Apache Spark는 메모리 내 처리를 지원하여 빅 데이터 분석 애플리케이션의 성능을 향상하는 병렬 처리 프레임워크입니다. Azure Synapse Analytics의 Apache Spark는 Microsoft가 구현한 클라우드의 Apache Spark 중 하나입니다.
이제 Azure Synapse는 GPU의 방대한 병렬 처리 능력을 사용하여 처리를 가속화하는 기본 RAPIDS 라이브러리를 통해 Spark 워크로드를 실행하는 Azure Synapse GPU 사용 풀을 만드는 기능을 제공합니다. Apache Spark용 RAPIDS 가속기를 사용하면 GPU 사용 풀로 미리 구성된 구성 설정을 사용하도록 설정하여 코드 변경 없이 기존 Spark 애플리케이션을 실행할 수 있습니다. 다음 구성을 설정하여 워크로드 전체 또는 일부에 대해 RAPIDS 기반 GPU 가속을 설정하거나 해제할 수 있습니다.
spark.conf.set('spark.rapids.sql.enabled','true/false')
참고 항목
Azure Synapse GPU 지원 풀 미리 보기는 이제 더 이상 사용되지 않습니다.
Apache Spark용 RAPIDS 가속기
Spark RAPIDS 가속기는 지원되는 GPU 작업을 통해 Spark 작업의 물리적 계획을 재정의하고 GPU에서 해당 작업을 실행하여 처리를 가속화하는 데 작동하는 플러그 인입니다. 이 라이브러리는 현재 미리 보기에 있으며 모든 Spark 작업을 지원하지 않습니다(여기에는 현재 지원되는 연산자 목록이 있으며 새 릴리스를 통해 추가 지원이 점진적으로 추가됨).
클러스터 구성 옵션
RAPIDS 가속기 플러그 인은 GPU와 실행기 간의 일대일 매핑만 지원합니다. 즉, Spark 작업은 풀 리소스에서 수용할 수 있는 실행기 및 드라이버 리소스를 요청해야 합니다(사용 가능한 GPU 및 CPU 코어 수에 따라). 이 조건을 충족하고 모든 풀 리소스를 최적으로 사용하도록 보장하려면 GPU 사용 풀에서 실행되는 Spark 애플리케이션에 대해 다음과 같은 드라이버 및 실행기를 구성해야 합니다.
| 풀 크기 | 드라이버 크기 옵션 | 드라이버 코어 | 드라이버 메모리(GB) | 실행기 코어 수 | 실행기 메모리(GB) | 실행기 수 |
|---|---|---|---|---|---|---|
| GPU-대형 | 소형 드라이버 | 4 | 30 | 12 | 60 (육십) | 풀의 노드 수 |
| GPU-대형 | 중간 드라이버 | 7 | 30 | 9 | 60 (육십) | 풀의 노드 수 |
| GPU-초대형 | 중간 드라이버 | 8 (여덟) | 40 | 14 | 80 | 4 * 풀의 노드 수 |
| GPU-초대형 | 대형 드라이버 | 12 | 40 | 13 | 80 | 4 * 풀의 노드 수 |
위의 구성 중 하나를 충족하지 않는 워크로드는 허용되지 않습니다. 이는 Spark 작업이 풀에서 사용 가능한 모든 리소스를 활용하는 가장 효율적이고 성능이 좋은 구성으로 실행되도록 하기 위해 수행됩니다.
사용자는 워크로드를 통해 위의 구성을 설정할 수 있습니다. Notebook의 경우 사용자는 %%configure 매직 명령을 사용하여 아래와 같이 위 구성 중 하나를 설정할 수 있습니다.
예를 들어 세 개의 노드가 있는 대형 풀을 사용하는 경우 다음과 같습니다.
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Azure Synapse GPU 가속 풀에서 Notebook을 통해 샘플 Spark 작업 실행
이 섹션을 진행하기 전에 Azure Synapse Analytics에서 Notebook을 사용하는 방법에 대한 기본 개념을 숙지하는 것이 좋습니다. GPU 가속을 활용하는 Spark 애플리케이션을 실행하는 단계를 살펴보겠습니다. Spark 애플리케이션은 Synapse 내에서 지원되는 4개 언어(PySpark(Python), Spark(Scala), SparkSQL 및 .NET for Spark(C#)) 모두로 작성할 수 있습니다.
GPU 지원 풀을 만듭니다.
Notebook을 만들고 첫 번째 단계에서 만든 GPU 사용 풀에 연결합니다.
이전 섹션에서 설명한 대로 구성을 설정합니다.
아래 코드를 Notebook의 첫 번째 셀에 복사하여 샘플 데이터 프레임을 만듭니다.
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- 이제 부서 ID당 최대 급여를 가져와서 집계를 수행하고 결과를 표시해 보겠습니다.
