이벤트를 분류하도록 허용하는 문자열 (고정된 열거형 아님). 예를 들어, 보고자 A는 Node01 "스토리지" 속성의 상태를 보고할 수 있으며 보고자 B는 Node01 "연결" 속성의 상태를 보고할 수 있습니다. Health 스토어에서 이 보고서는 Node01 엔터티에 대한 별도의 상태 이벤트로 처리됩니다.
설명. 보고자가 상태 이벤트에 대한 세부 정보를 제공하도록 허용하는 문자열. SourceId, 속성 및 HealthState는 보고서를 완벽하게 설명해야 합니다. 설명을 통해 보고서에 대한 알기 쉬운 정보를 추가하면 관리자와 사용자가 상태 보고서를 손쉽게 이해할 수 있습니다.
HealthState. 보고서의 성능 상태를 설명하는 열거형 . 허용되는 값은 정상, 경고 및 오류입니다.
TimeToLive. 상태 보고서가 유효 상태를 유지하는 기간. RemoveWhenExpired와 연결되어 있으므로 Health 스토어에서 만료된 이벤트를 평가하는 방법을 알 수 있습니다. 기본적으로 이 값은 무한대이고 보고서는 영원히 유효합니다.
RemoveWhenExpired. 부울입니다. true로 설정되면 만료된 상태 보고서가 Health 스토어에서 자동으로 제거되며 엔터티 상태 평가에는 영향을 주지 않습니다. 보고서가 지정된 기간만 유효하고 보고자가 해당 보고서를 명시적으로 지울 필요가 없을 때 사용됩니다. Health 스토어에서 보고서를 삭제하는 데도 사용됩니다(예를 들어, Watchdog이 변경되어 이전 소스와 속성으로 보고서를 보내는 것을 중지하는 경우). RemoveWhenExpired와 함께 간략한 TimeToLive로 보고서를 보내 Health 스토어에서 이전 상태를 정리할 수 있습니다. 이 값을 false로 설정하면 만료된 보고서가 상태 평가에서 오류로 처리됩니다. false 값은 소스에서 이 속성에 대해 주기적으로 보고해야 함을 Health 스토어에 알려주는 것입니다. 그렇지 않은 경우 Watchdog에 문제가 있는 것입니다. Watchdog 상태는 이벤트를 오류로 간주하여 캡처됩니다.
SequenceNumber. 계속 증가되어야 하는 양의 정수로, 보고서의 순서를 나타냅니다. Health 스토어에서 네트워크 지연 또는 기타 문제 때문에 늦게 수신된 기한 경과된 보고서를 감지하는 데 사용됩니다. 시퀀스 번호가 동일한 엔터티, 소스 및 속성에 대해 가장 최근에 적용된 번호보다 작거나 같은 경우, 보고서는 거부됩니다. 시퀀스 번호를 지정하지 않으면 자동으로 생성됩니다. 상태 전환에 대해 보고하는 경우에만 시퀀스 번호를 부여해야 합니다. 이 경우 소스는 전송할 보고서를 기억해야 하며 장애 조치(failover)를 위해 복구에 대한 정보를 유지해야 합니다.
SourceId, 엔터티 식별자, 속성 및 HealthState의 4가지 정보는 모든 상태 보고서에서 필요합니다. SourceId 문자열은 접두사 "System."으로 시작할 수 없습니다. 이 접두사는 시스템 보고서용으로 예약되어 있습니다. 동일한 엔터티인 경우 동일한 소스 및 속성에 대해 하나의 보고서만 있습니다. 동일한 소스와 속성에 대한 여러 보고서는 상태 클라이언트(배치 처리된 경우) 또는 Health 스토어 중 한 군데에서 서로 재정의됩니다. 교체는 시퀀스 번호를 기준으로 수행됩니다. 최신 보고서(높은 시퀀스 번호)가 오래된 보고서를 대체합니다.