- Spark 기록 서버를 통해 SQL 계획을 살펴보면 GPU에서 실행된 쿼리의 작업을 확인할 수 있습니다.
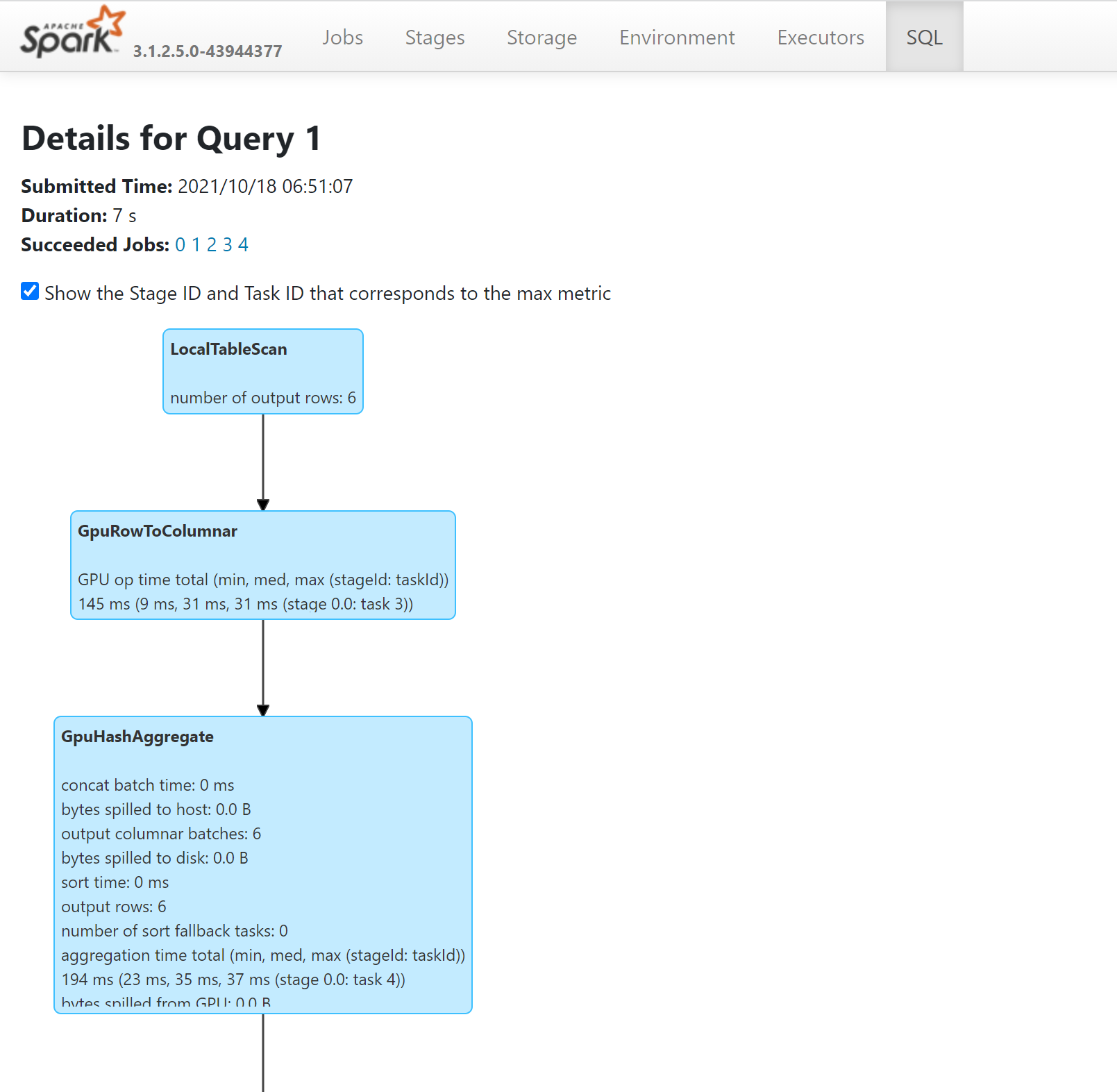
애플리케이션을 GPU용으로 튜닝하는 방법
대부분의 Spark 작업은 기본값에서 구성 설정을 튜닝하여 향상된 성능을 확인할 수 있으며, Apache Spark용 RAPIDS 가속기 플러그 인을 활용하는 작업의 경우에도 마찬가지입니다.
Azure Synapse GPU 사용 풀의 할당량 및 리소스 제약 조건
작업 영역 수준
모든 Azure Synapse 작업 영역에는 GPU vCore 수가 50개인 기본 할당량이 제공됩니다. GPU 코어 할당량을 늘리려면 Azure Portal 통해 지원 요청을 제출하세요.