상태 이벤트
내부적으로 Health 스토어에는 보고서와 추가 메타데이터의 모든 정보를 포함하는 상태 이벤트가 유지됩니다. 메타데이터에는 보고서를 상태 클라이언트에 제공한 시간 및 서버에서 보고서가 수정된 시간 등이 포함됩니다. 상태 이벤트는 상태 쿼리로 반환됩니다.
추가된 메타데이터에는 다음이 포함됩니다.
- SourceUtcTimestamp. 보고서가 상태 클라이언트에 제공된 시간(협정 세계시).
- LastModifiedUtcTimestamp. 서버에서 보고서가 마지막으로 수정된 시간(협정 세계시).
- IsExpired. Health 스토어에 의해 쿼리가 실행된 시간에 보고서가 만료되었는지 여부를 나타내는 플래그. RemoveWhenExpired가 false인 경우에만 이벤트가 만료될 수 있습니다. 그렇지 않은 경우 쿼리에 의해 이벤트가 반환되지 않으며 스토어에서 제거됩니다.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. 마지막 정상/경고/오류 전환 시간. 이러한 필드는 이벤트에 대한 성능 상태 전환 기록을 제공합니다.
상태 전환 필드는 보다 현명한 경고 또는 "시간에 따른" 상태 이벤트 정보에 대해 사용할 수 있습니다. 따라서 다음과 같은 시나리오가 가능해집니다.
- 속성이 X분 넘게 경고/오류 상태일 때 알림. 일정 기간에 대한 조건을 확인하면 임시 조건에 대한 경고를 방지합니다. 예를 들어, 5분 이상 경고 상태에 있었던 성능 상태가 (HealthState == 경고 및 현재 - LastWarningTransitionTime > 5분)으로 전환될 수 있는 경우.
- 지난 X분 내에 변경된 상태에 대해서만 알림. 지정된 시간 이전부터 보고서가 오류 상태인 경우, 이전에 이미 알린 상태이므로 무시할 수 있습니다.
- 속성이 경고와 오류 사이에 전환되고 있는 경우, 얼마나 오래 비정상(즉, 정상이 아닌 상태)이었는지 결정합니다. 예를 들어, 5분 이상 정상이 아니었던 속성이 (HealthState != 정상 및 현재 - LastOkTransitionTime > 5분)으로 전환될 수 있는 경우 알림.
예: 애플리케이션 상태 보고 및 평가
다음 예에서는 소스 MyWatchdog의 패브릭:/WordCount 애플리케이션에서 PowerShell을 통해 상태 보고서를 보냅니다. 상태 보고서에는 무한 TimeToLive와 함께 오류 성능 상태에서 상태 속성 Availability에 대한 정보가 포함됩니다. 그런 다음, 집계된 성능 상태 오류 및 보고된 상태 이벤트를 상태 이벤트 목록으로 반환되는 애플리케이션 상태를 쿼리합니다.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
상태 모델 사용
상태 모델을 사용하면 클러스터 내의 여러 모니터에 모니터링 및 상태 결정이 분산되므로 클라우드 서비스 및 기본 서비스 패브릭 플랫폼을 확장할 수 있습니다. 다른 시스템에는 서비스에서 내보낸 모든 잠재적으로 유용한 정보를 구문 분석하는 단일 중앙 집중 서비스가 클러스터 수준에 있습니다. 이 방법으로 인해 확장성이 저하됩니다. 문제 및 잠재적 문제를 가능한 한 근본 원인에 가깝게 식별하는 데 도움이 되는 매우 구체적인 정보를 수집할 수 없습니다.
상태 모델은 모니터링 및 진단, 클러스터 및 애플리케이션 상태 평가, 모니터링되는 업그레이드에서 굉장히 많이 사용됩니다. 다른 서비스에서는 상태 데이터를 사용하여 자동 복구를 수행하고 클러스터 상태 기록을 작성하고 특정 상태에 대한 알림을 생성합니다.
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기